三维目标检测算法汇总学习笔记
原文链接:https://mp.weixin.qq.com/s/_HdGVC6orkL2zfiv5sqrMw
2D与3D区别
3D目标检测面临更多的挑战,主要的体现在不仅要找到物体在图像中出现的位置,还需要反投影到实际3D中获得空间中准确位置,需要进行绝对的尺寸估计。
现代自动驾驶汽车通常配备多个传感器,如激光雷达和摄像头。
- 激光雷达的优点是可直接获取空间目标的三维信息,且该深度信息精度较高,缺点价格稍贵;
- 相机的优点是可以保存更详细的语义信息,缺点是需要正确计算图像点与三维点的对应关系。
3D目标检测的分类
三维目标检测按照传感器类型分为单目相机、双目相机、多目相机、激光雷达扫描、深度相机和红外相机目标检测。
- 由多目相机组成的立体视觉系统或者激光雷达可以实现更准确的3D推理信息。
- 单目RGB相机设备更便捷和更廉价,使用单目摄像头进行三维物体检测是经济型自动驾驶系统合理选择。
按照数据类型可分为三类分别是,即单目图像,多视图图像(视图或立体数据),点云目标检测。
- 基于单视图的方法,例如,[1],使用单目摄像头完成三维目标检测。
- 基于多视图的方法,例如,[2],可以使用从不同视图的图像中得到的视差来获得深度图。
- 基于点云的方法,例如[3,4,5,6],从点云获取目标信息,相比较而言基于点云的方法更为直观和准确的检测方法,由于点的深度数据可以直接测量,三维检测问题本质上是三维点的划分问题。
相比于使用雷达系统或者深度相机,使用摄像机系统成本更低,但是需要进行图像点的反投影,计算点在空间中的位置。除此之外,相比于深度图像点云数据,图像恢复深度可以适用于室外大尺度场景,这是普通深度相机所不能达到的。
单目图像3D目标检测
由射影几何学原理可知,仅仅依赖一副图像是无法恢复物体的三维位置,即使能得到相对位置信息,也无法获得真实尺寸。因此,正确检测目标的3D位置最少需要多个相机或者运动相机组成的立体视觉系统,或者由深度相机、雷达等传感器得到的3D点云数据。
对于特定类型目标,基于机器学习的方法使得通过单目相机进行物体3D检测成为可能。原因是特定类型目标往往具有很强的先验信息,因此依靠给真实物体做标注,联合学习物体类别和物体姿态可以大概估计出物体3D尺寸。不过,为了更好的估计物体的3D位置,更好的方法是联合学习方法和射影几何知识,来计算物体在真实世界中的尺度和位置。
A. Mousavian在CVPR2017提出了一种结合深度神经网络回归学习和几何约束的3D目标(主要针对车辆)检测和3维位置估计的算法[7]。论文中对车辆的三维姿态和位置进行建模,需要知道车辆在场景中的位置和车辆相对于摄像机的角度,以及车辆的尺寸大小。回归计算方位角和物体尺寸,利用投影公式,计算中心点向量。
GS3D[1]是基于引导和表面的三维车辆检测算法,由香港中文大学Buyu Li等完成,其思想为:首先预测二维检测框和观测角度;然后基于场景先验,生成目标的粗糙边界框,再将边界框重投影到图像平面,计算表面特征;最后通过子网络,由重投影特征进行分类学习,得到精细化的三维检测框。

通过2D探测器有效地确定预测对象的粗糙边界框。虽然粗糙,但可以接受。其精确度可以指导确定空间位置,尺寸(高度,宽度,长度)和物体的方向等。提取不同可见表面的特征,然后加以合并,因此结构信息被用来区分不同的三维边界框。将传统回归的形式重新表述为分类的形式,并为其设计了质量敏感的损失函数。主要贡献在于,基于可靠的二维检测结果,GS3D是一种纯单目摄像头的方法。可以有效为物体获取粗糙边界框。粗糙边界框提供了对象的位置大小和方向的可靠近似,并作为进一步优化的指导;利用投影在二维图像上的三维框的可见表面的结构信息,然后利用提取的特征解决模糊问题;设计比较之后发现基于质量敏感的损失的离散分类的效果要更好。
基于YOLO的三维目标检测:YOLO-6D[8]是一种使用一张2D图像来预测物体6D姿态的方法。但是,并不是直接预测6D姿态,而是通过预测3D编辑框在二维图像上的1个中心点和8个角点,然后在有九个点通过PNP算法计算得到6D姿态。把预测6D姿态问题转为了预测9个坐标点的问题。而在2D的目标检测中,我们实际上也是需要预测坐标点xy的。那么,我们能不能把目标检测框架拿来用呢?很显然是可以的。所以这篇文章就提出基于yolo的6D姿态估计框架。
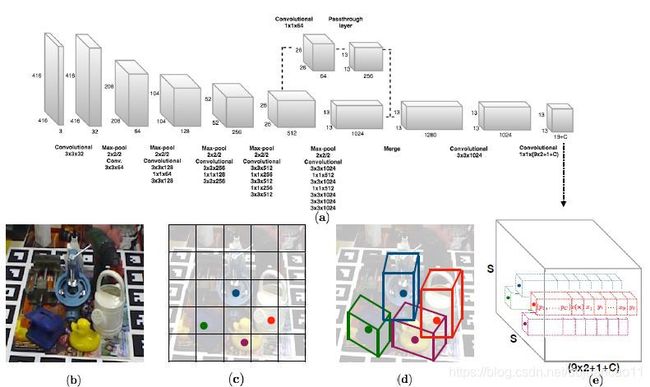
双(多)视图图像3D目标检测
对于双目立体视觉,进行合理的双目匹配,通过相机之间的相对位置计算,可以得到比单目视觉更强的空间约束关系,因此结合已有的物体先验知识,可能得到比单目相机更准确的检测结果。
基于3DOP的3D目标检测[9]采用类似于Fast R-CNN的二步检测算法。对于具有2幅成对图像的双目立体视觉图像。具体的,首先采用Yamaguchi在ECCV2014年发表的方法[10]计算每个点的深度图像,由此生成点云数据,后续的处理是基于点云做为处理和输入数据。然后,采用Struct-SVM优化的方法选择3D检测的候选3D框y。最后,通过R-CNN方式,对每个候选框进行分类评估和位置回归。在此处考虑像素的深度数据,为了处理深度数据,可以直接在输入图像中增加深度数据图像,也可以采用双分支架构的判别和回归网络。但是这种双分支训练时需要更大的显存。

个人观点:
不论是在做项目还是写论文,选择网络的时候一定要注意网络的输入与输出形式:
输入形式:点云数据(或者处理后的点云数据)、原始拍摄图像等输出形式:目标类别、三维边框坐标和角度(位姿)等
基于立体视觉R-CNN的3D目标检测算法是扩展 Faster-RCNN网络框架到双目立体视觉进行3D目标检测的方法[11]。该方法的关键步骤是对左右图像的自动对齐学习,以及通过稠密匹配优化最终的检测结果。由左右视图图像经过2个相同的Faster-RCNN中的RPN结构计算左右视图中匹配的推送(proposals)矩形框stereo-RPN。RPN主干网络采用Resnet-101或者FPN。与Faster-RCNN中的RPN相比,stereo-RPN同时计算了可能的2D框,并且对左右视图的2D框进行了配对(association)。
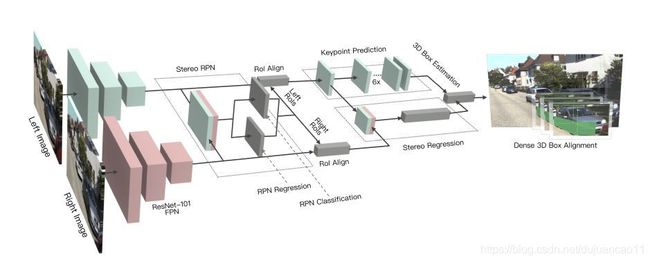
基于立体R-CNN的自主驾驶3D目标检测方法相关解读
https://blog.csdn.net/qq_18941713/article/details/90691791此方法不需要深度输入和三维位置信息,但优于现在所有的完全监督的基于图像的方法。
本方法的模型有点大,官方文档说是显存不足可以尝试轻量化模型,没有找到。
提供的模型:
readme训练说明截图
具体做项目的时候需要考虑到项目场景、最终推理盒子性能等,来选择模型。

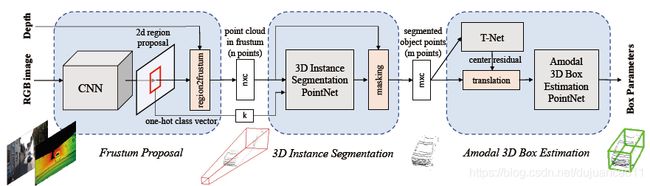
点云3D目标检测
三维点云数据是由无序的数据点构成一个集合来表示。较为早期深度学习点云分类的方式有两种:
- 一种是将点云数据投影到二维平面,此种方式不直接处理三维的点云数据,而是先将点云投影到某些特定视角再处理,如前视视角和鸟瞰视角,同时,也可以融合使用来自相机的图像信息,通过将这些不同视角的数据相结合,来实现点云数据的认知任务。比较典型的算法有MV3D和AVOD;
- 另一种是将点云数据划分到有空间依赖关系的voxel,此种方式通过分割三维空间,引入空间依赖关系到点云数据中,再使用3D卷积等方式来进行处理。这种方法的精度依赖于三维空间的分割细腻度,而且3D卷积的运算复杂度也较高。
- 不同于以上两种方法对点云数据先预处理再使用的方式,PointNet是直接在点云数据上应用深度学习模型的方法。
PointNet系列论文首先提出了一种新型的处理点云数据的深度学习模型,并验证了它能够用于点云数据的多种认知任务,如分类、语义分割和目标识别。PointNet的关键流程为:输入为一帧的全部点云数据的集合,表示为一个n×3的张量,其中n代表点云数量,3对应xyz坐标;输入数据先通过和一个T-Net学习到的转换矩阵相乘来对齐,保证了模型的对特定空间转换的不变性;通过多次mlp对各点云数据进行特征提取后,再用一个T-Net对特征进行对齐;在特征的各个维度上执行max-pooling操作来得到最终的全局特征;对分类任务,将全局特征通过mlp来预测最后的分类分数;对分割任务,将全局特征和之前学习到的各点云的局部特征进行串联,再通过mlp得到每个数据点的分类结果。
受到CNN的启发,作者提出了PointNet++,它能够在不同尺度提取局部特征,通过多层网络结构得到深层特征。PointNet++关键部分包括:采样层,组合层和特征提取层。上述各层构成了PointNet++的基础处理模块。如果将多个这样的处理模块级联组合起来,PointNet++就能像CNN一样从浅层特征得到深层语义特征。对于分割任务的网络,还需要将下采样后的特征进行上采样,使得原始点云中的每个点都有对应的特征。这个上采样的过程通过最近的k个临近点进行插值计算得到。
PointNet和PointNet++主要用于点云数据的分类和分割问题,Frustum-PointNet(F-PointNet)[12]将PointNet的应用拓展到了3D目标检测上。目前单纯基于Lidar数据的3D目标检测算法通常对小目标检测效果不佳,为了处理这个问题,F-PointNet提出了结合基于图像的2D检测算法来定位目标,再用其对应的点云数据视锥进行bbox回归的方法来实现3D目标检测。从KITTI数据集的检测结果来看,得益于精确的基于图像的2D检测模型,F-PointNet对小目标的检测效果确实处于领先地位。F-PointNet由2D目标检测模型和3D分割和回归网络构成,并非为端到端的模型。可以考虑将其组合成一个端到端的网络。
用于点云的目标检测方法,精度较高的还有港中文&商汤科技发表的Part-A2 Net[14],而海康威视的Voxel-FPN[13]单论mAP只能说勉强接近SOTA水平,但论文mAP与FPS的Trade-off,50 FPS的速度,还是强压其他算法的。
参考文献
[1] Li B , Ouyang W , Sheng L , et al. GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving[J]. 2019.
[2] X. Chen, K. Kundu, Y. Zhu, H. Ma, S. Fidler, and R. Urtasun. 3d object proposals using stereo imagery for accurate object class detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
[3] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas. Frustum pointnets for 3d object detection from rgb-d data. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[4] Y. Zhou and O. Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[5] J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. Waslander. Joint 3d proposal generation and object detection from view aggregation. IROS, 2018.
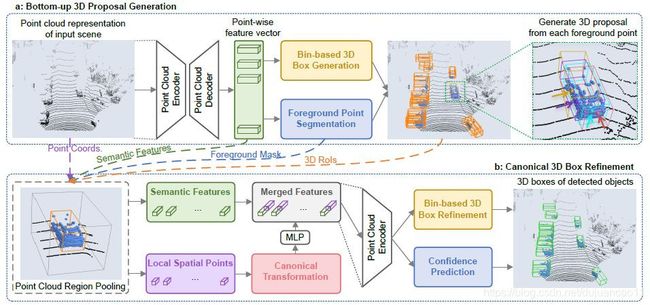
[6] Shi S , Wang X , Li H . PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud[J]. In IEEE CVPR, 2019.
[7]A. Mousavian, D. Anguelov, J. Flynn, J. Kosecka, “3d bounding box estimation
using deep learning and geometry”. In CVPR 2017, 5632-5640.
[8] Tekin B , Sinha S N , Fua P . Real-Time Seamless Single Shot 6D Object Pose Prediction[J]. 2017.
[9]A. Mousavian, D. Anguelov, J. Flynn, J. Kosecka, “3d bounding box estimation using deep learning and geometry”. In CVPR 2017, 5632-5640.
[10]K. Yamaguchi, D. McAllester, and R. Urtasun, “Efficient joint segmentation, occlusion labeling, stereo and flow estimation,” in Proc. Eur. Conf. Comput. Vis., 2014, pp. 756–771.
[11]P. Li, X. Chen, S. Shen. “Stereo R-CNN based 3D Object Detection for Autonomous Driving”. CVPR 2019.
[12] Qi C R , Liu W , Wu C , et al. Frustum PointNets for 3D Object Detection from RGB-D Data[J]. 2017.
[13] Wang B , An J , Cao J . Voxel-FPN: multi-scale voxel feature aggregation in 3D object detection from point clouds[J]. 2019.
[14] Shi S , Wang Z , Wang X , et al. Part-A^2 Net: 3D Part-Aware and Aggregation Neural Network for Object Detection from Poin Cloud[J]. 2019.