Python(PyTorch和TensorFlow)图像分割卷积网络导图(生物医学)
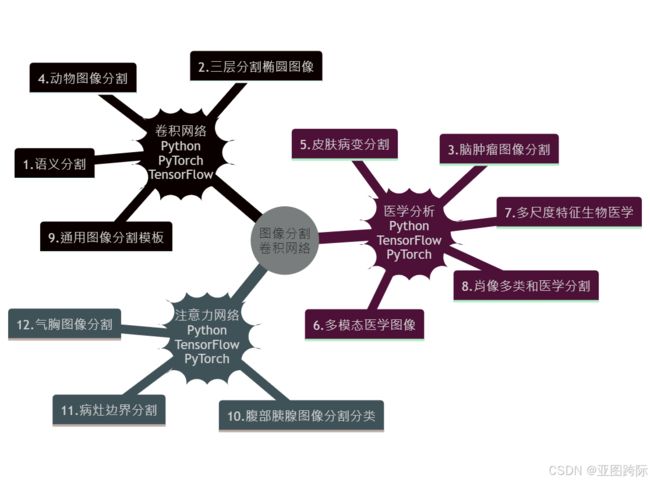
要点
- 语义分割图像
- 三层分割椭圆图像
- 脑肿瘤图像分割
- 动物图像分割
- 皮肤病变分割
- 多模态医学图像
- 多尺度特征生物医学
- 肖像多类和医学分割
- 通用图像分割模板
- 腹部胰腺图像分割分类注意力网络
- 病灶边界分割
- 气胸图像分割
Python生物医学图像卷积网络
该网络由收缩路径和扩展路径组成,收缩路径是一种典型的卷积网络,由重复应用卷积组成,每个卷积后跟一个整流线性单元 (ReLU) 和一个最大池化操作。在收缩过程中,空间信息减少,而特征信息增加。扩展路径通过一系列向上卷积和连接将特征和空间信息与收缩路径中的高分辨率特征相结合。
在生物医学图像分割中有很多应用,例如脑图像分割和肝脏图像分割以及蛋白质结合位点预测。也应用于物理科学,例如在材料显微照片的分析中。以下是此网络的一些变体和应用:
- 像素级回归及其在全色锐化中的应用
- 从稀疏注释学习密集体积分割
- 在 ImageNet 上进行预训练以进行图像分割
- 图像到图像的转换以估计荧光染色
- 蛋白质结构的结合位点预测
网络训练中数学计算
能量函数是通过最终特征图上的逐像素 soft-max 与交叉熵损失函数相结合来计算的。soft-max 定义为 p k ( x ) = exp ( a k ( x ) ) / ( ∑ k ′ = 1 K exp ( a k ′ ( x ) ) ) p_k( x )=\exp \left(a_k( x )\right) /\left(\sum_{k^{\prime}=1}^K \exp \left(a_{k^{\prime}}( x )\right)\right) pk(x)=exp(ak(x))/(∑k′=1Kexp(ak′(x))),其中 a k ( x ) a_k( x ) ak(x) 表示像素位置 x ∈ Ω x \in \Omega x∈Ω且 Ω ⊂ Z 2 \Omega \subset Z ^2 Ω⊂Z2 处特征通道 k k k 的激活。 K K K 是类别的数量, p k ( x ) p_k( x ) pk(x)是近似的最大函数。然后,交叉熵在每个位置上惩罚 p ℓ ( x ) ( x ) p_{\ell( x )}( x ) pℓ(x)(x) 与 1 的偏差,使用下式
E = ∑ x ∈ Ω w ( x ) log ( p ℓ ( x ) ( x ) ) E=\sum_{ x \in \Omega} w( x ) \log \left(p_{\ell( x )}( x )\right) E=x∈Ω∑w(x)log(pℓ(x)(x))
其中 ℓ : Ω → { 1 , … , K } \ell: \Omega \rightarrow\{1, \ldots, K\} ℓ:Ω→{1,…,K} 是每个像素的真实标签, w : Ω → R w: \Omega \rightarrow R w:Ω→R 是我们引入的权重图,以赋予某些像素更多的重要性在训练中。我们预先计算每个地面真实分割的权重图,以补偿训练数据集中某一类像素的不同频率,并迫使网络学习我们在接触细胞之间引入的小分离边界。分离边界使用形态学运算计算。然后计算权重图为
w ( x ) = w c ( x ) + w 0 ⋅ exp ( − ( d 1 ( x ) + d 2 ( x ) ) 2 2 σ 2 ) w( x )=w_c( x )+w_0 \cdot \exp \left(-\frac{\left(d_1( x )+d_2( x )\right)^2}{2 \sigma^2}\right) w(x)=wc(x)+w0⋅exp(−2σ2(d1(x)+d2(x))2)
其中 w c : Ω → R w_c:\Omega\rightarrow R wc:Ω→R是平衡类别频率的权重图, d 1 : Ω → R d_1:\Omega\rightarrow R d1:Ω→R表示到最近单元格边界的距离, d 2 : Ω → R d_2:\Omega\rightarrow R d2:Ω→R表示到第二个最近单元格边界的距离。在我们的实验中,我们设置 w 0 = 10 w_0=10 w0=10 和 σ ≈ 5 \sigma \approx 5 σ≈5 像素。
当只有少量训练样本可用时,数据增强对于教会网络所需的不变性和鲁棒性至关重要。对于显微图像,我们主要需要平移和旋转不变性以及对变形和灰度值变化的鲁棒性。尤其是训练样本的随机弹性变形似乎是用很少的带注释图像训练分割网络的关键概念。
代码构建模型
实现可分为三个部分。首先,我们将定义收缩路径中使用的编码器块。该块由两个 3×3 卷积层、后跟 ReLU 激活层和 2×2 最大池化层组成。第二部分是解码器块,它从下层获取特征图,对其进行上转换、裁剪并将其与同级编码器数据连接,然后执行两个 3×3 卷积层,然后执行 ReLU 激活。第三部分是使用这些块定义模型。
编码模块
def encoder_block(inputs, num_filters):
x = tf.keras.layers.Conv2D(num_filters,
3,
padding = 'valid')(inputs)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(num_filters,
3,
padding = 'valid')(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.MaxPool2D(pool_size = (2, 2),
strides = 2)(x)
return x
解码模块
def decoder_block(inputs, skip_features, num_filters):
x = tf.keras.layers.Conv2DTranspose(num_filters,
(2, 2),
strides = 2,
padding = 'valid')(inputs)
skip_features = tf.image.resize(skip_features,
size = (x.shape[1],
x.shape[2]))
x = tf.keras.layers.Concatenate()([x, skip_features])
x = tf.keras.layers.Conv2D(num_filters,
3,
padding = 'valid')(x)
x = tf.keras.layers.Activation('relu')(x)
x = tf.keras.layers.Conv2D(num_filters, 3, padding = 'valid')(x)
x = tf.keras.layers.Activation('relu')(x)
return x
打印模型简要
import tensorflow as tf
def model(input_shape = (256, 256, 3), num_classes = 1):
inputs = tf.keras.layers.Input(input_shape)
s1 = encoder_block(inputs, 64)
s2 = encoder_block(s1, 128)
s3 = encoder_block(s2, 256)
s4 = encoder_block(s3, 512)
b1 = tf.keras.layers.Conv2D(1024, 3, padding = 'valid')(s4)
b1 = tf.keras.layers.Activation('relu')(b1)
b1 = tf.keras.layers.Conv2D(1024, 3, padding = 'valid')(b1)
b1 = tf.keras.layers.Activation('relu')(b1)
s5 = decoder_block(b1, s4, 512)
s6 = decoder_block(s5, s3, 256)
s7 = decoder_block(s6, s2, 128)
s8 = decoder_block(s7, s1, 64)
outputs = tf.keras.layers.Conv2D(num_classes,
1,
padding = 'valid',
activation = 'sigmoid')(s8)
model = tf.keras.models.Model(inputs = inputs,
outputs = outputs,
name = 'NetModel')
return model
if __name__ == '__main__':
model = model(input_shape=(572, 572, 3), num_classes=2)
model.summary()
输出
Model: "NetModel"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_6 (InputLayer) [(None, 572, 572, 3 0 []
)]
conv2d_95 (Conv2D) (None, 570, 570, 64 1792 ['input_6[0][0]']
)
activation_90 (Activation) (None, 570, 570, 64 0 ['conv2d_95[0][0]']
)
conv2d_96 (Conv2D) (None, 568, 568, 64 36928 ['activation_90[0][0]']
)
activation_91 (Activation) (None, 568, 568, 64 0 ['conv2d_96[0][0]']
)
max_pooling2d_20 (MaxPooling2D (None, 284, 284, 64 0 ['activation_91[0][0]']
) )
conv2d_97 (Conv2D) (None, 282, 282, 12 73856 ['max_pooling2d_20[0][0]']
8)
activation_92 (Activation) (None, 282, 282, 12 0 ['conv2d_97[0][0]']
8)
conv2d_98 (Conv2D) (None, 280, 280, 12 147584 ['activation_92[0][0]']
8)
activation_93 (Activation) (None, 280, 280, 12 0 ['conv2d_98[0][0]']
8)
max_pooling2d_21 (MaxPooling2D (None, 140, 140, 12 0 ['activation_93[0][0]']
) 8)
conv2d_99 (Conv2D) (None, 138, 138, 25 295168 ['max_pooling2d_21[0][0]']
6)
activation_94 (Activation) (None, 138, 138, 25 0 ['conv2d_99[0][0]']
6)
conv2d_100 (Conv2D) (None, 136, 136, 25 590080 ['activation_94[0][0]']
6)
activation_95 (Activation) (None, 136, 136, 25 0 ['conv2d_100[0][0]']
6)
max_pooling2d_22 (MaxPooling2D (None, 68, 68, 256) 0 ['activation_95[0][0]']
)
conv2d_101 (Conv2D) (None, 66, 66, 512) 1180160 ['max_pooling2d_22[0][0]']
activation_96 (Activation) (None, 66, 66, 512) 0 ['conv2d_101[0][0]']
conv2d_102 (Conv2D) (None, 64, 64, 512) 2359808 ['activation_96[0][0]']
activation_97 (Activation) (None, 64, 64, 512) 0 ['conv2d_102[0][0]']
max_pooling2d_23 (MaxPooling2D (None, 32, 32, 512) 0 ['activation_97[0][0]']
)
conv2d_103 (Conv2D) (None, 30, 30, 1024 4719616 ['max_pooling2d_23[0][0]']
)
activation_98 (Activation) (None, 30, 30, 1024 0 ['conv2d_103[0][0]']
)
conv2d_104 (Conv2D) (None, 28, 28, 1024 9438208 ['activation_98[0][0]']
)
activation_99 (Activation) (None, 28, 28, 1024 0 ['conv2d_104[0][0]']
)
conv2d_transpose_20 (Conv2DTra (None, 56, 56, 512) 2097664 ['activation_99[0][0]']
nspose)
tf.image.resize_20 (TFOpLambda (None, 56, 56, 512) 0 ['max_pooling2d_23[0][0]']
)
concatenate_20 (Concatenate) (None, 56, 56, 1024 0 ['conv2d_transpose_20[0][0]',
) 'tf.image.resize_20[0][0]']
conv2d_105 (Conv2D) (None, 54, 54, 512) 4719104 ['concatenate_20[0][0]']
activation_100 (Activation) (None, 54, 54, 512) 0 ['conv2d_105[0][0]']
conv2d_106 (Conv2D) (None, 52, 52, 512) 2359808 ['activation_100[0][0]']
activation_101 (Activation) (None, 52, 52, 512) 0 ['conv2d_106[0][0]']
conv2d_transpose_21 (Conv2DTra (None, 104, 104, 25 524544 ['activation_101[0][0]']
nspose) 6)
tf.image.resize_21 (TFOpLambda (None, 104, 104, 25 0 ['max_pooling2d_22[0][0]']
) 6)
concatenate_21 (Concatenate) (None, 104, 104, 51 0 ['conv2d_transpose_21[0][0]',
2) 'tf.image.resize_21[0][0]']
conv2d_107 (Conv2D) (None, 102, 102, 25 1179904 ['concatenate_21[0][0]']
6)
activation_102 (Activation) (None, 102, 102, 25 0 ['conv2d_107[0][0]']
6)
conv2d_108 (Conv2D) (None, 100, 100, 25 590080 ['activation_102[0][0]']
6)
activation_103 (Activation) (None, 100, 100, 25 0 ['conv2d_108[0][0]']
6)
conv2d_transpose_22 (Conv2DTra (None, 200, 200, 12 131200 ['activation_103[0][0]']
nspose) 8)
tf.image.resize_22 (TFOpLambda (None, 200, 200, 12 0 ['max_pooling2d_21[0][0]']
) 8)
concatenate_22 (Concatenate) (None, 200, 200, 25 0 ['conv2d_transpose_22[0][0]',
6) 'tf.image.resize_22[0][0]']
conv2d_109 (Conv2D) (None, 198, 198, 12 295040 ['concatenate_22[0][0]']
8)
activation_104 (Activation) (None, 198, 198, 12 0 ['conv2d_109[0][0]']
8)
conv2d_110 (Conv2D) (None, 196, 196, 12 147584 ['activation_104[0][0]']
8)
activation_105 (Activation) (None, 196, 196, 12 0 ['conv2d_110[0][0]']
8)
conv2d_transpose_23 (Conv2DTra (None, 392, 392, 64 32832 ['activation_105[0][0]']
nspose) )
tf.image.resize_23 (TFOpLambda (None, 392, 392, 64 0 ['max_pooling2d_20[0][0]']
) )
concatenate_23 (Concatenate) (None, 392, 392, 12 0 ['conv2d_transpose_23[0][0]',
8) 'tf.image.resize_23[0][0]']
conv2d_111 (Conv2D) (None, 390, 390, 64 73792 ['concatenate_23[0][0]']
)
activation_106 (Activation) (None, 390, 390, 64 0 ['conv2d_111[0][0]']
)
conv2d_112 (Conv2D) (None, 388, 388, 64 36928 ['activation_106[0][0]']
)
activation_107 (Activation) (None, 388, 388, 64 0 ['conv2d_112[0][0]']
)
conv2d_113 (Conv2D) (None, 388, 388, 2) 130 ['activation_107[0][0]']
==================================================================================================
Total params: 31,031,810
Trainable params: 31,031,810
Non-trainable params: 0
__________________________________________________________________________________________________
图像分割和预测
import numpy as np
from PIL import Image
from tensorflow.keras.preprocessing import image
img = Image.open('cat.png')
img = img.resize((572, 572))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array[:,:,:3], axis=0)
img_array = img_array / 255.
model = umodel(input_shape=(572, 572, 3), num_classes=2)
predictions = model.predict(img_array)
predictions = np.squeeze(predictions, axis=0)
predictions = np.argmax(predictions, axis=-1)
predictions = Image.fromarray(np.uint8(predictions*255))
predictions = predictions.resize((img.width, img.height))
predictions.save('predicted_image.jpg')
predictions