宵夜杂谈:BEVFormer治好了我的精神内耗!
作者 | 战斗系牧师 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/539925138
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
论文:https://arxiv.org/abs/2203.17270
代码:https://github.com/zhiqi-li/BEVFormer
BEVFormer开放麦:https://www.zhihu.com/zvideo/1526597302591975424
开局第一张图
来句题外话:其实我个人来说,我特喜欢把网络模型结构放在文章开头的写法,这种写法很符合我阅读论文的习惯 ,我习惯带着思考和自己的初步理解逐渐探索的过程,这会极大的激发我的阅读兴趣!
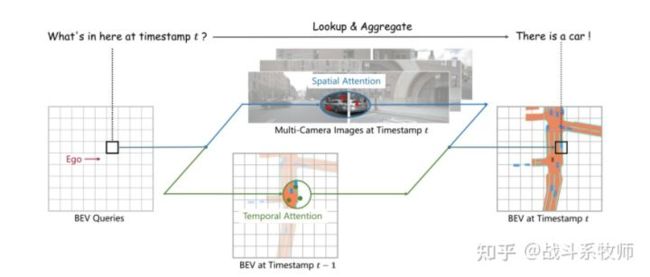
上面这张图展示了BEVFormer的两大核心任务:mutil-camera(多视角相机)和 bird- eye-view(鸟瞰图)。BEVFormer利用了Transformer强大的特征提取能力以及Timestamp结构的时序特征的查询映射能力,在时间维度和空间维度对两个模态的特征信息进行聚合,增强整体感知系统的检测效果。
那我们在开始读文章的时候先仔细的分析一下这张图
BEV Queries部分:根据字面意思推断应该是用于查询得到BEV图上的特征信息,那用什么怎么查询呢?是Transformer中的QKV吗?
Temporal Attention部分:根据字面意思推断是一个时序注意力机制,是提取出不同的时序下鸟瞰图的特征变化信息吗?
Spatial Attention部分:这个部分其实明显了,将多个视角的空间特征信息融合,因为多视角本来就是一个空间问题,所以使用空间注意力很正常,但是怎么使用这个空间注意力呢?然后这个空间注意力长啥样子呢?我们也还不知道。
所以让我们带着问题继续往下读这篇文章!
工作的Motivation
众所周知一个摄像头也就是几百或者几千,我八个摄像头也不过是万元内的价格,但是我部署一个激光雷达,最低也要3-5万美金。由于LiDAR设备的价格是真的高,业界一直都有想法希望通过低成本的相机方案去完成自动驾驶汽车的感知任务,降低整体感知方案的成本,但是很显然一直没有一套很好的方案可以打败LiDAR呢?
那相机除了够便宜之外,与基于激光雷达的方案相比,RGB视觉也能发挥很大的优势,比如在(红绿灯、停车线等)的场景中就有很大优势。
所以为啥之前的相机方案不行?其实之前方法的核心问题是没有能做到:让相机更精准的描述3D空间信息,合理的完成空间三维重建、完成认知决策和协同感知。
其实大家应该都不多不少有听说过,或者学习过赛车手都驾驭不了的Tesla(特斯拉)的纯视觉自动驾驶感知方案吧。那么我们为什么不尝试一下加入和优化这套纯视觉的BEV方案呢?
介绍
最简单的方式就是单一的处理每一个视角的信息,最后再进行后处理融合,但是这样就会使得这几个相机彼此没有参与其中,信息没有办法有效的交互,而且整体显得很笨拙也不美观。
受特斯拉的启发,我们发现了可以使用TransFormer来建模多视角摄像头的输入到BEV的输出这么一种映射关系。又因为我们的多视角摄像头是没有办法采集到深度信息的,所以BEV方法和LiDAR方法的GAP就在这里了,所以我们应该怎么去解决这个问题?
1、利用深度估计将信息处理成伪点云
2、根据预测的heatmap回归位置信息
3、利用深度信息训练一个backbone使得这个backbone更加适应3D任务
4、回避depth,将任务放在BEV视角下进行
本文章就是这样第四种思路进行设计的,此前的一些三维物体检测的工作很大程度会依赖于深度分布和深度值信息对检测任务的支持。但是从2D图像中生成的BEV是不稳定的,如果按照依赖深度信息和深度分布的LiDAR方法进行显然是不适合的。所以我们可以尝试回避Depth的信息,通过自适应的方式,利用Self-attention动态聚合有价值的特征完成我们的需求。
对于人类视觉感知系统,时序信息在推断物体的运动状态和识别遮挡物体方面起着至关重要的作用,视频领域的工作也很好的证明了这一点。但是加入时序信息的话也要考虑在自动驾驶场景运用,如果只是简单的交叉叠加时序信息的话,会引入许多额外的干扰信息(两个不同时序下的其他环境的变化引入的干扰信息)的同时,更增加了额外的计算成本。所以文章也采用了RNN的方式对不同的时间进行一个循环的迭代过程。
文章的主要贡献就是:
实现了一个利用率时序、空间信息建模出端到端的BEV生成器。通过这个BEV特征信息的统一可以更好的支持三维检测和地图分割任务。其实后续也可以有更多的任务加入其中!
BEVFormer设计了Spatial Cross Attention模块提取出多视角图中感兴趣的区域空间信息进行重建。然后通过Temporal self-Attention模块对历史的时序信息进行融合,通过这两个模块得到的空间和时序信息进行有效的聚合。
BEVFormer在nuScenes测试集上实现了56.9%的NDS,比以前的最佳检测方法DETR3D高9个点(56.9%vs.47.9%)。对于地图分割任务,我们还实现了最先进的性能,在最具挑战性的车道分割上比Lift Splat高出5个多点
结构讲解

其实上图这个是最开始结构图的详解版本,那么我们下面主要分析以下三个核心结构Spatial Cross-Attention、Temporal Self-Attention、BEV Queries
BEV Queries

如图所示文章中建立了H×W×C的空间作为BEVFormer的查询网格,在将BEV queries 输入到BEVFormer之前,先将可学习的位置编码添加到BEV queries Q集合空间中,然后开始学习并更新BEV queries的值。
BEV queries为空间网格的可学习参数,用来捕获自动驾驶汽车的BEV特征。
每个位于(x,y)位置的query都负责表征对应的最小位置
通过对Spatial和temporal信息的轮番查询,生成BEV特征图。
Spatial Cross-Attention

步骤1:在(x,y)的位置上不同的高度采集pillar的点。
步骤2:可以根据pillar点的3D参数投影到各个2D平面上。
对于一个BEV query,投影的2D点只能落在某些视图上,而其他视图不会被击中,在这里我们把被击中的视图称为hit视图
步骤3:在hit视图的区域位置中采样特征信息
步骤4:我们通过带权重的方式将这些特征信息进行一个融合
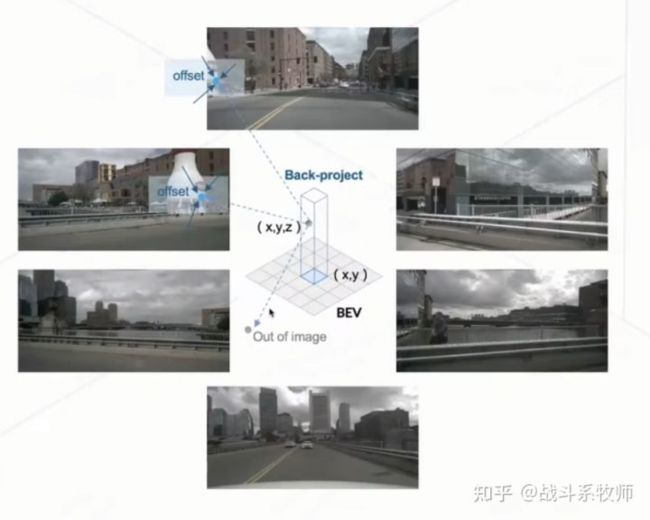
上图会更加直观的体会到Spatial Cross-Attention整个完整步骤流程,其中Out of image就是投影到整个视野以外,那么这个点就不会参与到查询的工作中来。
Temporal Self-Attention
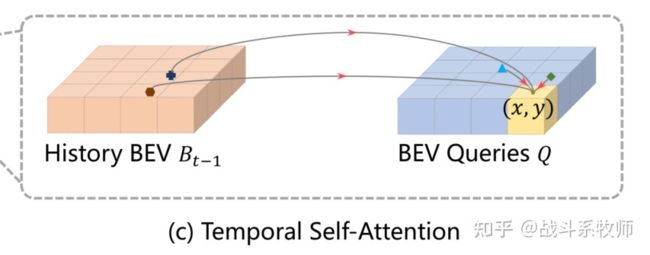
步骤1:通过ego-motion(帧间运动)将历史帧和当前帧映射到网格图对应于真实世界的位置,将两个历史的BEV特征信息进行对齐。
步骤2:通过Self-attention同时采样过去帧和当前帧的信息
步骤3:采样完成后通过一个加权的方式将特征加权当前的BEV视角,得到一个更加鲁棒的特征图
步骤4:通过一个RNN的方法做3-4次通过一种迭代的方式查询历史的当前特征,还能做做一个持续的融合。
优势和结果
多任务学习:3D目标检测和地图语义分割
可迁移性:常用的2D检测头也可以很好通过很小的修改迁移到3D检测头上面去。
BEVFormer在nuScenes测试集上实现了56.9%的NDS,比以前的最佳检测方法DETR3D高9个点(56.9%vs.47.9%)。对于地图分割任务,我们还实现了最先进的性能,在最具挑战性的车道分割上比Lift Splat高出5个多点
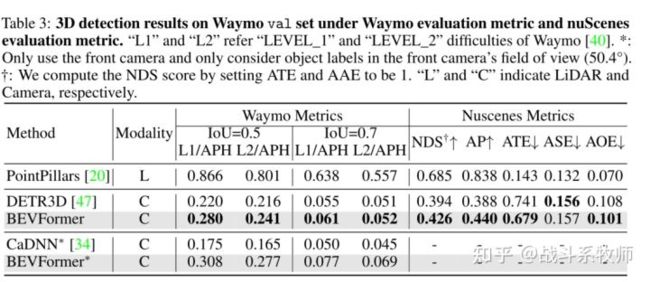

消融实验总结
1、强的backbone依然是涨点的关键
2、Local-attention要不global attention的效果要更好,global attention更加耗时,性能也不太好
3、时序信息的必要,能够有效的提高速度上的指标
4、不建议多任务头,多任务头在3D目标检测表现ok,但是在BEV map的语义分割中性能还是较差。
提问
Q1:其实纯视觉到底还能走多远?能不能真正的和LiDAR的效果做到一个大差不差的一个性能
Q2:打不过就加入,那么我们的多模态的方案到底怎么做才会让视觉与LiDAR的融合更加的优雅
Q3:对于BEV的部署要求,BEV能不能更友好的支持部署的要求!
我看完文章之后其实看完了这篇文章之后,会对第二个问题更加有共鸣,我们能不能让不同模态的融合方式更加优雅,在语义信息以及空间信息上对两个模态做更好的一个融合,更高效的信息补充。
对于融合的方式,我们常见的有下面几种
但是我们多用的融合方式通常是Early-fusion和Late-fusion

我们最直接,最方便的思路就是把不同模态的信息concatenate,然后一次性输入到模型当中,最后得到一个输出。
BEVFusion就采用的是这种方案,将多视角图与LiDAR投影到BEV视角下直接的通道叠加做一个效果出来

把整体的决策和融合交给黑箱,这显然是最简单,但是我认为也是最不负责任的做法。因为这压根没有办法针对不同模型的特征信息进行优化,我们只能把希望寄托在Encoder的特征学习能力足够强大,可以学习到自身的特征,和彼此之间的联系,但是如果两个模态信息并非强相关,也并非都是强模态,这样一定会带来的强模态抢占弱模态的事情发生。如果发生抢占,可能会在两个模态上识别效果很差。
我个人也其实不太喜欢后融合,如果后处理融合的话,两个模态的信息交互其实非常的不充分,也很难从里面学习到两个模态之间的联系信息,这样的做法其实是吃力不讨好的。
所以我个人来说会更偏向于做特征融合的方法,但是特征融合的方法会带来一个问题是,我们要怎么关联这两个模态,以及我们要怎么有效的处理两个模态特征之间的GAP,这是我们需要去直面解决的问题。但是特征融合会让我们更加直观的体会到模态融合的过程,相比前融合会更加的保护彼此的特征,相比后融合,会让两个模态的信息有更加丰富的参与感,更加细节化的特征交流和融合。
写在最后的话
其实我已经有了一些初步的融合方法和结论,并想把结论写出来,所以写这篇知乎的时候我人还在赶AAAI,但是负责任的说一句我应该也不太能赶上了,所以才写了这篇知乎!
你们都写完AAAI投稿出去了,我这还在写introduction呢!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
