大数据编程实验二:RDD编程
大数据编程实验二:RDD编程
文章目录
- 大数据编程实验二:RDD编程
-
- 一、前言
- 二、实验目的与要求
- 三、实验内容
- 四、实验步骤
-
- 1、pyspark交互式编程
- 2、编写独立应用程序实现数据去重
- 3、编写独立应用程序实现求平均值问题
- 五、最后我想说
一、前言
刚更完大数据编程实验一,紧接着我就继续写实验二,因为明天就要上这门课了,我也一直没做,我比较懒,今天才开始做,果然赶鸭子上架,效率还是高。
好啦,废话不多说,我们直接开始做实验。
二、实验目的与要求
- 熟悉Spark的RDD基本操作及键值对操作
- 熟悉使用RDD编程解决实际具体问题的方法
三、实验内容
- 给定数据集data1.txt,包含了某大学计算机系的成绩,数据格式如下所示:
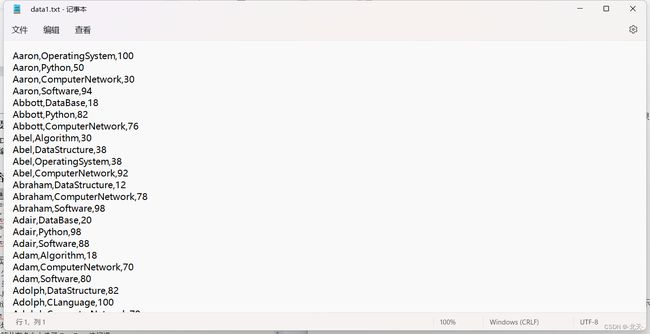
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
- 该系总共有多少学生
- 该系共开设了多少门课程
- Tom同学的总成绩平均分是多少
- 求每名同学的选修的课程门数
- 该系DataBase课程共有多少人选修
- 各门课程的平均分是多少
- 使用累加器计算共有多少人选了DataBase这门课
-
编写独立应用程序实现数据去重
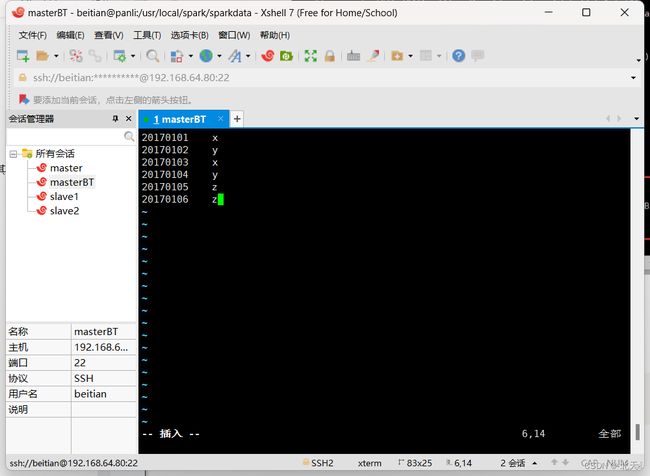
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
-
编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
四、实验步骤
1、pyspark交互式编程
我们首先在spark目录下面创建一个sparkdata目录用于存放我们的数据集data1.txt:
cd /usr/local/spark/
mkdir sparkdata

然后我们可以通过xftp软件将我们的数据集上传到该文件中或者进入到该目录下面直接拖入文件也可以上传文件:
然后我们启动pyspark:
cd /usr/local/spark/bin
pyspark

现在我们开始做题:
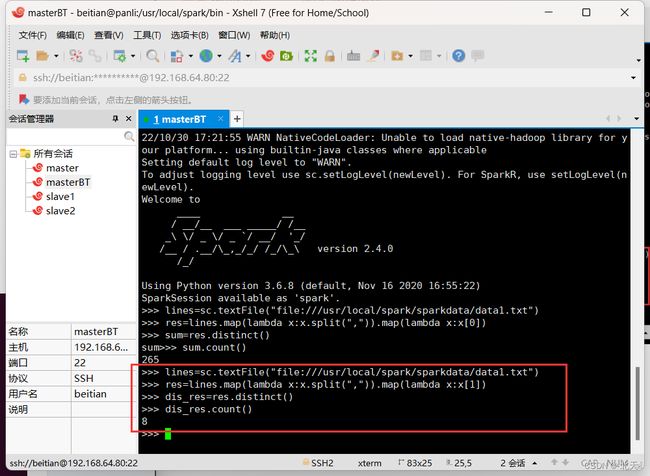
(1)该系总共有多少学生
>>> lines=sc.textFile("file:///usr/local/spark/sparkdata/data1.txt")
>>> res=lines.map(lambda x:x.split(",")).map(lambda x:x[0])
>>> sum=res.distinct()
>>> sum.count()

(2)该系共开设了多少门课程
>>> lines=sc.textFile("file:///usr/local/spark/sparkdata/data1.txt")
>>> res=lines.map(lambda x:x.split(",")).map(lambda x:x[1])
>>> dis_res=res.distinct()
>>> dis_res.count()
(3)Tom同学的总成绩平均分是多少
>>> lines=sc.textFile("file:///usr/local/spark/sparkdata/data1.txt")
>>> res=lines.map(lambda x:x.split(",")).filter(lambda x:x[0]=="Tom")
>>> score=res.map(lambda x:int(x[2]))
>>> num=res.count()
>>> sum_score=score.reduce(lambda x,y:x+y)
>>> avg=sum_score/num
>>> print(avg)

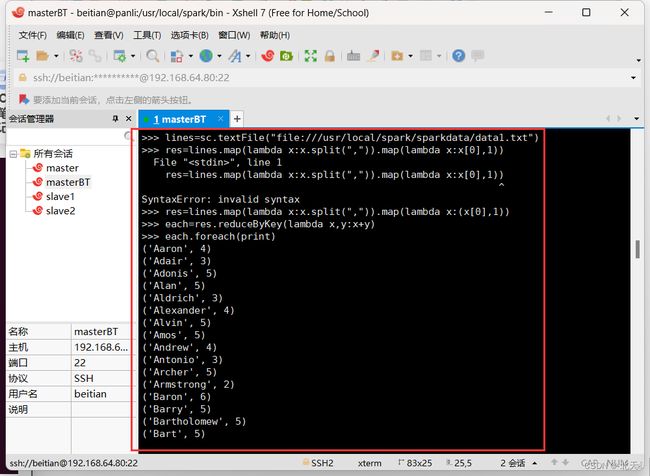
(4)求每名同学的选修的课程门数
>>> lines=sc.textFile("file:///usr/local/spark/sparkdata/data1.txt")
>>> res=lines.map(lambda x:x.split(",")).map(lambda x:(x[0],1))
>>> each=res.reduceByKey(lambda x,y:x+y)
>>> each.foreach(print)
(5)该系DataBase课程共有多少人选修
>>> lines=sc.textFile("file:///usr/local/spark/sparkdata/data1.txt")
>>> res=lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
>>> res.count()
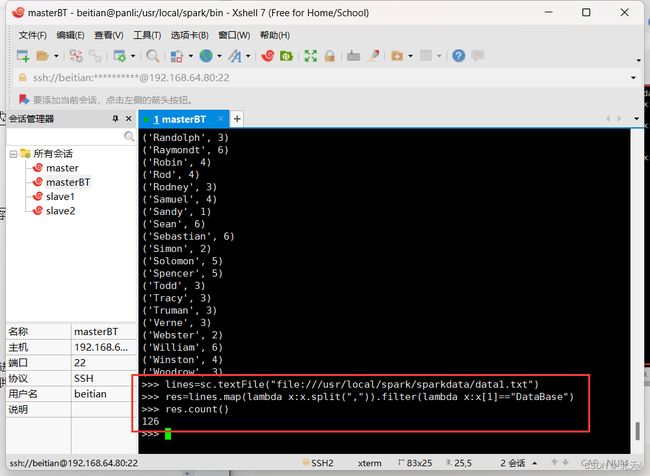
(6)各门课程的平均分是多少
>>> lines=sc.textFile("file:///usr/local/spark/sparkdata/data1.txt")
>>> res=lines.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1)))
>>> temp=res.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
>>> avg=temp.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
>>> avg.foreach(print)

(7)使用累加器计算共有多少人选了DataBase这门课
>>> lines=sc.textFile("file:///usr/local/spark/sparkdata/data1.txt")
>>> res=lines.map(lambda x:x.split(",")).map(lambda x:(x[1],1))
>>> count=res.reduceByKey(lambda x,y:x+y).filter(lambda x:x[0]=="DataBase")
>>> count.foreach(print)

2、编写独立应用程序实现数据去重
我们进入之前创建的sparkdata目录下面创建A,B以及python文件D。
cd /usr/local/spark/sparkdata/
vim A
vim B

vim D.py
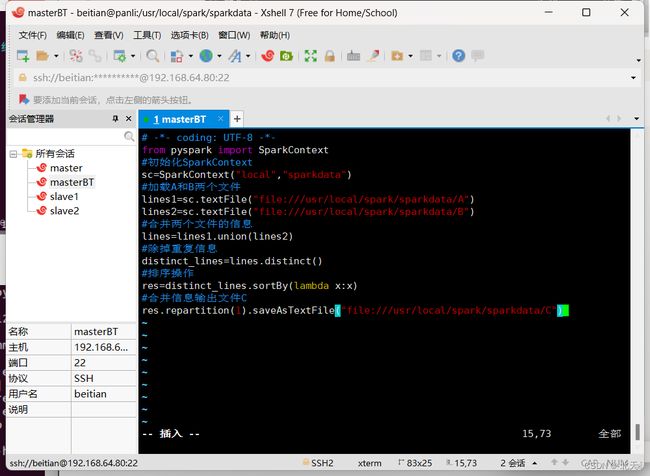
并填入如下代码:
# -*- coding: UTF-8 -*-
from pyspark import SparkContext
#初始化SparkContext
sc=SparkContext("local","sparkdata")
#加载A和B两个文件
lines1=sc.textFile("file:///usr/local/spark/sparkdata/A")
lines2=sc.textFile("file:///usr/local/spark/sparkdata/B")
#合并两个文件的信息
lines=lines1.union(lines2)
#除掉重复信息
distinct_lines=lines.distinct()
#排序操作
res=distinct_lines.sortBy(lambda x:x)
#合并信息输出文件C
res.repartition(1).saveAsTextFile("file:///usr/local/spark/sparkdata/C")
然后我们在该目录下面执行如下命令进行程序运行:
python3 D.py
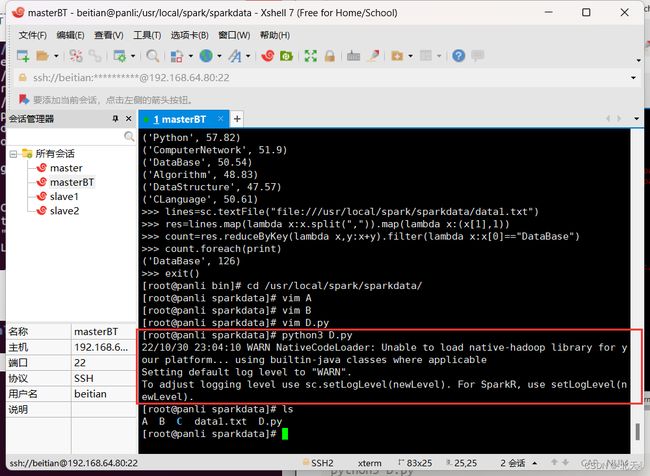
输入命令即可查看我们的运行结果:
cd /C
vim part-00000

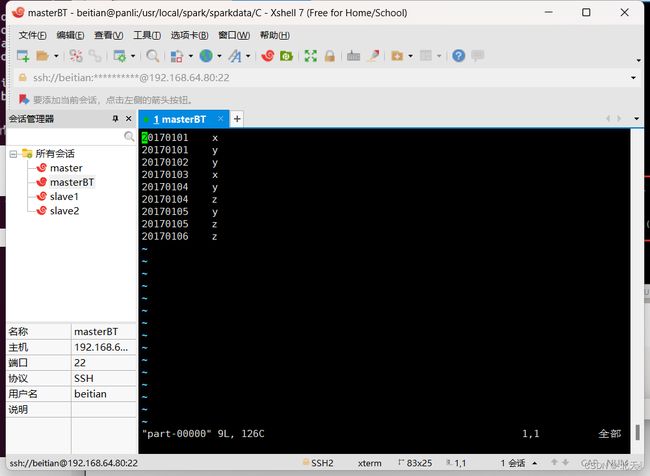
可以看出我们成功完成实验要求。
3、编写独立应用程序实现求平均值问题
我们首先回到sparkdata目录下,然后再该目录下面创建一个avgscore目录:
cd /usr/local/spark/sparkdata/
mkdir avgscore
然后我们进入avgscore目录中并在该目录下创建Algorithm.txt,Database.txt以及Python.txt文件并分别在三个文件中写入信息:
vim Algorithm
vim Database
vim Python
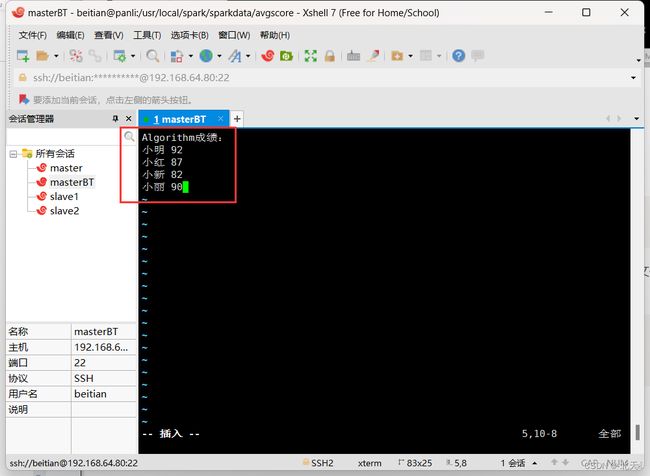

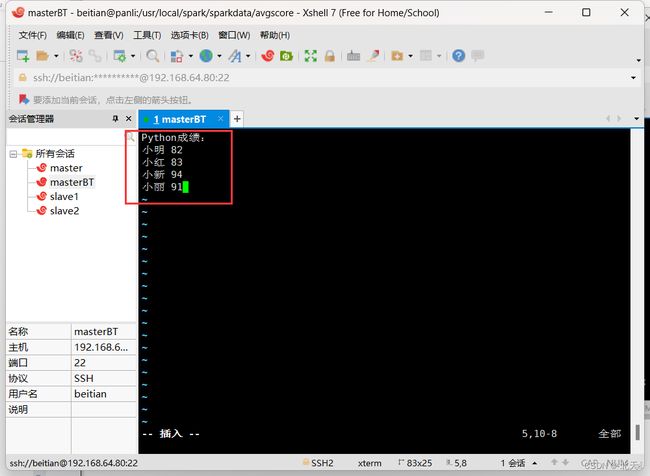
创建完三个信息文件之后我们再新建一个avgscore.py文件:
vim avgscore.py
并填入如下代码:
# -*- coding: UTF-8 -*-
from pyspark import SparkContext
sc= SparkContext('local','avgscore')
#加载三个文件并生成RDD
lines1 = sc.textFile("file:///usr/local/spark/mycode/avgscore/Algorithm.txt")
lines2 = sc.textFile("file:///usr/local/spark/mycode/avgscore/Database.txt")
lines3 = sc.textFile("file:///usr/local/spark/mycode/avgscore/Python.txt")
#合并三个文件
lines = lines1.union(lines2).union(lines3)
distinct_lines = lines.distinct()
lines4 = distinct_lines.sortBy(lambda x:x).filter(bool)
#给每一列额外添加一列“1”标签,便于统计学生的选秀的课程数目
data = lines4.map(lambda x:x.split(" ")).map(lambda x:(x[0],(int(x[1]),1)))
res = data.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
#用总成绩除以选秀的课程数,计算每门课程的平均分,并用round函数让结果保留两位小数
result = res.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
#将结果写入result文件中
result.repartition(1).saveAsTextFile("file:///usr/local/spark/mycode/avgscore/result")

然后我们在avgscore目录中直接输入如下命令执行程序:
python3 avgscore.py
然后我们进入生成的result文件中打开结果文件:
vim part-00000

可以看见我们的结果正确。
五、最后我想说
RDD编程很重要,是spark学习中很重要的技术,也是期末考试中必考的内容,所以必须要掌握牢固,我准备后面更新一遍专门学习RDD编程的博客,方便学习复习巩固。