Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
最近在关注 C V P R 2022 CVPR{\,} 2022 CVPR2022一些比较好的文章,也在做一些关于 o b j e c t c o n t e x t object{\,} context objectcontext的工作。好久没有好好更新博客了,今天想和大家分享下最近看的一篇我认为做的比较好的文章,问题的切入角度很好,文章也写得不错。
标题为Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels。
最后总结了最近对于读的一些关于 o b j e c t c o n t e x t object {\,}context objectcontext处理的论文。这应该是分享的最后一篇论文了,博主之后会进行《百面机器学习》或者算法相关内容的整理,要去实习了qaq~~,大家多多支持!!
文章目录
- 1. Introduction
- 2. Related Works
- 3. Methods
-
- 3.1 Overview
- 3.2 Pseudo-Labeling
- 3.3 Using Unreliable Pseudo-Labels
- 3.4 Pseudo Code
- 4. Experiments
-
-
- Ablation Study
-
- 5. Conclusion
- 6. Object Context Related Works
`
1. Introduction
在半监督工作中,最常见的做法是把 u n l a b e l e d d a t a unlabeled{\,} data unlabeleddata 经过用 l a b e l e d d a t a labeled{\,}data labeleddata训练好的模型得到的预测结果作为伪标签计算 u n s u p e r v i s e d l o s s unsupervised{\,}loss unsupervisedloss。但是为了尽可能保证伪标签的质量,常常选择那些 h i g h l y c o n f i d e n t highly{\,} confident highlyconfident的预测结果,而舍弃那些置信度低的。
- 作者认为在这个过程中有相当一部分 p i x e l pixel pixel是不会出现在训练过程中的,这样对于某些本来数据量就小的类别来说,会使得其训练更加不平衡(相当于 u n l a b e l e d d a t a unlabeled{\,} data unlabeleddata为本来就数量多的类别提供了更多的训练集)。
- 作者认为如何更好地利用这些 u n r e l i a b l e unreliable unreliable的伪标签是一个非常重要的待解决的问题。本文抓住了这些 u n r e l i a b l e unreliable unreliable标签的一个特点:即虽然有些伪标签是 m i s c l a s s i f i e d misclassified misclassified(可能在 G r o u n d T r u t h GroundTruth GroundTruth和某几个类别之间容易混淆),但是它可以非常确定地不属于其他类别。作者给了一个例子,如下图:

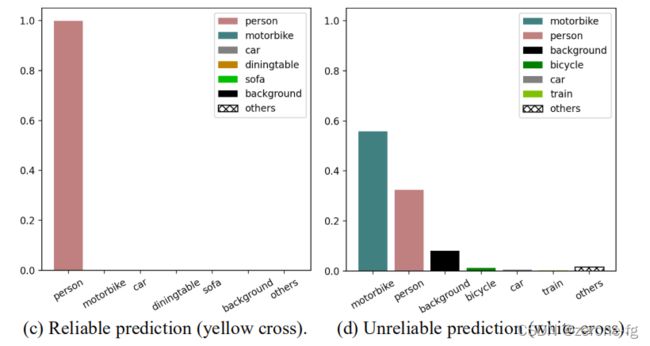
对于白色十字位置的特征分类可能会出现 F i g u r e d Figure{\,}d Figured的预测情况,虽然误分类成了 p e r s o n person person,但是在 c a r car car, t r a i n train train等类的置信度确极低,也就是说可以比较肯定地确定不属于 c a r car car, t r a i n train train类别。作者认为像这样的 u n r e l i a b l e unreliable unreliable的样本也是有意义的,可以利用它提供的信息提高分割精度。 - 作者提出了 U 2 P L U^{2}PL U2PL ( U s i n g U n r e l i a b l e P s e u d o − L a b e l s ) (Using Unreliable Pseudo-Labels) (UsingUnreliablePseudo−Labels),并在 P A S C A L V O C 2012 PASCAL VOC {\,}2012 PASCALVOC2012和 C i t y s c a p e s Cityscapes Cityscapes上进行了实验验证。
2. Related Works
- Semi-Supervised Learning
相比较于 C u t O u t CutOut CutOut, C u t M i x CutMix CutMix, C l a s s M i x ClassMix ClassMix这些用了较强的数据增强外,我们的方法则 f o c u s focus focus到那些 u n r e l i a b l e p i x e l unreliable{\,} pixel unreliablepixel的利用上。 - Pseudo-Labeling
F i x M a t c h FixMatch FixMatch设置 c o n f i d e n c e t h r e s h o l d confidence {\,}threshold confidencethreshold来选择伪标签; U P S UPS UPS则是在 F i x M a t c h FixMatch FixMatch的基础上考虑到了模型不确定性和数据不确定性。 - Model Uncertainty
贝叶斯深度学习网络常常用来估计模型不确定性,这里我们仅用 p i x e l − w i s e pixel-wise pixel−wise的 e n t r o p y entropy entropy作为评估准则。 - Contrastive Learning
同样作者认为现有的网络在计算 c o n t r a s t i v e l o s s contrastive{\,} loss contrastiveloss的计算没有利用 u n r e l i a b l e p i x e l unreliable{\,} pixel unreliablepixel的信息。 - Negative Learning
通过降低负样本的概率来降低信息错误的风险,但是这些负样本仍然具有很高的置信度。
3. Methods
3.1 Overview
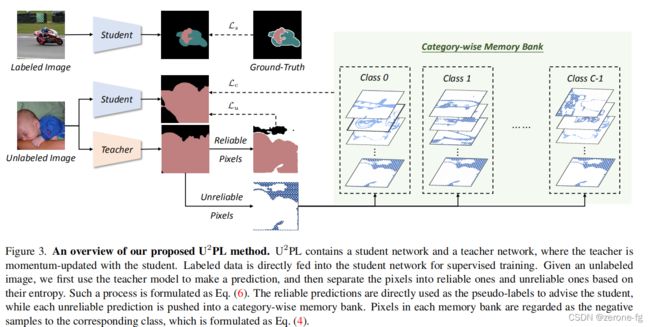
-
上图是作者提出的一个主要的网络结构,分为教师网络和学生网络:我们学生网络权重更新和一般网络更新过程相同,教师网络用 E M A EMA EMA更新网络权重。
在训练过程中,我们等量地选取 B l B_l Bl张 l a b e l e d i m a g e s labeled{\,}images labeledimages和 B u B_u Bu张 u n l a b e l e d i m a g e s unlabeled{\,}images unlabeledimages,对于每张带标签的图像我们的目的是减小 c r o s s e n t r o p y l o s s cross{\,} entropy{\,} loss crossentropyloss;对于每张 u n l a b e l e d i m a g e unlabeled{\,} image unlabeledimage,我们首先让其经过 t e a c h e r m o d e l teacher{\,}model teachermodel进行预测,然后选择那些 r e l i a b l e reliable reliable的伪标签计算 u n s u p e r v i s e d l o s s unsupervised{\,}loss unsupervisedloss;对于剩余的 u n r e l i a b l e unreliable unreliable的标签我们将通过 c o n t r a s t i v e l o s s contrastive {\,}loss contrastiveloss将其利用起来。因此整个 l o s s loss loss分为三大部分:
L = L s + λ L u + λ c L c L=L_s+\lambda L_u +\lambda_c L_c L=Ls+λLu+λcLc
其中 L s L_s Ls和 L u L_u Lu都是 C E l o s s CE{\,}loss CEloss:
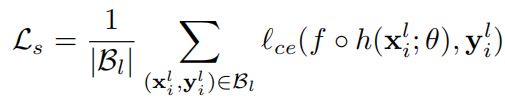
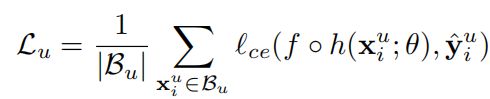
其中y为 u n l a b e l e d d a t a unlabeled{\,} data unlabeleddata和 l a b e l e d d a t a labeled{\,} data labeleddata的标签, f ∗ h f*h f∗h为网络预测组合,其中 h h h为 e n c o d e r encoder encoder部分, f f f为 s e g m e n t a t i o n h e a d segmentation{\,} head segmentationhead.剩余的 c o n t r a s t i v e l o s s contrastive{\,} loss contrastiveloss我们将在3.2部分结合具体过程进行介绍,方便大家理解。
先给出contrastive loss的公式:
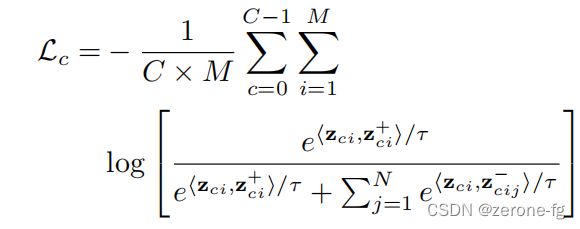
3.2 Pseudo-Labeling
首先我们要确定什么样的伪标签是 r e l i a b l e reliable reliable的,什么样的是 u n r e l i a b l e unreliable unreliable的,根据前面作者提出的问题,我们可以得到像素预测类别分布越均匀越不利于我们判断,这样的点是 u n r e l i a b l e unreliable unreliable的,说明该点同样是难分割的;相反,如果该点的预测分布是有明显倾向的,则认为这样的点是 r e l i a b l e reliable reliable的。我们希望用一个指标来表示这种标准,显然应该用信息熵来说明:
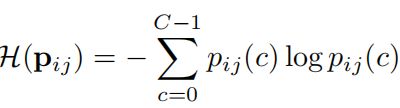
因此,我们定义第 i i i张 u n l a b e l e d i m a g e unlabeled{\,}image unlabeledimage的第 j j j个像素的伪标签为:
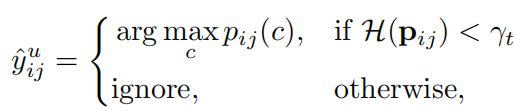
其中, γ t \gamma_t γt表示选取 α t \alpha_t αt比例的 u n r e l i a b l e unreliable unreliable像素点所对应的 t h r e s h o l d threshold threshold,有:
γ t = n p . p e r c e n t i l e ( H . f l a t t e n ( ) , 100 ∗ ( 1 − α t ) ) \gamma_t=np.percentile(H.flatten(),100*(1-\alpha_t)) γt=np.percentile(H.flatten(),100∗(1−αt))
其中,随着训练迭代数的增加, α t \alpha_t αt的大小是逐渐增加的,文中作者定义为线性增加:
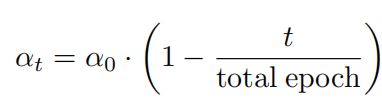
而其中 u n s u p e r v i s e d l o s s unsupervised{\,}loss unsupervisedloss的权重 λ u \lambda_u λu也是变化的,
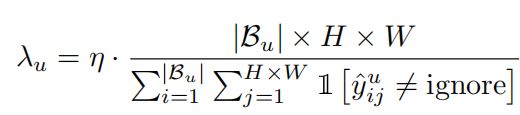
3.3 Using Unreliable Pseudo-Labels
那么问题关键也是文章最大的创新点是我们如何利用这些 u n r e l i a b l e p s e u d o l a b e l s unreliable{\,} pseudo{\,} labels unreliablepseudolabels,如我们前面图所示,虽然白色箭头位置不能区分是 p e r s o n person person和 m o t o r b i k e motor{\,} bike motorbike,但是我们可以模型可以比较确定其不为 c a r car car, t r a i n train train, b i c y c l e bicycle bicycle。因此作者提出不如把这些点作为这些类别 ( c a r . e t a l ) (car.etal) (car.etal)的负样本,进而引入 c o n t r a s t i v e l o s s contrastive{\,} loss contrastiveloss。具体来说,作者提出的 U 2 P L U^2PL U2PL包括三部分:
- anchor pixels(queries)
- positive samples for each anchor
- negative samples for each anchor
下面我们将对这三部分进行逐一详细介绍:
首先是anchor pixel,顾名思义,锚点,我们先介绍这部分点的特征:锚点分别从 u n l a b e l e d d a t a unlabeled{\,} data unlabeleddata和 l a b e l e d d a t a labeled{\,} data labeleddata中进行选择,以 u n l a b e l e d d a t a unlabeled {\,} data unlabeleddata为例,即选择那些 t h r e s h o l d > 0.3 threshold>0.3 threshold>0.3并且预测为该类别的点,对于 u n l a b e l unlabel unlabel的数据来说,锚点一定从 r e l i a b l e reliable reliable的伪标签中选择:
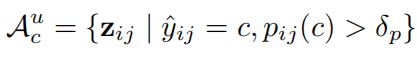
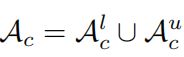
对于 l a b e l e d labeled labeled数据同样,最终两者集合组成锚点集。
Positive samples定义比较简单:
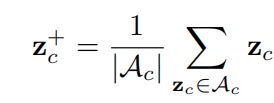
p o s i t i v e s a m p l e s positive{\,} samples positivesamples对于所有 a n c h o r anchor anchor来说是相同的,定义为所有 a n c h o r anchor anchor的中心。
Negative samples
对于 n e g a t i v e s a m p l e s negative{\,} samples negativesamples我们定义 0 − 1 0-1 0−1指示变量 n i j ( c ) n_{ij}(c) nij(c)为第 c c c个类别的第 i i i张图像的第 j j j个像素是否为负样本。判断是否为负样本需要满足以下条件:
- 对于 l a b e l e d i m a g e labeled{\,} image labeledimage来说,一个类别的负样本定义为:
(1)不属于类别 c c c;(2)难以区分是 c c c类别还是其 G r o u n d T r u t h GroundTruth GroundTruth
说白了对于 l a b e l e d i m a g e labeled{\,} image labeledimage来说,每个类别对应的负样本是该类别的易混样本,比如上图中的 p e r s o n person person和 m o t o r b i k e motorbike motorbike. - 对于 u n l a b e l e d i m a g e unlabeled{\,} image unlabeledimage来说,一个类别的负样本定义为:
(1)伪标签是 u n r e l i a b l e unreliable unreliable的;(2)可能不属于 c c c类别;(3)不属于大部分不可能的类别
n e g a t i v e s a m p l e s negative{\,} samples negativesamples对于所有 a n c h o r anchor anchor来说也是相同的,对于每个 a n c h o r anchor anchor来说有 N N N个 n e g a t i v e s a m p l e s negative {\,} samples negativesamples。
作者给出了以上标准的数学定义:定义 O i j = a r g s o r t ( p i j ) O_{ij}=argsort(p_{ij}) Oij=argsort(pij),表示像素点 p i j p_{ij} pij预测类别的排序,很显然有 O i j ( a r g m a x p i j ) = 0 O_{ij}(argmax{\,}p_{ij})=0 Oij(argmaxpij)=0和 O i j ( a r g m i n p i j ) = C − 1 O_{ij}(argmin{\,}p_{ij})=C-1 Oij(argminpij)=C−1,这点比较显然,我们举个例子来说明,假设第 ( i , j ) (i,j) (i,j)个位置的预测值为: [ 0.3 , 0.28 , 0.15 , 0.025 , 0.025 , 0.02 , 0.02 , 0.02 , 0.02 , 0.02 , 0.015 , 0.015 , 0.015 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.01 , 0.005 ] [0.3,0.28,0.15,0.025,0.025,0.02,0.02,0.02,0.02,0.02,0.015,0.015,0.015,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.005] [0.3,0.28,0.15,0.025,0.025,0.02,0.02,0.02,0.02,0.02,0.015,0.015,0.015,0.01,0.01,0.01,0.01,0.01,0.01,0.01,0.005]
一共有 20 20 20个类别,进行排序后,概率最大 0.3 0.3 0.3出现的位置为第 0 0 0个位置;概率最小 0.005 0.005 0.005出现的位置为第 19 19 19个位置,即 C − 1 C-1 C−1.
定义 n i j l ( c ) n_{ij}^l(c) nijl(c)为:
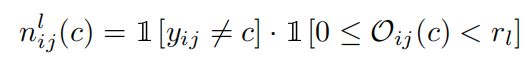
其中 r l r_l rl是 l o w r a n k t h r e s h o l d low{\,}rank{\,}threshold lowrankthreshold,在实验过程中设置为 3 3 3,我们仍然以前面的预测值为例,假设该点是第 c c c个类别的概率为 0.28 0.28 0.28,也即 O i j ( c ) = 2 O_{ij}(c)=2 Oij(c)=2,而事实上该点的 G r o u n d T r u t h GroundTruth GroundTruth为 0.15 0.15 0.15对应的类别,这样的点就满足上式,可以被认为是第 c c c个类别的负样本,也是属于和第 c c c个类别不易区分的点。
同理,
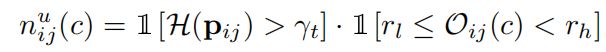
其中 r l r_{l} rl和 r h r_h rh分别为 3 3 3和 20 20 20,即该点的伪标签首先是不可靠的,其次位置处于 3 − 20 3-20 3−20之间,同样以上述的预测值为例,假设第 c c c个类别的预测概率为 0.01 0.01 0.01,处在排名靠后的位置,而且整个预测分布是比较均匀的,信息熵比较大,属于不可靠的伪标签。
Category-wise Memory Bank
因为在有的 m i n i − b a t c h mini-batch mini−batch中,某个类别的负样本很有限,因此作者定义了一个 c a t e g o r y − w i s e m e m o r y b a n k ( F I F O q u e u e ) category-wise {\,}memory{\,} bank(FIFO{\,} queue) category−wisememorybank(FIFOqueue)来存储。
在上面的过程中我们了解了每个类别的 p o s i t i v e s a m p l e positive{\,} sample positivesample、 n e g a t i v e s a m p l e negative{\,} sample negativesample以及 a n c h o r p i x e l anchor{\,} pixel anchorpixel之后,再看 c o n t r a s t i v e l o s s contrastive{\,} loss contrastiveloss就比较好理解。
该 l o s s loss loss可以理解为是为了尽量减少 a n c h o r p i x e l anchor{\,} pixel anchorpixel和 p o s i t i v e s a m p l e positive{\,} sample positivesample的距离,增大和 n e g a t i v e s a m p l e negative{\,} sample negativesample的距离从而提高模型的分割效果。
3.4 Pseudo Code

4. Experiments
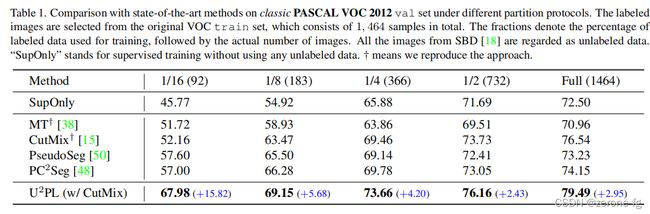
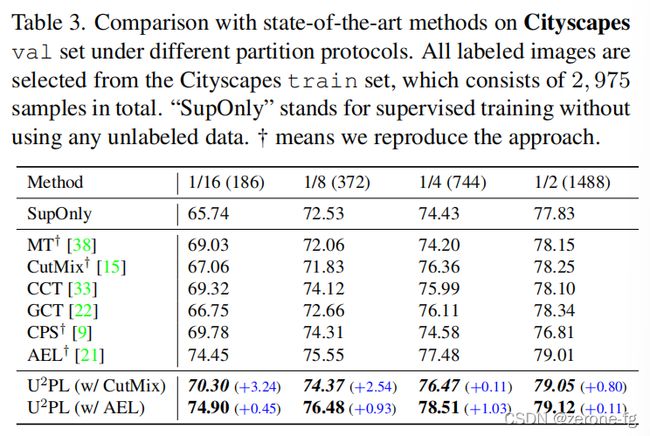
实验中和一些比较常见的半监督方法进行了比较,并且在不同比例的 l a b e l e d d a t a labeled{\,} data labeleddata和 u n l a b e l e d d a t a unlabeled{\,} data unlabeleddata情况下给出了对比结果,可以看到 U 2 P L U^2PL U2PL+ C u t M i x CutMix CutMix方法相比于其他方法是有提升的,特别是在 l a b e l e d d a t a labeled{\,} data labeleddata所占比例特别小的情况下。
- 在 P A S C A L V O C PASCAL{\,} VOC PASCALVOC上的不同划分比例下的表现效果
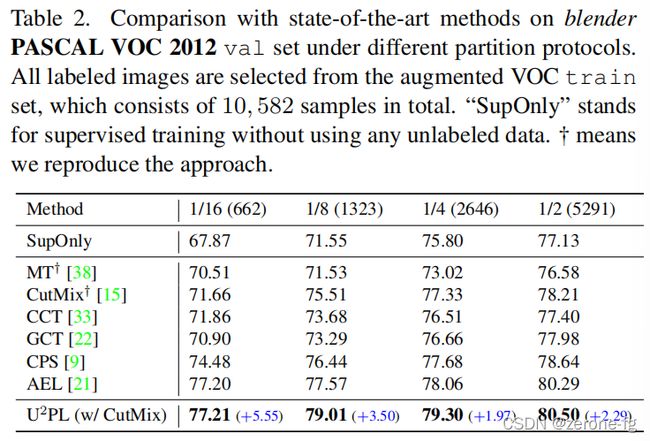
- 在 b l e n d e r P A S C A L V O C blender{\,} PASCAL{\,} VOC blenderPASCALVOC上不同划分下的表现效果
- 在 c i t y s c a p e s cityscapes cityscapes上不同划分比例下的表现效果
Ablation Study
Effectiveness of Using Unreliable Pseudo-Labels
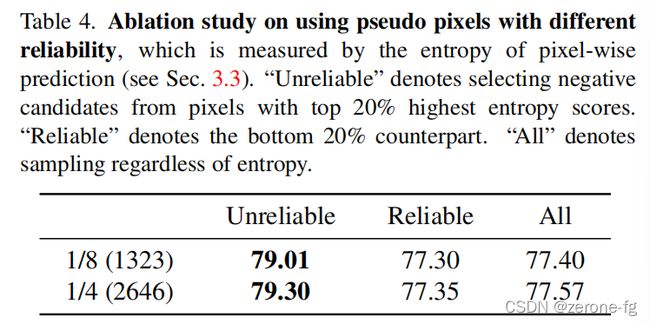
证明了利用 u n r e l i a b l e p s e u d o p i x e l s unreliable{\,} pseudo{\,} pixels unreliablepseudopixels确实可以给模型带来提升。
Effectiveness of Probability Rank Threshold
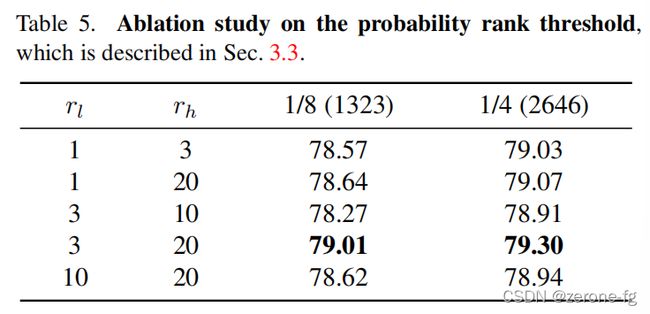
Section 3.3中 r l r_l rl和 r h r_h rh的选择对模型精度的影响,反映的是在整个数据集上的一个平均表现。
Effectiveness of Components
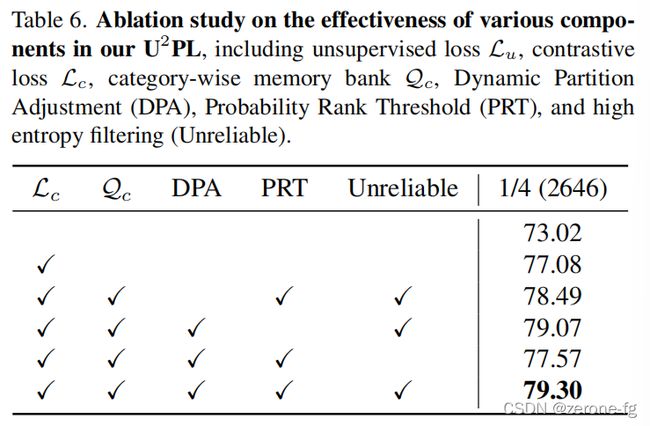
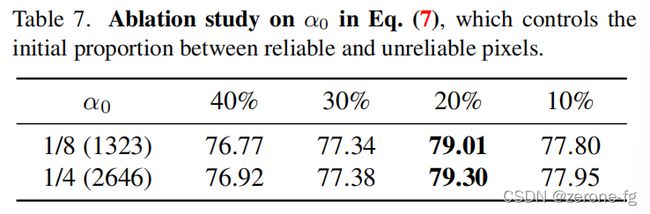
Ablation Study on Hyper-parameters
5. Conclusion
总的来说,这篇文章确实从一个很好的角度尝试解决了一些在半监督方法中没能被利用的 u n r e l i a b l e p i x e l s unreliable{\,} pixels unreliablepixels的问题,思路是非常值得我们借鉴和思考的!!
6. Object Context Related Works
- OCR: https://arxiv.org/pdf/1909.11065.pdf
- Context Prior for Scene Segmentation: https://arxiv.org/pdf/2004.01547.pdf
- ACFNet: https://arxiv.org/abs/1909.09408
- Class-wise GCN: https://link.springer.com/chapter/10.1007/978-3-030-58520-4_1