地图图像迁移研究与实现
快速图像颜色迁移
传统的图像颜色迁移是通过计算目标图像和源图像的颜色直方图,优化二者之间的差值,从而实现不更改内容,完成颜色的迁移。其核心在于如何找到颜色间的关系映射。一般情况的研究会现将RGB空间转化为更复杂、对色彩的支持度更佳的其他色彩空间,如HSV、Lab等。为了获取匹配规则,一般需要对图像进行色彩信息统计,可以是局部特征统计,也可以是全局。一般的特征统计计算的是色彩直方图信息,局部特征提取可以通过聚类来实现,或者是特征部分如角点、边缘、背景、Blob等。考虑到色彩之间存在语义信息,也会对不同色彩之间进行权重修正或是不同语义采用不同的算法来计算两幅图像之间的差异。
Reinhard提出的算法(2001)步骤大致如下:
-
输入目标图像和源图像
-
将源图像和目标图像转化到Lab颜色空间,Lab颜色空间模拟感知均匀性,其中颜色量的微小变化会产生颜色重要性的相对变化。Lab空间在模仿人类如何解释颜色上做的比RGB更好
-
分离源图像和目标图像的通道
-
计算图像每个通道的平均值和标准差
-
利用标准差做缩放
-
I n e w = ( I t a r g e t − M E A N t a r g e t ) ∗ S T D t a r g e t S T D s o u r c e + ( M E A N s o u r c e ) I_{new}=(I_{target}-MEAN_{target})*\frac{STD_{target}}{STD_{source}}+(MEAN_{source}) Inew=(Itarget−MEANtarget)∗STDsourceSTDtarget+(MEANsource)
-
裁剪输出范围至[0,255]
-
融合通道并转回RGB空间
实现代码
import numpy as np
import cv2
def getImageStatistic(img):
# 获取通道的统计信息
# 相当于img[...,0]...
l,a,b=cv2.split(img)
lM,lS=l.mean(),l.std()
aM,aS=a.mean(),a.std()
bM,bS=b.mean(),b.std()
return [lM,lS,aM,aS,bM,bS]
def colorTransfer(source,target,needmask=False):
if needmask:
mask,edge=changeBackColor(target)
# # 边缘需要提取下
# target_edge=cv2.bitwise_and(target,target,mask=edge)
# 通道转化
source=cv2.cvtColor(source,cv2.COLOR_BGR2LAB).astype("float32")
target=cv2.cvtColor(target,cv2.COLOR_BGR2LAB).astype("float32")
# 分离通道并获取统计信息
source_list=getImageStatistic(source)
target_list=getImageStatistic(target)
# 缩放图像
LAB=[i for i in cv2.split(target)]
for i in range(3):
LAB[i]=np.clip((LAB[i]-target_list[i*2])*(target_list[i*2+1]/source_list[i*2+1])+source_list[i*2],0,255)
# 合并通道
new=cv2.merge(LAB)
# 转回RGB并使用8位无符号整形
new=cv2.cvtColor(new.astype("uint8"),cv2.COLOR_Lab2BGR)
# 获取掩膜区域外的数据
cv2.imshow("new",new)
if needmask:
new=cv2.bitwise_and(new,new,mask=mask) # 在掩膜范围内做按位与
# 掩膜白色相当于逻辑1,黑色相当于逻辑0
# 在白色部分也就是逻辑1部分进行运算,其他部分不参与运算
# 替换黑色
new[mask==0]=np.array([255,255,255])
# new[edge!=0]=np.array([0,0,0])
return new
def changeBackColor(img):
# 如何修正背景色?
# 可以选择边界提取算法来做
# 也可以选择腐蚀+高斯算法
# 获取边界
upper = np.array([255, 255, 255])
lower = np.array([200, 80, 180])
mask = cv2.inRange(img, lower, upper) # 在区域内就是255,否则是0
# 腐蚀
erode=cv2.erode(mask,kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3))
,iterations=10) # 分离连接
# 膨胀
dilate=cv2.dilate(erode,kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3))
,iterations=10) # 孤岛填充
# 黑色是需要剔除的,所以要按位取反
mask = cv2.bitwise_not(mask, mask)
cv2.imshow("mask", mask)
# 高斯滤波去除噪声
blurred = cv2.GaussianBlur(img, (3, 3), 0)
gray = cv2.cvtColor(blurred, cv2.COLOR_BGR2GRAY)
# X Gradient cv.CV_16SC1所对应的数据类型必须是整型
# 获取两个方向梯度
xgrad = cv2.Sobel(gray, cv2.CV_16SC1, 1, 0)
# Y Gradient
ygrad = cv2.Sobel(gray, cv2.CV_16SC1, 0, 1)
# edge,50、150分别是低阈值和高阈值
edge_output = cv2.Canny(xgrad, ygrad, 50, 150)
cv2.imshow("edge", edge_output)
return mask,edge_output
if __name__ == '__main__':
tar=cv2.imread(r"C:\Users\lenovo\Desktop\gif\img\04.jpg")
src=cv2.imread(r"C:\Users\lenovo\Desktop\gif\img\02.jpg")
try:
cv2.imshow('src',src)
cv2.imshow('tar',tar)
new=colorTransfer(src,tar,True)
cv2.imshow('result',new)
cv2.waitKey(0)
cv2.destroyAllWindows()
except:
print("Your path is error")
new = colorTransfer(src, tar)
结果展示
迁移图像

目标图像

结果图像

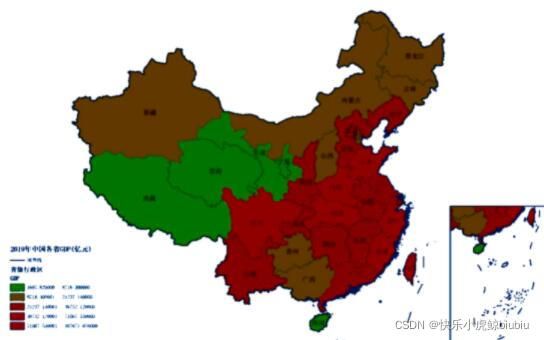
专题地图迁移
迁移图像

目标地图
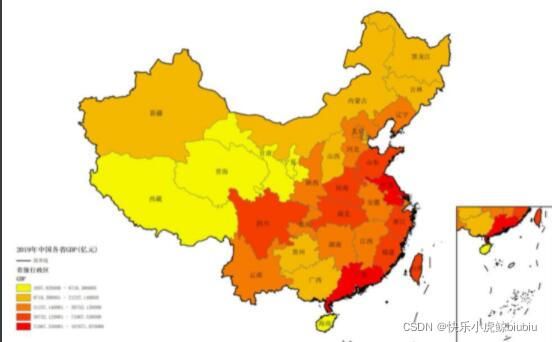
结果展示
图像风格迁移
图像风格迁移顾名思义,就是将别的图像的风格迁移到内容图像上去。这一思想一经提出,无论是学术界还是艺术界,都伸出了橄榄枝。
图像风格迁移又能分成固定风格固定内容的普通迁移和固定风格不限内容的快速迁移。
固定风格固定内容的迁移
该思想最早是由图宾根大学的研究学者提出,核心在于将图片作为可训练的变量,通过不断优化图片的像素值,降低其与内容图片的内容差异,并降低其与风格图片的差异。


在该研究中,通过提取VGG16网络的第0、5、10、19、28层卷积层作为需要比对的风格特征。而21层则是需要比对的内容特征。
在21层也就是conv4_2层上,计算特征映射的相似性作为图像的内容损失:
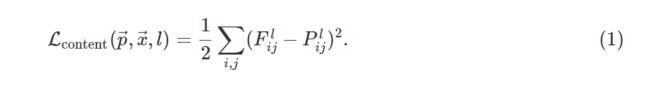
其中 l l l表示特征映射的层数, F F F和 P P P是目标图像和内容图像在对应卷积层输出的特征向量。
损失函数求导后是这个样:

一般来说,目标图像可以是噪声,也可以是初始图像的副本。为了方便训练,一般选用副本。
图像的风格损失主要是通过Gram矩阵进行计算的。Gram矩阵通过计算特征映射,将其转为列向量,在用该列向量乘以其转置获得,能够更好的表示图片的风格。(风格是一种潜在的整体特征,而Gram矩阵能够提取这种特征)
运作方法如下:
# 假设A是个数据,shape为[batch,deep,heigh,width]
A=torch.Tensor(1,21,300,300)
# 获取其列向量
# 相当于把内容融合了
A=A.view(1,21,300*300)
# 最后计算Gram矩阵
gram=torch.mm(A,A.t())
风格损失呢,可以这样去评估
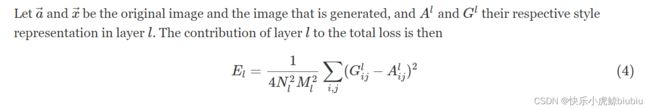
N l N_l Nl和 M l M_l Ml对应特征映射的宽高
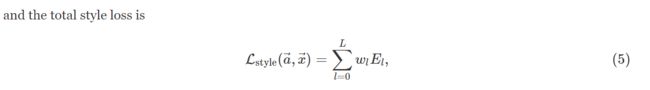
w l w_l wl表示每层的权重
求偏导后是这样

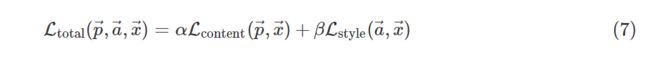
总损失则是由内容损失和风格损失加权得到。
实现代码
import torch
from torchvision import models
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import requests
from torchvision import transforms
import time
import hiddenlayer as hl
from skimage.io import imread
# 使用VGG19网络构建特征
vgg19=models.vgg19(pretrained=True)
# 不需要网络分类器,只用卷积层和池化层
vgg=vgg19.features
# 设置显卡
device=torch.device("cuda:0")
# 将VGG19的特征提取网络权重冻结,训练不进行更新
for param in vgg.parameters():
param.requires_grad_(False)
vgg=vgg.to(device)
# 定义图像读取函数,将图像进行相应转化
def load_image(img_path,max_size=400,shape=None):
image=Image.open(img_path).convert("RGB")
size=max_size if max(image.size)>max_size else max(image.size)
# 指定尺寸需要转化
if shape is not None:
size=shape
# 进行图像数据转化
in_transform=transforms.Compose(
[transforms.Resize(size),
transforms.ToTensor(),
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))]
)
# 使用RGB通道,并升维到[b,c,h,w]
image=in_transform(image)[:3,...].unsqueeze(dim=0)
return image.to(device)
# 定义可视化图像函数
def im_convert(tensor):
# [1,c,h,w]->[c,h,w]
image=tensor.data.cpu().numpy().squeeze()
# [c,h,w]->[h,w,c]
image=image.transpose(1,2,0)
# 逆标准化
image=image*np.array((0.229,0.224,0.225))+np.array((0.485,0.456,0.406))
# 裁剪图片到[0,1]
image=image.clip(0,1)
return image
# 读取内容和风格图像
content=load_image(r"C:\Users\lenovo\Desktop\新建文件夹\图片\03.jpg")
print("content shape:",content.shape)
style=load_image(r"C:\Users\lenovo\Desktop\新建文件夹\渲染\03.jpg",shape=content.shape[-2:])
print("Style'shape:",style.shape)
fig,(ax1,ax2) = plt.subplots(1,2,figsize=(12,5))
ax1.imshow(im_convert(content))
ax1.set_title("Content")
ax2.imshow(im_convert(style))
ax2.set_title("Style")
plt.show()
# 定义函数,获取图像在网络上指定层的输出
def get_features(image,model,layers=None):
# 获取指定layer的输出
# lyaers参数指定需要用于图像内容和样式表示的图层
# 没有指定就使用默认的层
if layers is None:
layers={
'0':'conv1_1',
'5':'conv2_1',
'10':'conv3_1',
'19':'conv4_1',
'21':'conv4_2',
'28':'conv5_1',
}
# 获取的每层特征保存到字典中
features={}
x=image
for name,layer in model._modules.items():
# 从第一层开始获取图像特征
x=layer(x)
# 如果是指定层的特征就保存
if name in layers:
features[layers[name]]=x
return features
# 通过Gram矩阵来评价两幅图像是否具有相同风格
def gram_matrix(tensor):
'''
Gram矩阵表示图像的风格特征,在保证内容的情况下,进行风格传输
'''
_,d,h,w=tensor.size()
# 改变维度为(深度,高*宽)
tensor=tensor.view(d,h*w)
# 计算gram矩阵
gram=torch.mm(tensor,tensor.t())
return gram
# 计算第一次训练之前的内容特征和风格特征
content_features=get_features(content,vgg)
style_features=get_features(style,vgg)
# 计算每层的Gram矩阵,用于表示风格
style_grams={layer:gram_matrix(style_features[layer]) for layer in style_features}
# 使用内容图像的副本创建一个目标图像,训练时对目标图像进行调整
target=content.clone().requires_grad_(True)
# 定义每个样式层的权重
style_weights={'conv1_1':1.,
'conv2_1':0.75,
'conv3_1':0.2,
'conv4_1':0.2,
'conv5_1':0.2}
alpha=1
beta=1e6
content_weight=alpha
style_weight=beta
# conv4 2用于度量图像内容相似性
# 每1000次迭代输出一个中间结果
show_every=1000
# 保存损失
total_loss_all=[]
content_loss_all=[]
style_loss_all=[]
# 使用Adam优化器
optimizer=optim.Adam([target],lr=0.0003)
step=50000
t0=time.time()
for i in range(1,step+1):
# 获取图像特征
target_features=get_features(target,vgg)
# 计算内容损失
content_loss=torch.mean((target_features['conv4_2']-content_features['conv4_2'])**2)
# 计算风格损失
style_loss=0
# 把每个层的Gram矩阵相加
for layer in style_weights:
# 计算要生成的图像风格表示
target_feature=target_features[layer]
# [d,h*w]
target_gram=gram_matrix(target_feature)
_,d,h,w=target_feature.shape
# 获得风格在每层的Gram矩阵
style_gram=style_grams[layer]
# 计算损失
layer_style_loss=style_weights[layer]*torch.mean((target_gram-style_gram)**2)
# 累加计算风格差异
# 每个像素点
style_loss+=layer_style_loss/(d*h*w)
# 总损失等于风格损失加上内容损失
total_loss=content_weight*content_loss+style_weight*style_loss
# 保留三种损失大小
content_loss_all.append(content_loss.item())
style_loss_all.append(style_loss.item())
total_loss_all.append(total_loss.item())
# 更新需要生成的图像
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 输出show_ecvery次数厚度图像
if i%show_every==0:
print("Total loss",total_loss.item())
print("Use time: ",(time.time()-t0)/3600,"hour")
newim=im_convert(target)
plt.imshow(newim)
plt.title("Iteration: "+str(i)+"times")
plt.show()
# 保存图片
result=Image.fromarray((newim*255).astype(np.uint8))
result.save(r"C:\Users\lenovo\Desktop\新建文件夹\结果\Map_Result"+str(i)+".bmp")
# 结果可视化
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(total_loss_all,'r',label='total_loss')
plt.legend()
plt.title("total loss")
plt.subplot(1,2,2)
plt.plot(content_loss_all,'g-',label="content_loss")
plt.plot(style_loss_all,'b-.',label="style_loss")
plt.legend()
plt.title("Content and Style loss")
plt.show()
结果展示
内容图片
风格图片

渲染图片

对抗生成网络
GAN
GAN的核心在于生成器和判别器的勾心斗角。
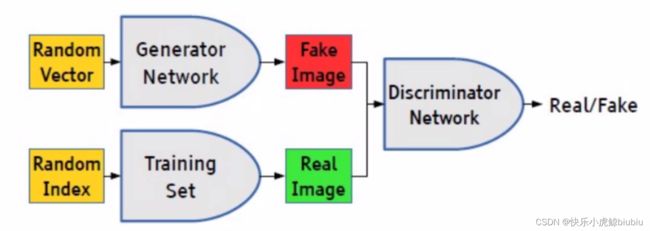
BCELOSS
如何去评估模型的效果?对于判别器来说,会出现正负值,我们先将其映射到[0,1]区间,接着根据信息熵的计算公式来得到损失函数:
l o s s ( o , t ) = − 1 / n ∑ i ( t [ i ] ∗ l o g ( o [ i ] ) + ( 1 − t [ i ] ) ∗ l o g ( 1 − o [ i ] ) ) loss(o,t)=-1/n\sum_{i}(t[i]*log(o[i])+(1-t[i])*log(1-o[i])) loss(o,t)=−1/ni∑(t[i]∗log(o[i])+(1−t[i])∗log(1−o[i]))
实现代码
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
# 创建文件夹,用来存放数据
os.makedirs("images",exist_ok=True)
# 创建全局参数
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=100, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=128, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args()
# 图像形状 : (c,h,w)
img_shape=(opt.channels,opt.img_size,opt.img_size)
# 是否调用GPU
cuda=True if torch.cuda.is_available() else False
# 生成器
class Generator(nn.Module):
def __init__(self):
# 生成器要做的就是把随机噪声转化为图像像素
super(Generator, self).__init__()
def block(in_feat,out_feat,normalize=True):
# in: 初始化随机噪声
# out: 指定神经元输出
# 做个最简单的全连接
layers=[nn.Linear(in_feat,out_feat)]
if normalize:
# batch初始化
layers.append(nn.BatchNorm1d(out_feat,0.8))
# leakrelu激活函数
layers.append(nn.LeakyReLU(0.2,inplace=True))
return layers
self.model=nn.Sequential(
*block(opt.latent_dim,128,normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
# 转化到图像大小
# 即: c*h*w
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self,z):
# 生成fake图像
img=self.model(z)
# 将展平的scalar变成图像格式
img=img.view(img.size(0),*img_shape)
return img
# 判别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model=nn.Sequential(
# 判别器要做的就是识别图像状态
nn.Linear(int(np.prod(img_shape)),512),
nn.LeakyReLU(0.2,inplace=True),
nn.Linear(512,256),
nn.LeakyReLU(0.2,inplace=True),
nn.Linear(256,1),
# 需要映射到01
nn.Sigmoid()
)
def forward(self,img):
img_flat=img.view(img.size(0),-1)
validity=self.model(img_flat)
return validity
# 损失函数
# 用的是BCEloss
# 即计算样本正确识别信息熵
loss=torch.nn.BCELoss()
# 创建生成器
gen=Generator()
dis=Discriminator()
if cuda:
gen.cuda()
dis.cuda()
loss.cuda()
# 创建MNIST数据集
os.makedirs("./data/mnist", exist_ok=True)
dataloader = DataLoader(
datasets.MNIST(
"./data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# 定义优化器
opt_G=torch.optim.Adam(gen.parameters(),lr=opt.lr,betas=(opt.b1, opt.b2))
opt_D=torch.optim.Adam(dis.parameters(),lr=opt.lr,betas=(opt.b1, opt.b2))
Tensor=torch.cuda.FloatTensor if cuda else torch.FloatTensor
# -------
# 训练
# -------
for epoch in range(opt.n_epochs):
for i,(imgs,_) in enumerate(dataloader):
# 验证数据表
valid=Variable(Tensor(imgs.size(0),1).fill_(1.0),requires_grad=False)
fake=Variable(Tensor(imgs.size(0),1).fill_(0.0),requires_grad=False)
# 真实影像
real_imgs=Variable(imgs.type(Tensor))
# ----------
# 训练生成器
# ----------
opt_G.zero_grad()
# 创建随机噪声
z=Variable(Tensor(np.random.normal(0,1,(imgs.shape[0],opt.latent_dim)))) # imgs:(128,1,28,28) z:(128,100)
# 生成batch图片
gen_imgs=gen(z)
# 计算生成器能够骗过判别器的能力
g_loss = loss(dis(gen_imgs), valid)
g_loss.backward()
opt_G.step()
# ---------------------
# 训练判别器
# ---------------------
opt_D.zero_grad()
# 计算判别器对真实数据的敏感度
real_loss = loss(dis(real_imgs), valid)
# 计算判别器识别虚假数据的敏感度
fake_loss = loss(dis(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
opt_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
结果展示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jX2J0eIl-1647692130208)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20220318011258706.png)]
训练生成的图像已经能够以假乱真了。
CyCleGAN
CycleGAN区别于其他网络,不需要图像配对(Paired)即可对目标图像进行风格与颜色的迁移。
CycleGAN能做什么?

CycleGAN网络架构
循环架构能够保证生成的图像与源图像有关系。 G A B G_{AB} GAB用于将源图像生成目标图像,该目标图像进入判别器与真时图像进行比对。同时,为了保证图像间的关联,还需要通过 G B A G_{BA} GBA网络将目标图像还原至与源图像相似的图像,并衡量最后结果与源图像的相似程度。
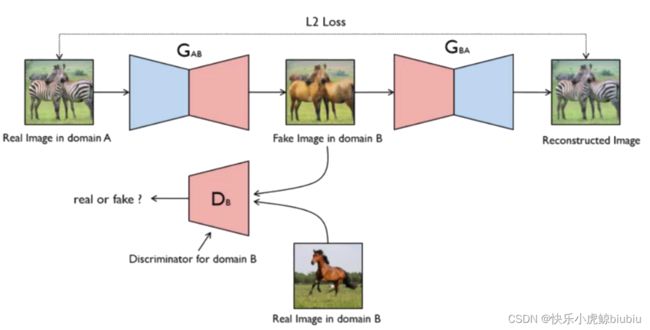
G B A G_{BA} GBA在其中也有着非常重要的作用,同样需要经过训练。
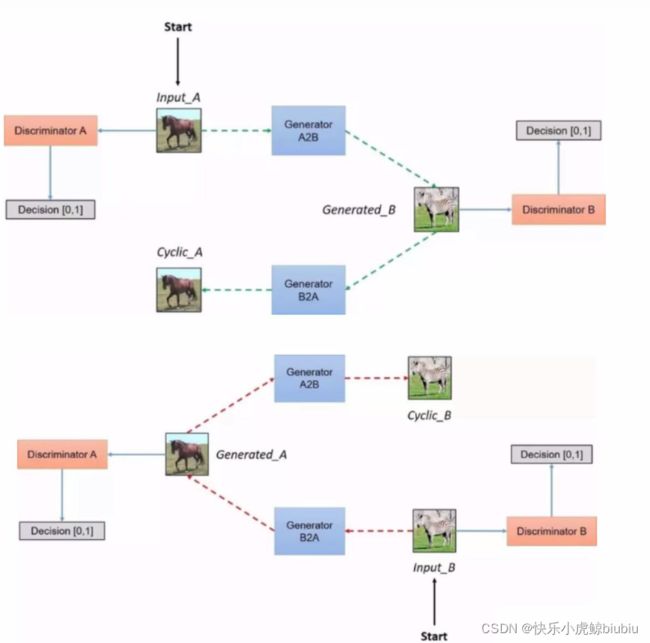
在整体网络架构中,通过颠倒目标图像与源图像的方式,能够对循环生成器进行训练。
损失函数
- 生成器损失
- 判别器损失
- 循环损失
- 映射损失(将生成图像再通过生成器,看二次生成与一次生成的差别)
重点代码详解
结果展示
样本类A示例

样本类B示例
生成器结果示例
