由浅入深尝试图书分类任务实战(特征工程+GBDT、机器学习模型、深度学习模型)
文章目录
- 引言
- 任务说明
- 数据集
- 0. 文本预处理
- 1. 训练Embedding
-
- 1.1 Tfidf
- 1.2 word2vec
- 1.3 FastText
- 1.4 LDA
- 1.5 存储模型
- 1.6 加载模型
- 2. 特征工程+GBDT
-
- 2.1 特征工程
-
- 2.1.1 Tfidf特征
- 2.1.2 词向量特征挖掘
-
- 2.1.2.1 w2v全局粒度句向量
- 2.1.2.2 滑动窗口粒度句向量
- 2.1.2.3 与Label交互句向量
- 2.1.3 basic特征
- 2.1.4 LDA特征
- 2.1.5 图像封面特征
- 2.1.6 BERT预训练句向量
- 2.1.7 特征拼接
- 2.2 不平衡数据处理,采样技术
- 2.3 GBDT+参数搜索
-
- 2.3.1 网格搜索
- 2.3.2 贝叶斯优化(BO)
- 3. 机器学习模型
-
- 3.1 词向量选择
- 3.2 机器学习模型选择
- 3.3 实验结果
-
- 3.3.1 Tfidf
- 3.3.2 word2vec
- 3.3.3 FastText
- 3.4 结果分析
- 4. 深度学习模型
-
- 4.1 数据集处理
-
- 4.1.1 构建词典
- 4.1.2 自己动手构建Dataset
- 4.1.3 自己动手构建Dataloader
- 4.2 模型设计
-
- 4.2.1 BERT
- 4.2.2 XLNet
- 4.2.3 Roberta
- 4.2.4 CNN
- 4.2.5 RNN
- 4.2.6 RCNN
- 4.2.7 RNN_ATT
- 4.2.8 Transformer
- 4.3 训练器设计
引言
在本项目中,我们主要来解决文本单标签的任务。数据源来自于京东电商, 任务是基于图书的相关描述和图书的封面图片,自动给一个图书做类目的分类。这种任务也叫作多模态分类。
在这个实战中,可以掌握学习到以下的代码实践:
文本特征提取:任何建模环节都需要特征提取的过程,你将会学到如何使用 tfidf、wor2vec、FastText 等技术来设计文本特征。图片特征提取:由于项目是多模态分类,图片数据也是输入信号的一 部分。你可以掌握如何通过预训练好的 CNN 来提取图片的特征, 并且结合文本向量一起使用。特征工程搭建:对于一个文本,如何使用更多的特征,包括 LDA特征、窗口词向量、包括label交互词向量、bert预训练句向量、基于统计的基本NLP特征等等。标签不平衡处理:由于本项目数据集中的标签类别较多,但是不同类别样本的数量差异较大, 即存在标签不平衡的情况。为了解决该问题,引入了BalancedBaggingClassifier、 SMOTE 和 ClusterCentroids。参数搜索优化:由于使用模型参数比较多,所以要进行参数选择优化,这里我们包括网格搜索优化和贝叶斯优化。经典机器学习模型搭建:包括RandomForestClassifier随机森林,LogisticRegression逻辑回归,MultinomialNB朴素贝叶斯,SVC支持向量机,GBDT梯度提升决策树等等。经典的深度学习模型:包括RNN、CNN、RCNN、RNN_ATT、Transformer、BERT、XLNet、Roberta等等。可视化:对一个复杂模型的结果做一些 可视化分析,试图理解背后分类正确或者分类错误的原因。
任务说明
在本项目中,我们主要来解决文本单标签的任务。数据源来自于京东电商, 任务是基于图书的相关描述和图书的封面图片,自动给一个图书做类目的 分类。这种任务也叫作多模态分类。在本项目中,我们使用的是图书数据。每一本图书都录 属于列表中的一个类目,我们决定使用图书的二级类目作为样本的真实标签,比如 “中国文学”,“纪实文学”,“青春校园”等。在给定的数据集中,一共包含 33 个不同类别的标签。
我们具体实现方法有以下三种:
- 特征工程(图片特征、Tfidt特征、 LDA特征、窗口词向量、包括label交互词向量、bert预训练句向量、基本NLP特征)+ GBDT
- 机器学习模型 (包括RandomForestClassifier随机森林,LogisticRegression逻辑回归,MultinomialNB朴素贝叶斯,SVC支持向量机,GBDT梯度提升决策树)
- 深度学习模型(包括RNN、CNN、RCNN、RNN_ATT、Transformer、BERT、XLNet、Roberta)
数据集
对于标签的识别,我们主要采用两种数据,第一种是图书的内容简介,包括title、desc以及 label,如下图示:

第二种是图书的封面图,如下图所示:

0. 文本预处理
我们这里是对中文文本进行预处理,所以预处理的步骤和标准的大致相同,分为三步走:
- 将文本数据的title和desc拼接起来,用来建模图书文本特征
- 利用Jieba工具进行中文分词
- 进行去停用词(停用词单独保存在一个stopwords里)
# 拼接数据
self.train["text"] = self.train['title'] + self.train['desc']
self.dev["text"] = self.dev['title'] + self.dev['desc']
# 分词
self.train["queryCut"] = self.train["text"].apply(query_cut)
self.dev["queryCut"] = self.dev["text"].apply(query_cut)
# 过滤停止词
self.train["queryCutRMStopWord"] = self.train["queryCut"].apply(
lambda x: [word for word in x if word not in self.em.stopWords])
self.dev["queryCutRMStopWord"] = self.dev["queryCut"].apply(
lambda x: [word for word in x if word not in self.em.stopWords])
然后,我们将Label映射为一个id,方便后面处理:
labelName = self.train['label'].unique() # 全部label列表
labelIndex = list(range(len(labelName))) # 全部label标签
labelNameToIndex = dict(zip(labelName, labelIndex)) # label的名字对应标签的字典
# 将训练集中的label名字映射到标签并保存到列labelIndex中
self.train["labelIndex"] = self.train['label'].map(labelNameToIndex)
# 将测试集中的label名字映射到标签并保存到列labelIndex中
self.dev["labelIndex"] = self.dev['label'].map(labelNameToIndex)
1. 训练Embedding
这里我们训练得到的几个特征包括Tfidf、word2vec、FastText以及LDA
1.1 Tfidf
logger.info('train tfidf')
count_vect = TfidfVectorizer(stop_words=self.stopWords,
max_df=0.4,
min_df=0.001,
ngram_range=(1, 2))
self.tfidf = count_vect.fit(self.data["text"])
1.2 word2vec
self.w2v = models.Word2Vec(min_count=2,
window=5,
size=300,
sample=6e-5,
alpha=0.03,
min_alpha=0.0007,
negative=15,
workers=4,
iter=30,
max_vocab_size=50000)
self.w2v.build_vocab(self.data["text"])
self.w2v.train(self.data["text"],
total_examples=self.w2v.corpus_count,
epochs=15,
report_delay=1)
1.3 FastText
self.fast = models.FastText(
self.data["text"],
size=300,
window=3,
alpha=0.03,
min_count=2,
iter=30,
max_n=3,
word_ngrams=2,
max_vocab_size=50000)
1.4 LDA
self.id2word = gensim.corpora.Dictionary(self.data.text)
corpus = [self.id2word.doc2bow(text) for text in self.data.text]
self.LDAmodel = LdaMulticore(corpus=corpus,
id2word=self.id2word,
num_topics=30,
workers=4)
1.5 存储模型
logger.info('save tfidf model')
joblib.dump(self.tfidf, root_path + '/model/embedding/tfidf')
logger.info('save w2v model')
self.w2v.wv.save_word2vec_format(root_path +
'/model/embedding/w2v.bin',
binary=False)
logger.info('save fast model')
self.fast.wv.save_word2vec_format(root_path +
'/model/embedding/fast.bin',
binary=False)
logger.info('save lda model')
self.LDAmodel.save(root_path + '/model/embedding/lda')
这里我们一般这个使用gensim的存储词向量,主要是两种,一种是我们的上述方式,另外一种是model.save(),后者是带模型一起保存了。为了减少内存加快速度,我们使用了前者方式。
1.6 加载模型
logger.info('load tfidf model')
self.tfidf = joblib.load(root_path + '/model/embedding/tfidf')
logger.info('load w2v model')
self.w2v = models.KeyedVectors.load_word2vec_format(
root_path + '/model/embedding/w2v.bin', binary=False)
logger.info('load fast model')
self.fast = models.KeyedVectors.load_word2vec_format(
root_path + '/model/embedding/fast.bin', binary=False)
logger.info('load lda model')
self.lda = LdaModel.load(root_path + '/model/embedding/lda')
2. 特征工程+GBDT
2.1 特征工程
接下来我们将进行一个特征工程的搭建,就是给定数据后,我们尽可能的利用特征工程提取数据更多的特征,挖掘更多的信息。
具体来说一个样本的特征是由下面组成的(~右侧是维度):
- tfidf ~ 7621
- 词向量特征挖掘 ~ 3000(300x10,具体是由图示w2v开头的10个特征,各自是300维)
- basic NLP特征 ~ 22
- LDA特征 ~ 30 (我们LDA主题分类设为30类)
- 图片特征 ~ 1000
- BERT预训练句向量特征 ~ 768
2.1.1 Tfidf特征
我们用我们训练好的Tfidf来表示句子特征:
# 根据过滤停止词后的数据, 获取tfidf 特征
data["queryCutRMStopWords"] = data["queryCutRMStopWord"].apply( lambda x: " ".join(x))
tfidf_data = pd.DataFrame( tfidf.transform(data["queryCutRMStopWords"].tolist()).toarray())
tfidf_data.columns = ['tfidf' + str(i) for i in range(tfidf_data.shape[1])]
读取后如下图所示(以5个数据为例):

2.1.2 词向量特征挖掘
我们这里采用的训练好的w2v词向量来表征句向量。具体表征可以参考下面阿里巴巴这个图,可以分为三部分,一个是全局的Avg/Max,另外一个是窗口(2、3、4)的Avg/Max,还有一个是和label标签计算一个attention。

首先,加载我们刚才训练好的w2v词向量,来获取输入的每个单词表征。
print("transform w2v")
data['w2v'] = data["queryCutRMStopWord"].apply(
lambda x: wam(x, embedding_model, aggregate=False)) #[seq_len * 300]
2.1.2.1 w2v全局粒度句向量
print('generate embedding max/mean')
# 将embedding 进行max, mean聚合
data[model_name + '_mean'] = data[model_name].progress_apply(
lambda x: np.mean(np.array(x), axis=0))
data[model_name + '_max'] = data[model_name].progress_apply(
lambda x: np.max(np.array(x), axis=0))
2.1.2.2 滑动窗口粒度句向量
def Find_embedding_with_windows(embedding_matrix, window_size=2, method='mean'):
# 最终的词向量
result_list = []
# 遍历input的长度, 根据窗口的大小获取embedding, 进行mean操作, 然后将得到的结果extend到list中, 最后进行mean max 聚合
for k1 in range(len(embedding_matrix)):
# 如何当前位置 + 窗口大小 超过input的长度, 则取当前位置到结尾
# mean 操作后要reshape 为 (1, 300)大小
if int(k1 + window_size) > len(embedding_matrix):
result_list.extend( np.mean(embedding_matrix[k1:], axis=0).reshape(1, 300))
else:
result_list.extend( np.mean(embedding_matrix[k1:k1 + window_size], axis=0).reshape(1, 300))
if method == 'mean':
return np.mean(result_list, axis=0)
else:
return np.max(result_list, axis=0)
2.1.2.3 与Label交互句向量
首先获取标签label的embedding,然后和输入文本的embedding进行交互。这个实现是根据论文《joint embdeeing of words and labels》来 获取标签交互的嵌入。
def Find_Label_embedding(example_matrix, label_embedding, method='mean'):
'''
@description: 根据论文《Joint embedding of words and labels》获取标签空间的词嵌入
'''
# 根据矩阵乘法来计算label与word之间的相似度
similarity_matrix = np.dot(example_matrix, label_embedding.T) / (
np.linalg.norm(example_matrix) * (np.linalg.norm(label_embedding)))
# 然后对相似矩阵进行均值池化,则得到了“类别-词语”的注意力机制
# 这里可以使用max-pooling和mean-pooling
attention = similarity_matrix.max()
attention = softmax(attention)
# 将样本的词嵌入与注意力机制相乘得到
attention_embedding = example_matrix * attention
if method == 'mean':
return np.mean(attention_embedding, axis=0)
else:
return np.max(attention_embedding, axis=0)
具体一个样本得到的特征可以表示如下:

2.1.3 basic特征
获取基本的 NLP feature,这些文本的基本特征容易被人忽略,但往往会起到奇效,例如一句话中含有多少形容词、动词或者含有多少特殊符号等等。
df['length'] = df['queryCut'].progress_apply(lambda x: len(x)) # 文本的长度
df['capitals'] = df['queryCut'].progress_apply(lambda x: sum(1 for c in x if c.isupper())) # 大写的个数
df['caps_vs_length'] = df.progress_apply(lambda row: float(row['capitals']) / float(row['length']), axis=1) # 大写 与 文本长度的占比
df['num_exclamation_marks'] = df['queryCut'].progress_apply(lambda x: x.count('!')) # 感叹号的个数
df['num_question_marks'] = df['queryCut'].progress_apply(lambda x: x.count('?')) # 问号个数
df['num_punctuation'] = df['queryCut'].progress_apply(lambda x: sum(x.count(w) for w in string.punctuation)) # 标点符号个数
df['num_symbols'] = df['queryCut'].progress_apply(lambda x: sum(x.count(w) for w in '*&$%')) # *&$%字符的个数
df['num_words'] = df['queryCut'].progress_apply(lambda x: len(x)) # 词的个数
df['num_unique_words'] = df['queryCut'].progress_apply(lambda x: len(set(w for w in x))) # 唯一词的个数
df['words_vs_unique'] = df['num_unique_words'] / df['num_words'] # 唯一词 与总词数的比例
df['nouns'], df['adjectives'], df['verbs'] = zip( *df['text'].progress_apply(lambda x: tag_part_of_speech(x))) # 获取名词, 形容词, 动词的个数, 使用tag_part_of_speech函数
df['nouns_vs_length'] = df['nouns'] / df['length'] # 名词占总长度的比率
df['adjectives_vs_length'] = df['adjectives'] / df['length'] # 形容词占总长度的比率
df['verbs_vs_length'] = df['verbs'] / df['length'] # 动词占总长度的比率
df['nouns_vs_words'] = df['nouns'] / df['num_words'] # 名词占总词数的比率
df['adjectives_vs_words'] = df['adjectives'] / df['num_words'] # 形容词占总词数的比率
df['verbs_vs_words'] = df['verbs'] / df['num_words'] # 动词占总词数的比率
df["count_words_title"] = df["queryCut"].progress_apply(lambda x: len([w for w in x if w.istitle()])) # 首字母大写其他小写的个数
df["mean_word_len"] = df["queryCut"].progress_apply(lambda x: np.mean([len(w) for w in x])) # 平均词的个数
df['punct_percent'] = df['num_punctuation'] * 100 / df['num_words'] # 标点符号的占比
其中我们获得名词和形容词以及动词用到了词性标注,这里我们借助jieba.posseg的工具来进行:
# 获取文本的词性, 并计算名词,动词, 形容词的个数
words = [tuple(x) for x in list(pseg.cut(data))]
noun_count = len([w for w in words if w[1] in ('n', 'nr', 'ns', 'nt', 'nz')])
adjective_count = len([w for w in words if w[1] in ('aj', 'a', 'ag', 'ad', 'an')])
verb_count = len([w for w in words if w[1] in ('vg', 'v', 'vd', 'vn')])
具体一个样本得到的特征可以表示如下:
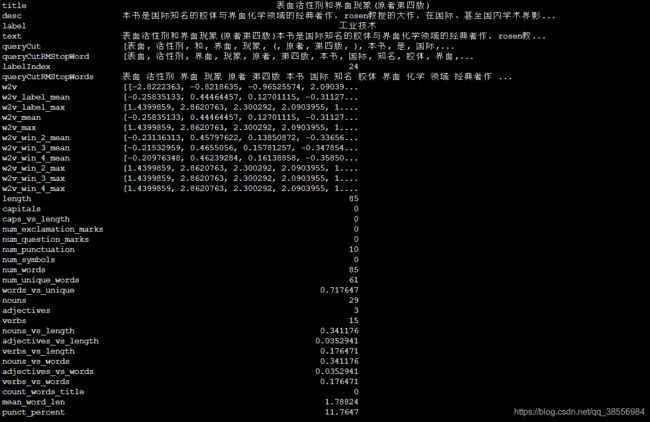
2.1.4 LDA特征
# 生成bag of word格式数据
train['bow'] = train['queryCutRMStopWord'].apply(lambda x: self.ml_data.em.lda.id2word.doc2bow(x))
test['bow'] = test['queryCutRMStopWord'].apply(lambda x: self.ml_data.em.lda.id2word.doc2bow(x))
# 在bag of word 基础上得到lda的embedding
train['lda'] = list( map(lambda doc: get_lda_features(self.ml_data.em.lda, doc), train['bow']))
test['lda'] = list(map(lambda doc: get_lda_features(self.ml_data.em.lda, doc), test['bow']))
得到的bow形式如下:

其中具体的get_lda_features定义如下:
def get_lda_features(lda_model, document):
# 基于bag of word 格式数据获取lda的特征
topic_importances = lda_model.get_document_topics(document, minimum_probability=0)
topic_importances = np.array(topic_importances)
return topic_importances[:, 1]
2.1.5 图像封面特征
关于图像封面的图像特征,我们先采用torchvision 初始化预训练好的 resnet152模型,这里也可以试着一下别的模型,例如resnext101_32x8d,wide_resnet101_2 :
import torchvision
# 加载图像处理模型, resnet, resnext, wide resnet, 如果支持cuda, 则将模型加载到cuda中
self.res_model = torchvision.models.resnet152(pretrained=True) # model feature [1* 1000]
self.res_model = self.res_model.to(config.device)
#self.resnext_model = torchvision.models.resnext101_32x8d(pretrained=True)
#self.resnext_model = self.resnext_model.to(config.device)
#self.wide_model = torchvision.models.wide_resnet101_2
#self.wide_model = self.wide_model.to(config.device)
然后对于输入的图片,我们首先像图像任务一样对图像进行一个归一化的处理(3x256x56),方便进入resnet模型进行特征提取:
def get_transforms():
'''
@description: transform image data
@return:transformed data
'''
# 将图片数据处理为统一格式
return transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.46777044, 0.44531429, 0.40661017],
std=[0.12221994, 0.12145835, 0.14380469],),
])
完成 image 特征的获取
def get_img_embedding(cover, model):
# 处理图片数据, 传入的不是图片则 生成(1, 1000)的0向量
transforms = get_transforms()
if str(cover)[-3:] != 'jpg':
return np.zeros((1, 1000))[0]
image = Image.open(cover).convert("RGB")
image = transforms(image).to(config.device)
return model(image.unsqueeze(0)).detach().cpu().numpy()[0]
2.1.6 BERT预训练句向量
首先加载预训练好的中文bert模型,这里我们选择的是Hugging Face的中文bert模型。
# 加载 bert 模型, 如果支持cuda, 则将模型加载到cuda中
self.bert_tonkenizer = BertTokenizer.from_pretrained(config.root_path + '/model/bert')
self.bert = BertModel.from_pretrained(config.root_path + '/model/bert')
self.bert = self.bert.to(config.device)
然后对于一个文本,我们将他输入到bert模型中去,提取到一个句子特征。我们这里使用了tokenizer的encode方法,方法可以一步到位地生成对应模型的输入。
在这里bert模型有两个输入,我们选的后者 Last layer hidden-state of the first token of the sequence (classification token)
def get_pretrain_embedding(text, tokenizer, model):
# 通过bert tokenizer 来处理数据, 然后使用bert model 获取bert embedding
text_dict = tokenizer.encode_plus(
text,
add_special_tokens=True, # Add '[CLS]' and '[SEP]'
max_length=400,
ad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
input_ids, attention_mask, token_type_ids = text_dict['input_ids'], text_dict['attention_mask'], text_dict['token_type_ids']
_, res = model(input_ids.to(config.device),
attention_mask=attention_mask.to(config.device),
token_type_ids=token_type_ids.to(config.device))
return res.detach().cpu().numpy()[0]
2.1.7 特征拼接
我们上面几个步骤在很多维度和模态中得到了一个样本的特征表示,现在我们把这些特征拼接起来,具体来说一个样本的特征是由下面组成的(~右侧是维度):
- tfidf ~ 7621
- 词向量特征挖掘 ~ 3000(300x10,具体是由上面图示w2v开头的10个特征,各自是300维)
- basic NLP特征 ~ 22
- LDA特征 ~ 30 (我们LDA主题分类设为30类)
- 图片特征 ~ 1000
- BERT预训练句向量特征 ~ 768
下面图上面的是输入样本特征(以5个样本为例),下面的是5个样本对应的label。我们可以看到一个样本的特征维度是12441。

2.2 不平衡数据处理,采样技术
我们将上述特征融合后,就得到了所有样本的特征表示。然后我们这里为了处理有不平衡数据的情况,可以利用一些采样技术。我们下面这段代码包括可以进行上采样,下采样和集成处理方式。
方法一:通过上采样(过采样)的方法从原始数据集中抽样出平衡的数据集
SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。对于少数类样本a, 随机选择一个最近邻的样本b, 然后从a与b的连线上随机选取一个点c作为新的少数类样本。
if imbalance_method == 'over_sampling':
logger.info("Use SMOTE deal with unbalance data ")
self.X_train, self.y_train = SMOTE().fit_resample(
self.X_train, self.y_train)
self.X_test, self.y_test = SMOTE().fit_resample(
self.X_train, self.y_train)
model_name = 'lgb_over_sampling'
方法二:通过下采样(欠采样)的方法从原始数据集中抽样出平衡的数据集
原型生成方法将减少数据集的样本数量, 剩下的样本是由原始数据集生成的, 而不是直接来源于原始数据集。ClusterCentroids函数实现了上述功能: 每一个类别的样本都会用K-Means算法的中心点来进行合成, 而不是随机从原始样本进行抽取
elif imbalance_method == 'under_sampling':
logger.info("Use ClusterCentroids deal with unbalance data ")
self.X_train, self.y_train = ClusterCentroids(
random_state=0).fit_resample(self.X_train, self.y_train)
self.X_test, self.y_test = ClusterCentroids(
random_state=0).fit_resample(self.X_test, self.y_test)
model_name = 'lgb_under_sampling'
方法三:通过集成的方法从原始数据集中抽样出样本标签平衡的数据集
在机器学习中,集成方法会使用多种学习算法和技术,以获得比单独使用其中一个算法更好的性能(是的,就像一个民主投票系统)。当使用集合分类器时,bagging方法变得流行起来,它通过构建多个分类器在随机选择的不同数据集上进行训练。我们可以使用imblearn库中的BalancedBaggingClassifier。它允许在训练集成分类器中每个子分类器之前对每个子数据集进行重采样。具体的采样策略由sampling_strategy来控制,具体函数说明见官方源码。
elif imbalance_method == 'ensemble':
self.model = BalancedBaggingClassifier(
base_estimator=DecisionTreeClassifier(),
sampling_strategy='auto',
replacement=False,
random_state=0)
model_name = 'ensemble'
下图维为使用ClusterCentroids进行下采样的实例,从15个样本欠采样到10个样本。

2.3 GBDT+参数搜索
GBDT 的实现有很多种,在此我们使用微软开发的 LightGBM。GDBT 的超参数较多,为了找到模型最优的超参数组合,我们在项目中使用基于网格搜索的超参数优化算法来实现交叉验证。
LightGBM实现代码如下:
import lightgbm as lgb
self.model = lgb.LGBMClassifier(objective='multiclass',n_jobs=10,num_class=33,num_leaves=30,
reg_alpha=10,reg_lambda=200,ax_depth=3,learning_rate=0.05,
n_estimators=2000,bagging_freq=1,bagging_fraction=0.9,
feature_fraction=0.8,seed=1440)
2.3.1 网格搜索
网格搜索:网格搜索优化需要提前定义好各个超参数的范围,然后遍历 所有超参数组成的笛卡尔积的参数集合。通常网格优化的时间复杂度较大,消耗时间也比较长。
def Grid_Train_model(model, Train_features, Test_features, Train_label, Test_label):
# 构建训练模型并训练及预测
# 网格搜索
parameters = {
'max_depth': [3, 4, 5],
'learning_rate': [0.01, 0.05],
'n_estimators': [1000, 2000],
'subsample': [0.6, 0.75, 0.9],
'colsample_bytree': [0.6, 0.75, 0.9],
'reg_alpha': [5, 10],
'reg_lambda': [10, 30, 50]
}
gsearch = GridSearchCV(model, param_grid=parameters, scoring='accuracy',
cv=3, verbose=True)
gsearch.fit(Train_features, Train_label)
# 输出最好的参数
print("Best parameters set found on development set:{}".format(gsearch.best_params_))
return gsearch
2.3.2 贝叶斯优化(BO)
贝叶斯优化它的主要思想是,给定优化的目标函数 (广义的函数,只需指定输入和输出即可,无需知道内部结 构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布 (高 斯过程, 直到后验分布基本贴合于真实分布。简单的说,就是考虑了上一次参数信息,从而更好的调整当前的参数。
相比网格搜索和弹性搜索它的优势是:
- 贝叶斯调参采用高斯过程,会考虑到之前的参数信息,不断地更新先验;网格搜索则不会考虑先验信息。
- 贝叶斯调参迭代次数少,速度快;网格搜索会遍历所有的可能的参数组合,所以速度慢,参数多时易导致维度爆炸
- 贝叶斯调参针对非凸问题依然稳健;网格搜索针对非凸问题易得到局部最优
BO通过高斯过程回归(假设超参数间符合联合高斯分布)计算前面n个点的后验概率分布,得到每一个超参数在每一个取值点的期望均值和方差,其中均值代表这个点最终的期望效果,均值越大表示模型最终指标越大,方差表示这个点的效果不确定性,方差越大表示这个点不确定是否可能取得最大值非常值得去探索。因此选择均值大的点我们成为exploritation(开发),选择方差大的点我们称为exploration(探索)。
具体的一些形象讲解可以参考这篇博客 知乎 知乎2
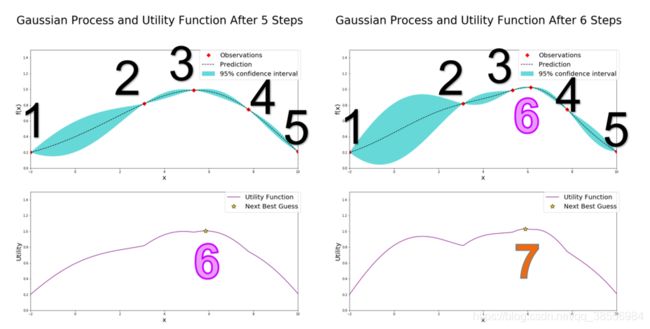
如左上图,在经过了五次迭代后,左上图已经有五个确定的点(红点标出),因此贝叶斯优化器需要根据已知的情况(五个确定的点)进一步猜测最大点在哪里,按照UCB策略,贝叶斯优化器就计算出左下的AC函数,而AC函数最大值就是贝叶斯优化器猜的第六个点的位置,计算该点的函数值,看右上图,发现点6确实比点3好一点,但是还达不到要求,继续猜第7个点的位置,就是右下图新的AC函数取得最大值的位置。
具体实现代码如下:
def bayes_parameter_opt_lgb(trn_data,init_round=3,opt_round=5,n_folds=5, n_estimators=10000,learning_rate=0.05):
# 定义搜索空间
def lgb_eval(num_leaves, feature_fraction, bagging_fraction, max_depth,
lambda_l1, lambda_l2, min_split_gain, min_child_weight):
params = {
'application': 'multiclass',
'num_iterations':n_estimators,
'learning_rate':learning_rate,
'early_stopping_round':100,
'num_class':len([x.strip() for x in open(config.root_path +'/data/class.txt').readlines()]),
'metric':'multi_logloss'
}
params["num_leaves"] = int(round(num_leaves))
params['feature_fraction'] = max(min(feature_fraction, 1), 0)
params['bagging_fraction'] = max(min(bagging_fraction, 1), 0)
params['max_depth'] = int(round(max_depth))
params['lambda_l1'] = max(lambda_l1, 0)
params['lambda_l2'] = max(lambda_l2, 0)
params['min_split_gain'] = min_split_gain
params['min_child_weight'] = min_child_weight
cv_result = lgb.cv(params,
trn_data,
nfold=n_folds,
seed=random_seed,
stratified=True,
verbose_eval=200)
return max(cv_result['multi_logloss-mean'])
# 搜索参数
lgbBO = BayesianOptimization(lgb_eval, {'num_leaves': (24, 45), 'feature_fraction': (0.1, 0.9),
'bagging_fraction': (0.8, 1), 'max_depth': (5, 8.99),'lambda_l1': (0, 5),
'lambda_l2': (0, 3),'min_split_gain': (0.001, 0.1), 'min_child_weight': (5, 50)}, random_state=0)
# optimize
lgbBO.maximize(init_points=init_round, n_iter=opt_round)
return lgbBO.max
3. 机器学习模型
我们在这里探索一下不同的词向量和不同的机器学习模型组合在我们这个数据集中的实现结果。我们这里的词向量有三种,包括tfidf、word2vec以及fasttext;我们的机器学习模型包括以下几种:随机森林、逻辑回归、朴素贝叶斯、支持向量机以及梯度提升决策树。
3.1 词向量选择
## tfidf
X_train, X_test, y_train, y_test = m.ml_data.process_data(method='tfidf')
## word2vec
m.model_select(X_train,X_test,y_train,y_test, feature_method='word2vec')
## fasttext
X_train, X_test, y_train, y_test = m.ml_data.process_data(method='fasttext')
这三种词向量方式的读取具体细节稍有不同,代码如下:
def get_feature(self, data, method='word2vec'):
if method == 'tfidf':
data = [' '.join(query) for query in data["queryCutRMStopWord"]]
return self.em.tfidf.transform(data)
elif method == 'word2vec':
return np.vstack(data['queryCutRMStopWord'].apply(
lambda x: wam(x, self.em.w2v)[0]))
elif method == 'fasttext':
return np.vstack(data['queryCutRMStopWord'].apply(
lambda x: wam(x, self.em.fast)[0]))
else:
NotImplementedError
3.2 机器学习模型选择
我们的机器学习模型包括以下几种:随机森林、逻辑回归、朴素贝叶斯、支持向量机以及梯度提升决策树。具体实现如下代码所示,简单的当一个调包侠即可hh,具体的实现细节以及算法原理需要去参考一下相关书籍和博客。
self.models = [
RandomForestClassifier(n_estimators=500, max_depth=5, random_state=0),
LogisticRegression(solver='liblinear', random_state=0),
MultinomialNB(),
SVC(),
lgb.LGBMClassifier(objective='multiclass',
n_jobs=10,num_class=33,num_leaves=30,
reg_alpha=10,reg_lambda=200,max_depth=3,
learning_rate=0.05,n_estimators=2000,bagging_freq=1,
bagging_fraction=0.8,feature_fraction=0.8)
]
3.3 实验结果
3.3.1 Tfidf
| 模型 | Train_acc | Test_acc |
|---|---|---|
| 随机森林 | 0.447 | 0.426 |
| 逻辑回归 | 0.721 | 0.657 |
| 朴素贝叶斯 | 0.477 | 0.463 |
| 支持向量机 | 0.775 | 0.723 |
| 梯度提升决策树 | 0.751 | 0.664 |
3.3.2 word2vec
| 模型 | Train_acc | Test_acc |
|---|---|---|
| 随机森林 | 0.435 | 0.418 |
| 逻辑回归 | 0.702 | 0.631 |
| 朴素贝叶斯 | 0.418 | 0.416 |
| 支持向量机 | 0.788 | 0.711 |
| 梯度提升决策树 | 0.745 | 0.653 |
3.3.3 FastText
| 模型 | Train_acc | Test_acc |
|---|---|---|
| 随机森林 | 0.444 | 0.415 |
| 逻辑回归 | 0.706 | 0.552 |
| 朴素贝叶斯 | 0.388 | 0.377 |
| 支持向量机 | 0.760 | 0.656 |
| 梯度提升决策树 | 0.732 | 0.633 |
3.4 结果分析
词向量模型比较
我们潜在的感觉应该是FastText>W2v>Tfidf,但是在我们目前的参数设计下,Tfidf效果最好,FastText效果最差。一是可能和我们的参数设计有关,一方面是机器学习模型的参数,另一方面是我们在第一部分训练词向量时设计的参数;
第二个原因可能是我们进入机器学习模型的参数,这里w2v和fasttext选择的是词向量的平均值,一个样本用一个数值来表示,可能建模的过于粗糙,或许也是效果比tfidf差的原因。
机器学习模型比较
- 随机森林根据实验结果显示,该模型的准确率大概在 0.4 左右,这个结果相对来说是比较低的,可以通过调节随机森林模型中 n_estimators,max_depth 等参数来提升模型性能。
- 实验结果显示逻辑回归模型的测试集的准确率大概在 0.6 左右,但是实验中训练集的准确率通常要高于测试集,因此可以认为该模型产生了一定的过拟合现象。
- 根据实验结果显示,朴素贝叶斯模型的实验效果大概在 0.35-0.45 之间,总体上低于其他分类模型。该模型效果较差主要是因为朴素贝叶斯模型假设样本特征之间是相互独立的,因此在特征之间关联度比价高的情况下该模型表现的会比较差。
- 支持向量机该分类模型的分类结果较好。可以发现 SVC 模型在训练集上的准确率要高于测试集,说明该模型同样具有一定程度的过拟合现象。同样可以考虑加入正则化操作来提高模型的泛化能力
- 梯度提升决策树效果也不错。该模型可以调整的参数很多,而且很容易产生过拟合,如果产生过拟合,可以过降低树的叶子结点个数(num_leaves),调整 L1 正则化(reg_alpha)和 L2 正则化(reg_lambda)参数以及降低树的深度(max_depth)
总的来说,朴素贝叶斯模型由于特征之间相互独立性的假设,导致其在大规模数据集上的效果最差。分类准确率
SVC > GBDT > LR > RandomForesst > MultiNB
4. 深度学习模型
4.1 数据集处理
我们在深度学习中所用到的模型有两种:
一种是常规的CNN/RNN/RNN_ATT/Transformer的**normal**模型等等;
另外一种是BERT、XLNet以及Roberta的**bert**模型。
所以我们数据集处理分为两种情况不同处理。
4.1.1 构建词典
对于Normal
我们对于Normal模型需要做到下面几个步骤:
- 输入样本数据,统计vocab的词频
- 构建词库,首先加入以下特殊字符PAD、UNK等,然后将单词根据词频由大到小加入词库(词库大小最多5w)。
- 然后构建单词到id的映射word2idx、id到单词的映射id2word以及id到单词数的映射id2count。
def _build_dictionary(self, data):
# 加入UNK标示, 按照需要加入EOS 或者EOS
vocab_words = [self.PAD_TOKEN, '' ]
vocab_size = 2
if self.start_end_tokens:
vocab_words += ['' , '' ]
vocab_size += 2
# 使用Counter 来同级次的个数
counter = Counter([word for sentence in data for word in sentence.split()])
# 按照最大的词典个数进行筛选
if self.max_vocab_size:
counter = {word: freq for word, freq in counter.most_common(self.max_vocab_size - vocab_size)}
# 过滤掉低频词
if self.min_count:
counter = {word: freq for word, freq in counter.items() if freq >= self.min_count}
# 按照出现次数进行排序, 并加到vocab_words 当中
vocab_words += list(sorted(counter.keys()))
idx2count = [counter.get(word, 0) for word in vocab_words]
word2idx = {word: idx for idx, word in enumerate(vocab_words)}
idx2word = vocab_words
return vocab_words, word2idx, idx2word, idx2count
对于BERT
我们直接记载bert/xlnet/roberta等模型公开的tokenzier,即可实现对文本一步到位的处理,可以说相当方便。
from transformers import BertTokenizer, RobertaTokenizer, XLNetTokenizer
if 'bert' in model_name:
config.tokenizer = BertTokenizer.from_pretrained(config.bert_path)
elif 'xlnet' in model_name:
config.tokenizer = XLNetTokenizer.from_pretrained(config.bert_path)
elif 'roberta' in model_name:
config.tokenizer = RobertaTokenizer.from_pretrained(config.bert_path)
else:
raise NotImplementedError
4.1.2 自己动手构建Dataset
自定义Dataset只需要一个class,继承自Dataset类。有三个私有函数:
def __init__(self, loader=default_loader):这个里面一般要初始化
def __getitem__(self, index):这里就是在给你一个index i i i的时候,返回的 x [ i ] x[i] x[i],需要重写。
def __len__(self):返回你所有数据的个数
其实__init__和__len__函数都比较好说,重点说一下__getitem__函数的设计:
normal模型:
使用自建的dictionary 来处理。
bert类模型:
使用tokenizer 的encode_plus方法处理数据。
代码如下:
def __getitem__(self, i):
data = self.data.iloc[i]
text = data['text']
labels = int(data['category_id'])
attention_mask, token_type_ids = [0], [0]
if 'bert' in self.model_name:
# 如果是bert类模型, 使用tokenizer 的encode_plus方法处理数据
text_dict = self.tokenizer.encode_plus(
text, # Sentence to encode.
add_special_tokens=True, # Add '[CLS]' and '[SEP]'
max_length=self.max_length, # Pad & truncate all sentences.
ad_to_max_length=True,
return_attention_mask=True, # Construct attn. masks.
)
input_ids, attention_mask, token_type_ids = text_dict['input_ids'], text_dict['attention_mask'], text_dict['token_type_ids']
else:
# 如果是cnn rnn, transformer则使用自建的dictionary 来处理
text = text.split()
text = text + [0] * max(0, self.max_length - len(text)) if len(text) < self.max_length else text[:self.max_length]
input_ids = [self.tokenizer.indexer(x) for x in text]
output = {
"token_ids": input_ids,
'attention_mask': attention_mask,
"token_type_ids": token_type_ids,
"labels": labels
}
return output
4.1.3 自己动手构建Dataloader
Dataset一次调用只是返回一条数据,在深度学习中,我们经常是对一个batch的数据进行操作,也就是一批一批数据交给模型训练,同时还需要对数据进行shuffle(打乱)操作和并行加速等等,这时候,使用Dataset就显得功能不太足够了,所以Pytorch提供了DataLoader给我们使用。
其中pytorch有个重要的参数叫做collate_fn,它是定义如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可。但是我们这里要进行一个padding的操作,还要注意对attention和type_id都要进行padding。
collate_fn代码如下:
def collate_fn(batch):
"""
动态padding, batch为一部分sample
"""
def padding(indice, max_length, pad_idx=0):
"""
pad 函数
注意 token type id 右侧pad 添加 0
"""
pad_indice = [
item + [pad_idx] * max(0, max_length - len(item))
for item in indice
]
return torch.tensor(pad_indice)
token_ids = [data["token_ids"] for data in batch]
max_length = max([len(t) for t in token_ids])
token_type_ids = [data["token_type_ids"] for data in batch]
attention_mask = [data["attention_mask"] for data in batch]
labels = torch.tensor([data["labels"] for data in batch])
token_ids_padded = padding(token_ids, max_length)
token_type_ids_padded = padding(token_type_ids, max_length)
attention_mask_padded = padding(attention_mask, max_length)
return token_ids_padded, attention_mask_padded, token_type_ids_padded, labels
Dataloader代码如下:
train_dataset = MyDataset(config.train_file,
dictionary,
args.max_length,
tokenizer=tokenizer,
word=args.word)
train_dataloader = DataLoader(train_dataset,
batch_size=config.batch_size,
shuffle=True,
drop_last=True,
collate_fn=collate_fn)
4.2 模型设计
4.2.1 BERT
bert实现很简单,直接在预训练的基础上加一层全连接层来进行微调。代码如下:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
model_config = BertConfig.from_pretrained(config.bert_path, num_labels=config.num_classes)
self.bert = BertModel.from_pretrained(config.bert_path, config=model_config)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[1] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
token_type_ids = x[2]
_, pooled = self.bert(context,attention_mask=mask,token_type_ids=token_type_ids)
out = self.fc(pooled)
return out
4.2.2 XLNet
XLNet的实现同理:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
model_config = XLNetConfig.from_pretrained(config.bert_path, num_labels=config.num_classes)
self.xlnet = XLNetForSequenceClassification.from_pretrained(config.bert_path, config=model_config)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[1] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
token_type_ids = x[2]
_, pooled = self.xlnet(context,attention_mask=mask,token_type_ids=token_type_ids)
out = self.fc(pooled)
return out
4.2.3 Roberta
Roberta实现同理:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
model_config = RobertaConfig.from_pretrained(config.bert_path, num_labels=config.num_classes)
self.roberta = RobertaForSequenceClassification.from_pretrained(config.bert_path, config=model_config)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[1] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
token_type_ids = x[2]
_, pooled = self.roberta(context, attention_mask=mask, token_type_ids=token_type_ids)
out = self.fc(pooled)
return out
4.2.4 CNN
这个CNN的实现和Text-CNN很相似:
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed)
self.convs = nn.ModuleList([nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
out = self.embedding(x[0])
out = out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
return out
4.2.5 RNN
这个RNN就是用的LSTM,利用句子最后一个单词的hdden-state来进行判断。
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=0)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
out = self.embedding(x[0]) # [batch_size, seq_len, embeding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
4.2.6 RCNN
这个RCNN模型来自于论文:Recurrent Convolutional Neural Networks for Text Classification
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=0)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
embed = self.embedding(x[0]) # [batch_size, seq_len, embeding]=[64, 32, 64]
out, _ = self.lstm(embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out)
out = out.squeeze()
out = self.fc(out)
return out
4.2.7 RNN_ATT
这个RNN_ATT模型来自于论文:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=0)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
self.w = nn.Parameter(torch.Tensor(config.hidden_size * 2))
self.tanh2 = nn.Tanh()
self.fc1 = nn.Linear(config.hidden_size * 2, config.hidden_size2)
self.fc = nn.Linear(config.hidden_size2, config.num_classes)
def forward(self, x):
emb = self.embedding(x[0]) # [batch_size, seq_len, embeding]=[128, 32, 300]
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size * num_direction]=[128, 32, 256]
M = self.tanh1(H) # [128, 32, 256]
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1) # [128, 32, 1]
out = H * alpha # [128, 32, 256]
out = torch.sum(out, 1) # [128, 256]
out = F.relu(out)
out = self.fc1(out)
out = self.fc(out) # [128, 64]
return out
4.2.8 Transformer
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=0)
self.postion_embedding = Positional_Encoding(config.embed, config.pad_size, config.dropout, config.device)
self.encoder = Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
self.encoders = nn.ModuleList([copy.deepcopy(self.encoder) for _ in range(config.num_encoder)])
self.fc1 = nn.Linear(config.pad_size * config.dim_model, config.num_classes)
def forward(self, x):
out = self.embedding(x[0])
out = self.postion_embedding(out)
for encoder in self.encoders:
out = encoder(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
return out
class Encoder(nn.Module):
def __init__(self, dim_model, num_head, hidden, dropout):
super(Encoder, self).__init__()
self.attention = Multi_Head_Attention(dim_model, num_head, dropout)
self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)
def forward(self, x):
out = self.attention(x)
out = self.feed_forward(out)
return out
4.3 训练器设计
这里没啥可说的,我们注意一下BERT类模型和Normal模型的优化器选择区别就好。
Normal模型:Adam
BERT模型:AdamW
if config.model_name.isupper():
print('User Adam...')
print(config.device)
optimizer = torch.optim.Adam(model.parameters(),
lr=config.learning_rate)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
else:
print('User AdamW...')
print(config.device)
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [{
'params': [
p for n, p in param_optimizer
if not any(nd in n for nd in no_decay)
],
'weight_decay':
0.01
}, {
'params':
[p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay':
0.0
}]
# optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
optimizer = AdamW(optimizer_grouped_parameters,
lr=config.learning_rate,
eps=config.eps)