【弱监督学习】End-to-end weakly supervised semantic segmentation with reliable region mining
0.前言
这是一篇2022年发表在Pattern Recognition期刊上的一篇有关弱监督语义分割的文章。由于只使用图像级标签来训练语义分割模型扔充满挑战,并且现有弱监督方法都是两阶段的方法,缺少一个端对端的方法。所以本文提出了一个新的端对端弱监督语义分割方法。
1.介绍
只是用图像级标签来训练语义分割模型非常充满挑战性,这是因为没有像素级的标签可以供模型学习,模型不能直接学习到像素级到像素级的映射关系。使用图像级的标签来进行语义分割模型的弱监督学习现有的方法大致可以分为两类,一类是one-step的方法,另一类是two-step的方法。One-step方法一般就是来构建一个端到端的方法,引入多实例学习和一些其它限制条件来进行优化,它的好处是整体框架比较简单,缺点是精度一般较低;另一类方法是two-step的方法,它通常先利用某种方法来产生伪标签,然后利用伪标签来进行训练。它的有点事精度较高,缺点是伪标签生成得可能有振铃或其它类型的噪声,并且整体方案通常比较复杂,比较难以复现。
为了解决上述的问题,本文提出了一种比较简单的One-step弱监督语义分割方法——Reliable Region Mining(RPM).它有两个分支,一个分支用来产生伪标签,一个分支用来产生像素级分割结果。与现有的Two-step方法不同的是,在第二个分支使用伪标签来进行训练时,它只使用比较靠得住的伪标记像素来训练,本文引入CRF来进行值得信赖伪标签的选取。
2.方法
本文方法的整体框架如下图所示:
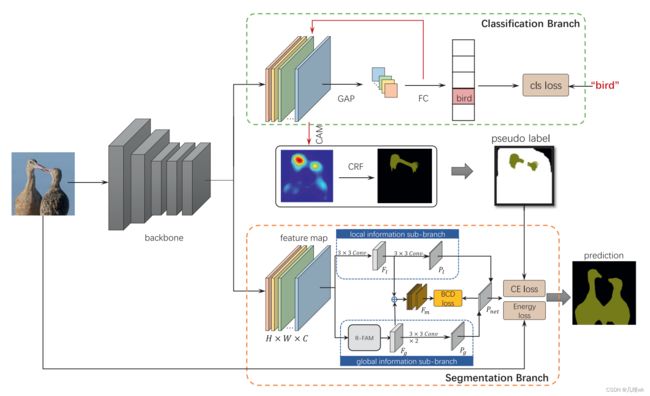
这个方法的Backbone采用一个含有38层卷积的ResNet结构,这个ResNet结构是在论文《Wider or deeper: revisiting the resnet model for visual recognition》中提出的,在Backbone之后分为两个分支:
- 分类分支:分类分支其实就是一个分类网络,它通过CAM和CRF产生比较可靠的伪标签;
- 分割分支:分割分支由两个分支组成,局部信息子分支和全部信息子分支,量分支经过信息融合和loss约束,并且以分类分支传来的伪标签作为监督信息,最终可以完成分割任务。
2.1 可靠伪标签的获取
伪标签的获取在现有的一些方法中,一般的流程是先使用CAM[1]方法来通过特征图获得最容易区分的区域的类别注意力map,然后再由CAM生成伪标签。
文章[1]中的CAM方法可以从特征图中获取到一个目标中最容易区分的区域,本文采用了一个多尺度的CAM方案来获得最容易区分的区域的类别注意力图,如下:

这里就不写CAM的公式了,这个CAM是有一个scale参数的,本文采用了多scale的方式来获得了一个更好的CAM。
获得了CAM以后,接下来就要获得靠得住的标签了,这里面作者是先引入了一个CRF[2]的前向推理过程,通过刚刚获得的多scaleCAM来获取到一个CRF标签,我们把这个标签记作 I c r f I_{crf} Icrf,这个东西写成公式就是:

里面的 I I I就是获得的哪个CAM, P f g P_{fg} Pfg和 P b g P_{bg} Pbg分别是前景和背景的概率,这个公式简单理解下就可以,实际使用时就是直接把CAM输入到CRF模型里面,然后就获得了一个输出。
接着,为了能够获得最后的靠得住的标签,作者先在CAM中获得了可靠的CAM标签,直接是根据下面的公式:

其实就是设置了一个阈值,当概率大于一定的阈值,就判定它为哪个类。
最后取刚刚两个的 I c r f I_{crf} Icrf和 I c a m I_{cam} Icam的交集,就构成了最后的reliable label,一个范例如下:

这里面白色的区域也就是Unreliable的区域。
[1] Learning deep features for discriminative localization CVPR 2016
[2]Parameter learning and convergent inference for dense random fields ICML 2013
2.2分割分支中的两个子分支
首先,和其它的Two-step方法不一样的是,分割分支和分类分支虽然类似Two-step方法,但是它们共享一个backbone的权重,所以还算是个One-step。那么分割分支中又细分了两个子结构,那就是局部信息子分支和全局信息子分支。
局部信息子分支就是用两个简单的卷积来从特征图中提取局部信息,结构比较简单。而全局信息子分支中,为了更好的提取有用的信息,作者新设计了一个R-FAM结构,如下图所示:
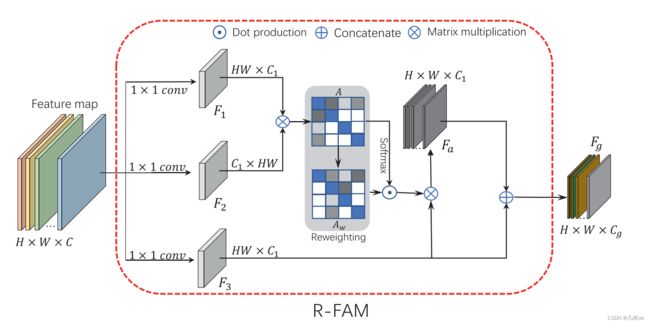
引入这个结构是想让全局信息子分支能够更好的提取到全局的特征信息,毕竟只依靠简单的卷积层是无法从有限的可依靠的伪标签中学习到所有的像素级标注,比如上面讲的那个例子,伪标签就只包括了鸟头。通过这个R-FAM中的Reweighting操作能够抑制网络对低级和高级特征的注意力,从而产生更加中级的特征,也就是更加关注全局的特征。这里对于低级、中级和高级特征的理解可以是低级特征更偏空间特征,高级特征更偏语义特征,而中级特征则是比较两者兼顾,是更有利于我们进行分割的一种特征,因为我们的标签空间特征不完整,所以需要这样兼顾整幅图的空间和语义的特征。
2.3 分割分支中的损失函数
分类分支中的损失比较好理解,就是一个分类任务中常用的交叉熵损失,而分割分支中的损失函数有好几个,总的如下:

这里面包括CEloss,Energyloss和BCDloss三个损失。
2.3.1 CE loss
CEloss还是比较常规的交叉熵损失,他是基于伪标签和预测结果计算的。
2.3.2 Energy loss
Energy损失是为了利用到未标记的像素。
Energy loss的计算推导如下:
- 首先,定义计算能量的公式如下:

里面i和j就代表一个图像中的某两个像素,G(i,j)是一个高斯带通滤波器,后面两项分别是网络预测i是a类的概率和网络预测j是b类的概率。
G(i,j)的具体定义式如下:
这里, I s I_s Is表示像素的空间位置, I r g b I_{rgb} Irgb也就表示像素的值,两个分母就是两个高斯里的超参数, - 因为就前景类和后景类,就可以简化能量计算式:
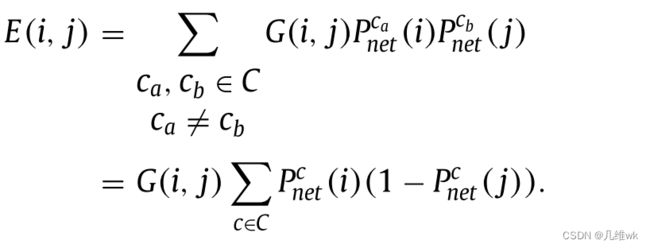
- 最终定义Energy loss为:

S(i)是个软过滤器:

这个损失的计算过程能够理解,但是优化这个损失的具体意义还是理解的不是很好。原文只是说利用这个损失就可以利用到没有标记的像素,确实是这样,因为熵的计算是计算所有的像素的。
总的来看这个熵的计算是和像素的位置以及其预测的概率有关,熵越小,位置和预测的概率组成的系统的混乱程度也就会越小,那么他们的相关性也就越大,可能就是因为这个原因才引入了这个loss。
2.3.3 BCE loss
增加BCEloss是根据下面三方面进行考虑的:
- 增加不同类特征之间的距离会让类别更好区分;
- 低级特征更多是空间颜色特征,高级特征更多是语义特征,而BCE Loss利用高级特征来让不同类的特征更好区分;
- 直接对特征进行计算loss的计算复杂度非常高,所以这里采用BCE Loss;
从整体pipeline的图中来看,用来计算BCEloss的有来自两子分支cat的结果: F m F_m Fm和和两自两子分支结果经过一定计算获得的 P n e t P_{net} Pnet:

首先计算预测的mask:

然后计算前景类和背景类的特征中心:

整体损失如下:

一共四项,第一项是前景类的特征中心更加靠近,第二项是让背景类和前景类的中心离得更远,第三项和第四项是让所有的特征都靠近他们相关的特征中心。
2.3.4 损失总结
本文在分割分支中一共用了三种损失函数,其中CE Loss是为了利用伪标签的监督信息来训练模型,Energy Loss是为了利用无标签数据来对模型进行特征增强的学习,而BCE Loss则是在特征空间上让前景类和背景类的特征距离更大,更容易区分。
3.总结
本文提出了一个RPM Network,利用One-step的方法利用image-level的标签进行学习。文中比较有亮点的地方有两个:
- 伪标签生成
利用Multi-scale CAM的方法来获得class attention map,引入CRF,最终获得Reliable的标签; - 新损失函数的提出
提出Energy loss来更充分利用无标签的像素来参与训练过程,提出的BCE Loss更能够简化特征损失的计算复杂度,并且能够更好地让模型区分前景和背景。