数据湖之基于flink+hudi+hive的实践(一)
文章目录
-
- 一、介绍
- 二、环境准备与实验
-
- 1、环境
- 2、启动步骤
- 3、实验过程
- 三、遇到过的坑
- 四、参考资料
一、介绍
hudi最新的0.9版本经过众人千呼万唤,终于在9月份出来了。hudi可以兼容在hadoop基础之上存储海量数据,不仅可以进行批处理,还可以在数据湖上进行流处理,即离线与实时结合。并且同时提供了2种原生语义:
- 1)Update/Delete记录:即通过hudi可以更新和删除表中记录,同时还提供写操作的事务保证。
- 2)Change Streams:可以从某个时间点获取给定表中已updated/inserted/deleted的所有记录的增量流。
不仅支持近实时写入和分析,还支持Spark、Presto、Trino、Hive 等的 SQL 读/写、事务回滚和并发控制、快照查询/增量查询、可插入索引等。更多介绍请参考Apache hudi官网
hudi0.8版本与flinksql的兼容性不好,里面没有对connector='hudi’的实现,在github上可以看到0.9版本有相关的实现了。
二、环境准备与实验
1、环境
- flink1.12.2
- hudi0.9
- hive 3.1.2
- hadoop 3.1.1
2、启动步骤
flink-conf.yaml中,需要开启checkpoint,其配置如下:
execution.checkpointing.interval: 3000sec
state.backend: rocksdb
state.checkpoints.dir: hdfs://hadoop0:9000/flink-checkpoints
state.savepoints.dir: hdfs://hadoop0:9000/flink-savepoints
第一步:启动hadoop集群,进入$HADOOP_HOME,执行:
./sbin/start-dfs.sh
在启动hadoop集群之前,建议先同步集群的时间,不然在后面操作hudi时会报错,可以使用如下命令同步。
ntpdate time1.aliyun.com
第二步:启动hive节点,进入$HIVE_HOME/conf,执行命令:
nohup hive --service metastore
nohup hiveserver2 &
启动hive后,执行beeline -u jdbc:hive2://hadoop0:10000命令是可以正常进入hive的。如果没有,可能需要检查hive-site.xml的配置或者查看启动日志。
第三步:启动flink节点,进入$FLINK_HOME/bin,执行命令:
./start-cluster.sh
在此之前,可以设置taskmanager的数量和slot的数量,hudi官网上是将taskmanager的数量设置为4,一个taskmanager有一个slot。当然也可以根据服务器的配置和数据量大小而定;
此外,$FLINK_HMOE/lib/目录下还需引入下面几个包:
flink-connector-hive_2.11-1.12.2.jar
flink-hadoop-compatibility_2.11-1.12.2.jar
flink-sql-connector-hive-3.1.2_2.11-1.12.2.jar
hive-exec-3.1.2.jar
hudi-flink-bundle_2.11-0.9.0.jar
3、实验过程
第一步:启动flink-sql客户端,在$FLINK_HOME/bin目录执行:
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./sql-client.sh embedded
hudi0.9官网上执行是的./sql-client.sh embedded -j …/lib/hudi-flink-bundle_2.11-0.9.0.jar shell这条命令,用flink sql插入数据时会报错,导致jobmanager挂掉,目前在hudi0.10已经修复了这个bug。
第二步:建表和插入数据
use catalog myhive; --指定catalog,也可以不指定
CREATE TABLE tb_hudi_0901_tmp30 (
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30',
'write.tasks'='1',
'compaction.async.enabled' = 'false',
'compaction.tasks'='1',
'table.type' = 'MERGE_ON_READ' ) ;
INSERT INTO tb_hudi_0901_tmp30 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','part1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','part1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','part1'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','part1'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','part1'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','part1');
效果如下图所示:
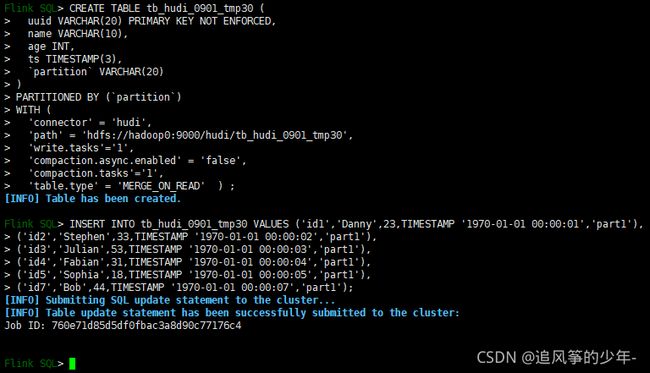
在这里,实验用的是离线压缩,compaction.async.enabled设置了false,也可以在线压缩。如果是在线压缩,批环境实验还没有成功,但是在流环境下,接kafka作为数据源,触发checkpoint是可以的,默认是当触发5次checkpoint时会生成压缩计划,然后调度对应的压缩任务,在hdfs便可以看到生成parquet文件了,这个是至关重要的,没有生成parquet文件,在hive里面是查不到数据了。如图所示:

第三步:建立hive外部表
- 方式一:INPUTFORMAT为HoodieParquetInputFormat类型的外部表。只会查询出来parquet数据文件中的内容,但是刚刚更新或者删除的数据不能查出来,对hive表中mor/cow类型的表均可执行count(*)操作。
CREATE EXTERNAL TABLE hudi_tb_test_copy4 (
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`uuid` STRING,
`name` STRING,
`age` bigint,
`ts` bigint) PARTITIONED BY (`partition` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30';
- 方式二:INPUTFORMAT为HoodieParquetRealtimeInputFormat类型的外部表。会实时读出来写入的数据,将基于Parquet的基础列式文件和基于行的Avro日志文件合并在一起呈现出来。不过最近发现用此类型时,在hive集群中对mor表执行count(*)操作会报内存溢出错误,cow类型的表没有这个问题。
CREATE EXTERNAL TABLE hudi_tb_test_copy4 (
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`uuid` STRING,
`name` STRING,
`age` bigint,
`ts` bigint) PARTITIONED BY (`partition` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30';
alter table hudi_tb_test_copy4 add if not exists partition(`partition`='part1') location 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30/part1';
在hudi0.9版本也可以不用手动建立hive外部表,可以自动生成的,可惜目前还没有打通这个环节…
第四步:beeline查询数据
- 查询之前,先执行如下命令,第一个命令是把包加入到hive环境中,是属于当前会话的;若永久生效,需要在$HIVE_HOME建立auxlib/,把包放入此目录,然后重启hive集群。
效果如下图所示:add jar hdfs://hadoop0:9000/jar/hudi-hadoop-mr-bundle-0.9.0.jar; set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
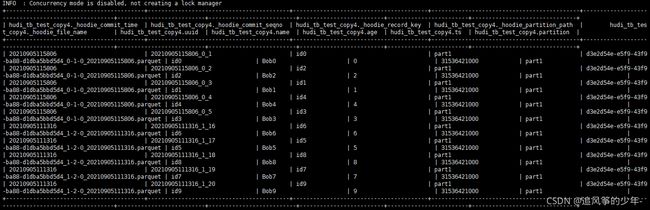
至此,flink->hudi->hive的环节就打通了,但是还有许多问题在研究中。比如:- cow表会有写放大问题,当表中有大量的更新数据写入时,落地的parquet文件的总大小会double,每写一次会double一次。不过这是正常的,copy_on_write,copy的是没有变化的数据,hudi将这些数据copy出来,然后append新增或更新的数据,落地为一个新文件。所有不难理解cow表会产生很多文件了。
- cow表会生成很多小的parquet文件,parquet文件的个数好像与这个参数write.bucket_assign.tasks有关,设置之后发现文件个数明显减少了。
- mor类型的表默认是完成5次checkpoint才会调度压缩任务,生成parquet文件的,如果在hdfs上没有看到parquet文件,那得看看有没有完成指定次数的checkpoint了。不过测试时发现批环境下即便完成了checkpoint,也没有触发压缩任务,很奇怪;但在流环境中是可以的。对了,mor生成的log会定期清理的。
- hoodie.datasource.write.precombine.field: 更新数据时,如果存在两个具有相同主键的记录,则此列中的值将决定更新哪个记录。选择诸如时间戳的列确保选择具有最新时间戳的记录。这个参数很有用,默认指定的字段是ts字段,所以flink表中要有ts字段,没有的话,需要指定了。
- read.streaming.check-interval: 每隔多久去检验一次有没有新的操作在timeline上产生的。
三、遇到过的坑
- [1] ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation. 解决办法:在 hadoop-env.sh 文件下面添加如下内容。export JAVA_HOME=/usr/java/jdk1.8.0_181 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_ZKFC_USER=root export HDFS_JOURNALNODE_USER=root - [2] IllegalArgumentException: Following instants have timestamps >= compactionInstant (20210710211157) Instants :[[20210713205004__deltacommit__COMPLETED], [20210713205200__deltacommit__COMPLETED], [20210714091634__deltacommit__COMPLETED]]
错误原因:compaction时必须保证所有completed,inflight,requested的compaction的时间必须小于当前压缩时间。解决办法:查看集群的时间,同步时间ntpdate time1.aliyun.com - [3] java.lang.NoSuchMethodError: io.javalin.core.CachedRequestWrapper.getContentLengthLong()J
at io.javalin.core.CachedRequestWrapper.(CachedRequestWrapper.kt:22) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
at io.javalin.core.JavalinServlet.service(JavalinServlet.kt:34) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
at io.javalin.core.util.JettyServerUtil i n i t i a l i z e initialize initializehttpHandler$1.doHandle(JettyServerUtil.kt:72) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
at org.apache.hudi.org.apache.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:203) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
错误原因:像这类NoSuchMethodError的错误,一般都是类冲突导致,同一个类依赖了多个版本,运行的时类加载器没有找到这个类的方法导致的。 定位到ServletRequestWrapper这个类冲突,把相关的类移除就可以了。 - [4] FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat (state=42000,code=40000)。在hive集群里面执行如下命令:
这里只列出了印象较深刻的一些问题。。。add jar hdfs://hadoop0:9000/jar/hudi-hadoop-mr-bundle-0.9.0.jar;
四、参考资料
- [1] https://hudi.apache.org/docs/flink-quick-start-guide/
- [2] https://www.yuque.com/docs/share/01c98494-a980-414c-9c45-152023bf3c17?#
- [3] https://zhuanlan.zhihu.com/p/131210053
- [4] https://cloud.tencent.com/developer/article/1812134
- [5] https://blog.csdn.net/xxscj/article/details/115320772
- [6] https://blog.csdn.net/hjl18309163914/article/details/116057379?spm=1001.2014.3001.5501
最后用一句话结尾
世事洞明皆学问,人情练达即文章~~~