概率论与数理统计学习:随机变量(三)——知识总结与C语言实现案例
hello,大家好
这里是第五期概率论与数理统计的学习,我将用这篇博客去整理知识点以及用C语言去实现做题的过程。

注:关于用C语言实现做题的过程,这里不是去设计一个数学公式去做题,而是像平时写作业那样,先用书上的知识点去完成一个题目,然后再用C语言去得到题目的答案,过程可以有千千万万,只要能实现自己的想法就好。
下面开始知识点的总结。
随机变量函数的分布
随机变量的分布函数…等等
![]()
我们应该总结的是随机变量函数的分布吧?这两个咋这么像呢?
分布函数和函数分布之间有啥关系,又有啥区别呢?
先回顾一下随机变量的分布函数是个啥:
:随机变量的分布函数
最开始,对于离散型随机变量,我们是用分布律来刻画它的概率分布情况;对于连续型随机变量,我们是用概率密度来刻画它的概率分布情况。那么讲到这里也就大致明白分布函数是来干啥的了。没错!就是用来刻画离散型和连续型它俩的概率分布情况。
设 X X X是一随机变量(离散型和连续型都适用),称函数 F ( x ) = P { X ≤ x } , − ∞ < x < ∞ F(x)=P\{X\leq x\},-\infty
为 X X X的分布函数。关于它的具体性质可以点击分布函数
随机变量函数的分布
在一些试验中,我们所关心的量往往不能通过直接观测来得到,而它恰恰是某个能直接观测到的随机变量的已知函数。例如,我们能直接测量到一个圆的直径 D D D,而所关心的却是该圆的面积 S = ( D 2 ) 2 π S=(\frac{D}{2})^2\pi S=(2D)2π。那么,随机变量 S S S就是随机变量 D D D的函数。也就是我们已知随机变量 D D D的分布函数,来求函数 S = g ( D ) S=g(D) S=g(D)的分布。
总结:分布函数就是求随机变量 X X X的分布函数,函数的分布呢就是求另一个随机变量 Y Y Y的分布函数,而 Y Y Y是关于 X X X的函数。
怎么样,对这的理解有没有更深刻了一些?
☁️ 离散型随机变量函数的分布
定义:设离散型随机变量 X X X的概率分布为 P { X = x k } = p k , k = 1 , 2 , . . . P\{X=x_{k}\}=p_{k},k=1,2,... P{X=xk}=pk,k=1,2,..., g ( x ) g(x) g(x)是一个已知的单值函数,令 Y = g ( X ) Y=g(X) Y=g(X),则 Y Y Y也是一个离散型随机变量。
例如:
设随机变量 X X X有如下的概率分布
| X X X | -1 | 0 | 1 | 2 |
|---|---|---|---|---|
| p k p_{k} pk | 0.2 | 0.3 | 0.1 | 0.4 |
求随机变量 Y = ( X − 1 ) 2 Y=(X-1)^2 Y=(X−1)2的概率分布:
首先 Y Y Y的可能取得值为0,1,4。那么
P { Y = 0 } = P { X = 1 } = 0.1 P\{Y=0\}=P\{X=1\}=0.1 P{Y=0}=P{X=1}=0.1
P { Y = 1 } = P { X = 0 } + P { X = 2 } = 0.7 P\{Y=1\}=P\{X=0\}+P\{X=2\}=0.7 P{Y=1}=P{X=0}+P{X=2}=0.7
P { Y = 4 } = P { X = − 1 } = 0.2 P\{Y=4\}=P\{X=-1\}=0.2 P{Y=4}=P{X=−1}=0.2
可以得到 Y Y Y得概率分布为:
| Y | 0 | 1 | 4 |
|---|---|---|---|
| q i q_{i} qi | 0.1 | 0.7 | 0.2 |
☁️ 连续型随机变量函数的分布
对于连续型随机变量 X X X,我们先给出一个具体例子,再总结求 Y = g ( X ) Y=g(X) Y=g(X)的基本方法:
例子:设随机变量 X X X~ N ( 0 , 1 ) , Y = e x N(0,1),Y=e^x N(0,1),Y=ex,求 Y Y Y的概率密度函数
设 F ( y ) , f ( y ) F(y),f(y) F(y),f(y)分别为随机变量 Y Y Y的分布函数和概率密度函数
当 y ≤ 0 y\leq 0 y≤0时,有 F ( y ) = P { Y ≤ y } = P { e X ≤ y } = P { ∅ } = 0 F(y)=P\{Y\leq y\}=P\{e^X\leq y\}=P\{\varnothing\}=0 F(y)=P{Y≤y}=P{eX≤y}=P{∅}=0
当 y > 0 y>0 y>0时,因为 g ( x ) = e x g(x)=e^x g(x)=ex是 x x x的严格单调递增函数,有: F ( y ) = P { Y ≤ y } = P { e X ≤ y } = P { X ≤ l n y } = 1 2 π ∫ − ∞ l n y e − x 2 2 d x F(y)=P\{Y\leq y\}=P\{e^X\leq y\}=P\{X\leq lny\}=\frac{1}{\sqrt{2\pi}}\int_{-\infty}^{lny}e^{-\frac{x^2}{2}}dx F(y)=P{Y≤y}=P{eX≤y}=P{X≤lny}=2π1∫−∞lnye−2x2dx
然后由 f ( y ) = F ′ ( y ) f(y)=F^{'}(y) f(y)=F′(y),可以得到 f ( y ) = { 1 2 π y e − ( l n y ) 2 2 , y > 0 0 , y ≤ 0 f(y)=\begin{cases} \frac{1}{\sqrt{2\pi}y}e^{-\frac{(lny)^2}{2}},y >0\\ 0~~~~~~~~~~~~~~~~~~,y\leq 0\\ \end{cases} f(y)={2πy1e−2(lny)2,y>00 ,y≤0
总结:就是先将 Y Y Y转换成关于 X X X的函数,然后所求的就是 X X X的分布函数,最后再对这个函数求导即可求出 Y Y Y的概率密度函数。
提问:
为啥直接就 f ( y ) = F ′ ( y ) f(y)=F^{'}(y) f(y)=F′(y)啦?发生了甚么???
![]()
这里就要从连续型随机变量的概率密度函数说起了。
总所周知, P { a < X ≤ b } = ∫ a b f ( x ) d x P\{a
而分布函数中, F ( X ) = P { X ≤ x } = ∫ − ∞ x f ( x ) d x F(X)=P\{X\leq x\}=\int_{-\infty}^xf(x)dx F(X)=P{X≤x}=∫−∞xf(x)dx,这时, F ′ ( X ) = f ( x ) F^{'}(X)=f(x) F′(X)=f(x)。
如果你还要问为啥,可能是表述能力不太行,也可能是你没学过高数的原因
![]()
等等哈,上面的描述都是针对于连续型随机变量的,千万别搞错了哟!
☀️ 定理
若随机变量 X X X有概率密度函数 f ( x ) , x ∈ ( − ∞ , + ∞ ) , y = g ( x ) f(x),x\in(-\infty,+\infty),y=g(x) f(x),x∈(−∞,+∞),y=g(x)为严格单调函数,且 g ′ ( x ) g^{'}(x) g′(x)对一切 x x x都存在,记 ( a , b ) (a,b) (a,b)为 g ( x ) g(x) g(x)的值域, x = h ( y ) x=h(y) x=h(y)为 y = g ( x ) y=g(x) y=g(x)的反函数,则随机变量 Y = g ( X ) Y=g(X) Y=g(X)的概率密度函数为 f ( y ) = { f [ h ( y ) ] [ h ′ ( y ) ] , a < y < b 0 , 其它 f(y)=\begin{cases} f[h(y)][h^{'}(y)],a
上面这个呢,只是比较官方的解释,自己能理解上面示例的过程即可,不用太纠结。
 知识总结到这里就结束啦~~下面就开始用做题并用C语言实现过程了喔。
知识总结到这里就结束啦~~下面就开始用做题并用C语言实现过程了喔。
C语言实现具体案例
首先呢,就拿最开始那个简单的离散型随机变量函数分布的例子来用C语言实现!好久没用结构体了,整点骚的,直接上代码:
#include 
离散型随机变量函数的分布做了一个,下面就来一个连续型随机变量的题
- 设随机变量 X X X有概率密度函数 f ( x ) = { ∣ x ∣ , − 1 < x < 1 0 , 其它 f(x)=\begin{cases} |x|,-1
求随机变量 Y = 2 X + 1 Y=2X+1 Y=2X+1的概率密度函数。
分析:这个题的思路就跟着上面例题那样就好。 F ( y ) = P { Y ≤ y } = P { 2 X + 1 ≤ y } = P { X ≤ y − 1 2 } = P ∫ − ∞ y − 1 2 f ( x ) d x F(y)=P\{Y\leq y\}=P\{2X+1\leq y\}=P\{X\leq \frac{y-1}{2}\}=P\int_{-\infty}^{\frac{y-1}{2}}f(x)dx F(y)=P{Y≤y}=P{2X+1≤y}=P{X≤2y−1}=P∫−∞2y−1f(x)dx
然后再由定理得出即可。
em…但是由于连续型随机变量总是涉及到求导与积分,个人技术有限,还不能表示出来,不过也在努力中~~~
![]()
- 设随机变量 X X X的分布函数为 F ( x ) = { 0 , x < − 1 0.3 , − 1 ≤ x < 1 0.8 , 1 ≤ x < 2 1 , x ≥ 2 F(x)=\begin{cases} 0~~~~~~~~,x<-1\\ 0.3~~~~~,-1\leq x<1\\ 0.8~~~~~,1\leq x<2\\ 1~~~~~~~~,x\geq 2\\ \end{cases} F(x)=⎩ ⎨ ⎧0 ,x<−10.3 ,−1≤x<10.8 ,1≤x<21 ,x≥2
1)求 X X X的概率分布
2)求 Y = ∣ X ∣ Y=|X| Y=∣X∣的概率分布
分析:由上图随机变量 X X X的分布函数可知它是一个离散型的随机变量。那么这个题也就好做了,直接上代码:
#include 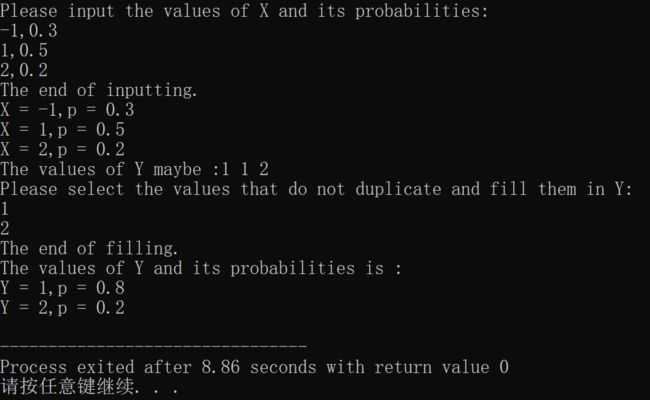
这期学习到这里就结束啦

下次再见!