Hadoop部署
1 Linux系统安装
1.1 VM安装
官方下载
1.2 CentOS安装
安装步骤
1.3 修改虚拟机网络
1)查看虚拟网络编辑器
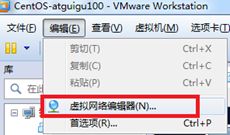
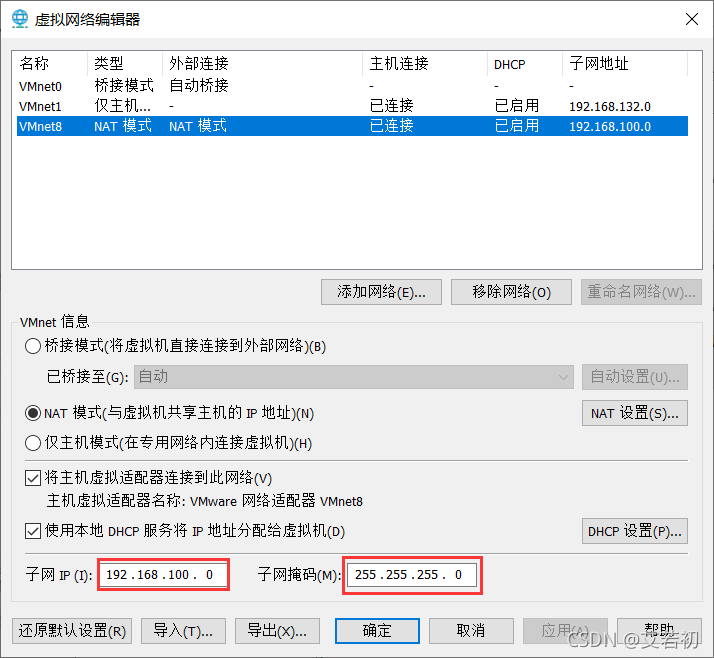
2)修改ip地址和子网掩码
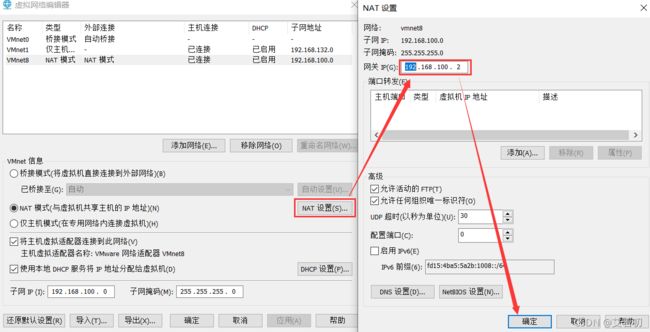
3)查看网关
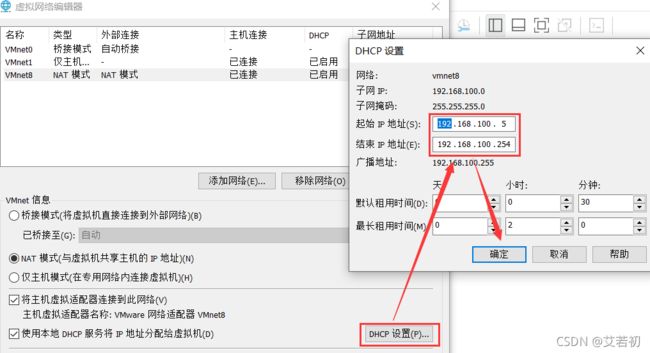
4)DHCP设置
1.4 Linux主机名、IP配置
1.4.1、修改主机名
切换到root
su root
修改
[root@localhost ~]# vi /etc/hostname

生效需要重启linux(可暂不重启)
[root@localhost ~]# reboot
或
[root@localhost ~]# hostnamectl set-hostname NEW_NAME #永久修改主机名
[root@localhost ~]# exit #之后需要,退出重连才能生效。
查看文件

1.4.2、修改IP
[root@hadoop100 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
BOOTPROTO="static" #改为静态
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="92080b37-6045-47a2-872c-a832939226f4"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.100.100 #虚拟机需要配置独立的 IP 地址
GATEWAY=192.168.100.2
NETMASK=255.255.255.0
DNS1=172.16.247.22 #不用配置。如需连接 Internet,则配置跟宿主主机配置一致
DNS2=192.16.247.10 #不用配置。如需连接 Internet,则配置跟宿主主机配置一致
按“i"进入文件的编辑模式;按“Esc"进入命令模式;进入命令模式,输入:wq(或shift+Z+Z,保存退出)、:q!(退出不保存)。
1.4.3、修改主机名和ip的映射
[root@hadoop100 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.100 hadoop100
192.168.100.101 hadoop101
192.168.100.102 hadoop102
重启系统:
reboot
重启网络(如果1.4.1已经冲洗系统,此处可以重启网络代替重启系统):
[root@hadoop100 ~]# service network restart
此处可以使用mobaxterm连接测试
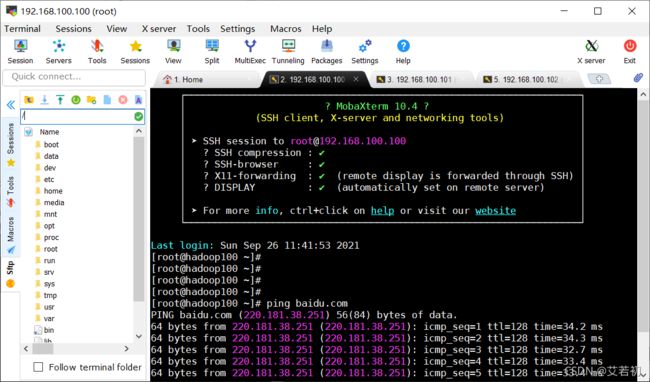
1.4.4、关闭防火墙
Centos7关闭命令:
systemctl status firewalld #查看当前防火墙状态
#或
firewall-cmd --state #查看当前防火墙状态
systemctl stop firewalld #关闭当前防火墙。
systemctl disable firewalld #开机防火墙不启动。
防火墙关闭后可以通过ping测试连通性
1.5 SSH免密登录
1、执行
ssh-keygen -t rsa
一路回车
执行:
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
查看/root/.ssh/文件夹中生成一系列文件
2 Java JDK环境安装
软件卸载:
已有OpenJdk卸载
查询现有Java Jdk版本
java -version
查看已经安装版本
rpm -qa|grep java
进行卸载:
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
查看卸载情况
java -version
创建目录
mkdir -p /usr/local/soft #创建soft目录
通过mobaxterm将javajdk上传linux系统。
jdk官网下载
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html

解压:
cd /usr/local/soft/
tar -zxvf jdk-8u11-linux-x64.tar.gz
配置环境变量:
vim /etc/profile #vim或vi都可以
输入
export JAVA_HOME=/usr/local/soft/jdk1.8.0_11
export PATH=.:$PATH:$JAVA_HOME/bin

保存退出
:wq #或Shift+Z+Z
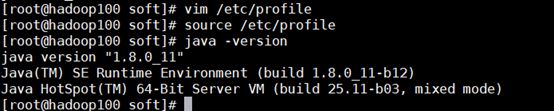
使修改立即生效:
source /etc/profile
验证:
java -version
3 Hadoop单机部署
通过mobaxterm将hadoop发布包上传/usr/local/soft/目录下
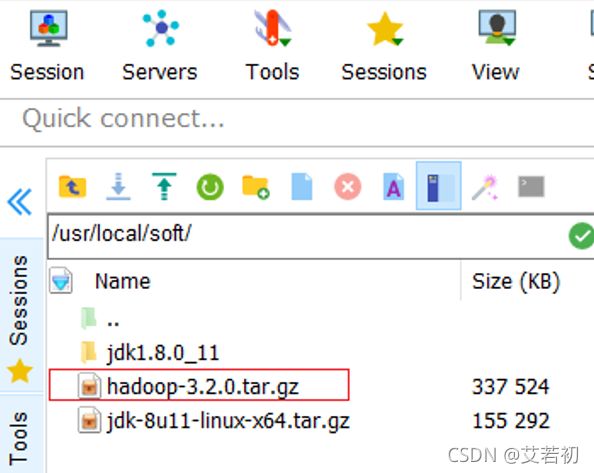
3.1 软件解压
cd /usr/local/soft/
tar -zxvf hadoop-3.2.0.tar.gz
3.2 修改Hadoop的Java配置路径:/usr/local/soft/hadoop-3.2.0/etc/hadoop/hadoop-env.sh
vi /usr/local/soft/hadoop-3.2.0/etc/hadoop/hadoop-env.sh
文件末尾添加如下内容:
export JAVA_HOME=/usr/local/soft/jdk1.8.0_11
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/data/hadoop/pids
export HADOOP_LOG_DIR=/data/hadoop/logs
添加系统环境变量:
vi /etc/profile
新增如下内容
export HADOOP_HOME=/usr/local/soft/hadoop-3.2.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
使环境变量生效
source /etc/profile
3.3 修改配置文件
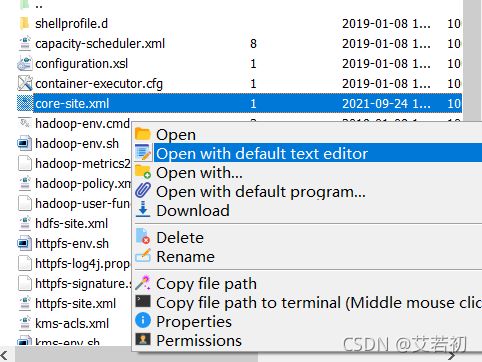
进入/usr/local/soft/hadoop-3.2.0/etc/hadoop/目录,修改core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop100:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/data/hadoop/tmpvalue>
property>
configuration>
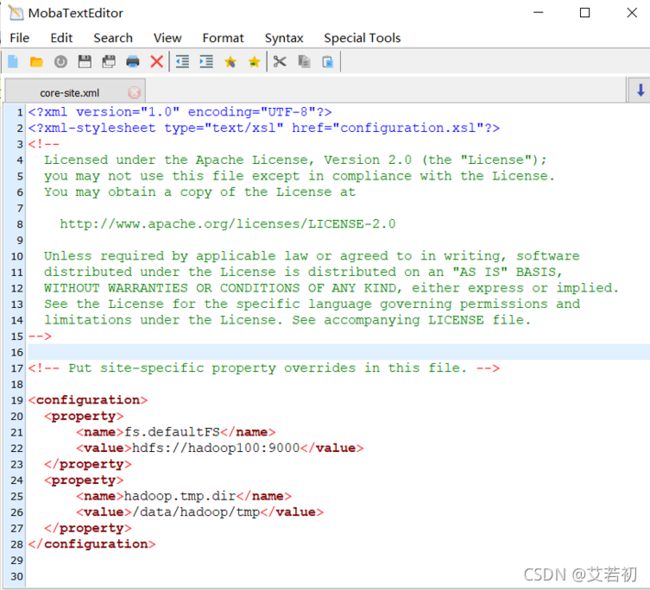
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop100:50090value>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/data/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/data/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
configuration>

dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将master1规划为SecondaryNameNode服务器。
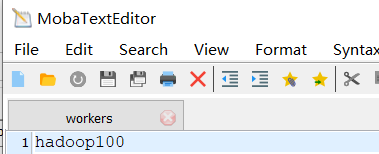
Workers中添加
hadoop100
workers文件是指定HDFS上有哪些DataNode节点。
Yarn-site.xml配置
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.localizer.addressname>
<value>0.0.0.0:8140value>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop100value>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.log.server.urlname>
<value>http://hadoop100:19888/jobhistory/logsvalue>
property>
configuration>
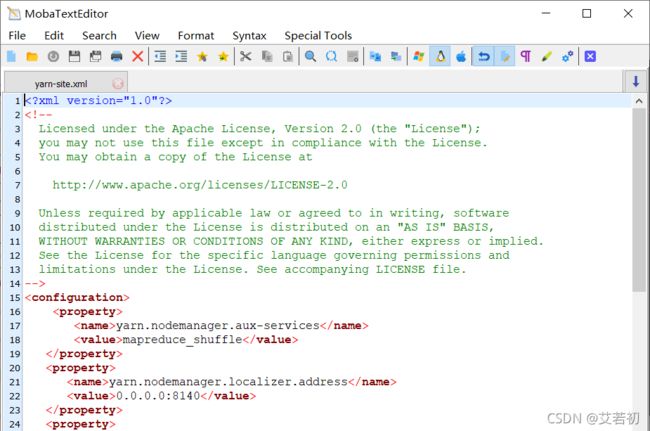
根据规划yarn.resourcemanager.hostname这个指定resourcemanager服务器指向hadoop100。
yarn.log-aggregation-enable是配置是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多长时间。
Maperd-site.xml配置
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/soft/hadoop-3.2.0value>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/soft/hadoop-3.2.0value>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/soft/hadoop-3.2.0value>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop100:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value> hadoop100:19888value>
property>
configuration>

mapreduce.framework.name设置mapreduce任务运行在yarn上。
mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在master1机器上。
mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口号
3.4 格式化Hadoop系统(如果是配置集群,下面几步不要操作)
hdfs namenode -format
3.5 启动hdfs和yarn
start-all.sh
(停止:stop-all.sh)
3.6 检测
进程:
jps
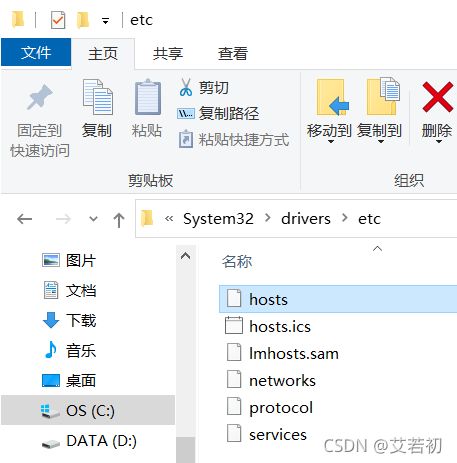
配置Windows的hosts映射
打开C:\Windows\System32\drivers\etc文件夹,修改hosts,添加如下内容
192.168.100.100 hadoop100
192.168.100.101 hadoop101
192.168.100.102 hadoop102

打开浏览器验证
HDFS Web页面
http://hadoop100:9870/
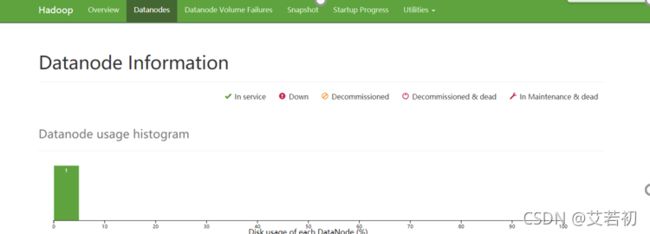
YARN Web页面
http://hadoop100:8088/

创建test文件夹:
hadoop fs -mkdir /test
4 Hadoop集群部署
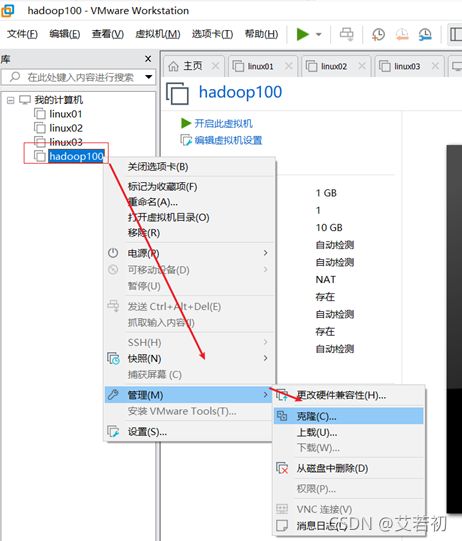
4.1 虚拟机克隆
①关闭要被克隆的虚拟机
②找到克隆选项
③欢迎页面点击下一步
④克隆虚拟机,克隆自虚拟机的当前状态后,点击下一步
⑤设置创建完整克隆
⑥设置克隆的虚拟机名称和存储位置
⑦等待正在克隆
⑧点击关闭,完成克隆
4.2 进入各主机修改内容
4.2.1 Hadoop101服务器上修改
修改主机名为hadoop101
切换到root
su root
[root@localhost ~]# vi /etc/hostname

修改IP
[root@hadoop100 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=“Ethernet”
BOOTPROTO=“static”
DEFROUTE=“yes”
PEERDNS=“yes”
PEERROUTES=“yes”
IPV4_FAILURE_FATAL=“no”
IPV6INIT=“yes”
IPV6_AUTOCONF=“yes”
IPV6_DEFROUTE=“yes”
IPV6_PEERDNS=“yes”
IPV6_PEERROUTES=“yes”
IPV6_FAILURE_FATAL=“no”
IPV6_ADDR_GEN_MODE=“stable-privacy”
NAME=“ens33”
UUID=“92080b37-6045-47a2-872c-a832939226f4”
DEVICE=“ens33”
ONBOOT=“yes”
IPADDR=192.168.100.101
GATEWAY=192.168.100.2
NETMASK=255.255.255.0
DNS1=
重启系统:
reboot
此处可以使用mobaxterm连接测试
4.2.2 Hadoop102服务器上修改
修改主机名为hadoop102
切换到root
su root
vi /etc/hostname
修改IP
[root@hadoop100 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=“Ethernet”
BOOTPROTO=“static”
DEFROUTE=“yes”
PEERDNS=“yes”
PEERROUTES=“yes”
IPV4_FAILURE_FATAL=“no”
IPV6INIT=“yes”
IPV6_AUTOCONF=“yes”
IPV6_DEFROUTE=“yes”
IPV6_PEERDNS=“yes”
IPV6_PEERROUTES=“yes”
IPV6_FAILURE_FATAL=“no”
IPV6_ADDR_GEN_MODE=“stable-privacy”
NAME=“ens33”
UUID=“92080b37-6045-47a2-872c-a832939226f4”
DEVICE=“ens33”
ONBOOT=“yes”
IPADDR=192.168.100.102
GATEWAY=192.168.100.2
NETMASK=255.255.255.0
DNS1=
重启系统:
reboot
此处可以使用mobaxterm连接测试
4.2.3、修改配置文件执行集群间拷贝
修改hadoop100上面的workers
vi /usr/local/soft/hadoop-3.2.0/etc/hadoop/workers
添加hadoop101和hadoop102
同步修改后文件到hadoop101和hadoop102上
scp /usr/local/soft/hadoop-3.2.0/etc/hadoop/workers root@hadoop101:/usr/local/soft/hadoop-3.2.0/etc/hadoop/
scp /usr/local/soft/hadoop-3.2.0/etc/hadoop/workers root@hadoop102:/usr/local/soft/hadoop-3.2.0/etc/hadoop/
拷贝完成,检查另两台机器是否执行拷贝成功
4.2.4 集群SSH免密登录
.ssh文件夹下(~/.ssh)的文件功能解释
known_hosts 记录ssh访问过计算机的公钥(public key)
id_rsa 生成的私钥
id_rsa.pub 生成的公钥
authorized_keys 存放授权过的无密登录服务器公钥
ssh-copy-id hadoop100
ssh-copy-id hadoop101
ssh-copy-id hadoop102
三个服务器上都用root账户执行上述脚本
4.2.5 格式化系统
将三个服务器上的/data全部删除,各服务器上执行如下命令:
rm -fr /data
hadoop100服务器上执行:
hdfs namenode -format
5、启动
定位到路径:
cd /usr/local/soft/hadoop-3.2.0/
执行
./sbin/start-all.sh
从节点生成相关文件
停止:
./sbin/stop-all.sh
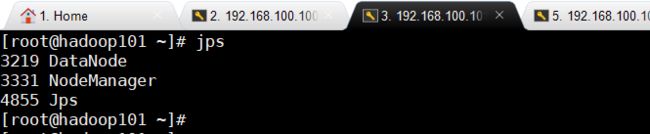
6、检测
进程:
jps

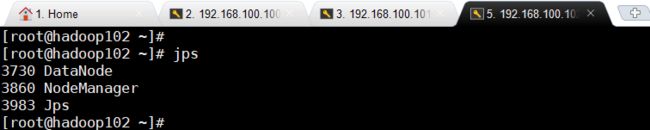
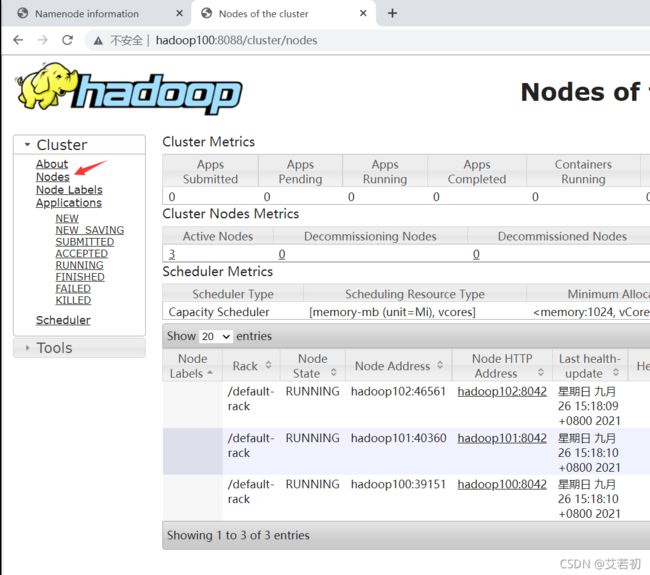
HDFS Web页面
http://hadoop100:9870/
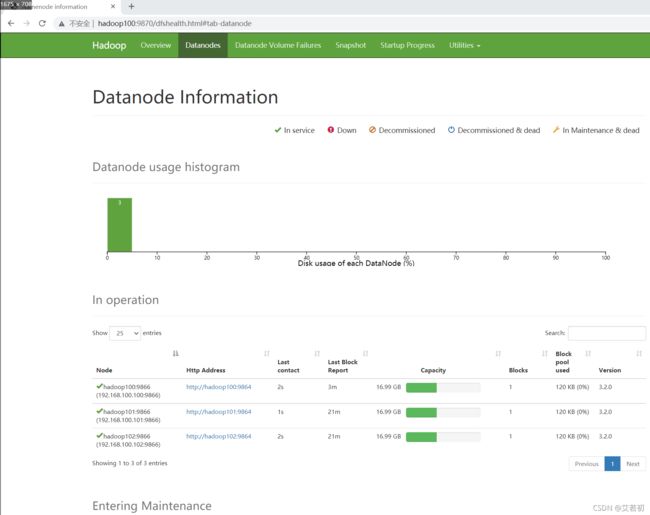
YARN Web页面
http://hadoop100:8088/
创建test文件夹:
hadoop fs -mkdir /test
附常见问题:FQA
1、如果集群正常启动,发现网页中没有子节点:
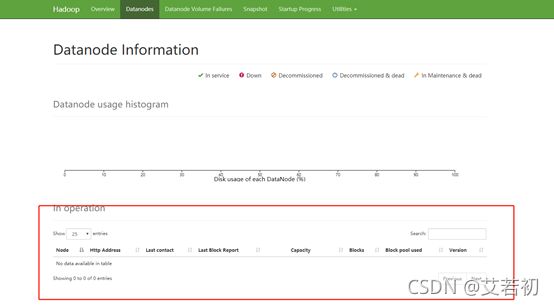
先关闭集群:
./sbin/stop-all.sh
查找主节点version中的集群ID,路径/data/hadoop/hdfs/name/current/
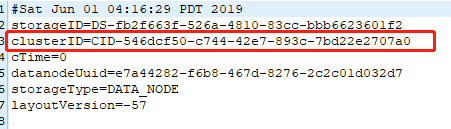
在两个从节点中找到从节点的version,路径:/data/hdfs/data/current/
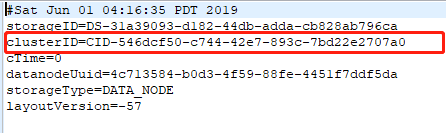
clusterID从节点需要和主节点保持一致,如果从节点没有current文件夹,再自己检查配置和日志文件里面错误信息
2、启动都成功,网页中没有从节点
检查防火墙是否关闭
3、格式化失败,报权限问题
检查hadoop文件夹所有者是否当前用户,如果不是,执行命令
chown -R root /usr/local/soft/hadoop-3.2.0
4、如果某个端口号不起作用,命令查看端口启动情况
netstat -tlpn
5、整个文件夹拷贝
scp -r /usr/local/soft/hadoop-3.2.0 root@hadoop100:/usr/local/soft/hadoop-3.2.0
scp -r /usr/local/soft/hadoop-3.2.0 root@hadoop100:/usr/local/soft/hadoop-3.2.0