ATTS 论文解析
Bridging the Gap Between anchor-based and anchor-free Detection via AdaptiveTraining Selection (ATTS)
最详细的论文解析
论文地址:ATTS论文
源码地址:ATSS源码
1.摘要
anchor-based和anchor-free的目标检测算法最大的差异其实是如何在训练时去定义正负样本,如果在两类算法在训练中采用统一的正负样本的定义,那么最后的性能将没有什么大的差异,无论是基于bbox还是基于point的。因此,对目前的检测算法而言,如何去合理的选择正负样本是至关重要的。
本文提出一种自适应采样正负样本,针对样本的统计学特征自动的选取,可以在基于box的或者基于point的检测算法中适用。达到50.7%的mAP值,相当于EfficientDet-D6的水平。
2.引言
由仅仅是介绍了anchor-based中的one-stage和two-stage系列算法,以及anchor-free中的keypoint-baed和center-based系列算法。为了避免行文冗余,下面用一个表格来总结:
以FCOS和RetinaNet为例子,来说明anchor-based和anchor-free的区别:
1)在每个预测区域生成的anchor先验框的数目,前者在每个检测区域只设置一个anchor,后者在每个网格cell中设置多个anchor;
2)正负样本的划分不同,前者使用空间和尺度的约束来选择正负样本,后者使用IoU阈值;
3)对于anchor的初始回归不同,前者是基于point来回归,后者是基于先验框来回归box
值得研究的是,这三个差异中哪一个是造成性能差距的重要因素呢?
答案是正负样本的划分造成两类算法之间的性能差异,另外实验证明了在每个预测区域都设置多个anchor并不是必要的。
本论文中的贡献在于:
1)指出anchor-based和anchor-free在性能上最大差异的原因在于如何划分正负样本;
2)根据object的统计学特征设计一种自适应选取正负样本机制;
3)指出在每个cell上都设置多个anchor进行回归是不必要的;
4)在不引入额外计算量的前提下,在COCO2017达到了50.7的mAP.
3.anchor-based和anchor-free的性能差异分析
3.1.实验设置
Dataset : COCO 2017:train11K,val5K
Training Details:Backbone使用ResNet50 + FPN(5个尺度的预测特征图),网络层中的权重初始化使用与RetinaNet中的方法,对于RetinaNet,5个预测特征图的每个cell只预测一个正方形8S尺度的anchor,S是整体步长size(需要在源码中找到细节的解释)。
训练时,将图像的最短边长调整到800最大边长调整到≤1333,使用SGD优化器,总共迭代90K iterations,momentum=0.9,weight decay=0.0001以及batch_size=16。初始学习率为0.01,在60K个iteration时将学习率降低为原来的0.1,在80个iteration时再降低原来学习率的0.1。
Inference Details:在验证时,将输入图像做预处理,步骤与训练相同。通过网络的前向传播得到预测结果包括类别和bounding box,得到的预测框与GT的IoU先经过0.05的阈值筛选掉背景bbox,每个预测特征图再输出得分前1000的预测信息,那么5个预测特征图有5000个,最后对这5000个预测结果使用阈值为0.6的NMS处理得到每张图像上的前100个最终预测结果。
3.2.Inconsistency Removal
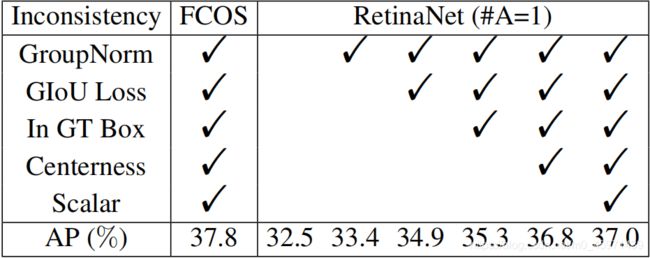
RetinaNet(A=1)表示RetinNet中的预测特征图上每一个cell只预测一个anchor,与FCOS中每个cell只预测一个point保持一致
在FCOS的这些improvements/tricks,一个一个的加入到RetinaNet中,对比两者的mAP。
Tricks:1)Giou :Generalized IoU = IoU - (Ac-U)/AC ,这里的U是预测框和GT的并集面积,Ac是预测框与GT的最小外接矩形的面积,当预测框与GT重合时,Ac=U,那么此时的GIoU = IoU。当预测框与GT没有交集时,IoU=0,Ac -> ∞,而U是一个常数,此时GioU -> -1。区间为[-1, 1] 。
Giou loss = 1- Giou,区间为:[0, 2]。
2)GroupBN与BN,layerNorm的区别
BatchNorm:batch方向做归一化,算NxHxW的均值
LayerNorm:channel方向做归一化,算CxHxW的均值
InstanceNorm:一个channel内做归一化,算HxW的均值
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)xHxW的均值。
3)Centerness branch:对于预测框的中心进行打分,表示当前pixel是否处于GT的中心区域
4)In GT Box:anchor point如果落在GT的内部就属于候选正样本。
5)Scalar:对每个预测特征图增加一个可学习的权重,相当于表示每个预测特征图对最后预测结果的影响程度。
到这里,两者还是有0.8的AP差距,那么此时两者的差异还有两个:
1)对于分类任务:FCOS和RetinaNet使用的是不同的划分正负样本的标准
Retinanet使用IoU来判别正负样本,对每个目标与所有anchor的IoU值矩阵来找出每个objec它对应最大IoU的anchor,每个目标有且仅有一个称为最佳anchor,如果其他的anchor与这些anchor的IoU值大于某一个阈值,那么就为positive;小于某一个阈值就为negative,其余的anchor丢弃,不参与训练。
FCOS是将GT内部的anchor point全部作为候选positive examples,在通过预测特征图的scale range来决定哪些是positive哪些是negative samples
如下图:
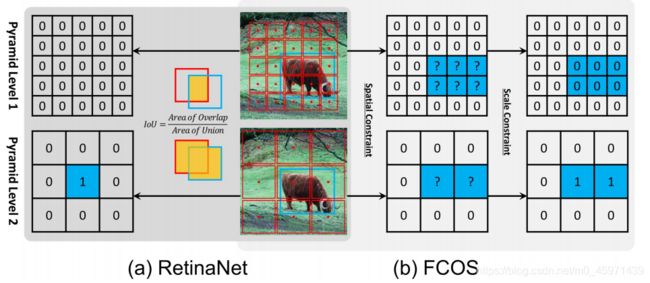
对于RetinaNet,使用IoU标准来划分正负样本的AP为37.0,改为Spatial and Scale Constraints得到的AP值为37.8;而对于FCOS,将之前的Spatial and Scale Constraints strategy改成IoU标准来划分正负样本的AP值从37.8下降到36.9,如下图:
关于IoU阈值来划分正负样本策略其实是同时从Spatial和Scale两个角度去判断的。
而对于使用FCOS中的判别标准,第一步是Spatial Constraint:对于所有在GT内部的center point都视作candidate positive samples;第二步是Scale Constraint:对candidate positive samples,关于这里的scale,论文中提到There are several preset hyperparameters in FCOS to defifine the scale range for fifive pyramid levels: [m2, m3] for P3, [m3, m4] for P4, [m4, m5] for P5, [m5, m6] for P6 and [m6, m7] for P7. 我的理解是这些scale类似于SSD中设置default box的scale范围,因为SSD中设置default box的思想是:小特征图预测大目标,大特征图预测小目标。因此对于feature map1而言,是大特征图,不会去预测图像中的这个大目标,因此所有candidate positive point全部设置为0也就是负样本;而对于feature map2而言,是小特征图,会负责预测图像中的大目标,因此小特征图上的所有candidate positive point全部设置为1也就是正样本。
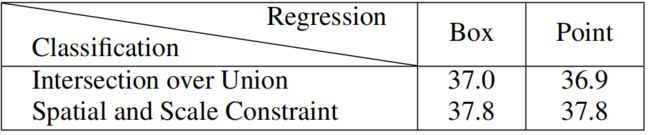
2)对于回归任务:前者是基于point来回归的,后者是基于box来回归的
回归是建立在正负样本划分基础上的,对于RetinaNet需要对GT和anchor的4个offset进行过回归,而FCOS需要对GT-point和anchor-point的4个distance进行回归,如下图:
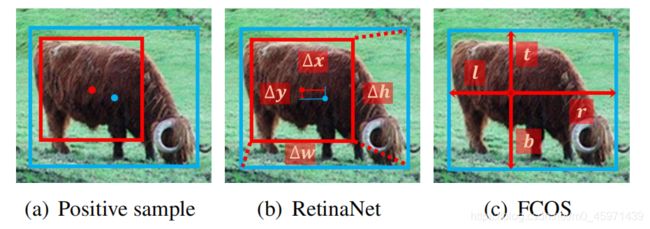
根据上面的表格可以看出:采用相同的采样采样策略时,FCOS和RetinaNet在性能差异上没有什么区别,第一行中的使用IoU阈值来划分正负样本,得到的mAP为36.9和37.0,;当使用 Spatial和Scale Constraints策略来划分正负样本得到的mAP都为37.8,表明回归的起始状态对于性能差异不是根本性的因素。因此,得出结论:anchor-based和anchor-free检测的性能差异是来源于如何定义正负样本?即划分正负样本的标准
PS: 说实话,仅仅基于两个算法的对比实验,用0.8%的AP差距来证明RetinaNet和FCOS两者的差距在正负样本选择上,我觉得很牵强,虽然后面的ATTS算法还是比较新颖的。很简单的例子,当数据分布不一样时,AP的微小波动都是正常的,就好比你拿RetinaNet的源码你自己再train一遍,你就很难达到原论文的精度。所以仅仅拿这0.8的AP差距来论证我觉得是不妥的。
仅代表个人观点。。。虽然这篇文章是2020CVPR的,但是我觉得他和DETR,EfficientDet等同年的目标检测算法比,还是差了一截的。
4.Adaptive Training Sample Selection
目标检测的训练阶段的主要任务:找到图像中的anchor bbox或者anchor point,可以是手工设置的也可以是基于算法得到的(YOLOv3中采用K-means聚类得到anchor),将所得的anchor box或者anchor point进行划分正负样本操作,正负样本用作分类loss的计算,正样本用过bbox的回归loss计算。论文中提出的AATS方法来选择正负样本,相比于传统的IoU策略,没有什么超参数并且鲁棒性较好可用于各种目标检测算法中。
4.1.Description
之前的采样策略要么是基于IoU阈值的,要么是基于scale ranges,具体操作在上面的Section 3中已经给出明确的说明,这里不再提及,两种策略都需要提前设置好对应的超参数,然后再基于设定好的超参数去给每个GT分配对应的正样本,而且这种规则有时候对于一些outer objects可能会忽略掉即漏检,举个例子:在图像的左上角靠近边缘的位置有一只猫,由于是使用阈值来划分可能会导致没有一个先验框和GT的阈值超过α,即使使用FasterRCNN中划分正样本的第二条准:和这个GT的IoU阈值最大的一个先验框即使IoU没有超过α依旧设定为positive examples,但是后续的回归时调整先验框的offset也有可能会导致框与GT并不是很准确。
下面介绍ATTS算法主要思路:
Input:一幅图像中的所有GT G;预测特征层L表示是在哪一个预测特征图上划分正负样本;
Ai表示第i个预测特征图上有多少个先验框;A表示所有预测特征图上的所有先验框数;
k表示对于一个GT,每一个预测特征图上只选择k个candidate positive samples,是一个超参数默认是9.
Output:positive samples P;negative samples N

Steps1-6:遍历一幅图像中所有的GT,对于每一个GT构建一个候选正样本集合Cg,再循环遍历每一个预测特征图,当anchor的中心点与GT的中心点的L2距离最小的前k个作为该GT的候选正样本,当前特征图上得到的候选正样本放到集合Si中。因此对于每一个GT,有k(一个特征图上选k个)xL(有多少个预测特征图)个候选正样本。
Step7-13:对于所有特征图上的Cg,计算Cg中的每个anchor与GT的IoU得到一个IoU集合Dg(len=Cg),计算Dg的平均值mg以及标准差vg,接着计算每个GT对应的IoU阈值为g:
tg = mg + vg。遍历Cg中的每一个anchor与对应GT的IoU值,如果IoU≥tg,并且anchor的中心点落在GT内部,那么该anchor设定为positive sample,并入到集合P中。
内层循环结束得到当前GT对应的所有正样本,外层循环结束,得到每个GT对应的正样本集合P,用全部anchor集合A - P =所有负样本集合N。
另外,对于RetinaNet,当anchor的中心点与GT的中心点越接近此时IoU阈值越大;对于FCOS,anchor point越接近于GT中心会得到更高质量的检测效果。因此,使用中心点距离的策略可以得到最好的候选正样本。
使用IoU的mean和std来划分正样本的原因:如果一个很高的mg表示有高质量的候选框并且该GT的IoU阈值tg也会很高,相反,一个很低的mg表示当前GT对应的候选框质量低并且对应的IoU阈值tg也会很低。而vg是用来表明GT由哪些特征图去负责预测最好。如果vg很高那么就选取那一个预测特征图去预测即可,反之选取多个预测特征图去预测。
如下图:
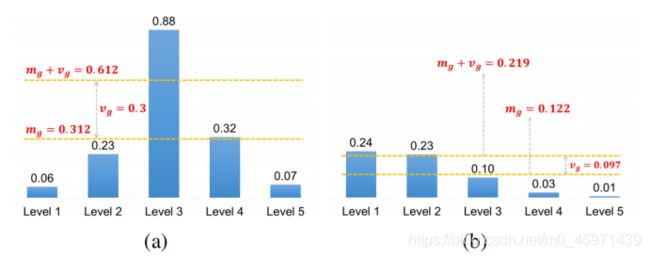
对于上图a,mg+vg = 0.612,仅有一个level3的IoU阈值大于0.612,那么只需要在level3特征图上去预测该GT。对于图b,mg+vg = 0.219,阈值很低,可以选取level1和level2来同时预测该GT。
Limiting the positive samples’s center to object:保证正样本的中心落在GT内部,不会导致使用GT外部的特征来进行分类预测和回归预测
Maintaining fairness between different objects:根据统计学理论,大约有16%的样本处于[mg+vg, 1]区间,尽管IoU阈值不是一个标准正态分布,但是每个GT都会有大约0.2*KL个正样本,不会像FCOS和RetinaNet一样,对于大目标所匹配到的正样本个数会多于负样本,可保证不同目标匹配正样本数的公平性。
Keeping almost hyperparameter-free:ATTS中有且仅有一个超参数k,实验表明k的不同对结果的影响并不明显,因此可以将ATTS看成是一个无超参数的算法。
4.2.Verification
在anchor-based RetinaNet上面使用ATTS机制,baseline为RetinaNet(#A=1),如下表格所示,AP增加2.3个百分点,AP50增加2.4%,AP75增加2.9%。由于ATTS只是改变了先前的正负样本的定义,所有在baseline上的性能增加是cost-free的。
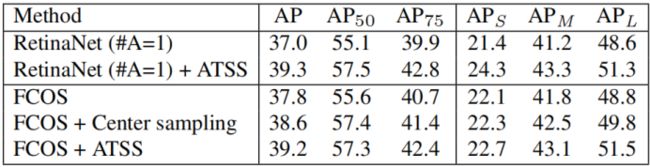
在anchor-free FCOS上使用ATTS机制有两种方式:
1)lite version:只替代FCOS中选取candidate positive samples的策略,原先是anchor的中心点在GT内部都属于candidate positive samples,导致有许多质量很低的候选正样本。现在改成对每个GT在每个预测特征图上只选取前k个candidate positive samples。而对于最后的决定正样本策略并没有改变,依旧是FCOS中的scale constraint。mAP提高了0.8个百分点
2)Full version:使用ATTS机制全部替换FCOS中的选择正样本策略,性能提升为:1.4% for AP, by 1.7% or AP50, by 1.7% for AP75, by 0.6% for APSmall,by 1.3% for APMedium and by 2.7% for APLarge。尤其对于APlarge的提升幅度最大。这也表明了FCOS中确实存在unfairness between different objects问题。
4.3.Analysis
对于超参数k,作者从[3, 5, 7, 9, 11, 13, 15, 17, 19]选取不同的k做了一系列的实验。如下:

可以看到,在k=5-17之间,AP值变化并不大,当k=3和k=19时,性能差距还是有的,可说明太少或者太多的anchor会导致正样本的质量比较低。总而言之,ATTS可视作无参数的。
对于anchor size的设置,ATTS也是使用的,如下两个表格:
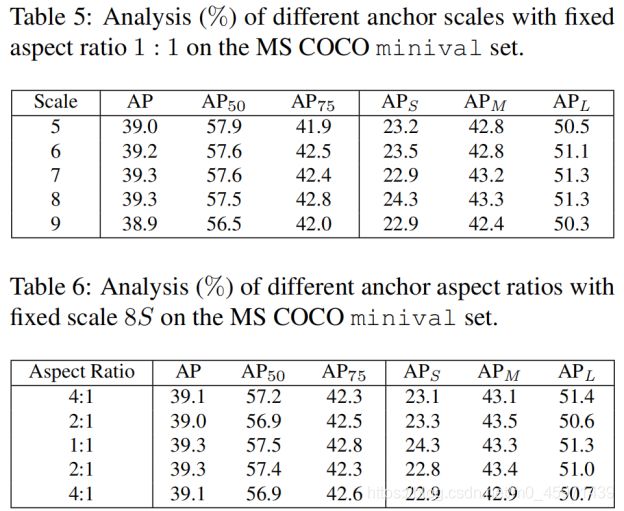
当固定anchor的aspect-ratio为1:1时,改变anchor的scale的数量,AP值并没有很大程度上的变化;当固定anchor的scale为8S(这里的S为当前预测特征图的尺寸)时,改变respect_ratio,同样AP值也无太大变化。说明ATTS对于不同anchor的设置是鲁棒的。
4.4.Comparison
对比one-stage和two-stage的各种检测算法,为了保证公平性,对于先前所有的检测器都使用了multi-scale Training strategy多尺度训练,如裁剪成640-800,resize最短变长为指定尺寸,长边等比例进行缩放。另外,将迭代次数翻一倍为180K,学习率素衰减变为在120K和160K。具体实验结果如下图:
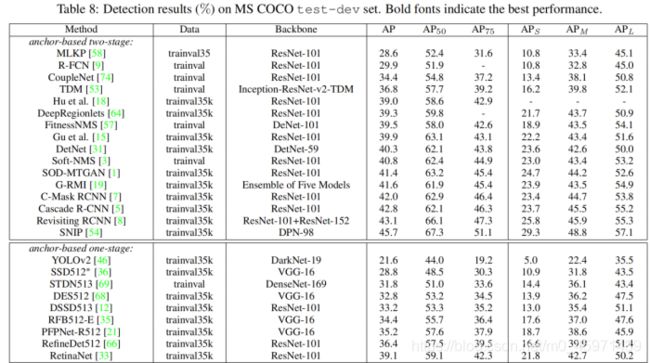
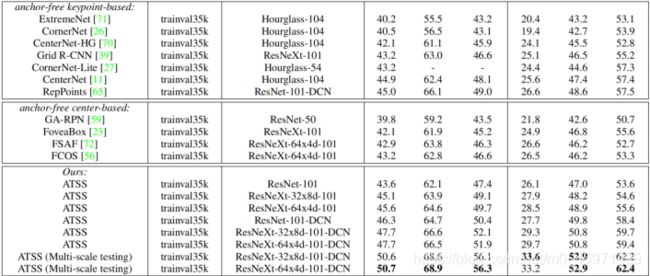
很奇怪的是作者没有提他是在哪一个baseline上进行改进的。只能从代码里找答案了。。。。
这里面的DCN是Deformable Convolutional Networks可变形卷积,ResNeXt中的64x4d和32x8d
是在残差模块中使用group conv操作,64x4d表示groups=64,每组4个channel;同理32x8d表示groups=32,每组8个channel。
4.5.Discussion
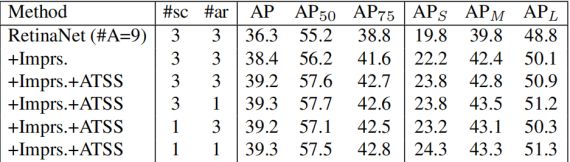
将RetinaNet(#A=9)作为baseline,先使用5种tricks:GroupNorm,GIoU Loss,In GT Box以及Centernes和Scalar。AP值可提高2.1个百分点,继而使用ATTS机制,AP提高至39.2.并且对比了在使用ATTS机制下,不用数量的anchor scale和anchor respect_ratio对AP的影响并不大。说明一旦正样本被合理的采样到,无论在每个预测区域(cell)使用多少个anchor结果都是相同的。进一步说明在预测区域使用多种anchor来进行预测不是必要的。
实验结果如下图:
- Conclusion
在本文中指出anchor-based和anchor-free的检测算法最本质的区别在于如何划分正负样本,以及在训练时如何划分正负样本是至关重要的。提出一种自适应采样方法去自动的划分正负样本,因此可以在anchor-based和anchor-free检测算法中建立联系。并且文中讨论了在每个预测区域设置多个anchor去预测是没有意义的。
PS: 如果需要使用本博客中的观点请标明出处,谢谢!
博客中有不正确的地方也欢迎xdm指正,评论或者私信都可以。
只能一星期一更了,最近在搞自己的工作,时间并不充裕,希望今年可以投出去把。。。