干货|深入浅出YOLOv5
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|机器学习算法工程师之前已经对Yolov4的相关基础知识做了比较系统的梳理(深入浅出Yolov3和Yolov4Yolov4后不久,又出现了Yolov5,虽然作者没有放上和Yolov4的直接测试对比,但在COCO数据集的测试效果还是很可观的。
很多人考虑到Yolov5的创新性不足,对算法是否能够进化,称得上Yolov5而议论纷纷。
但既然称之为Yolov5,也有很多非常不错的地方值得我们学习。不过因为Yolov5的网络结构和Yolov3、Yolov4相比,不好可视化,导致很多同学看Yolov5看的云里雾里。
因此本文,大白主要对Yolov5四种网络结构的各个细节做一个深入浅出的分析总结,和大家一些探讨学习。
版权申明:本文包含图片,都为大白使用PPT所绘制的,如需网络结构高清图和模型权重,可点击查看下载(https://blog.csdn.net/nan355655600/article/details/107852288)。
本文目录
1 Yolov5 四种网络模型
1.1 Yolov5网络结构图
1.2 网络结构可视化
1.2.1 Yolov5s网络结构
1.2.2 Yolov5m网络结构
1.2.3 Yolov5l网络结构
1.2.4 Yolov5x网络结构
2 核心基础内容
2.1 Yolov3&Yolov4网络结构图
2.2 Yolov5核心基础内容
2.2.1 输入端
2.2.2 Backbone
2.2.3 Neck
2.2.4 输出端
2.3 Yolov5四种网络结构的不同点
2.3.1 四种结构的参数
2.3.2 Yolov5网络结构
2.3.3 Yolov5四种网络的深度
2.3.4 Yolov5四种网络的宽度
3 Yolov5相关论文及代码
4 小目标分割检测
5 后语
1 Yolov5四种网络模型
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。
学习一个新的算法,最好在脑海中对算法网络的整体架构有一个清晰的理解。
但比较尴尬的是,Yolov5代码中给出的网络文件是yaml格式,和原本Yolov3、Yolov4中的cfg不同。
因此无法用netron工具直接可视化的查看网络结构,造成有的同学不知道如何去学习这样的网络。
比如下载了Yolov5的四个pt格式的权重模型:

但因为netron对pt格式的文件兼容性并不好,直接使用netron工具打开,会发现,根本无法显示全部网络。
因此可以采用pt->onnx->netron的折中方式,先使用Yolov5代码中models/export.py脚本将pt文件转换为onnx格式,再用netron工具打开,这样就可以看全网络的整体架构了。

如需下载Yolov5整体的4个网络pt文件及onnx文件,也可点击链接查看下载,便于直观的学习。
1.1 Yolov5网络结构图
安装好netron工具,就可以可视化的打开Yolov5的网络结构。
这里大白也和之前讲解Yolov3&Yolov4同样的方式,绘制了Yolov5s整体的网络结构图,配合netron的可视化网络结构查看,脑海中的架构会更加清晰。
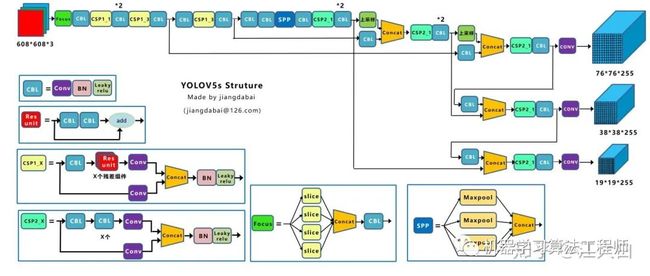
本文也会以Yolov5s的网络结构为主线,讲解与其他三个模型(Yolov5m、Yolov5l、Yolov5x)的不同点,让大家对于Yolov5有一个深入浅出的了解。
1.2 网络结构可视化
将四种模型pt文件的转换成对应的onnx文件后,即可使用netron工具查看。
但是,有些同学可能不方便,使用脚本转换查看。
因此,大白也上传了每个网络结构图的图片,也可以直接点击查看。
虽然没有netron工具更直观,但是也可以学习了解。
1.2.1 Yolov5s网络结构
Yolov5s网络是Yolov5系列中深度最小,特征图的宽度最小的网络。后面的3种都是在此基础上不断加深,不断加宽。
上图绘制出的网络结构图也是Yolov5s的结构,大家也可直接点击查看,Yolov5s的网络结构可视化的图片。
1.2.2 Yolov5m网络结构
此处也放上netron打开的Yolov5m网络结构可视图,点击即可查看,后面第二版块会详细说明不同模型的不同点。
1.2.3 Yolov5l网络结构
此处也放上netronx打开的Yolov5l网络结构可视图,点击即可查看。
1.2.4 Yolov5x网络结构
此处也放上netronx打开的Yolov5x网络结构可视图,点击即可查看。
2 核心基础内容
2.1 Yolov3&Yolov4网络结构图
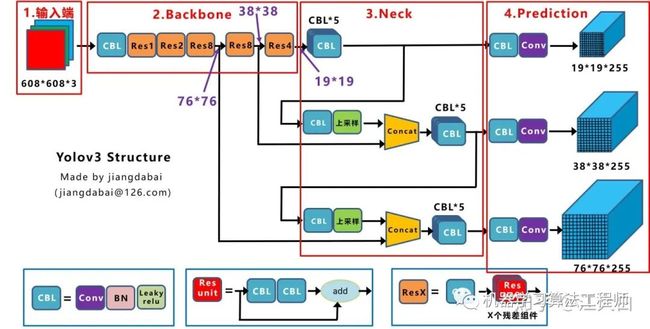
2.1.1 Yolov3网络结构图
Yolov3的网络结构是比较经典的one-stage结构,分为输入端、Backbone、Neck和Prediction四个部分。
大白在之前的《深入浅出Yolo系列之Yolov3&Yolov4核心基础知识完整讲解》中讲了很多,这里不多说,还是放上绘制的Yolov3的网络结构图。
2.1.2 Yolov4网络结构图
Yolov4在Yolov3的基础上进行了很多的创新。
比如输入端采用mosaic数据增强,
Backbone上采用了CSPDarknet53、Mish激活函数、Dropblock等方式,
Neck中采用了SPP、FPN+PAN的结构,
输出端则采用CIOU_Loss、DIOU_nms操作。
因此Yolov4对Yolov3的各个部分都进行了很多的整合创新,关于Yolov4详细的讲解还是可以参照大白之前写的《深入浅出Yolo系列之Yolov3&Yolov4核心基础知识完整讲解》,写的比较详细。

2.2 Yolov5核心基础内容
Yolov5的结构和Yolov4很相似,但也有一些不同,大白还是按照从整体到细节的方式,对每个板块进行讲解。
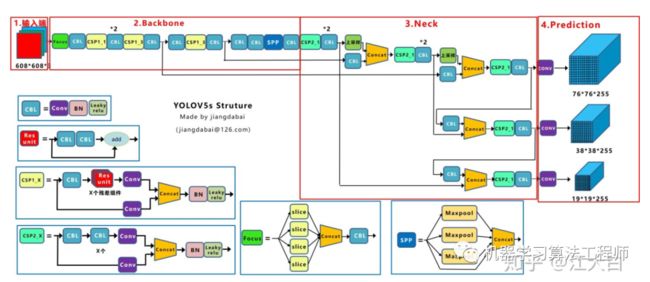
上图即Yolov5的网络结构图,可以看出,还是分为输入端、Backbone、Neck、Prediction四个部分。
大家可能对Yolov3比较熟悉,因此大白列举它和Yolov3的一些主要的不同点,并和Yolov4进行比较。
(1)输入端:Mosaic数据增强、自适应锚框计算
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
下面丢上Yolov5作者的算法性能测试图:

Yolov5作者也是在COCO数据集上进行的测试,大白在之前的文章讲过,COCO数据集的小目标占比,因此最终的四种网络结构,性能上来说各有千秋。
Yolov5s网络最小,速度最少,AP精度也最低。但如果检测的以大目标为主,追求速度,倒也是个不错的选择。
其他的三种网络,在此基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
2.2.1 输入端
(1)Mosaic数据增强
Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式。
Mosaic数据增强提出的作者也是来自Yolov5团队的成员,不过,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的。

Mosaic数据增强的内容在之前《深入浅出Yolo系列之Yolov3&Yolov4核心基础知识完整讲解》文章中写的很详细,详情可以查看之前的内容。
(2) 自适应锚框计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
因此初始锚框也是比较重要的一部分,比如Yolov5在Coco数据集上初始设定的锚框:

但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。
控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
(3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
比如Yolo算法中常用416*416,608*608等尺寸,比如对下面800*600的图像进行缩放。

但Yolov5代码中对此进行了改进,也是Yolov5推理速度能够很快的一个不错的trick。
作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
这种方式在之前github上Yolov3中也进行了讨论:https://github.com/ultralytics/yolov3/issues/232
在讨论中,通过这种简单的改进,推理速度得到了37%的提升,可以说效果很明显。
但是有的同学可能会有大大的问号??如何进行计算的呢?大白按照Yolov5中的思路详细的讲解一下,在datasets.py的letterbox函数中也有详细的代码。
第一步:计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
第二步:计算缩放后的尺寸

原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
第三步:计算黑边填充数值

将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到40个像素,再除以2,即得到图片高度两端需要填充的数值。
此外,需要注意的是:
a.这里大白填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
b.训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
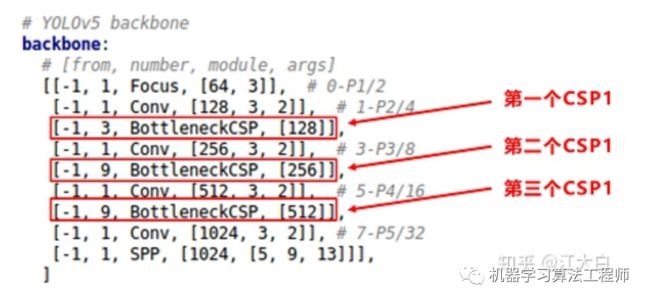
2.2.2 Backbone
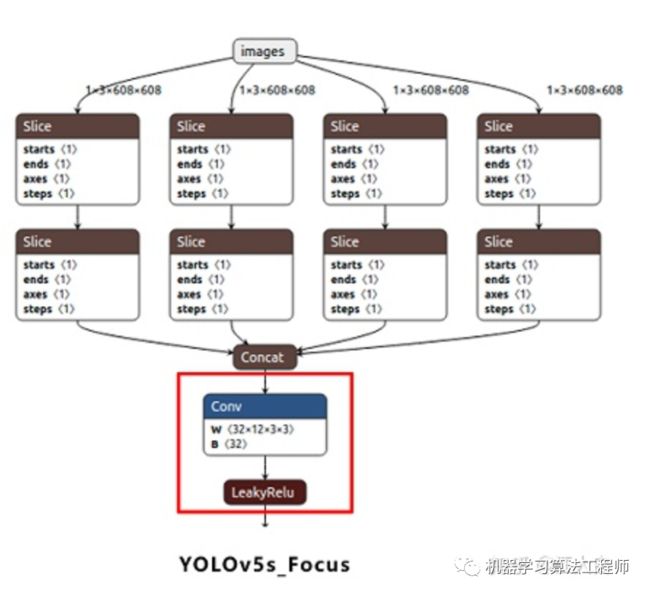
(1)Focus结构
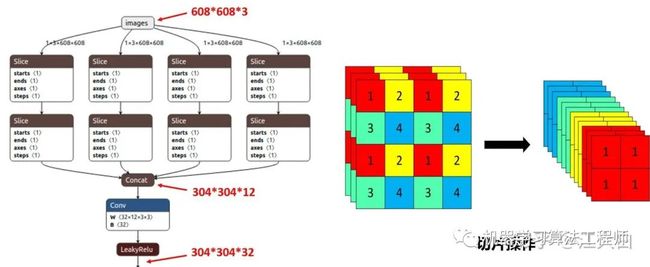
Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。
比如右图的切片示意图,4*4*3的图像切片后变成3*3*12的特征图。
以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加,先注意下,后面会讲解到四种结构的不同点。
(2)CSP结构
Yolov4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。

Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。
而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。

这里关于CSPNet的内容,也可以查看大白之前的《深入浅出Yolo系列之Yolov3&Yolov4核心基础完整讲解》。
2.2.3 Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。
因此,大白在Yolov5刚提出时,画的很多结构图,又都重新进行了调整。
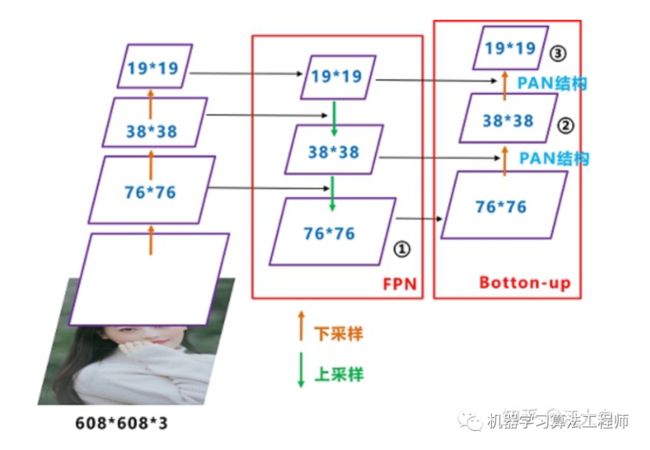
这里关于FPN+PAN的结构,大白在《深入浅出Yolo系列之Yolov3&Yolov4核心基础知识完整讲解》中,讲的很多,大家应该都有理解。
但如上面CSPNet结构中讲到,Yolov5和Yolov4的不同点在于,
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。

2.2.4 输出端
(1)Bounding box损失函数
在《深入浅出Yolo系列之Yolov3&Yolov4核心基础知识完整讲解》中,大白详细的讲解了IOU_Loss,以及进化版的GIOU_Loss,DIOU_Loss,以及CIOU_Loss。
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。

而Yolov4中采用CIOU_Loss作为目标Bounding box的损失,如果采用CIOU_Loss,应该会有更快更好的收敛效果。

(2)nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。
Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中仍然采用普通的nms的方式。
可以看出,下方中间箭头的黄色部分,原本被遮挡的摩托车也可以检出。

大白在项目中,也采用了DIOU_nms的方式,在同样的参数情况下,将nms中IOU修改成DIOU_nms。对于一些遮挡重叠的目标,确实会有一些改进。
比如下面黄色箭头部分,原本两个人重叠的部分,在参数和普通的IOU_nms一致的情况下,修改成DIOU_nms,可以将两个目标检出。
虽然大多数状态下效果差不多,但在不增加计算成本的情况下,有稍微的改进也是好的。

2.3 Yolov5四种网络结构的不同点
Yolov5代码中的四种网络,和之前的Yolov3,Yolov4中的cfg文件不同,都是以yaml的形式来呈现。
而且四个文件的内容基本上都是一样的,只有最上方的depth_multiple和width_multiple两个参数不同,很多同学看的一脸懵逼,不知道只通过两个参数是如何控制四种结构的?
2.3.1 四种结构的参数
大白先取出Yolov5代码中,每个网络结构的两个参数:
(1)Yolov5s.yaml
(2)Yolov5m.yaml
(3)Yolov5l.yaml
(4)Yolov5x.yaml
四种结构就是通过上面的两个参数,来进行控制网络的深度和宽度。其中depth_multiple控制网络的深度,width_multiple控制网络的宽度。
2.3.2 Yolov5网络结构
四种结构的yaml文件中,下方的网络架构代码都是一样的。
为了便于讲解,大白将其中的Backbone部分提取出来,讲解如何控制网络的宽度和深度,yaml文件中的Head部分也是同样的原理。

在对网络结构进行解析时,yolo.py中下方的这一行代码将四种结构的depth_multiple,width_multiple提取出,赋值给gd,gw。后面主要对这gd,gw这两个参数进行讲解。
下面再细致的剖析下,看是如何控制每种结构,深度和宽度的。
2.3.3 Yolov5四种网络的深度

(1)不同网络的深度
在上图中,大白画了两种CSP结构,CSP1和CSP2,其中CSP1结构主要应用于Backbone中,CSP2结构主要应用于Neck中。
需要注意的是,四种网络结构中每个CSP结构的深度都是不同的。
a.以yolov5s为例,第一个CSP1中,使用了1个残差组件,因此是CSP1_1。而在Yolov5m中,则增加了网络的深度,在第一个CSP1中,使用了2个残差组件,因此是CSP1_2。
而Yolov5l中,同样的位置,则使用了3个残差组件,Yolov5x中,使用了4个残差组件。
其余的第二个CSP1和第三个CSP1也是同样的原理。
b.在第二种CSP2结构中也是同样的方式,以第一个CSP2结构为例,Yolov5s中使用了3个残差组件,因此是CSP2_3。
而Yolov5m中使用了5个,Yolov5l中使用了7个,Yolov5x中使用了9个。
其他的四个CSP2结构,也是同理。
Yolov5中,网络的不断加深,也在不断增加网络特征提取和特征融合的能力。
(2)控制深度的代码
控制四种网络结构的核心代码是yolo.py中下面的代码,存在两个变量,n和gd。
我们再将n和gd带入计算,看每种网络的变化结果。

(3)验证控制深度的有效性
我们选择最小的yolov5s.yaml和中间的yolov5l.yaml两个网络结构,将gd(height_multiple)系数带入,看是否正确。
其中height_multiple=0.33,即gd=0.33,而n则由上面红色框中的信息获得。
以上面网络框图中的第一个CSP1为例,即上面的第一个红色框。n等于第二个数值3。
而gd=0.33,带入(2)中的计算代码,结果n=1。因此第一个CSP1结构内只有1个残差组件,即CSP1_1。
第二个CSP1结构中,n等于第二个数值9,而gd=0.33,带入(2)中计算,结果n=3,因此第二个CSP1结构中有3个残差组件,即CSP1_3。
第三个CSP1结构也是同理,这里不多说。
b. yolov5l.xml
其中height_multiple=1,即gd=1
和上面的计算方式相同,第一个CSP1结构中,n=1,带入代码中,结果n=3,因此为CSP1_3。
下面第二个CSP1和第三个CSP1结构都是同样的原理。
2.3.4 Yolov5四种网络的宽度
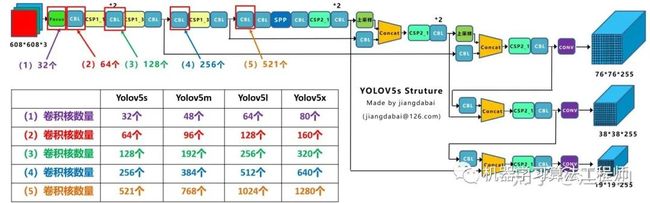
(1)不同网络的宽度:
如上图表格中所示,四种yolov5结构在不同阶段的卷积核的数量都是不一样的,因此也直接影响卷积后特征图的第三维度,即厚度,大白这里表示为网络的宽度。
a.以Yolov5s结构为例,第一个Focus结构中,最后卷积操作时,卷积核的数量是32个,因此经过Focus结构,特征图的大小变成304*304*32。
而yolov5m的Focus结构中的卷积操作使用了48个卷积核,因此Focus结构后的特征图变成304*304*48。yolov5l,yolov5x也是同样的原理。
b. 第二个卷积操作时,yolov5s使用了64个卷积核,因此得到的特征图是152*152*64。而yolov5m使用96个特征图,因此得到的特征图是152*152*96。yolov5l,yolov5x也是同理。
c. 后面三个卷积下采样操作也是同样的原理,这样大白不过多讲解。
四种不同结构的卷积核的数量不同,这也直接影响网络中,比如CSP1,CSP2等结构,以及各个普通卷积,卷积操作时的卷积核数量也同步在调整,影响整体网络的计算量。
大家最好可以将结构图和前面第一部分四个网络的特征图链接,对应查看,思路会更加清晰。
当然卷积核的数量越多,特征图的厚度,即宽度越宽,网络提取特征的学习能力也越强。
(2)控制宽度的代码
在yolov5的代码中,控制宽度的核心代码是yolo.py文件里面的这一行:
它所调用的子函数make_divisible的功能是:
(3)验证控制宽度的有效性
我们还是选择最小的yolov5s和中间的yolov5l两个网络结构,将width_multiple系数带入,看是否正确。

a. yolov5x.yaml
其中width_multiple=0.5,即gw=0.5。
以第一个卷积下采样为例,即Focus结构中下面的卷积操作。
按照上面Backbone的信息,我们知道Focus中,标准的c2=64,而gw=0.5,代入(2)中的计算公式,最后的结果=32。即Yolov5s的Focus结构中,卷积下采样操作的卷积核数量为32个。
再计算后面的第二个卷积下采样操作,标准c2的值=128,gw=0.5,代入(2)中公式,最后的结果=64,也是正确的。
b. yolov5l.yaml
其中width_multiple=1,即gw=1,而标准的c2=64,代入上面(2)的计算公式中,可以得到Yolov5l的Focus结构中,卷积下采样操作的卷积核的数量为64个,而第二个卷积下采样的卷积核数量是128个。
另外的三个卷积下采样操作,以及yolov5m,yolov5x结构也是同样的计算方式,大白这里不过多解释。
3 Yolov5相关论文及代码
3.1 代码
Yolov5的作者并没有发表论文,因此只能从代码角度进行分析。
Yolov5代码:github.com/ultralytics/
大家可以根据网页的说明,下载训练,及测试,流程还是比较简单的。
3.2 相关论文
另外一篇论文,PP-Yolo,在Yolov3的原理上,采用了很多的tricks调参方式,也挺有意思。
感兴趣的话可以参照另一个博主的文章:点击查看
4 小目标分割检测
目标检测发展很快,但对于小目标的检测还是有一定的瓶颈,特别是大分辨率图像小目标检测。比如7920*2160,甚至16000*16000的图像。

图像的分辨率很大,但又有很多小的目标需要检测。但是如果直接输入检测网络,比如yolov3,检出效果并不好。
主要原因是:
(1)小目标尺寸
以网络的输入608*608为例,yolov3、yolov4,yolov5中下采样都使用了5次,因此最后的特征图大小是19*19,38*38,76*76。
三个特征图中,最大的76*76负责检测小目标,而对应到608*608上,每格特征图的感受野是608/76=8*8大小。
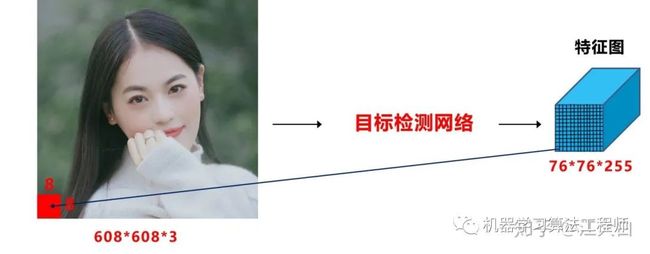
再将608*608对应到7680*2160上,以最长边7680为例,7680/608*8=101。
即如果原始图像中目标的宽或高小于101像素,网络很难学习到目标的特征信息。
(PS:这里忽略多尺度训练的因素及增加网络检测分支的情况)
(2)高分辨率
而在很多遥感图像中,长宽比的分辨率比7680*2160更大,比如上面的16000*16000,如果采用直接输入原图的方式,很多小目标都无法检测出。
(3)显卡爆炸
很多图像分辨率很大,如果简单的进行下采样,下采样的倍数太大,容易丢失数据信息。
但是倍数太小,网络前向传播需要在内存中保存大量的特征图,极大耗尽GPU资源,很容易发生显存爆炸,无法正常的训练及推理。
因此可以借鉴2018年YOLT算法的方式,改变一下思维,对大分辨率图片先进行分割,变成一张张小图,再进行检测。
需要注意的是:
为了避免两张小图之间,一些目标正好被分割截断,所以两个小图之间设置overlap重叠区域,比如分割的小图是960*960像素大小,则overlap可以设置为960*20%=192像素。

每个小图检测完成后,再将所有的框放到大图上,对大图整体做一次nms操作,将重叠区域的很多重复框去除。
这样操作,可以将很多小目标检出,比如16000*16000像素的遥感图像。

无人机视角下,也有很多小的目标。大白也进行了测试,效果还是不错的。
比如下图是将原始大图->416*416大小,直接使用目标检测网络输出的效果:
可以看到中间黄色框区域,很多汽车检测漏掉。
再使用分割的方式,将大图先分割成小图,再对每个小图检测,可以看出中间区域很多的汽车都被检测出来:

不过这样的方式有优点也有缺点:
优点:
(1)准确性
分割后的小图,再输入目标检测网络中,对于最小目标像素的下限会大大降低。
比如分割成608*608大小,送入输入图像大小608*608的网络中,按照上面的计算方式,原始图片上,长宽大于8个像素的小目标都可以学习到特征。
(2)检测方式
在大分辨率图像,比如遥感图像,或者无人机图像,如果无需考虑实时性的检测,且对小目标检测也有需求的项目,可以尝试此种方式。
缺点:
(1)增加计算量
比如原本7680*2160的图像,如果使用直接大图检测的方式,一次即可检测完。
但采用分割的方式,切分成N张608*608大小的图像,再进行N次检测,会大大增加检测时间。
借鉴Yolov5的四种网络方式,我们可以采用尽量轻的网络,比如Yolov5s网络结构或者更轻的网络。
当然Yolov4和Yolov5的网络各有优势,我们也可以借鉴Yolov5的设计方式,对Yolov4进行轻量化改造,或者进行剪枝。
5 后语
综合而言,在实际测试中,Yolov4的准确性有不错的优势,但Yolov5的多种网络结构使用起来更加灵活,我们可以根据不同的项目需求,取长补短,发挥不同检测网络的优势。
希望在人工智能的道路上,和大家共同进步。
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

