FlinkCDC-Hudi:Mysql数据实时入湖全攻略一:初试风云
一、背景
FlinkCDC是基于Flink开发的变化数据获取组件(Change data capture),目前支持mysql、PostgreSQL、mongoDB、TiDB、Oracle等数据库的同步。
 Hudi是一个流式数据湖平台,使用Hudi可以直接打通数据库与数据仓库,Hudi可以连通Hadoop、hive,支持对数据record粒度的增删改查。Hudi支持同步数据入库,提供了事务保证、索引优化,是打造实时数仓、实时湖仓一体的新一代技术。
Hudi是一个流式数据湖平台,使用Hudi可以直接打通数据库与数据仓库,Hudi可以连通Hadoop、hive,支持对数据record粒度的增删改查。Hudi支持同步数据入库,提供了事务保证、索引优化,是打造实时数仓、实时湖仓一体的新一代技术。

本文尝试使用FlinkCDC同步Mysql数据,通过Hudi实时同步数据到Hadoop/Hive,为下游用户提供实时数据查询。
二、测试版本说明
flink:1.13.5
hadoop:3.1.4
hive: 3.1.2
hudi: release-0.10.1
mysql: 5.7.29
java: 1.8.0_181
scala:2.11
spark: 3.1.2
三、系统环境变量
export JAVA_HOME=/data/software/jre1.8.0_91
export HADOOP_HOME=/data/software/hadoop
export HADOOP_CONF_DIR=/data/software/hadoop/conf
export YARN_CONF_DIR=/data/software/hadoop/conf
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`四、Hudi源码编译
4.1 源码下载
git clone https://github.com/apache/hudi.git4.2 版本适配
- 0.9.0(git分支:release-0.9.0)适配 flink 1.12.x
- 0.10.0(git分支:release-0.10.0) 适配 flink 1.13.x(建议直接用master分支进行编译,目前master已经到0.11.0,0.10中有些bug在master才解决)
4.3 文件修改
修改hudi/pom.xml,在properties修改hadoop、hive版权为自己的版本
3.1.4
3.1.2
##同时编译对应的hudi-spark-hundle时注意修改对应的spark版本,以免后续与spark整合时踩坑
${spark3.version}
2.4.4
3.1.2 修改hudi/packaging/hudi-flink-bundle/pom.xml, 在profiles中将flink-bundle-shade-hive3的hive.version修改为自己的版本。如果是hive1.x则修改flink-bundle-shade-hive1,hive2.x则修改flink-bundle-shade-hive2。
4.4 执行编译
hudi> mvn clean install -DskipTests -D rat.skip=true -P flink-bundle-shade-hive3
如果不修改pom可以在mvn中增加编译属性
hudi> mvn clean install -DskipTests -D rat.skip=true -D scala-2.11 -D hadoop.version=3.1.4 -D hive.version=3.1.2 -P flink-bundle-shade-hive3 -P spark3.1.x首次编译用时1小时左右,编译成功后再次编译用时在15分钟左右。
说明:编译时增加-Pspark2,-Pspark3.1.x,-Pspark3对编译对应的hudi-spark-bundle版本。
4.5 编译异常
编译时module:hudi-integ-test分经常出错,找不到依赖或找不到符号。这时分导致整个项目编译失败。
[WARNING] warning: While parsing annotations in C:\Users\zhang\.m2\repository\org\apache\spark\spark-core_2.11\2.4.4\spark-core_2.11-2.4.4.jar(org/apache/spark/rdd/RDDOperationScope.class), could not find NON_NULL in enum .
[INFO] This is likely due to an implementation restriction: an annotation argument cannot refer to a member of the annotated class (SI-7014).
[ERROR] D:\IdeaProject\hudi\hudi-integ-test\src\main\scala\org\apache\hudi\integ\testsuite\utils\SparkSqlUtils.scala:518: error: Symbol 'term com.fasterxml.jackson.annotation' is missing from the classpath.
[ERROR] This symbol is required by ' '.
[ERROR] Make sure that term annotation is in your classpath and check for conflicting dependencies with `-Ylog-classpath`.
[ERROR] A full rebuild may help if 'RDDOperationScope.class' was compiled against an incompatible version of com.fasterxml.jackson.
[ERROR] .map(record => {
[ERROR] ^
[WARNING] one warning found
[ERROR] one error found


由于hudi-integ-test是专项的测试模块,不用于项目实践,可以直接跳过这个模块的编译。修改hudi/pom.xml,将modules里的测试模块注释掉。
hudi-common
hudi-cli
hudi-client
hudi-aws
hudi-hadoop-mr
hudi-spark-datasource
hudi-timeline-service
hudi-utilities
hudi-sync
packaging/hudi-hadoop-mr-bundle
packaging/hudi-hive-sync-bundle
packaging/hudi-spark-bundle
packaging/hudi-presto-bundle
packaging/hudi-utilities-bundle
packaging/hudi-timeline-server-bundle
packaging/hudi-trino-bundle
docker/hoodie/hadoop
hudi-examples
hudi-flink
hudi-kafka-connect
packaging/hudi-flink-bundle
packaging/hudi-kafka-connect-bundle
再次编译后项目编译成功。
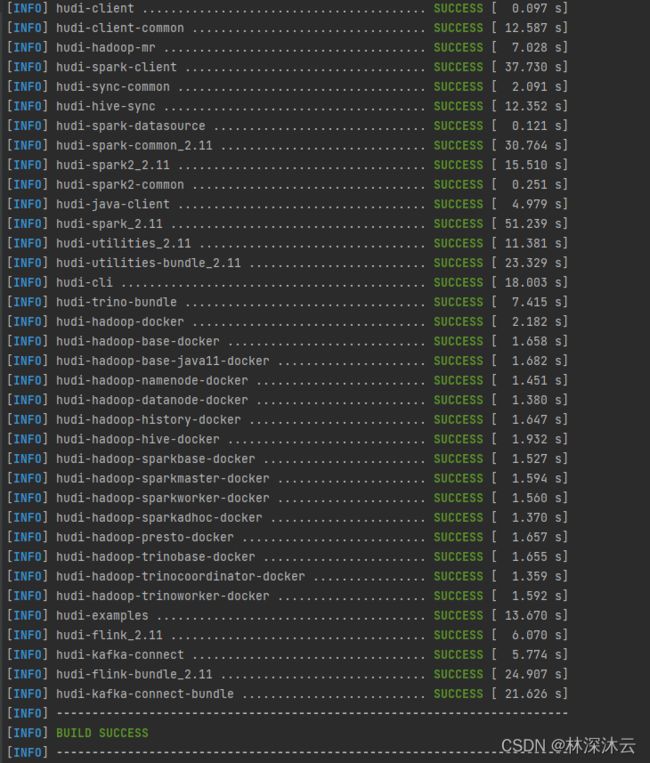
备注:
1、编译时遇到RAT异常时,可以在编译参数中增加-D rat.skip=true来跳过RAT检验。
[ERROR] Failed to execute goal org.apache.rat:apache-rat-plugin:0.12:check (default) on project hudi-examples: Too many files with unapproved license: 4
See RAT report in: D:\Workspace\Apache\apache-hudi\hudi-examples\target\rat.txt -> mvn clean install -DskipTests -D rat.skip=true4.6 编译结果
主要使用两个文件:
1、hudi-flink-bundle_2.11-0.10.0.jar,用于flink读写hudi数据,文件位置:hudi/packaging/hudi-flink-bundle/target/hudi-flink-bundle_2.11-0.10.0.jar。
2、hudi-hadoop-mr-bundle-0.10.0.jar,用于hive读取hudi数据,文件位置:hudi/packaging/hudi-hadoop-mr-bundle/target/hudi-hadoop-mr-bundle-0.10.0.jar
五、FlinkCDC编译
5.1 源码下载与编译
git clone https://github.com/ververica/flink-cdc-connectors.git
flink-cdc-connectors> mvn clean install -DskipTests5.2 编译结果
获取mysql cdc相关的文件:
flink-format-changelog-json/target/flink-format-changelog-json-2.2-SNAPSHOT.jar
flink-sql-connector-mysql-cdc/target/flink-sql-connector-mysql-cdc-2.2-SNAPSHOT.jar
六、Flink配置
修改FLINK_HOME/conf下的配置文件
6.1 flink-conf.yaml配置
taskmanager.numberOfTaskSlots: 4
#状态管理
state.backend: rocksdb
state.backend.incremental: true
state.checkpoints.dir: hdfs://cluster_namespace/tmp/flink/checkpoints
#类加载
classloader.check-leaked-classloader: false
classloader.resolve-order: parent-first
#on yarn配置, cluster_namespace为hdfs命名空间
rest.address: cluster_namespace
jobmanager.rpc.address: cluster_namespace
jobmanager.archive.fs.dir: hdfs://cluster_namespace/tmp/flink/completed-jobs/
historyserver.archive.fs.dir: hdfs://cluster_namespace/tmp/flink/completed-jobs/6.2 sql-client-defaults.yaml配置
execution:
planner: blink
type: streaming
6.3 FLINK_HOME/lib下添加依赖
# flinkcdc编译文件
flink-format-changelog-json-2.2-SNAPSHOT.jar
flink-sql-connector-mysql-cdc-2.2-SNAPSHOT.jar
# flinkcdc依赖
flink-sql-connector-kafka_2.11-1.13.5.jar
#HADOOP_HOME/lib下拷贝
hadoop-mapreduce-client-common-3.1.1.3.1.4.0-315.jar
hadoop-mapreduce-client-core-3.1.1.3.1.4.0-315.jar
hadoop-mapreduce-client-jobclient-3.1.1.3.1.4.0-315.jar
# hudi编译文件
hudi-flink-bundle_2.11-0.10.0.jar
七、启动flink yarn session服务
7.1 启动命令
flink-1.13.5$ ./bin/yarn-session.sh -s 4 -jm 1024 -tm 2048 -nm flink-hudi -d7.2 启动异常1:guava包异常,报NoSuchMethodError
异常提示:java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument
The program finished with the following exception:
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.lang.reflect.InvocationTargetException
at org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl.getClient(RpcClientFactoryPBImpl.java:81)
at org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC.getProxy(HadoopYarnProtoRPC.java:48)
at org.apache.hadoop.yarn.client.RMProxy$1.run(RMProxy.java:151)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:360)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1710)
at org.apache.hadoop.yarn.client.RMProxy.getProxy(RMProxy.java:147)
at org.apache.hadoop.yarn.client.RMProxy.newProxyInstance(RMProxy.java:134)
at org.apache.hadoop.yarn.client.RMProxy.createRMProxy(RMProxy.java:102)
at org.apache.hadoop.yarn.client.ClientRMProxy.createRMProxy(ClientRMProxy.java:72)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.serviceStart(YarnClientImpl.java:216)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.flink.yarn.YarnClusterClientFactory.getClusterDescriptor(YarnClusterClientFactory.java:83)
at org.apache.flink.yarn.YarnClusterClientFactory.createClusterDescriptor(YarnClusterClientFactory.java:61)
at org.apache.flink.yarn.YarnClusterClientFactory.createClusterDescriptor(YarnClusterClientFactory.java:43)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:582)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$4(FlinkYarnSessionCli.java:860)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:860)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl.getClient(RpcClientFactoryPBImpl.java:78)
... 21 more
Caused by: java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1358)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1339)
at org.apache.hadoop.conf.Configuration.setClass(Configuration.java:2672)
at org.apache.hadoop.ipc.RPC.setProtocolEngine(RPC.java:205)
at org.apache.hadoop.yarn.api.impl.pb.client.ApplicationClientProtocolPBClientImpl.(ApplicationClientProtocolPBClientImpl.java:197)
... 26 more
异常分析:Preconditions是guava下的工具类,hudi的源码依赖了不同的项目,这些项目使用了不同的guava版本,所报错误是由于运行时guava版本过旧,没有相应的方法。

(hudi的guava依赖)
异常解决:将HADOOM_HOME/lib下的guava版本拷贝到FLINK_HOME/lib下。我这里的hadoop guava版本是guava-28.0-jre.jar。
7.3 Flink on yarn session启动成功
重新执行命令,flink on yarn session启动成功,命令行日志中可以看到对应的yarn applicationId。

Yarn web ui:

点击Yarn web UI下的
ApplicationMaster进入Flink session集群,后续在这里跟踪flinkcdc作业状态。
 7.4 启动Flink sql client
7.4 启动Flink sql client
### -j指定额外的依赖包,可以指定多个依赖包,-j jar1 -j jar2
flink-1.13.5$ ./bin/sql-client.sh -s yarn-session -j lib/hudi-flink-bundle_2.11-0.10.0.jar shell

八、Mysql环境准备
8.1 安装Mysql
sudo apt install mysql-server -y8.2 配置Mysql文件 /etc/mysql/my.cnf, 开启binlog
!includedir /etc/mysql/conf.d/
!includedir /etc/mysql/mysql.conf.d/
[mysqld]
bind-address = 0.0.0.0
server_id = 1
log-bin = /var/lib/mysql/mysql-bin
#binlog-do-db = *
log-slave-updates
sync_binlog = 1
auto_increment_offset = 1
auto_increment_increment = 1
log_bin_trust_function_creators = 1
gtid_mode = on
enforce_gtid_consistency = on
8.3 重启Mysql并进行账号配置
## 重启Mysql
service mysql restart
## 连接mysql
mysql -uroot -pyourpassword
## 授权
grant select,replication client,replication slave on *.* to 'user_test'@'%' identified by 'user_test_password';
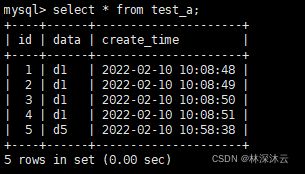
flush privileges;8.4 创建测试库、测试表并准备数据
mysql> create database flink_cdc;
mysql> CREATE TABLE `test_a` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`data` varchar(10) DEFAULT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=UTF8;
mysql> insert into test_a(data) values('d1');
mysql> insert into test_a(data) values('d1');
Query OK, 1 row affected (0.04 sec)
mysql> select * from test_a;
+----+------+---------------------+
| id | data | create_time |
+----+------+---------------------+
| 1 | d1 | 2022-02-10 10:08:48 |
| 2 | d1 | 2022-02-10 10:08:49 |
| 3 | d1 | 2022-02-10 10:08:50 |
| 4 | d1 | 2022-02-10 10:08:51 |
| 5 | d1 | 2022-02-10 10:08:52 |
+----+------+---------------------+
5 rows in set (0.00 sec)
九、FlinkCDC sink Hudi测试
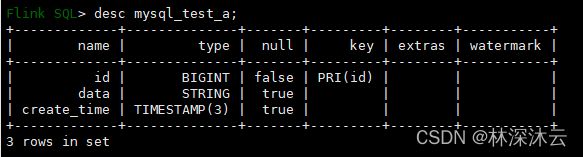
9.1、FlinkCDC Sql Table DDL:
Flink SQL> create table mysql_test_a(
id bigint primary key not enforced,
data String,
create_time Timestamp(3)
) with (
'connector'='mysql-cdc',
'hostname'='your-mysql-host',
'port'='3306',
'server-id'='5600-5604',
'username'='user_test',
'password'='user_test_password',
'server-time-zone'='Asia/Shanghai',
'debezium.snapshot.mode'='initial',
'database-name'='flink_cdc',
'table-name'='test_a'
)查看建表状态:
FlinkCDC mysql connector相关配置说明请参考官网文档:Mysql CDC Connector
注意:Hostname,username,password等信息根据自己的实际情况填写。
9.2 FlinkCDC Sql Table查询验证
Flink SQL> select * from mysql_test_a;这时Flink yarn session 集群中会启动一个作业来读取数据。

数据直接返回shell窗口:

读取结果与Mysql里的一致。在Mysql里执行一条更新:
mysql> update test_a set data='d5' where id=5;
观察到FlinkSql中,id=5的数据实时刷新了。

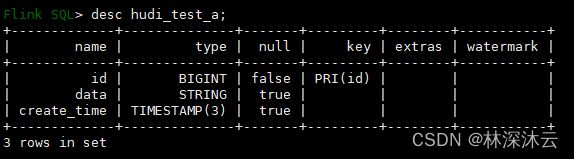
9.3 Hudi Sink Table DDL
create table hudi_test_a(
id bigint,
data String,
create_time Timestamp(3),
PRIMARY KEY (`id`) NOT ENFORCED
)
with(
'connector'='hudi',
'path'='hdfs://cluster-namespace/tmp/flink/cdcdata/test_a',
'hoodie.datasource.write.recordkey.field'='id',
'hoodie.parquet.max.file.size'='268435456',
'write.precombine.field'='create_time',
'write.tasks'='1',
'write.bucket_assign.tasks'='1',
'write.task.max.size'='1024',
'write.rate.limit'='30000',
'table.type'='MERGE_ON_READ',
'compaction.tasks'='1',
'compaction.async.enabled'='true',
'compaction.delta_commits'='1',
'compaction.max_memory'='500',
'changelog.enabled'='true',
'read.streaming.enabled'='true',
'read.streaming.check.interval'='3',
'hive_sync.enable'='true',
'hive_sync.mode'='hms',
'hive_sync.metastore.uris'='thrift://hive-metastore-host:9083',
'hive_sync.db'='test',
'hive_sync.table'='test_a',
'hive_sync.username'='flinkcdc',
'hive_sync.support_timestamp'='true'
)查看建表状态:
DDL是关键定义说明:
1、table_type是Hudi的表文件类型,定义了Hudi文件格式与索引组织方式。支持COPY_ON_WRITE 和MERGE_ON_READ,默认COPY_ON_WRITE 。
COPY_ON_WRITE:数据保存在列式文件中,如parquet。更新时可以定义数据版本或直接重写对应的parquet文件。支持快照读取和增量读取。
MERGE_ON_READ:数据保存在列式文件(如parquet) + 行记录级文件(如avro)中。数据更新时,会先将数据写到增量文件,然后会定时同步或异步合并成新的列式文件。支持快照读取和增量读取与读查询优化。
两种表类型的特点差异比较如下:
| 项目 | COPY_ON_WRITE | MERGE_ON_READ |
|---|---|---|
| 写延时 | 高 | 低 |
| 读延时 | 低 | 高 |
| 数据更新(update)成本(IO) | 高(重写整个parquet文件) | 低(追加到增量日志) |
| Parquet文件大小 | 小(高update(I/O成本) | 大(低update(I/O成本) |
| 写扩展性 | 高 | 低(取决于文件合并策略) |
更多的Hudi表类型说明参见官方文档-table_types
2、path为落地到hdfs的目录路径。
3、hoodie.datasource.write.recordkey.field为表去重主键,hudi根据这个配置创建数据索引,实现数据去重和增删改。主键相同时,选取write.precombine.field中对应字段的最大值的记录。
4、write.bucket_assign.tasks,write.tasks,compaction.tasks,设置3个子任务的并行度。
5、hive_sync*相关配置项定义hive元数据的同步方式。这里定义的是hms(hive metastore)同步,hudi会根据配置自动创建相应的hive表。
补充说明:Hudi详细配置说明参照Hudi官方文档:Hudi FlinkSQL配置
9.4 从MysqlCdc表同步数据到Hudi表
Flink SQL> set execution.checkpointing.interval=30sec;
Flink SQL> insert into hudi_test_a select * from mysql_test_a;
要设置execution.checkpointing.interval开启checkpoint,只有checkpoint开启时才会commit数据到hdfs,这时数据才可见。测试时可以设置较少的时间间隔以便于数据观察,线上设置应该根据实际情况设定,设置的间隔不宜过小。
命令执行后会显示成功提交了一个作业:
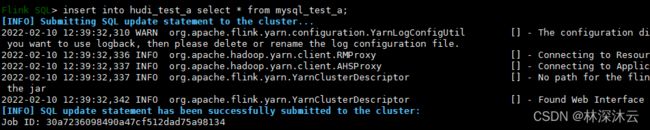
在Flink web ui上可以看到对应的作业信息:

9.5 在FlinkSql上验证Hudi表同步状态
Flink SQL> select * from hudi_test_a;
查询结果:

在Mysql中更新一条记录:
mysql> update test_a set data='d4' where id=4;
Hudi在一次Checkpoint完成后成功同步数据:

在Mysql中删除一条记录:
mysql> delete from test_a where id=2;
Hudi同样实现了数据删除:

9.6 Hive上验证Hudi表同步
9.6.1 Hudi-Hdfs同步目录与文件说明
通过hadoop web ui查看数据同步目录:
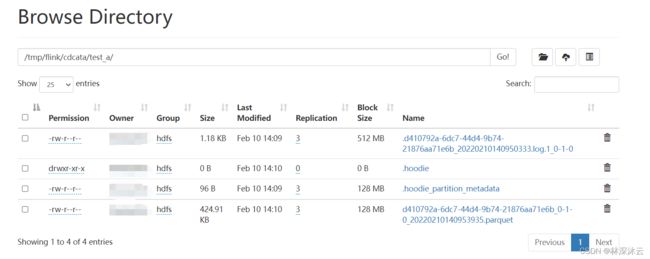
可以看到有四种文件/目录:
.*log*文件记录增量数据。
*.parquet为生成的parquet镜像文件。
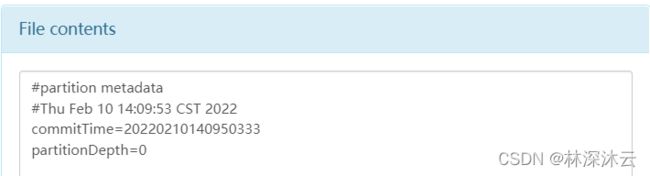
.hoodie_partition_metadata 记录当前同步到的分区元数据。查看文件内容如下。
.hoodie目录是Hudi作业的工作目录。进入目录查看相应文件:
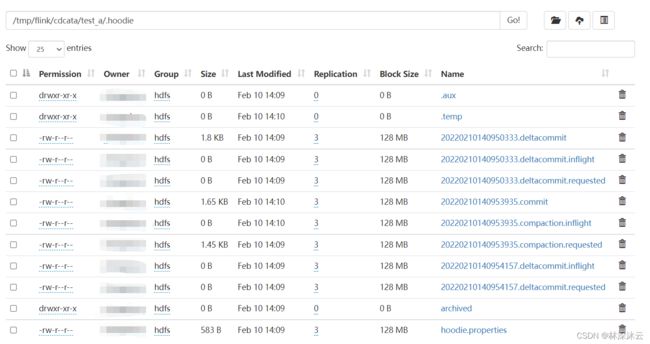
文件命名规则为:instance_time.action.action_state。
instance_time为一个instance触发时为时间戳,通过时间戳可以区分文件发生的先后。
action为instance的行为类型,主要有commit,clean,delta_commit,compaction,rollback,savepoint。
action_state指action的状态,主要有requested(调度发起,但未初始化),inflight(执行中),completed(已完成)。
更多的概念说明参见官方文档-timeline
9.6.2 Hudi生成的hive表说明
在hive中进行test库,show table后可以看到Hudi自动建了两张hive外部表:test_a_ro,test_a_rt。
Merge on read表会创建两张表,rt表支持快照+增量查询(近实时),ro支持读优化查询(ReadOptimized)。
show create table查看两张表的DDL:
hive > show create table test_a_ro;
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE EXTERNAL TABLE `test_a_ro`( |
| `_hoodie_commit_time` string COMMENT '', |
| `_hoodie_commit_seqno` string COMMENT '', |
| `_hoodie_record_key` string COMMENT '', |
| `_hoodie_partition_path` string COMMENT '', |
| `_hoodie_file_name` string COMMENT '', |
| `_hoodie_operation` string COMMENT '', |
| `id` bigint COMMENT '', |
| `data` string COMMENT '', |
| `create_time` bigint COMMENT '') |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' |
| WITH SERDEPROPERTIES ( |
| 'hoodie.query.as.ro.table'='true', |
| 'path'='hdfs://cluster-namespace/tmp/flink/cdcdata/test_a') |
| STORED AS INPUTFORMAT |
| 'org.apache.hudi.hadoop.HoodieParquetInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' |
| LOCATION |
| 'hdfs://cluster-namespace/tmp/flink/cdcdata/test_a' |
| TBLPROPERTIES ( |
| 'last_commit_time_sync'='20220210140950333', |
| 'spark.sql.sources.provider'='hudi', |
| 'spark.sql.sources.schema.numParts'='1', |
| 'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"_hoodie_commit_time","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_commit_seqno","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_record_key","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_partition_path","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_file_name","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_operation","type":"string","nullable":true,"metadata":{}},{"name":"id","type":"long","nullable":false,"metadata":{}},{"name":"data","type":"string","nullable":true,"metadata":{}},{"name":"create_time","type":"timestamp","nullable":true,"metadata":{}}]}', |
| 'transient_lastDdlTime'='1644473394') |
+----------------------------------------------------+
hive > show create table test_a_rt;
+----------------------------------------------------+
| createtab_stmt |
+----------------------------------------------------+
| CREATE EXTERNAL TABLE `test_a_rt`( |
| `_hoodie_commit_time` string COMMENT '', |
| `_hoodie_commit_seqno` string COMMENT '', |
| `_hoodie_record_key` string COMMENT '', |
| `_hoodie_partition_path` string COMMENT '', |
| `_hoodie_file_name` string COMMENT '', |
| `_hoodie_operation` string COMMENT '', |
| `id` bigint COMMENT '', |
| `data` string COMMENT '', |
| `create_time` bigint COMMENT '') |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' |
| WITH SERDEPROPERTIES ( |
| 'hoodie.query.as.ro.table'='false', |
| 'path'='hdfs://cluster-namespace/tmp/flink/cdcdata/test_a') |
| STORED AS INPUTFORMAT |
| 'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' |
| LOCATION |
| 'hdfs://cluster-namespace/tmp/flink/cdcdata/test_a' |
| TBLPROPERTIES ( |
| 'last_commit_time_sync'='20220210140950333', |
| 'spark.sql.sources.provider'='hudi', |
| 'spark.sql.sources.schema.numParts'='1', |
| 'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"_hoodie_commit_time","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_commit_seqno","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_record_key","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_partition_path","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_file_name","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_operation","type":"string","nullable":true,"metadata":{}},{"name":"id","type":"long","nullable":false,"metadata":{}},{"name":"data","type":"string","nullable":true,"metadata":{}},{"name":"create_time","type":"timestamp","nullable":true,"metadata":{}}]}', |
| 'transient_lastDdlTime'='1644473394') |
+----------------------------------------------------+
可以看到Hudi在两张表中都加入了6个Hudi的元数据字段,字段名以'_hoodie_'为前缀。
rt和ro的读写类是不一样的。
| INPUT FORMAT | OUT FORMAT | |
|---|---|---|
| rt | org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat |
| ro | org.apache.hudi.hadoop.HoodieParquetInputFormat | org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat |
rt表(HoodieParquetRealtimeInputFormat)读取parquet文件与增量log文件,读取时将两种数据进行合并,产生近实时的数据镜像。rt表实时性好,但读IO效率较差。
ro表(HoodieParquetInputFormat)查询时只读取parquet文件。新数据只有经过compact合并生成新的parquet文件时才可以读到,数据存在一定的延时,但读IO效率更高,因为只读取parquet文件,不需要读增量log进行数据合并。
9.7 Hive表查询验证前准备
使用Hive查询hudi表前需要将之前编译得到的hudi-hadoop-mr-bundle-0.10.0.jar加入到hive的运行依赖中。直接查询的话会报错,找不到INPUTFORMAT对应的类:
hive > select * from test_a_ro;
Error: Error while compiling statement: FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.hudi.hadoop.HoodieParquetInputFormat (state=42000,code=40000)
hive > select * from test_a_rt;
Error: Error while compiling statement: FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat (state=42000,code=40000)配置过程如下:
a.将hudi-hadoop-mr-bundle-0.10.0.jar拷贝到hive server所在的HIVE_HOME/auxlib下。如果HIVE_HOME下没有auxlib目录,则新建目录。
b. 重启hiveserver2
nohup hive --service hiveserver2 &9.8 Hudi hive表查询验证
hive> set hive.resultset.use.unique.column.names=false;
hive> select * from test_a_ro;
hive> select * from test_a_rt;
rt表与ro表查询正常。
9.9 Hudi hive表增改删验证
9.9.1 在Mysql上增改删数据
mysql> select * from test_a;
+----+------+---------------------+
| id | data | create_time |
+----+------+---------------------+
| 1 | d1 | 2022-02-10 10:08:48 |
| 3 | d1 | 2022-02-10 10:08:50 |
| 4 | d4 | 2022-02-10 12:51:06 |
| 5 | d5 | 2022-02-10 10:58:38 |
+----+------+---------------------+
4 rows in set (0.00 sec)
mysql> insert into test_a(data) values('d6');
Query OK, 1 row affected (0.03 sec)
mysql> update test_a set data='d3' where id=3;
Query OK, 1 row affected (0.04 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> delete from test_a where id=1;
Query OK, 1 row affected (0.06 sec)
mysql> select * from test_a;
+----+------+---------------------+
| id | data | create_time |
+----+------+---------------------+
| 3 | d3 | 2022-02-10 16:33:43 |
| 4 | d4 | 2022-02-10 12:51:06 |
| 5 | d5 | 2022-02-10 10:58:38 |
| 6 | d6 | 2022-02-10 16:33:21 |
+----+------+---------------------+
4 rows in set (0.00 sec)
9.9.2 Hudi rt表查询验证MysqlCdc增删改
再次查询rt表,mysql表的数据马上同步到rt里,可以根据_hoodie_commit_time确认完成同步的时间,_hoodie_commit_seqno标记同步的次序。_hoodie_operation标记增(I)、改(U)、删(D)。这时还可以查询到已删除的记录。

已删除的记录在parquet文件被compact重写之后正式删除。默认5次commit触发一次compact。compact后数据为最新的镜像,所有记录对应的operate都为I。
9.9.3 Hudi ro表查询验证MysqlCdc增删改
查询ro表,ro表的数据同步要明显慢于rt表,删除记录不会马上直接反映在ro表中。insert、update的数据反映到ro表时,delete依然为早期的状态。

delete的数据只有在compact后才会反映到ro表中。
![]()
十、总结
至此,我们展示了FlinkCdc-Hudi-Hive落地的全过程。下一步会探索更多的应用场景,并记录遇到的坑点。敬请期待!