sql优化 进阶
数据库性能之sql优化
随着我们业务水平扩展,数据库表的数据成倍递增,势必会给数据库造成压力,不能及时给我们的业务做出响应,之前也看了很多Blog关于数据库性能,sql优化相关的,总是没有找到合适的通俗易懂以及适用于平时开发中,很多写的比较专业导致很多初学者不太理解,笔者是喜欢用通俗易懂的表达方式来理解学习一个技能,下面我就几个大纲围绕来说下数据库性能优化的几方面,毕竟我也是菜鸟,有说的不对地方,请各位看官多多包涵,指正
- 1)优化sql和索引优化(重要)
- 2)利用redis加缓存
- 3)读写分离,主从复制或者主主复制
- 4 )利用分区表
- 5)最后是分库分表
以上按照顺序来解决,1解决不了就用2解决,2解决不了就用3解决,3不行就用4
先来了解下sql执行的整个过程,如下图的一个执行流程:
优化sql和索引优化
先说优化sql和索引优化,一般我们java开发来说,用这个差不多就能解决大部分的业务场景的问题了,也是最重要的一步,也就是我们要尽量避免全表扫描和扫描次数。
1)禁止在索引列上使用表达式和函数,否则会进行全表扫描。SELECT子句中使用distinct,尽量用exist代替distinct,用exist,只要找到第一个符合条件的值,就返回了,而不管后面有多少条符合条件的重复记录。而distinct是全扫描。为null的列不要建索引,为null的列值建索引也会被优化器排除,也就是说如果某列存在空值,即使对该列建索引也不会提高性能,索引尽量在有索引列上面禁止在where子句中使用is null或is not null的语句优化器是不允许使用索引的,where 子句中使用!=或<>操作符,否则优化器将放弃使用索引而进行全表扫描。禁止在索引字段上使用not,<>,!=,使用>=代替>效率会高些。尽量避免使用having函数( 注:sql语句的执行顺序on->where->group by->having,系统首先根据各个表之间的联接条件,把多个表合成一个临时表 后,再由where进行过滤,然后group by再计算,计算完后再由having进行过滤)所以我们尽量把having的条件用在where 后尽量过滤效率会高很多,再计算。
2)索引优化,在innoDB引擎索引长度最大支持767L,而在MyiSAM引擎中最大支持长度1000L,索引我们在建索引的时候可以根据内容指定索引的长度,比如一个字段列的值超过767,我们可以指定索引的长度( 如:create index index_name on table(column_name(length),这里前缀索引的长度和索引内容长度是相关的)。如果where 后面的字段较多且经常出现的查询列,可建联合索引(联合索引也可以减少多个单列索引的开销,联合索引遵循做匹配原则进行索引,选择性高的列放在索引的最左侧,联合索引where字句中出现>号,后面的索引字段将不能使用索引),一般btree索引都是进行了二次查询,在叶子节点找到键值,在根据键值查到对应的数据行。索引建多了势必会给insert和update造成压力,Btree索引的update操作可能会产生碎片,会降低查询时的效率问题,聚集索引的空间不连续之类的。optimize table table_name整理索引碎片,但是会锁表,索引尽量在用户量不多的情况下去维护。
注:sql排序方式有种:1,排序操作(全表扫描)。2,按索引顺序扫描。尽量使用索引扫描排序:①索引列的顺序和Oder by后字段顺序要一致②Oder by 后出现的字段尽量在where后也出现,尽量在第一个个关联表中,不能出现个别的字段升序和降序
3)索引优化锁至关重要,如果没有使用索引查找使用的排它锁是表级锁, 换言之如果使用索引查询加的排它锁是行级锁,行级锁可以增大并发,它的应用差劲比如抢购商品,大家都来update商品count时,这个时候这个商品数量在高并发的情况下是不准确的,所以用for update来加排它锁,其他查询就会阻塞。
4)sql语句的子查询优化: 对于where子句后面的查询,尽量转化为关联查询这样来优化。有时候我们会查询sql语句在哪个执行阶段消耗的时间比较多,可以利用mysql的profile命令来查看,在mysql5.7时候就弃用了可以用performation-schema来查询所消耗的时间。
5)如何优化not in和<>查询,前面我们强调尽量把where子查询优化成关联查询, 下面我们来看一个demo:A表是customer表也就是用户表,B表是payment缴费表。下面我们要查询没有交费的用户是哪些。一般情况下我们会用以下sql进行查询:select customer_id, username,mobile from customer where customer_id not in (select customer_id from payment) 这就会出现一个问题用户表的每个customer_id每次都会去payment找一遍,相当于A*B的一个过滤次数了。下面我们改成关联查询:select a.customer_id,a.username,a.mobile from customer a left join payment b on a.customer_id = b.customer_id where b.customer_id is null;提高了查询效率,过滤条数变成了A表的条数。有时候我们也会去亿级别的数据表做统计操作,比如我们有个亿级别的商品表product_count,我们要统计目前为止每个商品的购买数量,一般情况下是这样:select count(*) from product_count where product_id=’商品id’ 这样的话每次请求都会去查询计算,这样对临时表开销是很大的,数据库是吃不消的。我们换个思路,维护一个商品统计表product_count_s 表结构只有两个字段product_id,count,这个查询思路就变成了查询当天之前的记录数(这个记录数计算每晚凌晨12点就就存到维护到我们商品统计表中了)+当天的记录数(当天记录数可以根据时间索引进行查询速度会快很多),最后union all合并sum下就ok了
6)exist和in的效率问题(有争议):IN是把外表(也就是我们的子查询表)建一个hashtable,内表在hashtable中去找匹配项,思路是内表每行去hashtable中找匹配项,此时在hashtable中找匹配项如果用了索引,效率是非常高的。这个适合A表比较大的应用场景。如select*from A where id in(select id from B)。而exist是对内表进行loop循环,每次对B表进行loop时会使用B表的索引,效率是非常高的如:select *from A where exist (select id from where A.id=id) 总结:IN适合走外表数据量比较大的情况,exist适合走内表数据量比较大的情况,如果AB表数据相当,那么效率其实差不多。
7)大表的更新和删除,比如数据千万级别的表操作,尽量分批操作。如下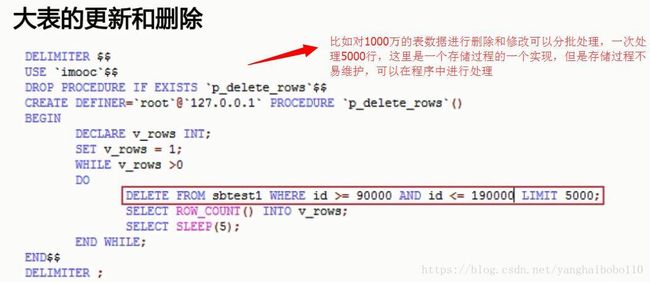
注:动态修改表结构的使用pt-online-schema-change来实现
利用redis加缓存
sql优化解决不了,那么我们可以用redis加缓存,在系统启动的时候就做一个数据的热处理提前加入到缓存中,以至于每次查询命中缓存。教程如下
https://www.cnblogs.com/Leo_wl/p/5791327.html
读写分离,主从复制或者主主复制
缓存解决不了,我们可以做读写分离,这里推荐360的Atlas配置高可用的读写分离。教程如下
https://www.cnblogs.com/alex-note/p/6835965.html
利用分区表
利用数据库的分区表做存储分区,这里我们说下分区和分表的区别,后面还会对分表做专门的介绍。分区的表的原理就是把一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。 mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完正的一张表,比如user表按userid分表后就是user_01和user_02。分区表mysql有专门的语句做分区存储,教程如下:
https://www.cnblogs.com/freeton/p/4265228.html
最后是分库分表
首先说一下oracle的分区表和表分区是不同的概念,其实就是oracle的分区表说的就是mysql的分区表,但是表分区说的就是mysql的分表操作,也就是我们所说的水平拆分。f分库分表也是我们所说的分库就是垂直拆分,分表就是水平拆分。
垂直拆分:把表按模块划分到不同数据库表中。
水平拆分:把一个大表的压力按照相同的表结构分到不同的数据库上或者同一个数据库中的拆分成多个表,每次存储根据分区建做hash取模运算判断出存在哪个字表上面。
垂直拆分:我用一个图来表明,通俗易懂
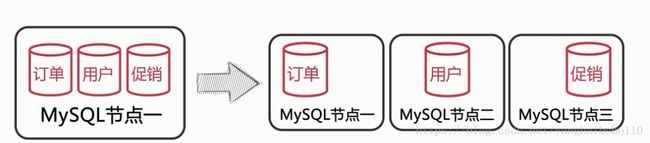
水平拆分:就是数据库的分表操作,水平拆分就是把一个表拆分成多个相同结构的子表根据分区键hash取模存储在不同的子表中,每一个字表代表一个分片,这样就减少我们单表操作大数据量的负载。分片的可以分在多个数据库实例中也可以分在一个数据库中,尽量避免跨分片的查询发生。比如我们的Blog,如果我们按照博客id进行hash只分片存储的话,那么统计某个特定用户博客条数的时候,我们就会发生跨分片查询,但是如果我们按照用户id进行分区建的分片的话,就能保证每个片存储特定用户的博客都在同一个分片上。还有尽量使各个分片的写负载都是平均的,因为我们的分区建hash值取模存储的话,不能控制存储在哪个分片上,就会发生某个分片上的写负载远高于其他的分片,我们的效果就没达到分片的目的。这个时候我们可以维护一个字典表,规定哪个范围内的数据存在哪个分片上面,这个表我们可以提前加载到内存中去。当然这里会有一个问题,因为现在每个分片都是一张实际存在的物理表,就会存在主键冲突的情况,因为每个表的自增id都是以表为隔离级别自增,我们必须需要一个全局的唯一ID做主键插入,可以用数据库来实现这个全局唯一id,这里推荐用redis缓存服务器来创建全局性的唯一ID。分片的工具可以用oneproxyp代理工具来做分片的存储写负载,增删改都是通过oneproxyp代理服务器去操作分片上的数据库的,实际还是单表操作。
有哪里写的不好的地方,希望各位老师多多指正,小弟尽量少用专业术语来描述,为了大家能够通俗易懂,同时也是给自己做一个笔记!