日撸 Java 三百行(20 天: 过去10日总结)
注意:这里是JAVA自学与了解的同步笔记与记录,如有问题欢迎指正说明
目录
· 前言
一、面向对象与面向过程相比, 有哪些优势?
二、比较顺序表和链表的异同
三、分析顺序表和链表的优缺点
四、分析调拭程序常见的问题及解决方案
五、分析链队列与循环队列的优缺点
六、第 18 天建立的两个队列, 其区别仅在于基础数据不同, 一个是 int, 一个是 char. 按这种思路, 对于不同的基础数据类型, 都需要重写一个类, 这样合理吗? 你想怎么样?
· 前言
今天不介绍新的数据结构,我们主要来回顾下之前几日的学习,并且通过问答的形式来总结下截止到目前我们所写内容的一些特征。
问题来源于:日撸 Java 三百行(11-20天,线性数据结构)
一、面向对象与面向过程相比, 有哪些优势?
自从面向对象出现后,人们就不断对这两种编程方式进行对比,但是无可否认,任何编程方式的诞生是有其原因的。上个世纪末,随着硬件突飞猛进的发展,过去“小作坊”式的软件开发逐渐陷入瓶颈,从此迎来了第二次软件危机 ,由此,面向对象语言才逐渐进入大家视野。(这里我强烈推荐一篇介绍语言架构发展历史的文章:关于系统架构你不知道的那些事之架构设计的历史背景,我还是第一次听说1963 年美国的水手一号火箭发射失败事故,就是因为一行 FORTRAN 代码错误导致的,当时真的让面向过程是否能够胜任超大型的项目开发引发了质疑)
为什么面向对象能够顺利让我走出第二次软件危机,成为我们现在开发任何一个大型算法、项目都几乎是必须采用的一种思维,其本质来说,应该是这种“ 抽象 ”现实世界的能力。
面向过程是分析出问题解决所需要的步骤,然后用函数把这些步骤逐步实现即可,使用的时候逐步调用。而面向对象我们不先分析步骤,而是先去划分我们的问题为一个个事务,并为每个事务建立对象,建立对象的目的不在于如何去完成一个个步骤,而是为了描述某个事务在解决全部问题中表现的行为。
这种事务的划分时基于我们现实世界的,因此,这是非常有利于去契合我们人看待世界的思维,从而发现面向过程思维中所无法轻易察觉的错误。而且这种事务的划分常常因为与现实重合,从而表现出极佳的重用性,而且模块构造良好,接口完善,具备优秀的内聚性,低耦合,灵活方便。其具备的继承,多态,抽象等手段又能非常方便于大型项目的扩展和维护(要知道大型的项目往往是多人参与),避免了机械陷入分析问题步骤的“一维式的编程思维”,而是模块化的,易于多人参与的工程式的思维与视角。
这些是面向过程所缺乏的,但是也能理解的,毕竟,面向过程语言只是从机器语言脱离出来的第一次抽象,还留有大量指令的过程化风格。我们不能完全否定过程化的思维,毕竟其对于小范围内算法的设计性价比是最高的,所以,一个良好的项目应当是全局的面向对象与细节方法手段的面向过程。
二、比较顺序表和链表的异同
三、分析顺序表和链表的优缺点
顺序表和链表作为线性表的双子,他们俩在许多情形下都有非常具有鲜明特点的互补性,而这些互补性也鲜明表示此优彼劣,所以我就把这两个问题合二为一分析。下面我就从数据结构特性,以及增、删、改、查、创建删除的复杂度角度去分析他们的异同与优缺点。
1.数据结构特性:
顺序表在逻辑上相邻元素于物理上一定相邻,又因为物理存储块可以等大小,于是赋予了顺序表一个超级方便的特性:随机存取,即通过O(1)复杂度完成已知范围内元素的访问。但是这个特性同时也给顺序表结构带来了一些不便,因为其逻辑结构是严格线性的,所以通常不方便在逻辑结构上表示些复杂的拓扑结构,比如树、图等结构。
链表在逻辑上相邻元素于物理不一定相邻,因此链表只能用O(N)顺序存取,而且链表因为指针的引入,在有效数据的存储上存在一定的冗余,所以对于单个数据项量比较小的结构例如字符串,我们不会去使用链表。但是,因为其物理的上的离散特性往往能胜任一些比较麻烦复杂的高级数据结构比如树、图等结构。
2.查找(查找到了就可以改,所以改操作不赘述):
首先,对于按序查找,我们使用顺序表可以非常方便用O(1)复杂度完成随机存取。但是链表必须老老实实利用O(N)的顺序存取一个个遍历。这一点上顺序表胜。
其次,对于无序表的按值查找,顺序表和链表都必须O(N)逐个查找,但是若原数据为有序表,顺序表可以利用随机访问的特性实现二分查找,可以将查找复杂度优化为O(logN)。这一点上顺序表胜。
3.增、删
要实现增加和删除往往需要先找到需要操作的元素的位置,这一点继承上述的查找的结果,所以这里分析增加和删除就默认已经确定元素位置的增删。
对于顺序表来说,我们需要成批次需要用移动才能实现删除与添加,因此复杂度是O(N);对于链表来说,我们只需要修改节点之间的指针关系即可快速实现删除与添加,因此只要O(1)。
由此来看链表要更胜一筹,但是如果把非有序的按值查找+增删结合起来看的话,似乎两者在确定位置并且对位置元素进行增删的时间开销都是O(N)复杂度,只不过顺序表开销主要在移动元素上,而链表主要在找元素上。但是从数据本身来看,较大的元素进行移动似乎需要更多时间,而找元素这个过程并没有那么大开销,所以虽然都是O(N),对于大数据线性表,链表开销会稍微小点。
4.创建删除
创建删除操作具有非常鲜明的语言差异,但是一般来说,顺序表的创建会相对没那么灵活,首先某些语言的静态顺序表是不灵活的,一旦创建后空间大小便不再改变,不利于后期进行维护和扩展。动态的创建的顺序表虽然可以在后期进行扩展,但是每次扩展都需要O(N)复杂度对于数据进行重写拷贝,不算方便。相比来说,链表的数据创建就很方便,理论上,编译器给了你多少空间你都可以灵活扩充,当前空间即可用空间。所以就数据创建来看,链表更胜一筹。
删除操作优劣的话这个要看具体语言,有的语言编译器和自动进行无效数据清空(比如JAVA),所以这一点其实两种线性结构基本没有什么差异。但是放在早期语言,链表和动态顺序表的清理还是很大部分交给程序员自己完成,而静态顺序可以由系统自动完成清理。
四、分析调拭程序常见的问题及解决方案
写代码怎么可能会不遇到bug呢,往往这个时候我们都需要灵活运用调试这个工具。
调试一方面可以协助我们观察某个语句执行时的的变量环境。常见运用情景如下:
当我们发现一个奇怪的输出,我们可以首先定位到执行这个输出的那个语句,主要思路就是先在这个语句处打个断点进行跳转,如果这个语句有多次循环,而我们的错误出现在循环之中,那么就多次进行跳转直到执行到出现差错的那个环境。然后使用编译器的调试环境去查看当前涉及这个语句的变量,找出意料之外的异常变量,然后根据这个遍历进行回溯。
调试另一方面也可以辅助我们进行同步调的操作。常见运用场景如下:
我上述的第一种是回溯思维解bug方法,而另一种稍微比较简单的就是随着调试一步步从头到尾进行查看,然后时刻监视我们的变量情况,直到发现异常变量值。这种方法可能会稍微漫长一些,一般我们会通过先回溯找到最近一次程序整体一致性比较完善的情况后,然后再顺序调试。
当然调试是一个经验性的东西,调试多了,很多时候都会有自己的小Tips。甚至对程序熟悉的话,看到错误基本就能反应过来错误原因,或者通过调整进行一两个反常变量的暗示就能立马反应过来。
五、分析链队列与循环队列的优缺点
链队列是我们许多库中对队列的基本封装,其最大优点在于空间的理论上是无限大,不用考虑判断满,而且操作上比较方便,但是要额外注意误删尾指针的情况,以及注意带头链队列与不带头链队列判空的差异。但是一个语言如果不存在相应的自带库的话,我们就需要额外创建一个链表,这个过程会比较麻烦,而且链表也是存在一定的数据冗余的。
循环队列整体来看因为顺序表受限的空间,导致其整体大小是有限的,需要判断满,而且需要利用循环特征对于之前的空间进行复用,并且因为原始循环队列满&空判断重叠,需要额外使用开销或者损耗来解决这个问题。但是循环队列易于实现,可以快速通过一个顺序表实现一个简易的循环队列,而我们得到一个链表后如果要临时改造为队列还需要进行遍历获取尾指针。(而且大部分语言并不存在自带的链表,额外创建个链表是很麻烦的,而顺序表大部分语言的数组都可以胜任)
总的来看,其实链队列无论是效率还是开销都要更加好些,而循环队列更多是一种环思想运用,本身还是有许多麻烦的地方。要是用于实战的话,我推荐链队列,但在一些低级的语言开发中或者限制库的快速编程环境下,我还是可以推荐循环队列的。
六、第 18 天建立的两个队列, 其区别仅在于基础数据不同, 一个是 int, 一个是 char. 按这种思路, 对于不同的基础数据类型, 都需要重写一个类, 这样合理吗? 你想怎么样?
这个问题这么说呢,一方面得看你数据类型的相近程度,如果大家都是原子类型。那么对于像C++这样强类型的语言,其实我们会使用template实现泛型编程,通过模糊化数据类型来实现适用更广环境的类,增加了类的易用性。但是博主接触Java的泛型编程不深,不敢妄做评价,具体大家可以看下这个文章java 泛型详解。此外对于那些类型模糊的脚本语言例如JavaScript和Python的话,似乎可以很方便实现数据的通用化处理。
另一方面,如果数据差别比较大,比如一个是原子类型一个是结构类型,或者是更其他抽象数据类型,那么这个时候再用泛型处理就显得笨重了,因为这个时候,不同对象对应的方法会存在一些不可调和的差异,这个时候我的建议的话,重新写个类是个不错的选择。
但是,当时看到这个问题一瞬间,我其实也想过用继承思想,但是后来想,这样似乎冗余性有点大,如果两个数据关联程度太低的话,这么做相当于给自己找麻烦。但是其实就int和char这两个数据的话,也许能试试,因为数据范围来说,char是int的子集,char队列的类继承int队列是可以实现重叠的,只不过可能要重写(Override)一些方法:
(注:这个重写视语言不同而定,就数据打印这个方法,C++的话,int数据是不能直接“+=”到string数据上的,必须先经历to_string()方法预处理,当然Java的话是int/char一视同仁的,见下)
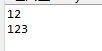
这是Java代码:
String testString = "1";
int testInt = 2;
char testChar = '3';
testString += testInt;
System.out.println(testString);
testString += testChar;
System.out.println(testString);Results:
而我们用C++的方式去完成:
string testString = "1";
int testInt = 2;
char testChar = '3';
testString += testInt;
cout << testString << endl;
testString += testChar;
cout << testString << endl;Results:

可见其把int数据按照字符表示了,得到与Java语言完成不同的结果,这个时候若我们将第五行代码改为testString += to_string(testInt) 便可解决问题。
我举这个例子的意图就是想说明:所以我们所言的char可以尝试继承int相关的类来实现重用也是要在视具体的语言而条件和方法的差异来进行相应方法的重写才行。