单阶段目标检测重要论文总结
文章目录
- 一、Yolov1
-
- 1、论文简介
- 2、检测原理
- 3、结构设计
- 4、疑难问题
- 5、论文总结
- 二、Yolov2
-
- 1、论文简介
- 2、更好、更快、更强
-
- 1)为什么更好?
- 2)为什么更快?
- 3)为什么更强? 此为YOLO9000内容
- 3、Darknet-19代码实现
- 4、论文总结
- 三、Yolov3
-
- 1、论文简介
- 2、结构设计
-
- Darknet-53
- 整体结构
- 3、Darknet-53代码实现
- 4、论文总结
- 四、Yolov4
-
- 1、论文简介
- 2、结构简介
-
- 2.1、输入端策略
-
- a、Mosaic数据增强
- 2.2、特征提取策略
-
- a、CSPDarknet53
- b、Dropblock正则化
- 2.3、Neck策略
-
- a、SPP模块
- b、FPN+PAN(路径聚合网络)
- 2.4、输出端策略
-
- a、CIOU loss
- b、DIOU-NMS
- 3、论文总结
- 五、Yolov5
-
- 1、结构设计
-
- 2.1、输入端策略
-
- a、自适应anchor计算
- b、自适应图片缩放
- 2.2、特征提取策略
-
- a、Focus结构
- b、CSP结构
- 2.3、 Neck策略
- 2.4、输出端策略
-
- a、CIOU loss
- b、官方NMS
- 2.5、模型缩放
- 五、SSD
-
- 1、论文简介
- 2、结构设计
-
- SSD检测框架
- SSD方法概述
- 3、论文总结
- 六、RetinaNet
-
- 1、论文简介
- 2、结构设计
-
- Focal Loss
- RetinaNet
- 3、Focal loss pytorch实现
- 4、论文总结
- 七、YOLOF
-
- 1、论文简介
- 2、结构设计
-
- 膨胀编码器
- 均衡匹配策略
- YOLOF
- 4、论文总结
- 八、CornerNet
-
- 1、论文简介
- 2、结构设计
-
- CornerNet总体框架
- 沙漏网络
- 预测模块
- 角池化
- loss函数
- 3、训练测试细节
- 4、论文总结
- 九、CenterNet
-
- 1、论文简介
- 2、结构设计
-
- CenterNet总体框架
- backbone
- 损失函数
- Heatmaps生成步骤
- 测试阶段细节
- 3、论文总结
- 十、CenterNet++
-
- 1、论文简介
- 2、结构设计
-
- 如何使用三元组关键点
- 中心池化
- 级联角池化
- LOSS函数
- 3、测试细节
- 4、论文总结
- 十一、FCOS
-
- 1、论文简介
- 2、结构设计
-
- 网络设计
- 正样本制作
- loss函数
- 基于FPN的多层预测
- Center-ness
- 3、实验结果
- 4、论文总结
- 十二、YOLOX
-
- 1、论文简介
- 2、结构设计
-
- 2.1、前期加强yolov3 Baseline策略
- 2.2、后期加强策略
- 2.4、端到端实现策略(最终的模型没有使用)
- 2.5、整体结构梳理
- 3、论文总结
- 十三、YOLOR
-
- 1、论文简介
- 2、论文结构
-
- 2.1、隐式知识的学习
-
- a、流型空间约简
- b、核空间对齐
- c、更多功能
- 、论文总结
- 十四、NanoDet&NanoDet plus
-
- 1、NanoDet简介
-
- 1.1、NanoDet结构
-
- a、backbone
- b、Neck:改进PAFPN
- c、head
- d、Gfocal loss
- e、标签匹配
- 2、NanoDet-Plus简介
-
- 2.1、NanoDet-Plus结构
-
- a、backbone
- b、Neck:Ghost-PAN
- c、head
- d、标签匹配策略
- e、训练策略调整
- f、部署优化调整
- 十五、Yolov7
-
- 1、论文简介
- 2、yolov5~yolov7中一些脱节的概念
-
- 2.1、模型重参数化
- 2.2、模型缩放
- 3、结构设计
-
- 3.1、聚合网络
- 3.2、模型缩放
- 4、可训练策略
- 5、 论文总结
- 引用
- 总结
单阶段目标检测重要论文总结
目标检测的常见结构:

Backbone:从图像中提取必要的特征,然后利用这些特征去实现分类和定位。常使用ImageNet Pretrained model,以减少训练时间。常见的有VGG-16,ResNet-50,ResNet-101,ResNeXT,ResNet+DCN,DarkNet,CSPResNet,Mobile-Net,ShuffleNet。
Neck:将backbone提取出的信息整合。常见的有FPN,SPP,RFB,ASPP,SAM,PAN。
Detection Head:输出分类与定位结果。这一模块通常就是普通的卷积。
一、Yolov1
1、论文简介
论文名称:You Only Look Once: Unified, Real-Time Object Detection
论文链接:yolov1
论文源码:yolov1的简单复现
自己注释了一部分并实现了demo
加强版yolov1
yolo的官方实现网站
摘要:我们提出了一种新的目标检测方法YOLO。以前目标检测的工作是重新利用分类器来执行检测,而我们将目标检测视为一个空间上分离的BBox和有联系的类概率的回归问题。YOLO 从输入图像仅仅经过一个 神经网络就能直接得到 bounding boxes 以及每个 bounding box 所属类别的概率。由于整个检测管道是一个单一的网络,因此可以直接对检测性能进行端到端优化。正因为整个的检测过程仅仅有一个网络,所以它可以直接在检测性能上进行端到端优化。
我们的统一架构非常快。基本YOLO模型能以每秒45帧的速度实时处理图像。该网络的一个较小版本Fast YOLO处理图像速度能达到每秒155帧,同时还较其他实施检测器的mAP提升了两倍。但是较之前目标检测的SOTA相比,YOLO在物体定位时更容易出错,但是在背景上预测出假阳性(不存在的物体)的情况会少一些。最后要说的是YOLO比DPM、R-CNN等物体检测系统能够学到更加抽象的物体的特征,这使得YOLO可以从真实图像领域迁移到其他领域,如艺术。
提出的问题:DPM,RCNN等目标检测器太慢又不好优化,RCNN太慢是因为要经过生成RP和分类RP这两个阶段,又要经过NMS后处理,难以优化是因为两阶段所用模型要分开训练。那么怎么解决这种太慢有不好优化的问题?
解决方案:将目标检测重建为一个单回归问题,直接从图像像素输出BBox坐标和分类概率。提出YOLO框架。

YOLO检测系统运作流程:
①将输入图resize到448×448;
②将resize后的图像喂到单个CNN中运作;
③根据模型的置信度对得到的检测结果进行阈值化。
YOLO优点:
①单个网络可以同时预测多个BBox和这些BBox的分类概率;
②在整张图片上训练且可以直接优化检测性能;
③速度快,可以做到实时检测。
④mAP较其他实时检测器提升了两倍之多。
⑤在做预测时YOLO 使用的是全局图像。YOLO在训练和测试时都是“看”的整张图,所以它可以将各类别的整体信息和外观信息进行编码。(Fast R-CNN较容易误将图像中的背景的一个小块看成是物体,因为它“看”的范围比较小,而YOLO犯的背景错误比 Fast R-CNN 少一半多)
⑥能够学到物体更泛化的特征表示。(当在自然场景图像上训练 YOLO,再在艺术图像上去测试 YOLO 时,YOLO 的表现要优于 DPM、R-CNN)
⑦仅使用一个卷积神经网络就可以端到端地实现检测物体的目的
YOLO缺点:较目标检测的SOTA系统定位精度欠缺,尤其对于小物体
2、检测原理
YOLO工作原理:将图片分成S×S的网格,如果物体中心落在一个网格上,那么这个网格就要被拿来检测这个物体(即只有GT处的网格才会被训练)。每个网格预测B个BBox和这些BBox的置信分数。每个BBox包含5个预测值,即置信分数和矩形框参数(x,y,w,h), ( x , y ) (x,y) (x,y)坐标代表BBox的中心与网格边界的相对值, ( w , h ) (w,h) (w,h)代表相对于整张图像来说BBox的宽高。注意:实际训练过程中, ( w , h ) (w,h) (w,h)的值使用图像的宽度和高度进行归一化到[0,1]区间内; ( x , y ) (x,y) (x,y)是BBox中心位置相对于当前网格位置的偏移值,并且被归一化到[0,1]。置信分数代表BBox和GT之间的IOU,这个IOU可看做是是正样本的标签。同时每个网格还要预测C个类别的概率,即在一个网格包含一个物体的前提下它属于某个类的概率,只为每个网格预测一组(C个)类的概率,不考虑BBox B的数量。因此特征图的通道数为: ( 5 B + C ) × S × S (5B+C)×S×S (5B+C)×S×S。其中 S = 输入图像尺寸 网络最大的 s t r i d e S=\frac{输入图像尺寸}{网络最大的stride} S=网络最大的stride输入图像尺寸。

本文使用S=7, B=2, VOC数据集的类别数C=20的配置,因此预测数有7 × 7 × 30。
本文的置信分数计算公式:
若BBox包含物体,则P(object) = 1;否则P(object) = 0。IOU(intersection over union)为预测BBox与GT之间的交集面积。object是一个二分类,即有物体还是无物体,也就是“边框的置信度”,没物体的标签显然就是0,而有物体的标签可以直接给1,也可以计算当前预测的bbox与GT之间的IoU作为有物体的标签,注意:这个IoU是object预测学习的标签。
测试时的置信分数计算公式:
这对每个BBox来说是一个特定类别的置信分数,这些分数对该类出现在框中的概率以及预测框与目标物体的匹配程度进行编码。
问题:对于这个公式最大的问题就在于IOU,因为测试阶段根本就没有真实框能够让我们去计算IoU。但是YOLO的objectness的学习标签就是预测框和GT之间的IoU,所以在测试阶段,这个IOU其实就是指YOLO预测的object-ness,它的物理意义就是:这个网格是否有物体。所以可以认为objectness隐含了IoU的概念,但本质就是有无物体的预测。基于这种问题,上面的置信分数公式可以写作:
这个IoU就是objectness预测,因为objectness在训练过程中的正样本标签就是IoU。
总的来说,yolov1一共有三部分输出,分别是object、class以及BBox:
- object就是框的置信度,用于表征该网格是否有物体;
- class就是类别预测;
- BBox就是Bounding Box
3、结构设计

YOLO的backbone:仿照GoogLeNet,但是没有Inception模块,而是替换成1×1和3×3卷积。24层卷积层+2个FC层,网络在最后的卷积层中将输出特征图做flatten操作,得到一个一维向量然后再接2个全连接层做预测。
以下就是YOLOv1的整体工作流程:

4、疑难问题
①训练阶段和测试阶段各做了些什么?
训练阶段:标签GT框中心点落在哪个网格,就由哪个网格预测这个物体,每个网格预测B个BBox,与GT的IOU最大的BBox负责预测这个物体,每个网格只能检测一个物体,包含/不包含GT的网格/BBox依损失函数分别处理。
测试阶段:直接获得 ( 5 B + C ) × S × S (5B+C)×S×S (5B+C)×S×S向量进行NMS后处理,得到目标检测结果。
②BBox怎么产生的?
答:是通过GT标签中的[xmin,xmax,ymin,ymax]计算得到GT的中心点坐标 ( b x , b y ) (b_x,b_y) (bx,by)和宽高,现通过这四个参数回归学习得到BBox的中心点坐标以及宽高。
③如何通过卷积操作将置信度+类别概率+位置偏移映射到卷积输出通道上?
答:因为CNN前向传播的同时要进行loss的反向传播,然后根据loss更新前向传播的这些预测值,因为这些预测值和反向传播的loss通道是一一对应的,所以是将预测值一一映射到卷积输出通道上了。至于为什么更新loss会对预测值产生影响:因为loss的计算离不开ground truth里的值和预测值,通用优化器如SGD根据loss对预测值进行更新,直到设置的epoch结束就可以输出预测值了。
5、论文总结
本文贡献:
①实现了使用单个卷积神经网络就可以端到端地实现检测物体的目的;
②提出的YOLO能够在整张图片上训练且可以直接优化检测性能;
③YOLO可以做到实时检测,mAP较其他实时检测器提升巨大;
④在做预测时YOLO 使用的是全局图像,使得检测器犯背景错误概率降低;
⑤能够学到物体更泛化的特征表示。
YOLOv1缺点:
①较目标检测的SOTA系统定位精度欠缺,召回率较低,尤其对于小物体;
②使用flatten操作破坏特征的空间结构信息;
③没有使用BN层(因为当时BN还不火)。
二、Yolov2
1、论文简介
论文名称:《YOLO9000: Better, Faster, Stronger》
论文链接:yolov2
论文源码:yolov2的简单复现
yolov2实现+自己理解
摘要:我们引进了YOLO9000,这是一个SOTA实时目标检测系统,可以检测9000多个目标类别。首先对YOLO检测方法提出了各种改进,在以前的工作上用了些创新点。yoov2模型在VOC和COCO数据集上已经达到SOTA。其次使用了一种新的多尺度训练方法,同样的一个YOLOv2模型可以在不同尺寸图片下运行,权衡了速度及精度。最后提出了一种联合训练目标检测和分类任务的方法,利用这种方法我们在COCO检测数据集和ImageNet分类数据集上同时对YOLO9000进行训练。联合训练允许YOLO9000预测那些没有检测数据标签的目标类别的检测。YOLO只能检测200多个类别,而YOLO9-000可以预测9000多个类别且可以实时运行。
本文提出的问题:检测数据集不会像分类数据集一样拥有很多类别,因此要怎么使得检测任务能够在有限类别的检测数据集上训练出能够检测更多类别的检测器呢?
解决方案:利用分类数据集且提出联合训练方案。(在YOLO中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练) 对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类;而对于分类数据集可以仅用来学习分类,但是其可以极大扩充模型所能检测的物体种类。
2、更好、更快、更强
1)为什么更好?
答:在提升召回率和定位精度做了提升,不改变分类精度。
①添加BN层

②高分辨率分类器
YOLOv2做法:将已在224×224的低分辨率图像上训练好的分类网络在448×448的高分辨率图像上进行微调10个epoch。微调完之后再去掉最后的GAP层和softmax层作为最后的检测backbone网络。
YOLOv1做法:backbone网络先在ImageNet上进行预训练,预训练时所输入的图像尺寸是224×224,而做检测任务时,YOLOv1所接收的输入图像尺寸是448×448,不难想到,训练过程中,网络必须要先克服由分辨率尺寸的剧变所带来的问题。
③anchor box机制
从YOLOv1中移除FC层并用anchor框去预测BBox。移除一个池化层使得网络卷积层(32倍下采样)后的输出具有更高分辨率(13×13),再将输入图像缩小到416使得特征图有奇数个位置且仅有一个中心点。为每个anchor分别预测类别和置信分数(objec-tness),这两种预测遵从YOLOv1。
缺点:mAP下降且生成BBox数量过多。
优点:recall提升(意味着有更多提升的空间)
Faster RCNN中RPN的原理:RPN网络在这些预先放置好的锚框上去为后续的预测提供ROI区域。每个网格处设定了k个不同尺寸、不同宽高比的anchor box,RPN网络会为每一个anchor box学习若干偏移量:中心点的偏移量和宽高的偏移量。用这些偏移量去调整每一个anchor box,得到最终的边界框。anchor box的本质是提供边界框的尺寸先验,网络使用偏移量在这些先验值上进行调整,从而得到最终的尺寸,对于边界框的学习,不再是之前的“无中生有”了。
anchor box与BBox区别:
anchor box是预设的,用来作为参照框,得到与GT框的IOU,然后让CNN输出物体相对于anchor box的中心点偏移以及长宽比例,用来做位置形状预测。
BBox是根据CNN输出的相对于anchor box中心点偏移以及长宽比例计算出的框,是后面产生的框,用来做分类预测。
训练标注阶段:把anchor box作为训练样本,为了训练样本我们需要为每个锚框标注两类标签:一是锚框所含目标的类别,简称类别;二是真实边界框相对锚框的偏移量,简称偏移量(offset)。找出与每个anchor box交并比最大的GT框,然后GT框的标签作为anchor box的标签,然后计算anchor box相对于GT框的偏移量。在目标检测时,我们首先生成多个锚框,然后为每个锚框预测类别以及偏移量,接着根据预测的偏移量调整锚框位置从而得到预测边界框,最后筛选需要输出的预测边界框。
训练阶段触发anchor box:在经过一系列卷积和池化之后,在feature map层使用anchor box,如下图所示,经过一系列的特征提取,最后针对3×3的网格会得到一个3×3×2×8的特征层,其中2是anchor box的个数,8代表每个anchor box包含的变量数,分别是4个位置偏移量、3个类别(one-hot标注方式)、1个anchor box标注(如果anchor box与真实边框的交并比最大则为1,否则为0)。到了特征层之后对每个cell映射到原图中,找到预先标注的anchor box,然后计算这个anchor box与ground truth之间的损失,训练的主要目的就是训练出用anchor box去拟合GT框的模型参数。
预测阶段:首先在图像中生成多个anchor box,然后根据训练好的模型参数去预测这些anchor box的类别和偏移量,进而得到预测的边界框。由于阈值和anchor box数量选择的问题,同一个目标可能会输出多个相似的预测边界框,这样不仅不简洁,而且会增加计算量,为了解决这个问题,常用的措施是使用NMS。

④维度聚类
不需要人工设计先验框的参数(先验框的数量和大小),在训练集上的BBox做K-means聚类得到好的先验框。聚类的目标是数据集中所有检测框的宽和高,与类别无关。使用IoU作为聚类的衡量指标,如下公式所示:
![]()
优点:得到的结果要比手动设置先验框参数好。
缺点:聚类效果依赖于数据集。倘若数据集规模过小、样本不够丰富,那么由聚类得到的先验框也未必会提供足够好的尺寸先验信息。
⑤定位预测
换上新先验框之后,又对BBox的预测方法做了一些调整:首先对每一个BBox,YO LO仍旧去学习中心点偏移量 t x t_x tx和 t y t_y ty,YOLOv1中是直接用线性函数输出的,而现在改用sigmoid函数使得网络对偏移量的预测是处在0~1范围内的;其次对每个BBox ,由于有了BBox的尺寸先验信息,因此网络不用再去学习整个BBox的宽高,但是仍要学习BBox宽高偏移量。假设某个先验框的宽高分别为: p w p_w pw和 p h p_h ph,网络输出宽高的偏移量为 t w t_w tw和 t h t_h th,则使用下面公式可以算出BBox的宽和高。


⑥使用更高分辨率的特征
在前面的改进中,YOLOv1都是在最后一张大小为13×13×1024的特征图上进行检测,为了引入更多的细节信息,作者将backbone的第17层卷积输出的26×26×512特征图拿出来,做一次特殊的降采样操作,得到一个13×13×2048特征图,然后将二者在通道的维度上进行拼接,最后在这张融合了更多信息的特征图上去做检测。
特殊下采样操作:类似pixelshuffle的逆操作:passthrough。这种特殊降采样操作的好处就在于降低分辨率的同时,没丢掉任何细节信息,信息总量保持不变。

⑦多尺度训练
使用图像金字塔。通过使用图像金字塔的操作,网络能够在不同尺寸下去感知同一目标,从而增强了其本身对目标尺寸变化的鲁棒性,提升了YOLO对物体的尺度变化的适应能力。
2)为什么更快?
①全卷积网络结构
网络的输入图像尺寸从448改为416,去掉了YOLOv1网络中的最后一个池化层和所有的全连接层,修改后的网络的最大降采样倍数为32,最终得到的也就是13×13的网格,不再是7×7。每个网格处都预设了k个anchor box。

原先的YOLOv1中,每个网格处的B个边界框都有一个置信度,但是类别是共享的,因此每个网格处最终只会有一个输出,而不是B个输出(YOLOv1只输出置信度最高的那一个),倘若一个网格包含了两个以上的物体,那必然会出现漏检问题。加入anchor box后,YOLOv1改为每一个anchor box都预测一个类别和置信度,即每个网格处会有多个边界框的预测输出。YOLOv2的输出张量大小是S×S×k×(1+4+C),每个边界框的预测都包含1个置信度、4个边界框的位置参数和C个类别预测。
②Darknet-19
网络结构:

卷积层有19层:包括线性卷积、BN层以及LeakyReLU激活函数。
做法:首先将DarkNet19在ImageNet上进行预训练,预训练完毕后,去掉最后一层卷积层(与此同时添加3个大小为3×3卷积核数量为1024的卷积层,其中每个3×3卷积层之后都跟一个大小为1×1且数量同检测的输出数量的卷积核的卷积层,还从最后一个卷积层中添加了从最后一个3×3×512的层到第二个3×3×512的层的passthro-ugh层)、GAP层以及softmax层,然后换掉原先的backbone网络。
3)为什么更强? 此为YOLO9000内容
①在分类、检测数据集上联合训练
原理:使用专门为检测贴标签的图像去学习特定的检测信息(BBox坐标预测和object-ness置信分数),使用专门为分类贴标签的图像去扩展可检测的目标类别。
做法:混合检测、分类数据集,当网络看到检测标签图时,网络反向传播YOLOv2的全部loss;当网络看到分类标签图时,网络仅反向传播特定的分类loss。
问题:检测数据集仅有常见标签,而ImageNet类别太细化,怎么去融合标签?
解决方案:使用多标签模型组合标签不互斥的数据集。
②建立分类层级树:WordTree
结合分类数据集和检测数据集标签。计算类别概率就可以用条件概率/全概率来计算,如: P r ( N o r f o l k t e r r i e r ) = P r ( N o r f o l k t e r r i e r ∣ t e r r i e r ) ∗ P r ( t e r r i e r ∣ h u n t i n g d o g ) ∗ … … ∗ P r ( m a m m a l ∣ a n i m a l ) ∗ P r ( a n i m a l ∣ p y s i c a l o b j e c t ) Pr(Norfolk terrier)=Pr(Norfolk terrier|terrier)*Pr(terrier|hunting dog)*……*Pr(mammal|animal)*Pr(animal|pysical object) Pr(Norfolkterrier)=Pr(Norfolkterrier∣terrier)∗Pr(terrier∣huntingdog)∗……∗Pr(mammal∣animal)∗Pr(animal∣pysicalobject)

3、Darknet-19代码实现
class Conv_BN_LeakyReLU(nn.Module):
def __init__(self, in_channels, out_channels, ksize, padding=0, dilation=1):
super(Conv_BN_LeakyReLU, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(in_channels, out_channels, ksize, padding=padding, dilation=dilation),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1, inplace=True)
)
def forward(self, x):
return self.convs(x)
class DarkNet_19(nn.Module):
def __init__(self, num_classes=1000):
print("Initializing the darknet19 network ......")
super(DarkNet_19, self).__init__()
# backbone network : DarkNet-19
# output : stride = 2, c = 32
self.conv_1 = nn.Sequential(
Conv_BN_LeakyReLU(3, 32, 3, 1),
nn.MaxPool2d((2,2), 2),
)
# output : stride = 4, c = 64
self.conv_2 = nn.Sequential(
Conv_BN_LeakyReLU(32, 64, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 8, c = 128
self.conv_3 = nn.Sequential(
Conv_BN_LeakyReLU(64, 128, 3, 1),
Conv_BN_LeakyReLU(128, 64, 1),
Conv_BN_LeakyReLU(64, 128, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 16, c = 256
self.conv_4 = nn.Sequential(
Conv_BN_LeakyReLU(128, 256, 3, 1),
Conv_BN_LeakyReLU(256, 128, 1),
Conv_BN_LeakyReLU(128, 256, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 32, c = 512
self.conv_5 = nn.Sequential(
Conv_BN_LeakyReLU(256, 512, 3, 1),
Conv_BN_LeakyReLU(512, 256, 1),
Conv_BN_LeakyReLU(256, 512, 3, 1),
Conv_BN_LeakyReLU(512, 256, 1),
Conv_BN_LeakyReLU(256, 512, 3, 1),
nn.MaxPool2d((2,2), 2)
)
# output : stride = 32, c = 1024
self.conv_6 = nn.Sequential(
Conv_BN_LeakyReLU(512, 1024, 3, 1),
Conv_BN_LeakyReLU(1024, 512, 1),
Conv_BN_LeakyReLU(512, 1024, 3, 1),
Conv_BN_LeakyReLU(1024, 512, 1),
Conv_BN_LeakyReLU(512, 1024, 3, 1)
)
self.conv_7 = nn.Conv2d(1024, 1000, 1)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = self.conv_1(x)
x = self.conv_2(x)
x = self.conv_3(x)
x = self.conv_4(x)
x = self.conv_5(x)
x = self.conv_6(x)
x = self.conv_7(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
4、论文总结
本文较YOLOv1改进点:只说YOLOv2
①移除了FC层,在卷积层上添加了BN层。
②在低分辨率图像上训练好的网络再放到高分辨率图像中微调,使得检测网络能够对高分辨率图像做出较快适应。
③用anchor box机制生成BBox,对BBox预测方法做了改进。
④使用多尺度训练,具体表现在使用图金字塔。
⑤将类似GoogLeNet的网络替换为Darknet-19网络。
⑤一个网格可以预测多个类别,漏检情况减少。
本文贡献:
①提出了YOLOv2和YOLO9000
②用维度聚类方法产生更好的先验框(anchor boxes)
③使用passthrough层从而可以使用更高分辨率的特征
④提出Darknet-19网络
本文缺点:
①YOLOv2输出量太大,使得运算时间加长了。
②anchor box机制会出现聚类所获得的先验框严重依赖于数据集本身的问题。
③YOLOv1只使用了最后一个经过32倍降采样的特征图即C5特征图,而尽管YOLOv2使用了passthrough技术将16倍降采样的特征图即C4特征图融合到了C5特征图中,但最终的检测仍是在C5尺度的特征图上进行的,最终结果便是导致了模型的小目标的检测性能较差(YOLOv1与YOLOv2的共同缺点)
三、Yolov3
1、论文简介
论文名称:《YOLOv3: An Incremental Improvement》
论文链接:yolov3
论文源码:yolov3实现
yolov3实现+自己理解
摘要:我们对YOLO进行了更新,做了一系列小的设计修改,使之更好,除此之外还训练了一个新网络DarkNet-53,虽然比YOLOv2使用的网络要大但是运行速度很快。在320×320图像中YOLOv3以28.2 mAP的速度在22毫秒内运行,与SSD一样精确,但速度快了三倍。相比之下RetinaNet与YOLOv3性能相似,但速度快3.8倍。
BBox预测:用均方差损失函数,每个BBox置信分数用罗杰思特回归计算得到。
类别预测:用单独的罗杰思特分类器,不用softmax,训练时用BCEloss。是多标签分类预测(即每个框不一定只有一类,而有多类)
2、结构设计
Darknet-53
特征提取器backbone——Darknet-53(融合了darknet-19和ResNet的方法)

注意:Darknet-53降采样使用的是步长为2的卷积,而没用maxpooling。卷积层仍是线性卷机+BN层+LeakyReLU激活函数。
特点:比Darknet-19更强,比ResNet-101和ResNet-152更快。
整体结构

每个特征图上,YOLOv3在每个网格处放置3个先验框。由于YOLOv3一共使用3个尺度,因此,YOLOv3一共设定了9个先验框,这9个先验框仍旧是使用kmeans聚类的方法获得的。注意:YOLOv3的先验框尺寸不同于YOLOv2,后者是除以了32,而前者是在原图尺寸上获得的,没有除以32。
每个先验框预测依然是置信度+位置偏移+类别,因此每个尺度预测的张量通道数为3×(1+4+C)。如果输入图像尺寸为416×416,那么yolov3在一种尺度上最终会输出52×52×3×(1+4+C)、26×26×3×(1+4+C)、13×13×3×(1+4+C)三个预测张量,然后将这些预测结果汇总到一起,进行后处理并得到最终的检测结果。
3、Darknet-53代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import os
import sys
__all__ = ['darknet53']
class Conv_BN_LeakyReLU(nn.Module):
def __init__(self, c1, c2, k=1, p=0, s=1, d=1):
super(Conv_BN_LeakyReLU, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(c1, c2, k, padding=p, stride=s, dilation=d),
nn.BatchNorm2d(c2),
nn.LeakyReLU(0.1, inplace=True)
)
def forward(self, x):
return self.convs(x)
class resblock(nn.Module):
def __init__(self, ch, nblocks=1):
super().__init__()
self.module_list = nn.ModuleList()
for _ in range(nblocks):
resblock_one = nn.Sequential(
Conv_BN_LeakyReLU(ch, ch//2, k=1),
Conv_BN_LeakyReLU(ch//2, ch, k=3, p=1)
)
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
x = module(x) + x
return x
class DarkNet_53(nn.Module):
"""
DarkNet-53.
"""
def __init__(self, num_classes=1000):
super(DarkNet_53, self).__init__()
# stride = 2
self.layer_1 = nn.Sequential(
Conv_BN_LeakyReLU(3, 32, k=3, p=1),
Conv_BN_LeakyReLU(32, 64, k=3, p=1, s=2),
resblock(64, nblocks=1)
)
# stride = 4
self.layer_2 = nn.Sequential(
Conv_BN_LeakyReLU(64, 128, k=3, p=1, s=2),
resblock(128, nblocks=2)
)
# stride = 8
self.layer_3 = nn.Sequential(
Conv_BN_LeakyReLU(128, 256, k=3, p=1, s=2),
resblock(256, nblocks=8)
)
# stride = 16
self.layer_4 = nn.Sequential(
Conv_BN_LeakyReLU(256, 512, k=3, p=1, s=2),
resblock(512, nblocks=8)
)
# stride = 32
self.layer_5 = nn.Sequential(
Conv_BN_LeakyReLU(512, 1024, k=3, p=1, s=2),
resblock(1024, nblocks=4)
)
# self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# self.fc = nn.Linear(1024, num_classes)
def forward(self, x, targets=None):
c1 = self.layer_1(x)
c2 = self.layer_2(c1)
c3 = self.layer_3(c2)
c4 = self.layer_4(c3)
c5 = self.layer_5(c4)
# x = self.avgpool(x)
# x = x.view(x.size(0), -1)
# x = self.fc(x)
return c3, c4, c5
4、论文总结
本文较yolov2改进点:
①从单级检测(只在C5特征图做检测)改变为使用FPN结构与多级检测方法(分别在C3\C4\C5特征图上针对目标大小有选择地做检测);
②特征提取backbone由不带残差结构的Darknet-19替换为带有残差结构的Darknet-53;

缺点:精度仍然落后于RetinaNet检测器
四、Yolov4
1、论文简介
论文名称:《YOLOv4: Optimal Speed and Accuracy of Object Detection》
论文链接:yolov4
论文源码:yolov4实现一
yolov4实现二
摘要:有大量的trick可以提高CNN的准确性。需要在大型数据集上对这些trick的组合进行实际测试,并对结果进行理论证明。某些trick只在某些模型上奏效,或者说只在某些问题上运行,或者只在小规模数据集上运行;而一些trick,如BN和残差连接适用于大多数模型、任务和数据集。我们假设这些通用trick包括加权残差连接(WRC)、跨阶段部分连接(CSP)、跨小批量标准化(CmBN)、自我对抗训练(SAT)和Mish激活。我们使用了新方法:WRC、CSP、CmBN、SAT、Mish激活、Masaic数据增强、CmBN、DropBlock正则化和CIoU loss,并结合这些trick中的一些以达到SOTA。
本文意图:欲解决目标检测系统速度和精度之间的平衡,并用1片GPU训练。设计一个更快速的目标检测器并优化并行计算。

作者总结目标检测器通常包含的元素有:输入、骨干网络、脖颈、头部。
输入包括:Image, Patches, Image Pyramid
Backbone包括:VGG-16、ResNet、ResNeXt、DenseNet、SpineNet、EfficientNet-B0/B7、CSPResNeXt50、CSPDarknet53
Neck包括:
①添加额外块:SPP、ASPP、RFB、SAM
②通路聚合块:FPN、PAN、NAS-FPN、FC-FPN、BiFPN、ASFF、SFAM
Head包括:
①密集预测(单阶段基于anchor):RPN、SSD、YOLO、RetinaNet
②密集预测(单阶段anchor-free):CornerNet、CenterNet、MatrixNet,、FCOS
③稀疏预测(两阶段基于anchor):Faster R-CNN、R-FCN、Mask RCNN
④稀疏预测(两阶段anchor-free):RepPoints
2、结构简介
Yolov4组成部分:
- Backbone: CSPDarkNet53
- Neck: SPP、FPN+PAN
- Head: YOLOV3
Yolov4用到的BoF:
①对backbone使用的:CutMix、Mosaic数据增强、DropBlock正则化、类标签平滑(Class Label Smoothing)。
②对检测器使用的:CIoU loss、CmBN(交叉小批量标准化)、DropBlock正则化、Mosaic数据增强、SAT自对抗训练、消除网格敏感性、为单个GT box使用多个anchor、余弦退火调度器、最优超参数、随机训练形状。
Yolov4用到的BoS:
①对backbone使用的:Mish激活函数、CSP:Cross-stage partial connections、MiWRC:Multi-input weighted residual connections。
②对检测器使用的:Mish激活函数、SPP、SAM(将空间上注意力改为点注意力)、PAN(将shrot-connect从相加修改为拼接)、DIoU NMS
Bag of Freebies:指的是那些不增加模型复杂度,也不增加推理的计算量的训练方法技巧,来提高模型的准确度。
主要代指:
1)数据增强:图像几何变换(随机缩放,裁剪,旋转),Cutmix,CutMix, Mosaic、SAT等
2)网络正则化:Dropout, Dropblock等
3)损失函数的设计:边界框回归的损失函数的改进如CIOU、GIOU等
4)数据不平衡问题:HEM、OHEM、focal loss、label smoothingBag-of-Specials:指的是那些增加少许模型复杂度或计算量的训练技巧,但可以显著提高模型的准确度。
主要代指:
1)增大模型感受野:SPP、ASPP等
2)引入注意力机制:SE、SAM
3)特征集成:PAN,BiFPN、FPN、ASFF、SFAM
4)激活函数改进:Swish、Mish、ReLU、Leaky-ReLU、ReLU6
5)后处理方法改进:soft NMS、DIoU NMS、NMS

YOLOv4的五个基本组件:
CBM:由Conv+Bn+Mish激活函数三者组成。
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concat组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合
2.1、输入端策略
a、Mosaic数据增强
Why?:在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而COCO数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。
How?:采用了4张图片,用随机缩放、随机裁剪、随机排布的方式进行拼接。
效果:

优点:
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU:Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
2.2、特征提取策略
a、CSPDarknet53
why CSP?:推理计算过高的问题是由于网络优化中的梯度信息重复导致的,主要从网络结构设计的角度解决推理中从计算量很大的问题。
how?:采用CSP模块先将基础层的特征图划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
优点:
- 增强CNN的学习能力,使得在轻量化的同时保持准确性。
- 降低计算瓶颈,降低内存成本
CSPNet:跨阶段局部网络,从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题(推理计算量之所以过高是因为网络优化中的梯度信息重复导致)。
CSPNet怎么做:通过将梯度的变化从头到尾地集成到特征图中,减少计算量的同时保证了准确率。它是一种处理思想,可与ResNet,DenseNet等网络结合。
CSPNet具有的特点:①增强CNN的学习能力,在保持轻量化的同时保证准确率;②降低计算瓶颈;降低内存成本。
CSPNet示例一(应用于DenseNet):将输入的特征图按照通道数分成了两个部分,其中一个部分正常进行Dense Block操作,另一部分直接进行Concat操作。因每个DenseBlock操作的输入通道都变少了,所以计算量也减少了。
concat方式本文采取下图b的方式,结合了c和d的优点。c的优点是大量的梯度信息可以被重复利用,有利于学习;d因梯度流被阻断,不能重复利用梯度信息,但由于transition层的输入通道比c要少,计算复杂度也能够大大减少。
CSPNet示例二(应用于ResNe(X)t):两个分支都包含全部通道数,两部分先通过1×1卷积各得到1/2的输出通道。分支2在此之后还要通过没有BottleNeck的ResNet Block和一个1×1卷积之后才得到该分支的输出。
局部过渡层目的是最大化梯度联合的差异,使用梯度流阶段的手段避免不同的层学习到重复的梯度信息。



CSPDarkNet53:https://blog.csdn.net/Jaredzzz/article/details/108560087

注:YOLO V4使用时删去了最后的池化层、全连接层以及Softmax层。CSPDarkNet和CSPResNe(X)t整体思路相仿,沿用网络的卷积核尺寸和整体结构,在每组残差块都加上了一个跨阶段局部结构,同时取消了BottleNeck结构。


注:每个body在part1和part2之前都要经过下采样处理(卷积处理),这样能够很大程度上减少参数量和计算量,提高运行速度。
b、Dropblock正则化
why?:卷积层对于这种随机丢弃并不敏感。因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。因此在全连接层上效果很好的Dropout在卷积层上效果并不好。
how?:将整个局部区域进行删减丢弃,借鉴了cutout数据增强,cutout是将输入图像的部分区域清零,而Dropblock是将Cutout应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。
效果:
优点:
- cutout只能作用于输入层,而Dropblock则是将Cutout应用到网络中的每一个特征图上
- Dropblock可以定制各种组合,在训练的不同阶段可以修改删减的概率,从空间层面和时间层面,和cutout相比都有更精细的改进,效果也更好。
2.3、Neck策略
a、SPP模块

用在backbone之后。本文在SPP模块中,使用k={1×1,5×5,9×9,13×13}的最大池化的方式,再将不同尺度的特征图进行Concat操作。
注意:这里最大池化采用padding操作,stride为1,比如13×13的输入特征图,使用池化核大小为5×5做池化,padding=2,因此池化后的特征图仍然是13×13大小。
b、FPN+PAN(路径聚合网络)
yolov4输入为608×608×3图片时结构图:

最后Prediction中用于预测的三个特征图:①76×76×255,②38×38×255 ③19×19×255。
FPN+PAN工作结构如下:

这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行特征聚合。
2.4、输出端策略
a、CIOU loss
①IOU loss

出现的问题:

问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
②GIOU_loss
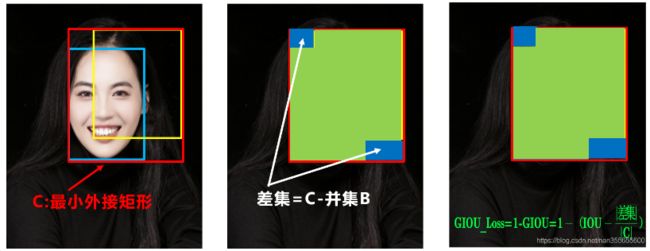
GIOU_Loss中,增加了相交尺度的衡量方式,缓解了IOU_Loss的一些问题
出现的问题:

问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。基于这个问题,又提出DIOU_Loss
③DIOU_loss
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU和GIOU存在的问题,作者从两个方面进行考虑
一:如何最小化预测框和目标框之间的归一化距离?
二:如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题提出了DIOU_loss,DIOU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。但就像前面好的目标框回归函数所说的,这时并没有考虑到长宽比。

出现的问题:

问题:比如上面三种状态,目标框包裹预测框,本来DIOU_Loss可以起作用。但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。针对这个问题,又提出了CIOU_Loss。
④CIOU_loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。

其中v是衡量长宽比一致性的参数,我们也可以定义为:

这样CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
总结IOU loss:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
b、DIOU-NMS
为什么不用CIOU_nms,而用DIOU_nms?
答:因为CIOU_loss是在DIOU_loss的基础上添加了影响因子,包含groundtruth标注框的信息,在训练时用于回归。
但在测试过程中,并没有groundtruth的信息,不用考虑影响因子,因此直接用DIOU_nms即可。
效果:

3、论文总结
本文贡献:
①开发了一个集快速、精准度为一体的目标检测模型,使得任何人都可以用一片1080Ti或2080Ti去训练。
②检测器训练过程中验证了SOTA所使用的Bag-of-Freebies 和 Bag-of-Specials。
③修改了已有的SOTA并使之更高效、更适合于单个GPU训练,包括CBN、PAN、SAM
本文较yolov3改进点:
①将backbone改进为CSPDarkNet53
②用BoF和BoS中的部分有效方法,具体表现如下:
- 输入端:Mosaic数据增强、cmBN、SAT自对抗训练
- BackBone主干网络:CSPDarknet53、Mish激活函数(后面的网络仍然使用Leaky-ReLU)、Dropblock
- Neck:SPP、FPN+PAN结构
- Head:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU loss,以及预测框筛选的nms变为DIOU_nms
五、Yolov5
1、结构设计
整体结构设计为:

YOLOV5使用策略:
- 输入端:Mosaic数据增强,自适应anchor计算,自适应图片缩放
- Backbone:Focus结构,CSP结构
- Neck:FPN+PAN
- 输出端:GIOU_LOSS
2.1、输入端策略
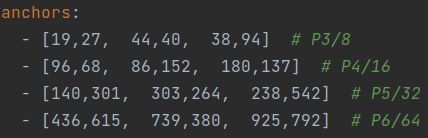
a、自适应anchor计算
现在对于不同数据集的anchor计算都是如下策略:训练中网络在初始anchor的基础上输出预测框,和GT比对后计算两者的差距,再反向更新并迭代网络参数。
YOLOV3、YOLOV4是通过运行单独的K-means来计算初始anchor的值。
YOLOV5是将该功能嵌入训练中,每次训练自适应计算不同数据集中最佳anchor值。
YOLOV5的anchor预设值在models/hub/*.yaml中:
b、自适应图片缩放
改进的letterbox策略:对原始图像自适应的添加最少量的黑边。
| 策略 | 图片 |
|---|---|
| 原始图片(800×600) |  |
| 初始letterbox策略(不保持原图像的宽高比)(416×416) |  |
| 改进的letterbox策略(保持原图像的宽高比)(416×352) |  |
letterbox具体步骤:
- 计算宽高缩放比例系数,选择小的缩放系数
- 计算缩放后的尺寸
- 计算黑边填充数值
注:
- 训练时采用的初始letterbox策略,推理使用的是改进的letterbox策略。
- np.mod函数之所以使用stride=32,是因为YOLOV5特征提取网络经过了5此下采样,每次下采样倍数为32。所以从原图上计算得到的像素也同样需要下采样32倍操作。
2.2、特征提取策略
a、Focus结构

关键操作是切片操作:如右图将特征图尺寸减半,维度增加4倍,此策略与YOLOV2中的passthrough相似。
Focus结构在yolov5s模型最后使用了32个卷积核,后续三种模型使用的卷积核数量则会有所增加。
b、CSP结构
YOLOV4只在Backbone使用了CSP思想,激活函数使用Mish,在分出两个分支之前进行下采样操作
YOLOV5在Backbone和Neck都有使用,激活函数使用LeakyReLu,取消了在分出两个分支之前的下采样操作


2.3、 Neck策略
FPN+PAN使用CSPNet思想
2.4、输出端策略
a、CIOU loss
b、官方NMS
可改进的策略:改进yolov5中general.py中的NMS代码实现
- DIOU-NMS:将NMS中的IOU阈值改为DIOU
- soft-NMS:将NMS算法中去除其他边界框改成修改其他边界框的置信度
2.5、模型缩放
根据yaml文件中的depth_multiple,width_multiple控制四种结构的深度、宽度。
图6中CSP1_1代表使用CSP1_X结构,使用一个Res Block

图7表示不同阶段的卷积核的数量也是不一样的,直接影响卷积后特征图的第三维度宽度

五、SSD
1、论文简介
论文名称:《SSD: Single Shot MultiBox Detector》
论文链接:SSD
源码:SSD实现
摘要:我们提出了一种使用单个CNN检测图像中目标的方法,该方法称为SSD。将BBox的输出空间离散化为一组默认的Box,该Box在每个特征图位置上有不同的纵横比和尺寸。在预测时,网络为每个默认框的每个存在的目标类别生成分数,并对框进行调整,以更好地匹配目标的形状。此外该网络将多个具有不同分辨率的特征图的预测结合起来,以自适应地处理各种大小的目标。SSD模型相对于region proposal方法要简单,因为它完全消除了proposal生成和后续像素或特征重采样阶段,并将所有计算封装在单个网络中。这使得SSD易于训练,并且可以直接集成到需要检测组件的系统中。在PASCAL VOC、COCO和ILSVRC数据集上SSD与使用region proposal的方法相比具有相似准确性并且速度更快,同时SSD为训练和推理提供了统一的框架。与其他单阶段方法相比,SSD具有更好的精度。
提出问题:怎么做到精度和速度的平衡
解决方案:
①使用基于CNN的不对像素或特征进行重采样的检测器。
②用小卷积核预测类别和BBox位置偏移。
③使用不同纵横比的分离的预测器(卷积核)并应用到后面的多个特征图中以实现多尺度检测。
优点:输入低分辨率图像也可以输出高进度检测结果,提高检测速度。
2、结构设计
SSD检测框架

图a:SSD训练期间仅需输入图像和每个目标的BBox
图b\图c:1)卷积时在具有不同尺度的若干特征图的每个位置处评估不同纵横比的一小组默认Box,对每个默认Box都预测所有目标类别的置信分数 ( c 1 , c 2 , . . . , c p ) (c_1,c_2,...,c_p) (c1,c2,...,cp)和形状偏移;
2)训练时让默认Box对GT进行匹配;
3)loss为定位损失(SmoothL1 loss)与分类损失(softmax loss)的加权求和。
SSD方法概述
基于前馈CNN产生固定大小的BBox集合和框中目标类别的置信分数,然后用NMS方法得到最终检测结果。本文使用VGG-16模型,再在此基础上添加了辅助结构。SSD的关键点如下所述:
①多尺度特征图检测:将卷积特征层添加到截断基础网络的末尾,实现了多尺度检测。对于每个特征层,预测检测的卷积模型不同。(这与Overfeat和YOLOv1只在单个尺度特征图上检测,仅有一个检测卷积模型不同)
②检测的卷积预测器:每个添加的特征层可以使用一组卷积核产生固定的预测集。对于具有p个通道的大小为m×n的特征层,使用3×3×p的小卷积核做卷积操作,产生类别的分数或相对于默认框的相对形状偏移。在每个应用卷积核运算的m×n大小位置处,产生一个输出值。这个BBox偏移输出值是相对于默认框测量的,默认框位置则是相对于每个特征图的。

③默认框和纵横比:将一组默认的BBox与顶层网络的每个特征图单元关联。每个特征图单元预测在单元中相对于默认框的偏移,同时预测各类别的分数。具体来说,对于在给定位置的k个框中每个框计算c类分数和相对于原始默认框的4个形状偏移量,这使得在特征图中的每个位置需要总共(c+4)k个卷积核,对于m×n特征图产生(c+4)kmn个输出。默认框这种方法与Faster RCNN中的anchor相似,但是本文是将默认框应用于不同分辨率的特征图中。在多个特征图中使用不同的默认框形状,可以有效地将可能的输出框形状空间离散化。
3、论文总结
SSD是在多尺度特征图上提取得到特征,然后评估在该尺度下的目标类别概率及BBox位置偏置。训练中应用到匹配策略(筛选默认框)、默认框比例计算法、数据增强和难例挖掘策略。
本文贡献:
①提出SSD这个单阶段检测器——可用于多类别检测,较YOLOv1更快,准度更高;
②SSD方法的核心是使用小卷积核来预测特征图上固定的一组默认BBox的类别分数和位置偏移;
③为了实现高检测精度,从不同尺度的特征图上进行不同尺度的预测,并且通过纵横比来明确地分离预测;
④可以实现端到端训练和高精度,在低分辨率输入上也能够获得精度与准度的平衡。
训练整体流程:
①图像经过卷积网络,得到图像的base特征A;
②在对这个特征进行多层级的提取特征图 B ;
③在每个特征图中各个位置都对应多个默认框;
④计算每个默认框的位置偏移 以及 类别得分;
⑤根据默认框以及位置偏移计算区域位置P,再根据类别得分,计算每个默认框的损失函数,累加得到最终的损失函数。
论文缺点:在各个位置中用到的特征仅是该尺度下的特征,没有结合其它层, 没有权衡语义信息和分辨率信息。
六、RetinaNet
1、论文简介
论文名称:《Focal Loss for Dense Object Detection》
论文链接:RetinaNet
源码:RetinaNet实现
摘要:迄今为止精度最高的目标检测器都是基于R-CNN推广的两阶段检测器,即对稀疏的候选目标位置集合应用分类器。相比之下,对可能的目标位置进行常规、密集采样的单阶段目标检测器可能更快、更简单,但迄今为止,其精度落后于两阶段目标检测器。在本文中我们将探讨为什么会出现这种情况,**我们发现,在密集检测器的训练过程中遇到的极端前景-背景类别不平衡是主要原因。我们通过重塑标准交叉熵损失来解决这一不平衡性,从而降低分类良好的示例损失的权重。Focal loss将训练集中在一组稀疏的难分示例上,并防止大量易分负样本在训练期间中占据主导。**为了评估损失的有效性,设计并训练了一种简单的密集检测器RetinaNet。我们的研究结果表明,当使用Focal loss进行训练时,RetinaNet能够与以前的单阶段检测器的速度相抗衡,同时精度超过现有的SOTA两阶段目标检测器。
提出问题:为什么单阶段目标检测器精度落后于两阶段?
主要原因:单阶段检测器训练中会遇到极端前景-背景不平衡问题。
前人解决类别不平衡问题的方法:固定前景-背景比例、OHEM、bootstrapping、HEM。
本文解决方案:提出Focal loss降低分类较好例子的损失权重。
Focal loss:动态变化比例的交叉熵损失,当正确类别置信度增加时,比例因子会衰减到0。比例因子在训练中可自动降低简单样本对权重的贡献并快速使模型关注困难样本。用Focal loss损失训练模型使得训练较用抽样启发和难例挖掘的方法效果更佳。Focal loss没有确切的格式,可以随着任务不同自己调整格式。
单阶段检测器RetinaNet:需要在输入图片中对目标位置做密集采样。特点是在一个有效的网络内使用特征金字塔和anchor框。本文实验得出最好的RetinaNet模型是基于ResNet-101-FPN的,超过了之前所有单模型的单阶段、两阶段目标检测器
2、结构设计
Focal Loss
Cross Entropy Loss(CE)→Balanced Cross Entropy Loss(BCE)→Focal Loss(FL)
①二分类交叉熵损失定义为:

上述 y ∈ ± 1 y \in \pm1 y∈±1 代表前景和背景, p ∈ [ 0 , 1 ] p∈[0,1] p∈[0,1]是模型预测属于前景 y = 1 y=1 y=1的概率。为了标记方便,定义 p t p_t pt为:

因此简化公式为: C E ( p , y ) = C E ( p t ) = − l o g ( p t ) CE(p,y)=CE(p_t)=-log(p_t) CE(p,y)=CE(pt)=−log(pt)。
②BCEloss:在CE上添加一个权重因子 α ∈ [ 0 , 1 ] \alpha \in[0,1] α∈[0,1]给类别1和 1 − α 1- \alpha 1−α给类别-1,这种 α \alpha α平衡的交叉熵损失记如下,这种损失是对交叉熵损失的简单扩展。
![]()
权重因子 α = 0.75 \alpha=0.75 α=0.75时效果最好。
③Focal Loss:虽然BCEloss平衡了正负样本,但是没有区分易分、难分样本,基于此引入了调节因子 ( 1 − p t ) γ (1-p_t)^{\gamma} (1−pt)γ使得训练聚焦到难分负样本上。其中 γ ≥ 0 \gamma \geq0 γ≥0是可变聚焦参数,因此定义Focal loss为:
![]()
Focal loss性质:
a) 当一个样本被误分类并 p t → 0 p_t→0 pt→0时,调节因子 ( 1 − p t ) γ → 1 (1-p_t)^{\gamma}→1 (1−pt)γ→1且损失没有改变。当 p t → 1 p_t→1 pt→1时, ( 1 − p t ) γ → 0 (1-p_t)^{\gamma}→0 (1−pt)γ→0即分类较好的样本权重较低。
b) 易分样本权重较低时,聚焦参数 γ \gamma γ平滑地调整比率。当 γ = 0 \gamma=0 γ=0时,Focal loss等于交叉熵损失,当 γ \gamma γ增长时,调节因子的影响也在增长。

上图表明了不同 γ \gamma γ对loss效果的影响,当 p t p_t pt越大即易分样本,其对应的loss越小。
④本文最终使用的是带有BCEloss权重因子 α t \alpha_t αt的Focal loss:
![]()
优点:通过 α t \alpha_t αt可以抑制正负样本的数量失衡,通过 γ \gamma γ可以控制易分\难分样本的数量失衡。
注意:Focal loss的精确形式不是很重要,可以有很多变体。
⑤本文中其他形式的Focal loss
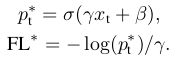
效果如下:


Focal loss使用场景:目标检测训练中正负样本极不平衡时。
RetinaNet
由一个主干网络和两个特定任务子网组成。主干网络提取整张输入图像的特征图,主要包括前馈ResNet+FPN,加入FPN目的是为了获得丰富的多尺度特征;第一个子网对主干网络的输出做目标分类,有anchor;第二个子网做预测框回归,从先验框到GT框。

①ResNet+FPN:使用金字塔层的 P 3 P_3 P3到 P 7 P_7 P7,结构如下:
| 层数 | 获得源头 | 源头处操作 |
|---|---|---|
| P 3 P_3 P3 | ResNet( C 3 C_3 C3) | 直接从输出计算 |
| P 4 P_4 P4 | ResNet( C 4 C_4 C4) | 直接从输出计算 |
| P 5 P_5 P5 | ResNet( C 5 C_5 C5) | 直接从输出计算 |
| P 6 P_6 P6 | ResNet( C 5 C_5 C5) | 在 C 5 C_5 C5上做3×3步长为2的卷积运算 |
| P 7 P_7 P7 | P 6 P_6 P6 | 在 P 6 P_6 P6上做3×3步长为2的卷积运算 |
与FPN不同之处:
1)没有用高分辨率的 P 2 P_2 P2金字塔层,因为计算太复杂;
2) P 6 P_6 P6是通过有步长的卷积运算得到,而没用FPN中的下采样;
3)在FPN基础上添加了 P 7 P_7 P7层,提升大型目标的检测性能。
②分类子网:在每个空间位置上对于每个A个anchor和K个目标类别预测当前目标出现的概率,这个子网是一个连接每个FPN层的小型FCN;子网参数可以共享到金字塔的各个层,只用到3×3卷积,但不与回归子网共享参数。
| 层数 | 卷积核尺寸 | 卷积核数量 | 步长/填充 | 输入尺寸 | 输出尺寸 |
|---|---|---|---|---|---|
| conv1+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv2+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv3+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv4+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv5 | 3×3 | K×A | 1/1 | W×H×256 | W×H×K×A |
| sigmoid | / | / | / | W×H×K×A | K×A |
③回归子网:与分类子网并行,此子网也是一个连接到每个FPN层的小型FCN,最后输出得到anchor框相对于邻近GT框的偏移量。设计同分类子网,但是每个空间位置的输出为4A个(即输出A个anchaor框的相对偏移量x,y,w,h)。因此与之前不同的是本文使用是这种参数更少、类不可知且同样高效的BBox回归,即虽然分类子网和回归子网共享同一个FPN,但是使用不同参数。
| 层数 | 卷积核尺寸 | 卷积核数量 | 步长/填充 | 输入尺寸 | 输出尺寸 |
|---|---|---|---|---|---|
| conv1+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv2+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv3+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv4+ReLU | 3×3 | 256 | 1/1 | W×H×256 | W×H×256 |
| conv5 | 3×3 | K×A | 1/1 | W×H×256 | W×H×K×A |
| sigmoid | / | / | / | W×H×K×A | 4×A |
3、Focal loss pytorch实现
from torch import nn
import torch
from torch.nn import functional as F
class focal_loss(nn.Module):
def __init__(self, alpha=0.25, gamma=2, num_classes=5, size_average=True):
"""
focal_loss损失函数, -α(1-yi)**γ *ce_loss(xi,yi)
步骤详细的实现了 focal_loss损失函数.
:param alpha: 阿尔法α,类别权重. 当α是列表时,为各类别权重,当α为常数时,类别权重为[α, 1-α, 1-α, ....],常用于 目标检测算法中抑制背景类 , retainnet中设置为0.25
:param gamma: 伽马γ,难易样本调节参数. retainnet中设置为2
:param num_classes: 类别数量
:param size_average: 损失计算方式,默认取均值
"""
super(focal_loss, self).__init__()
self.size_average = size_average
if isinstance(alpha, list):
assert len(alpha) == num_classes # α可以以list方式输入,size:[num_classes] 用于对不同类别精细地赋予权重
print(" --- Focal_loss alpha = {}, 将对每一类权重进行精细化赋值 --- ".format(alpha))
self.alpha = torch.Tensor(alpha)
else:
assert alpha < 1 # 如果α为一个常数,则降低第一类的影响,在目标检测中为第一类
print(" --- Focal_loss alpha = {} ,将对背景类进行衰减,请在目标检测任务中使用 --- ".format(alpha))
self.alpha = torch.zeros(num_classes)
self.alpha[0] += alpha
self.alpha[1:] += (1 - alpha) # α 最终为 [ α, 1-α, 1-α, 1-α, 1-α, ...] size:[num_classes]
self.gamma = gamma
def forward(self, preds, labels):
"""
focal_loss损失计算
:param preds: 预测类别. size:[B,N,C] or [B,C] 分别对应与检测与分类任务, B批次, N检测框数, C类别数
:param labels: 实际类别. size:[B,N] or [B] [B*N个标签(假设框中有目标)],[B个标签]
:return:
"""
# 固定类别维度,其余合并(总检测框数或总批次数),preds.size(-1)是最后一个维度
preds = preds.view(-1, preds.size(-1))
self.alpha = self.alpha.to(preds.device)
# 使用log_softmax解决溢出问题,方便交叉熵计算而不用考虑值域
preds_logsoft = F.log_softmax(preds, dim=1)
# log_softmax是softmax+log运算,那再exp就算回去了变成softmax
preds_softmax = torch.exp(preds_logsoft)
# 这部分实现nll_loss ( crossentropy = log_softmax + nll)
preds_softmax = preds_softmax.gather(1, labels.view(-1, 1))
preds_logsoft = preds_logsoft.gather(1, labels.view(-1, 1))
self.alpha = self.alpha.gather(0, labels.view(-1))
# torch.mul 矩阵对应位置相乘,大小一致
# 这里对应于公式的loss = -(1-p_t)^y*log(p_t)
loss = -torch.mul(torch.pow((1 - preds_softmax), self.gamma), preds_logsoft)
# torch.t()求转置
loss = torch.mul(self.alpha, loss.t())
if self.size_average:
loss = loss.mean()
else:
loss = loss.sum()
return loss
4、论文总结
本文贡献:
①提出了一种基于交叉熵损失的新loss:Focal loss,通过控制正负样本权重和易分/难分样本权重得到好的结果(因为类别不平衡是一阶段检测器的通病,所以这点改进效果提升明显),使得目标检测器准确率提升,同时实现了单阶段目标检测的密集检测。
②提出全卷积的单阶段检测器RetinaNet,backbone使用ResNet+FPN,使用了多尺度特征的方法,并在FPN的基础上做了一些改进,使得保证检测精度的同时提升检测速度。
缺点:速度太慢
七、YOLOF
1、论文简介
论文名称:《You Only Look One-level Feature》
论文链接:YOLOF
实现源码:YOLOF实现
摘要:本文回顾了用于单阶段检测器的FPN,指出FPN的之所以是由于它对目标检测中的优化问题的分而治之的解决方案,而不是多尺度特征融合。从优化的角度来看,我们引入了一种替代方法来解决这个问题,而不是采用复杂的FPN——只使用一层特征进行检测。基于简单而高效的解决方案,我们提出了YOLOF,在该方法中,提出了两个关键组件:膨胀编码器和均衡匹配,并带来了相当大的改进。在COCO benchmark上的大量实验证明了该模型的有效性,YOLOF在速度为RetinaNet的2.5倍的情况下,实现了与带有特征金字塔的RetinaNet相当的结果。在没有transformer层的情况下,YOLOF可以利用单层特征与DETR的性能相抗衡,并且训练次数可以减少7倍。
提出问题:能否不用FPN就达到分而治之的目的?(因为多层分治会使检测器结构复杂从而降低检测速度)
分析问题:FPN中有两种策略:①多尺度融合策略;②分治策略(即针对不同目标尺度选择在不同的层检测目标)。
实验实施:解耦两种策略,在RetinaNet上分别用这两种策略中的一种。将FPN看做是多入多出编码器,并对比多入多出,单入多出,多入单出,单入单出策略,对比发现多入多出,单入(C5特征图)多出得到的mAP指标相距甚微。
实验结论:C5特征图已经携带了足够多的不同尺度上的检测上下文信息,多尺度特征融合策略没有分治策略对FPN那么重要。
解决方法:用一层C5特征图解决优化策略问题,提出YOLOF。为弥补单入单出和多入多出编码器的性能差距,提出了膨胀编码器(解决多层特征信息缺乏问题)和均衡匹配组件(解决单一特征中稀疏anchor引起的真样本anchor的不平衡问题)。
2、结构设计
SiSo结构取代MiMo结构造成性能大幅下降原因:①与C5特征图感受野匹配的目标尺度范围是有限的,阻碍了不同尺度目标的检测性能;②单层特征图上由稀疏anchor生成策略引起的正样本anchor的不均衡问题。
膨胀编码器
受限尺度范围问题
SISO结构只会输出固定感受野的单层特征图。如图(a)所示,当一层特征图只能覆盖一个受限的感受野,且目标的尺度和感受野不匹配时检测效果就会很差。
通过堆叠标准卷积和膨胀卷积增大感受野,使得覆盖尺度范围得到一定程度的扩大,但仍不能覆盖所有的目标尺度,因为扩大过程相当于将一个大于1的因子乘以原来覆盖的所有尺度。如图(b)所示,表明了扩大了的尺度范围虽然可以使得特征能够覆盖大目标,但是仍然会错失小目标的检测。
如果将原始特征图(C5)和扩大感受野的特征图相加,就能覆盖所有目标尺度的特征图。如图©所示,具有多个感受野的特征覆盖了所有目标尺度。

通过在中间的3×3卷积层上构造带有膨胀的残差块实现,将之称为膨胀编码器。

膨胀编码器有两个模块:投影模块+残差模块。该编码器使得我们可以再单层特征图中做各种尺度的目标检测,不需要再使用多层特征图了。残差模块的第一个1×1卷积用于减少通道维数,3×3卷积用于增大感受野,第二个1×1卷积用于恢复通道维数。
| 模块类型 | 元素 | 说明 |
|---|---|---|
| 投影模块 | 1个1×1卷积层+1个3×3卷积层 | 1×1卷积用于减少通道维数,3×3卷积用于提炼语义上下文信息,与FPN相同。 |
| 残差模块 | 4×(1×1卷积层+3×3卷积层+1×1卷积层) | 每个膨胀残差块的膨胀率不同,以此产生多感受野的输出特征图,包含所有目标尺度。 |
注:每个膨胀残差快没有共享权重,投影模块每个卷积层是CB(Conv+BN)范式,残差模块每个卷积层都是CBR(Conv+BN+ReLU)范式。
均衡匹配策略
正样本anchor不均衡问题
正样本定义是基于anchor和GT框之间的IOU进行的,若一个anchor和GT之间的最大IOU大于一个给定的阈值叫这个anchor为正样本的话,则称此策略为Max-IOU匹配。
MiMo结构中,anchor以一个密集平铺的方式在多层特征图上预定义,GT框根据尺度在不同层的特征图上产生正样本,Max-IOU匹配使得GT框在各个尺度可以产生足够数量的正样本。但在SiSo结构中,正样本数量急剧减少,导致anchor非常稀疏,对稀疏anchor采用Max-IOU引起的问题如下:
大GT框回避小GT框产生更多的正anchor,从而造成了正anchor的不平衡问题,导致检测器只关注大目标而忽视小目标。

均衡匹配策略:对每个GT框而言,将K个最近的anchor和K个最近的预测框的索引标记为标记为正样本,使得GT框无论尺度大小(也可以说目标无论大小)都有相同数目的正样本与之匹配。
YOLOF

backbone:ResNet和ResNeXt系列,输出特征图是C5,通道数2048,下采样率32。
neck(encoder):对backbone输出使用两个投影模块,再用残差模块,结构上面已说。
head(decoder):两个并行分支,用于目标分类和边框回归。在DETR的FFN基础上修改两处:①两个head卷积层数目不同,回归分支中,是四个卷积层+BN层+ReLU层,分类分支是只有两个卷积层;②依据Autoassign,为回归分支的每个anchor增加一个隐式的置信分数objectness(没有直接监督),最终分类的置信度是由分类分支的输出和objectness得分相乘得到(与Yolov1类似)。
4、论文总结
本文贡献:
①发现FPN最重要的好处是对密集目标检测器的优化问题上有分治策略,多尺度特征融合只是其次的。
②提出YOLOF,不用FPN达分治目的。提出YOLOF关键组件:扩展编码器和均衡匹配,弥补SiSo与MiMo编码器的性能差距。使用单层特征图就可以达到多尺度目标检测的目的。
③在COCO基准上做了各组件重要性测试,并与RetinaNet和DETR做了对比,在精度几乎一致的前提下速度提高了。
八、CornerNet
1、论文简介
论文名称:《CornerNet: Detecting Objects as Paired Keypoints》
论文链接:CornerNet
实现源码:CornerNet实现
摘要: CornerNet——一种新的目标检测方法即使用单个CNN将目标BBox看作成对的关键点的检测,这个关键点是左上角以及右下角(通过检测目标框的左上角和右下角两个关键点得到预测框)。 通过将目标检测为成对的关键点,这就不需要再用anchor框了。 除了新构思之外,我们还引入了边角池化,这是一种新型的池化层,可以帮助网络更好地定位角点。 实验表明,CornerNet 在 MS COCO 上实现了 42.2% 的 AP,优于所有现有的一级检测器。
本文动机:可以不用anchor做目标检测吗?
分析基于锚框检测器的缺点:
①产生锚框的数量太大,造成正样本锚框样本及其不均衡,训练速度也慢。
正样本不均衡原因:anchor框数量巨大,能与GT框的IOU超过设定阈值的anchor框并不多,如果想解决此问题需要设定IOU阈值上下限、设定正负样本比例以及难负例挖掘。
②使用锚框引入了许多超参数如锚框数量、尺寸、长宽比,当与多尺度模型架构结合时会使问题变得更加复杂
复杂原因:单个网络在多个分辨率图像上是进行单独预测的,每个分辨率对应不同尺度大小,不同尺度大小又会使用不同的特征和独有的一组锚框。(锚框的尺寸是根据图像以及目标尺度来的,不是随便设的,因此各个尺度的锚框是独有的,可以自己根据经验设定锚框超参数,也可以根据Kmeans聚类确定)
解决办法:提出anchor-free的CenterNet。
具体做法①:将目标检测为一对关键点,这个关键点是BBox的左上角和右下角。使用单个CNN来预测同一目标类别的所有实例的左上角的热图、右下角热图以及每个检测角的嵌入向量,embedding用于对属于同一对象的一对角进行分组,具体是计算两种角点embedding的距离,若距离最小则说明两个角点是同一类目标。训练网络也就是要让网络能够预测它们的相似embedding。
优点:简化了网络输出并除去了anchor框。

具体做法②:提出角池化层,该层以两个特征图作为输入,在每个像素位置,从其中一个特征图上最大池化位于这个位置右边的所有位置的特征向量,从另外一个特征图上最大池化位于这个位置下边的所有位置的特征向量,然后将两个向量相加得到此位置的最终向量(长度为1)。每个类别独立进行该操作,因此有多少个类别,这个向量长度就是num_classes,所有位置的向量就构成了一张热图。
优点:帮助CNN更好地定位BBox的角点。
检测角点为什么比检测中心点或region proposal方法更好?
答:①框的中心点很难去定位因为它依赖于目标的四条边,而定位角点方法只需要两条边就够了,再加上角池化运用了角的先验知识(即左上角是由最上边界和最左边界确定这样的),因此更加简单。②比起region proposal方法,角在离散化BBox空间上更加高效。比如一张 ( h , w ) (h,w) (h,w)大小的特征图,检测角点方法一共只有 w h wh wh种可能,而带有anchor框的region proposal方法则有 A w h Awh Awh种可能,设每个位置有A个anchor。
2、结构设计
CornerNet总体框架
网络预测两组热图去表征不同目标类别的角点位置以及嵌入向量。

流程:网络输入图像之后先经过1个7×7的卷积层将图像缩小为原来的1/4,然后经过backbone(沙漏网络)提取特征,之后再通过两个预测模块,分别是左上角预测分支和右下角预测分支,每个分支模块最终产生3个输出:heatmap、embeddings、offsets。
heatmap是角点信息,用维度为CHW的特征图表示,其中C表示目标类别(无背景类),特征图每个通道都是一个mask,mask的每个值表示该点是角点的得分;
embedding表示对预测的角点做分组的分组信息,也就是说找到属于同一目标的左上角和右下角;通道为1因为embedding只需要在一张图中反映各类别目标信息。
offsets表示预测框的微调,这是因为从输入图像中的点映射到特征图时有量化误差,offsets就用来输出这些误差信息。通道为2是因为要分别调整x,y轴方向的。
沙漏网络

一个沙漏网络由若干沙漏模块组成(本文为两块),沙漏模块具体结构为:

沙漏结构先由卷积和池化将输入下采样到一个很小的尺寸,之后再用最近邻上采样方法进行上采样,将特征图恢复到最开始的尺度,每个上采样层都有一个跳跃连接,跳跃连接是一个残差模块。沙漏结构可以获取不同尺度下图片的信息,有局部信息和全局信息。
预测模块
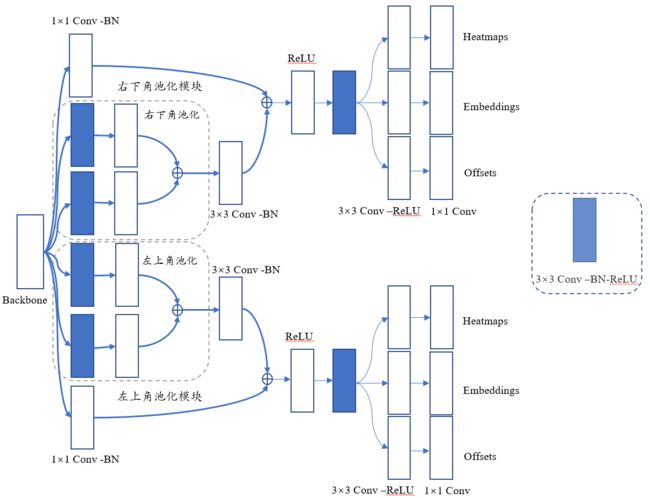
角池化
角池化层原理:当BBox的角不包含目标时,不能根据局部特征对角进行定位。一般确定像素位置是否是左上角,需要从这个位置水平向右看,知道是不是目标的最上边界,同时也需要垂直向下看,才能知道是不是目标的最左边界。

角池化概念:
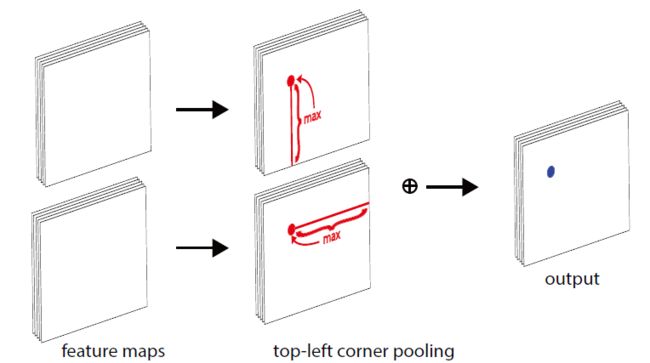

式子中 f t f_t ft和 f l f_l fl分别代表输入到左上角池化层的特征图, f t i j f_{tij} ftij和 f l i j f_{lij} flij分别代表在特征图 f t f_t ft和 f l f_l fl位置(i,j)处的向量,如果特征图大小为H×W,那么首先池化层需要最大池化在特征图 f t f_t ft的(i,j)和(i,H)之间的所有向量化为 t i j t_{ij} tij,然后再最大池化在特征图 f l f_l fl的(i,j)和(i,W)之间的所有向量化为 l i j l_{ij} lij,最后将 t i j t_{ij} tij和 l i j l_{ij} lij相加。右下角层化层工作原理与左上角相似。

loss函数
对每个角都有一个相对于GT的正位置,所有其他位置都是负的。训练期间减少正位置半径内负位置的惩罚,确保半径内的一对点将生成一个与GT的IOU至少为t的BBox以此来确定半径。给定半径,则惩罚量的减少由未归一化的2D高斯函数给出,这里中心点 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)为正样本角点位置, σ \sigma σ为半径的1/3。

那么这个半径怎么确定呢?
答:依赖于目标BBox的宽高,以IOU=0.7作为临界值,分别计算出下面三种临界情况的半径,取最小值作为高斯核的半径。情况一为两个角点均出现圆外切情况,如果使得BBox与GT的IOU大于0.7即交集要增大,那么要将绿色框缩小,此时圆半径变小;情况二为两个角点均出现圆内切情况,如果使得BBox与GT的IOU大于0.7,那么要将绿色框增大,此时圆半径变小;情况三为一个角点出现圆内切情况且另一个角点出现圆外切情况,如果使得BBox与GT的IOU大于0.7,那么需要使得绿色框向红色框方向偏移,圆半径变小。若要同时满足上面三种情况,则需要取所有圆半径的交集作为高斯核半径。

①Headmaps的loss函数:


p c i j p_{cij} pcij表示预测的热图在第C个通道(类别C)的位置 ( i , j ) (i,j) (i,j)的得分;
y c i j y_{cij} ycij表示为使用非归一化高斯函数增强的GT热图在第C个通道(类别C)的位置 ( i , j ) (i,j) (i,j)的值;
( 1 − y c i j ) (1-y_cij) (1−ycij)可以理解为从预测角点到GT角点的距离,这个距离被高斯函数非线性化了,所以离GT近的负样本惩罚就小了。
y c i j = 1 y_{cij}=1 ycij=1表示此位置就是GT角点位置;
N N N为一张热图中目标数量, α 、 β \alpha、\beta α、β控制难分易分样本的损失权重。
②Embeddings的loss函数:
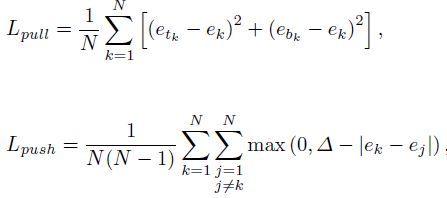
其中 e t k e_{tk} etk是目标左上角的embedding得分, e b k e_{bk} ebk是目标右下角的embedding得分, e k e_k ek代表 e t k e_{tk} etk和 e b k e_{bk} ebk均值,
N代表GT中目标数量, Δ \Delta Δ就是一个常数因子,论文中设置为1。
Pull loss越小表示同一目标的左上角和右下角的embedding的得分距离越小即左上角和右下角匹配同一目标的可能性越大,push loss越小表示不同的目标的左上角和右下角的embedding得分距离越大即左上角和右下角匹配同一目标的可能性越小。
③Offsets的loss函数:
一张图输入到网络中,原先位置为(x,y)的投影到热图就变为(x/n, y/n),n是下采样率,当从热图再投影回输入图像时就会出现量化误差(即有除不整的情况出现,这样会导致投影回去的坐标有差距,影响IOU的计算),为解决此问题,在投影回原输入图像之前微调角点位置。

这里 o k o_k ok是GT角点的偏移量, x k x_k xk和 y k y_k yk代表角点k的x和y坐标。

这里 o k ^ \hat{o_k} ok^是预测角点的偏移量,N代表GT中目标数量
④总损失函数
![]()
3、训练测试细节
训练:
- 随机初始化的,没有在任何外部数据集上进行预训练。
- 遵循Focal loss for dense object detection中的方法设置预测Heatmaps的卷积层的biases。
- 网络的输入分辨率是511×511, 输出分辨率为128×128。
- 为了减少过拟合,我们采用了标准的data augmentation,包括随机水平翻转、随机缩放、随机裁剪和随机色彩抖动,其中包括调整图像的亮度,饱和度和对比度。
- 使用PCA分析图像数据。
- 使用Adam优化训练损失
测试:
使用simple post-processing算法从Heatmaps, Embeddings, Offsets生成BBox。首先在heatmaps上使用3*3的max pooling进行非极大值抑制(NMS)。然后从Heatmaps中选择scores前100的top-left corners和前100的bottom-right corners,corner的位置由Offsets上相应的scores调整。 最后,计算top-left corners和bottom-right corners所对应的Embeddings的L1距离。距离大于0.5或包含不同类别的角点对将被剔除。配对上的top-left corners和bottom-right corners以Heatmaps的平均得分用作检测分数。
作者没有使用resize的方法保持输入图像的原始分辨率一致,而是维持原分辨率,用0填充缺失和超出的部分。 原始图像和翻转图像都参与测试,并应用soft-nms来抑制冗余检测。 仅记录前100个检测项。
4、论文总结
本文贡献:
①提出角点检测方法生成BBox,免除了anchor框。
②提出角池化概念,帮助CNN更好地定位角点。
③第一个将目标检测任务表述为使用embedding检测和角点分组任务。
④修改了沙漏架构并且对focal loss做改变去训练网络。
缺点:
①计算速度慢,因为要逐像素进行最大池化操作。
②小目标检测性能一般
九、CenterNet
1、论文简介
论文名称:《Objects as Points》
论文链接:CenterNet
实现源码:CenterNet实现
摘要:检测将目标识别为图像中的轴对齐框。 大多数成功的对象检测器都会列举详尽的潜在目标位置列表,并对每个位置进行分类。 这是浪费的、低效的,并且需要额外的后处理。 在本文中我们采用了不同的方法。我们将一个目标建模为一个点——BBox的中心点。 我们的检测器使用关键点估计来找到中心点并回归到所有其他目标属性,如大小、3D 位置、方向,甚至姿势。CenterNet具有端到端的可微分性且比相应的基于BBox的检测器更简单、更快且更准确。
问题:①anchor的定义在一定程度上限制了算法的性能。②后处理操作会降低整个检测的速度,大多数检测器都不是端到端可训练的。
解决措施:通过BBox的中心点来表示目标,然后直接从中心位置的图像特征回归得到其他属性,因此就将目标检测问题化成了关键点检测问题,只需要将图像输入到生成热图的FCN中,此热图的峰值就是目标中心。每个热图的峰值预测目标的BBox高宽,训练用标准密集监督学习,测试用单网络前向传递,没有NMS。
优点:①输出分辨率大,下采样率为4,对小目标召回率高。②不需要NMS
缺点:同一类别的两个物体中心点相同,模型只能给出一个物体检测框,因为输出特征图同一位置只设置一个样本。
2、结构设计
CenterNet总体框架
网络预测关键点值 Y ^ \hat{Y} Y^,偏移 O ^ \hat{O} O^,大小 S ^ \hat{S} S^,网络在每个位置总共预测C+4个输出,所有输出共享一个共同的FCN网络。


backbone
分别使用三种backbone对比实验

(a)为使用沙漏网络,(b)为使用转置卷积的ResNet网络,©为使用最初语义分割的DLA-34网络,(d)为使用修改的DLA-34网络
若用ResNet50提取图片特征,首先使用反卷积改变通道维度,然后再用转置卷积对特征图进行上采样(3个转置卷积因此上采样三次),最后三个分支卷积网络用来预测heatmap, 目标的宽高和目标的中心点坐标。值得注意的是转置卷积模块,其包括三个转置卷积组,每个组都包括一个3*3的卷积和一个转置卷积,每次转置卷积都会将特征图尺寸放大一倍。

结论:沙漏网络性能最好,但速度最慢。
损失函数
①Heatmaps的loss函数:
对于类别C的每个GT关键点 p ∈ R 2 p\in R^2 p∈R2都计算一个低分辨率等价的 p ~ = [ p R ] \tilde{p}=[\frac{p}{R}] p~=[Rp],然后使用高斯核将所有的GT关键点放在一张热图 Y ∈ [ 0 , 1 ] W R × H R × C Y \in [0,1]^{\frac{W}{R}×\frac{H}{R}×C} Y∈[0,1]RW×RH×C上。如果同一类的两个高斯函数重叠,取逐元素最大值。训练置信分数是用带有focal loss的逐像素惩罚减少的逻辑回归。
L k = − 1 N ∑ x y c { ( 1 − Y ^ x y c ) α log ( Y ^ x y c ) if Y x y c = 1 ( 1 − Y x y c ) β ( Y ^ x y c ) α log ( 1 − Y ^ x y c ) otherwise L_{k}=\frac{-1}{N} \sum_{x y c}\left\{\begin{array}{cl} \left(1-\hat{Y}_{x y c}\right)^{\alpha} \log \left(\hat{Y}_{x y c}\right) & \text { if } Y_{x y c}=1 \\ \left(1-Y_{x y c}\right)^{\beta}\left(\hat{Y}_{x y c}\right)^{\alpha} \log \left(1-\hat{Y}_{x y c}\right) & \text { otherwise } \end{array}\right. Lk=N−1∑xyc⎩ ⎨ ⎧(1−Y^xyc)αlog(Y^xyc)(1−Yxyc)β(Y^xyc)αlog(1−Y^xyc) if Yxyc=1 otherwise
这里 α \alpha α和 β \beta β是focal loss的超参数,N是图像I的关键点数目。GT关键点信息为 Y x y c Y_{xyc} Yxyc,预测关键点信息为 Y ^ x y c \hat{Y}_{xyc} Y^xyc。
②Offsets的loss函数:
为恢复输出步长引起的离散化误差,对每个中心点另外预测了一个局部偏移 O ^ ∈ R W R × H R × 2 \hat{O}\in R^{\frac{W}{R}×\frac{H}{R}×2} O^∈RRW×RH×2,所有类别C共享相同的偏差预测。
L o f f = 1 N ∑ ∣ O ^ p ~ − ( p R − p ~ ) ∣ L_{o f f}=\frac{1}{N} \sum\left|\hat{O}_{\tilde{p}}-\left(\frac{p}{R}-\tilde{p}\right)\right| Loff=N1∑∣ ∣O^p~−(Rp−p~)∣ ∣
p是GT中心点在原图中坐标,p/R是理论上该点映射到特征图的坐标,实际上映射后的坐标为 p ~ = ⌊ p R ⌋ \tilde{p}=\lfloor\frac{p}{R}\rfloor p~=⌊Rp⌋,量化误差为 ( p R − p ~ ) (\frac{p}{R}-\tilde{p}) (Rp−p~),KaTeX parse error: Got function '\tilde' with no arguments as subscript at position 8: \hat{O_\̲t̲i̲l̲d̲e̲{p}}是网络的offset输出特征图,即预测中心点的偏移。
监督只在关键点位置 p ^ \hat{p} p^起作用,其他位置都是忽略的。
③weight&height的loss函数:
( x 1 ( k ) , y 1 ( k ) , x 2 ( k ) , y 2 ( k ) ) (x_1^{(k)},y_1^{(k)},x_2^{(k)},y_2^{(k)}) (x1(k),y1(k),x2(k),y2(k))为目标k的GT坐标, s k = ( x 2 ( k ) − x 1 ( k ) , y 2 ( k ) − y 1 ( k ) ) s_k=(x_2^{(k)}-x_1^{(k)},y_2^{(k)}-y_1^{(k)}) sk=(x2(k)−x1(k),y2(k)−y1(k))是目标k的宽高,因为坐标已经除以下采样率了,所以计算出来的是在输出特征图上的大小。为限制计算量,对所有目标类别使用单个尺寸的预测 S ^ ∈ R W R × H R × 2 \hat{S}\in R^{\frac{W}{R}×\frac{H}{R}×2} S^∈RRW×RH×2,用L1loss计算中心点置信loss。不归一化尺度直接用原始像素坐标。

训练中整体loss:
![]()
Heatmaps生成步骤
产生热图步骤:
如下图左边是缩放后送入网络的图片,尺寸为512x512,右边是生成的heatmap图,尺寸为128x128(网络最后预测的heatmap尺度为128x128。其步骤如下:
①将目标的box缩放到128x128的尺度上,然后求box的中心点坐标并取整,设为point
②根据目标box大小计算高斯圆的半径,设为R
③在heatmap图上,以point为圆心,半径为R填充高斯函数计算值。(point点处为最大值,沿着半径向外按高斯函数递减)

由于两个目标都是猫,为同一类别,所以在同一张热图上,若输入图像上还有其他类别的目标,则该目标的关键点在另外一张热图上显示。
测试阶段细节
推理阶段,首先在热图中对每个类别独立地提取峰值,检测所有值小于或等于它的8邻域的响应,并保留前100的峰值,设 P c P_c Pc是类别c的n个检测中心点 P ^ = ( x ^ i , y ^ i ) i = 1 n \hat{P}=(\hat{x}_i,\hat{y}_i)_{i=1}^n P^=(x^i,y^i)i=1n的集合,通过一个整数坐标 ( x i , y i ) (x_i,y_i) (xi,yi)得到每个关键点位置,使用关键点值 Y ^ x y c \hat{Y}_{xyc} Y^xyc作为它的检测置信度度量,并且在关键点位置处产生一个BBox。

这里 ( δ x ^ i , δ y ^ i ) = O ^ x ^ i , y ^ i (\delta\hat{x}_i,\delta\hat{y}_i)=\hat{O}_{\hat{x}_i,\hat{y}_i} (δx^i,δy^i)=O^x^i,y^i是预测的偏移, ( w ^ i , h ^ i ) = S ^ x ^ i , y ^ i (\hat{w}_i,\hat{h}_i)=\hat{S}_{\hat{x}_i,\hat{y}_i} (w^i,h^i)=S^x^i,y^i是预测的尺寸。所有的输出直接由关键点估计产生,不需NMS等后处理,因为峰值关键点提取就已经能够看作是一个充分的NMS方案了,这个提取可以用3×3最大池化来完成。
3、论文总结
本文贡献:模型可应用于两阶段和单阶段,可推广到目标检测、3D检测和人体姿态识别领域
本文优点:没有用基于IOU的NMS方法,用到3×3最大池化对生成的热图进行抑制,筛选出最有可能出现的点。省去了NMS时间。
本文缺点:
①若两个不同物体中心点在一起,CenterNet只会检测到其中的一个。
②小目标检测性能一般
十、CenterNet++
1、论文简介
论文名称:《CenterNet: Keypoint Triplets for Object Detection》
论文链接:CenterNet
实现源码:CenterNet实现
摘要:在目标检测中,基于关键点的方法通常会遇到大量不正确的目标边界框,这可能是由于缺少对裁剪区域的检查。 本文提出了一种有效的解决方案,以最小的成本检索每个裁剪区域内的视觉模式。我们方法命名为CenterNet,是在CornerNet基础上做的。它将每个目标检测为一个三元组关键点,而不是一对关键点,提高了精度和召回率。 此外还设计了两个自定义模块,分别称为级联角池化和中心池化,它们分别起到丰富左上角和右下角收集的信息并在中心区域提供更多可识别信息的作用。 在 MS-COCO 数据集上,CenterNet 实现了 47.0% 的 AP,比所有现有的一级检测器至少高出 4.9%。 同时,凭借更快的推理速度,CenterNet 表现出与顶级两阶段检测器相当的性能。
问题:CornerNet对目标全局信息的引用能力较弱,这制约了模型性能。(每个目标由一对角构成,算法对检测目标的边界很敏感,但是不知道哪些关键点应该被归为目标)
分析原因:CornerNet无法查看边界框内的区域

解决方案:
①提出CenterNet,使用三元组关键点。
②提出中心池化(丰富中心信息,更容易感知中心部分)和级联角池化(丰富角点信息,使原角池化模块具备了感知内部信息的能力)
原理:如果一个预测的BBox与GT有高的IOU,那么其中心区域的中心关键点被预测为同一类的概率就高。在推理过程中,在proposal作为一对角点生成后,通过检查是否有一个属于同一类的中心关键点位于其中心区域,来确定该proposal是否确实是一个目标。
优点:双向池化方法更鲁棒,有助于提高精度和recall
2、结构设计

网络输出两个角点热图和中心点热图,一对角点和embeddings用来对两个角点做匹配生成潜在BBox,中心点用来决定是否最后输出这个BBox。
如何使用三元组关键点
使用CornerNet中提出的方法来生成top-k边界框后,为了有效地过滤不正确的包围框,我们利用检测到的中心关键点,采取以下步骤:
①根据得分选择top-k的中心关键点
②利用相应的偏移量将这些中心关键点重新映射到输入图像上
③为每个边界框定义一个中心区域,并检查中心区域是否包含中心关键点。 注意,选中的中心关键点的类标签应与BBox的类标签相同。
④如果在中心区域检测到一个中心关键点,我们将保留BBox。 BBox的得分将被左上角、右下角和中心关键点三个点的平均分所取代。 如果在它的中心区域没有检测到中心关键点,BBox将被移除。
边框中心区域大小会影响检测结果,提出尺度感知的中心区域自适应BBox大小。尺度感知的中心区域倾向于为较小的BBox生成相对较大的中心区,为一个较大的BBox生成一个相对较小的中心区。假设想确定一个BBox i是否需要保留, ( t l x , t l y ) (tl_x,tl_y) (tlx,tly)表示左上角坐标, ( b r x , b r y ) (br_x,br_y) (brx,bry)表示右下角坐标;定义一个中部区域 j j j, ( c t l x , c t l y ) (ctl_x,ctl_y) (ctlx,ctly)表示 j j j的左上角坐标, ( c b r x , c b r y ) (cbr_x,cbr_y) (cbrx,cbry)表示 j j j的右下角坐标。使得上面符号满足:

其中n为奇数,决定中心区域j的尺度。论文中对于小于150的边界框和大于150的边界框,n分别设为3和5。

中心池化
为什么要中心池化:物体的几何中心不一定传达可识别的视觉模式,要使用一种可以捕获更丰富和更易于识别的视觉模式的trick才行。
中心池化原理:backbone输出一个特征图,要确定特征图中的一个像素是否为中心关键点,需要在其水平和垂直方向上都找到最大值并相加。 通过这样做,中心池有助于更好地检测中心关键点。

(a)显示中心池化是将垂直和水平方向的最大值相加
(b)显示角池化只是获得了边界方向的最大值
©显示了级联角池化将边界方向和目标内部方向的最大值相加
中心池化模块:结合不同方向角池化即可实现,若想实现水平方向池化,只需串联左池化和右池化即可。


级联角池化
角池化使得角对边非常敏感,需要让角落看到物体的视觉模式。
原理:首先沿边界寻找边界最大值,然后沿着边界最大值的位置寻找内部最大值,然后将两个最大值相加,通过这样做,角既获得了物体的边界信息,又获得了物体的视觉模式。
寻找内部最大值的方向定义:对于最顶部、最左侧、最底部和最右侧边界,分别垂直向下看、水平向右看、垂直向上看、水平向左看。(图里方向画错了)
级联角池化模块:同样是结合不同方向的角池化。例如级联上角池化模块,在上角池化前加入一个左池化即可。


LOSS函数
![]()
L d e t c o L_{det}^{co} Ldetco和 L d e t c e L_{det}^{ce} Ldetce表示Focal Loss,分别用来训练网络检测角点和中心关键点。
L p u l l c o L_{pull}^{co} Lpullco和 L p u s h c o L_{push}^{co} Lpushco同CornerNet。
L o f f c o L_{off}^{co} Loffco和 L o f f c e L_{off}^{ce} Loffce用来训练网络预测角点和中心关键点的偏移量,与CornerNet不同在于这里用l1 loss。
3、测试细节
单尺度:将原始和水平翻转原始分辨率图像作为输入。
多尺度:将原始和水平翻转且分辨率分别为原始图像的0.6,1,1.2,1.5,1.8的图像作为输入。
选择热图中分数最高的70个中心点、70个左上角点以及70个右下角点去检测BBox,翻转水平翻转图像中检测到的BBox,并将之混合到原始BBox中。用Soft-nms去除多余BBox,最终根据得分选前100的BBox作为最终检测结果。
4、论文总结

本文贡献:
①对CornerNet做了改进,自定义中心池化和级联角池化模块,使得检测结果更加鲁棒。
②使用三元组角点检测,让池化模块具有感知中心信息和内部信息的能力。
论文缺点:虽然检测性能提升了但是较CornerNet更慢了。
十一、FCOS
1、论文简介
论文名称:《FCOS: Fully Convolutional One-Stage Object Detection》
论文链接:FCOS
论文实现:FCOS实现
摘要:我们提出了一种全卷积的单阶段目标检测器(FCOS),以类似于语义分割的逐像素预测方式解决目标检测问题。 几乎所有最先进的目标检测器,如 RetinaNet、SSD、YOLOv3 和 Faster R-CNN 都依赖于预定义的锚框。 相比之下,我们提出的检测器 FCOS 是anchor-free的,也无region proposal。 通过消除预定义的一组锚框,FCOS 完全避免了与锚框相关的复杂计算,例如在训练过程中计算IOU。 更重要的是,我们还避免了所有与锚框相关的超参数,这些超参数通常对最终检测性能非常敏感。凭借唯一的后处理NMS方式,FCOS with ResNeXt-64x4d-101在单模型单尺度测试的 AP 中达到 44.7%,超越了之前的单阶段检测器,且优势在于FCOS更简单。
动机:提出一种anchor-free检测器,使得检测器避免anchor、region proposal和anchor超参数。
问题1:现阶段目标检测都是需要预定义anchor的
解决方案:提出FCOS,使得它可以以类似FCN语义分割的逐像素预测方式进行目标检测。
问题2:FCOS可能会产生大量低分辨率的预测BBox
解决方案:引入新的center-ness分支来预测像素与其相应BBox中心的偏差,使得基于 FCN 的检测器可以超过基于锚框的检测器。
问题3:FCOS遇到目标重叠可能会带来recall降低,怎么解决?
解决方案:使用FPN结构,使不同尺度的目标能够在不同尺度的特征图上检测出,避免了上述问题。
实验结论:①能够以逐像素方式对目标进行预测②基于FCN的检测器比基于锚的性能更优。
FCOS优点:
①与其他使用FCN的任务(语义分割)是一样的,可以用到其他任务中的思想。
②不需要proposal和anchor,减少了参数量
③FCOS在单阶段是SOTA,也可以作为两阶段检测器的RPN网络,实现了优于基于锚框的RPN算法性能。
④FCOS可以小改后用到其他任务中:实例分割和关键点检测。
2、结构设计
网络设计

网络直接使用了RetinaNet的backbone,只是在分类分支上多了一个center-ness用于确定当前点是否是检测目标的中心;而由于没有anchor,最后分类分支和回归分支输出的feature map depth也分别是C和4,不需要乘以anchor数(K),因此相比anchor based的输出,FCOS的骨架输出可用减少K倍;而分类分支的分类器也从多分类器换成了C个二分类器。
正样本制作
特征图上的某个点只要落在GTbox区域中,这个点就是正样本;**如果这个点在多个GT box中,那么这个点就是混淆样本,当混淆情况出现时文章采用面积最小的GTBox作为这个点的回归目标。**目标框的回归从回归GT坐标 ( x 0 ( i ) , y 0 ( i ) , x 1 ( i ) , y 1 ( i ) ) (x_0^{(i)},y_0^{(i)},x_1^{(i)},y_1^{(i)}) (x0(i),y0(i),x1(i),y1(i))改变到回归当前点到框的各边距离 ( l , t , r , b ) (l,t,r,b) (l,t,r,b)。相比基于anchor的检测器,这种检测器能够产生更多的正样本用于训练回归,因此这也是FCOS性能超过其他基于anchor检测器的原因之一。

loss函数
L ( { p x , y } , { t x , y } ) = 1 N p o s ∑ x , y L c l s ( p x , y , c x , y ∗ ) + λ N p o s ∑ x , y 1 { c x , y ∗ > 0 } L r e g ( t x , y , t x , y ∗ ) \begin{aligned} L\left(\left\{\boldsymbol{p}_{x, y}\right\},\left\{\boldsymbol{t}_{x, y}\right\}\right) &=\frac{1}{N_{\mathrm{pos}}} \sum_{x, y} L_{\mathrm{cls}}\left(\boldsymbol{p}_{x, y}, c_{x, y}^{*}\right) +\frac{\lambda}{N_{\mathrm{pos}}} \sum_{x, y} \mathbb{1}_{\left\{c_{x, y}^{*}>0\right\}} L_{\mathrm{reg}}\left(\boldsymbol{t}_{x, y}, \boldsymbol{t}_{x, y}^{*}\right) \end{aligned} L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑1{cx,y∗>0}Lreg(tx,y,tx,y∗)
L c l s L_{cls} Lcls是focal loss( p x , y p_{x,y} px,y是分类分数, c x , y ∗ c_{x,y}^* cx,y∗是类别) L r e g L_{reg} Lreg是IOU loss( t x , y t_{x,y} tx,y是GT的location参数, t x , y ∗ t_{x,y}^* tx,y∗是回归预测的location参数), N p o s N_{pos} Npos代表正样本数量, λ = 1 \lambda=1 λ=1是 L r e g L_{reg} Lreg的权重, 1 c x , y ∗ > 0 \mathbb{1}_{c_{x, y}^{*}>0} 1cx,y∗>0代表如果类别是前景则判断为1,否则是0。整个式子是在特征图 F i F_i Fi中计算所有location的loss(i是特征图所在层数)。
1、focal loss
2、IOU loss


基于FPN的多层预测
问题背景:对应于问题3
细节1:直接限制各层特征图上能够回归的距离范围。首先需要计算所有特征层上的每个回归位置的l,t,r,b,如果一个点的 m a x ( l , t , r , b ) > m i max(l,t,r,b)>m_i max(l,t,r,b)>mi或 m a x ( l , t , r , b ) < m i − 1 max(l,t,r,b)
细节2:预测头在各层是公用的(同FPN),降低参数量同时提高了性能,但是每一层的回归尺寸大小不同(每一层都设计不同的尺寸范围),因此回归计算的时候使用包含可训练标量 s i s_i si的 e x p ( s i x ) exp(s_ix) exp(six)来自动调整特征层 P i P_i Pi的指数函数的基底,这会轻微提升检测性能。
Center-ness
问题背景:对应于问题2
设计初衷:因为有大量远离GTBox的低质量误检,设计Center-ness用于预测当前点是否是目标的中心。目标点的中心度评价公式为:

根号是为了降低中心度随距离增大的衰减程度。因为中心度大小都在0~1之间,因此在训练时使用BCE loss,然后将这个loss添加到整体loss函数中;在推理的时候直接将中心度分数乘到分类分数上,将偏离很远的检测框分值进行惩罚,然后用NMS就可以很容易去除。
替代方案:仅使用GT box的中心部分作为正样本,但是会增添一个额外超参。Center-ness方法和替代方案的结合可实现更好性能。
3、实验结果
①FCOS中FPN的在降低混淆上的作用远大于其在提高召回率上的作用
②Center-ness可以显著提高精度
③Center-ness方法和仅将GT box中心作为正样本训练方法的结合可实现更好性能。

4、论文总结
这篇论文中的框架结构是对RetinaNet的继承
论文贡献:
①用语义分割逐像素预测的方式进行目标检测
②FCOS可以替代Faster RCNN中的RPN网络,性能优于RPN。
③可以从本论文中拓展为其他任务
论文缺点:
①使用FPN必定会使检测器速度变慢
十二、YOLOX
1、论文简介
论文名称:《YOLOX: Exceeding YOLO Series in 2021》
论文链接:yolox
论文实现:yolox实现
摘要:我们介绍了对 YOLO 系列的一些改进,形成了一种新的高性能检测器——YOLOX。 将 YOLO 检测器切换为anchor-free的并进行其他高级检测技术,即解耦头和领先的标签分配策略 SimOTA,在大规模模型范围内都能达到SOTA:对于 YOLONano 只有 0.91M 参数和 1.08G FLOPs,我们在 COCO 上获得 25.3% AP,超过 NanoDet 1.8% AP; 对于 YOLOv3,我们在 COCO 上将其提升到 47.3% AP,比之前高出 3.0% AP; 对于与 YOLOX-L 参数量大致相同的YOLOv4-CSP、YOLOv5-L,在 COCO 上达到了 50.0% AP,超出 YOLOv5-L 1.8%的AP。
问题:YOLO系列较强的检测器都是基于anchor的,但是现在较流行的检测器都是anchor-free的
解决:yolov4和yolov5已经是在基于anchor的检测器中达到了过度优化,已经没有优化空间了,那么这篇文章就从yolov3(yolov3-SPP)作为出发点。
2、结构设计
2.1、前期加强yolov3 Baseline策略
选用yolov3作baseline的一些初步加强细节
- Darknet53作为特征提取网络
- 采用SPP层
- EMA权重更新策略(具体原理见yolov7第4节可训练策略第6点)
- COS学习率调整策略
学习率衰减策略介绍
①指数衰减
②固定步长衰减
③多步长衰减:适合后期调试使用
④余弦退火衰减
⑤等间隔衰减
⑥自适应衰减:当某指标(loss或是acc)不再变化下(降或升高超过给定阈值),调整学习率
⑦自定义调整学习率:为不同参数组设定不同学习率调整策略。fine-tune 中十分有用,我们不仅可为不同的层设定不同的学习率,还可以为其设定不同的学习率调整策略。参考:[1] https://zhuanlan.zhihu.com/p/93624972
[2] https://blog.csdn.net/shanglianlm/article/details/85143614
- 定位损失使用IOU loss和IOU-aware分支,分类和置信损失均使用BCE loss
- 数据增强使用随机垂直翻转、颜色抖动、多尺度策略,废弃RandomResizedCrop因为会跟mosaic重复。
2.2、后期加强策略
- 解耦头策略:将分类任务和回归任务分开
解耦头策略详解:
背景:分类任务与回归任务有冲突
分析:耦合检测头会对性能造成不利影响
解决:解耦这两种任务
结果:①提升了收敛速度及精度②如果想做端到端版本YOLO,即不用NMS的话解耦头较方便

图1:YOLOv3耦合头和本文提出的解耦头结构设计:解耦头先通过1×1卷积将前面的特征图通道变为256,然后再经过2个3×3卷积,接着再通过一个1×1卷积,分别到分类和回归检测,同时回归的分支还增加了IOU-aware分支。
- 数据增强策略:结合Mosaic和MixUp策略,ImageNet预训练已得不到好处,后面全部用从头训练方法。
Mosaic策略:几张图拼接为一张图。

图2:Mosaic策略MixUp策略:将其他图与原图混合,标签也混合。

图3:Mixup策略
- anchor-free策略:每个位置的预测量从3(左上角点偏移量、宽、高)减少到1(中心点),并使得预测量直接预测4个值:相对于网格左上角的偏移量(2个)和预测BBox的宽高(2个)。预定义一个尺度范围(如FCOS一样在FPN的每层设计一个范围)
- 多正样本策略:中心点附近的3×3区域都是正样本(FCOS也是如此做)
- SimOTA策略:标签分配策略。预测样本对每个GT的loss计算为: c i j = L i j c l s + λ L i j r e g c_{i j}=L_{i j}^{c l s}+\lambda L_{i j}^{r e g} cij=Lijcls+λLijreg,simOTA策略相对OTA减少训练时间同时避免了额外的超参。
标签分配是什么:目标检测器目的是要预测预定义的anchor的类别及偏移量。为每个anchor分配cls和reg目标,这个过程称为标签分配(正采样)。
常用标签分配方法:
RetinaNet 、Faster-RCNN:使用预定义的anchor与GT的IOU来区分正负样本。
YOLOV5:使用预定义的anchor与GT 的宽高比进行正采样。
FCOS:处于GT中心区域的BBox作为正样本。
CenterNet:处于物体中心区域的BBox作为正样本
ATSS:同时针对anchor-based和anchor-free的,基于GT的相关特征自动选择正负样本
OTA,simOTA:同时针对anchor-based和anchor-free的。
注:目标检测网络的正负样本判断是分为anchor-base和anchor-free的,anchor-based正负样本判断是依据anchor判断的,而anchor-free正负样本判断是根据产生的bbox来判断的。
OTA产生背景:使用人工规则分配,无法考虑尺寸、形状或边界遮挡的差异性,虽ATSS动态分配使得可以为每个目标动态分配正样本,但都有缺陷即没有全局性考虑(如处理一个模糊标签时,即一个anchor可能对应多个目标,对其分配任何一个标签都有可能对网络学习产生负面影响)。
OTA特点:全局最优的分配策略,提出将标签分配问题当做最优传输问题。
OTA思路及流程:https://blog.csdn.net/weixin_46142822/article/details/124074168?spm=1001.2014.3001.5502
OTA流程:
- 假设图片上有3个GT,2个检测类别,网络输出1000个(anchor)Bbox,只有少部分是正样本。那么候选检测框维度为[1000,4],obj_pred维度为[1000,1],cls_preds维度为[1000,2]。训练网络就是要知道这1000个检测框的标签。
- 筛选之前先进行粗筛选:即中心点或中心点半径范围内的anchor作为正样本。此步可做可不做,但是做了会减少OTA的运算量并提高精度。
- 生成cost矩阵:3个目标框和1000个预测框,因此维度为3×1000。cost= reg loss+cls loss
- dynamic_k_estimation:每个GT提供多少个正样本才能使得网络更好收敛,获取与当前GT的IOU前10的样本,然后将这Top10样本的IOU求和取整,就是当前GT的dynamic_k。
- 为每个GT挑选相应cost最小的dynamic_k个样本作为正样本。
- 人工去掉同一个样本被分配到多个GT的正样本的情况(全局信息)
SimOTA流程:
- 粗筛选:确定正样本候选区域(将gt里面的点或者在center_radius范围内的点作为候选正样本点)。
- 计算每个样本对每个GT的 Reg+Cls loss (Loss aware)
- 使用每个GT的预测样本确定它需要分配到的正样本数(Dynamic k),获取与当前GT的 iou前10的样本,然后将这Top10样本的 iou求和取整,就为当前GT的dynamic_k, dynamic_k最小保证为1,10这个数字并不敏感,在5-15之间几乎都没有影响。
- 为每个GT取 loss最小的前dynamic k个样本作为正样本
- 人工去掉同一个样本被分配到多个GT的正样本的情况(全局信息)
注:乍一看OTA和simOTA看不出区别,但是回到代码里面看OTA中求解出最优的正样本使用了Sinkhorn-Knopp算法(引入了背景提供负标签的思想);而simOTA中划分正样本没有用到这个算法,只是用了贪心算法求出cost。
SimOTA优点:①能够做到自动的分析每个gt要拥有多少个正样本;②能自动决定每个gt要从哪个特征图来检测;③相较OTA,simOTA更快且避免了额外的超参数。
2.4、端到端实现策略(最终的模型没有使用)
增加的策略有:
- 增加两个卷积层
- one-to-one标签分配
- stop-gredient策略
造成的影响是:
- 优点:检测器实现端到端
- 缺点:性能下降,推理速度减慢
参考《object detection made simpler by eliminating heuristic nms》中NMS-free以及end-to-end思想
这个PSS是正样本选择器,作为一个单独的分支来辅助完成为每个object挑选最优正样本的工作。
具体来讲该论文引入的策略有:
- PSS头的one-to-one标签分配
- stop-gradient解耦classification和PSS头:解决从one-to-many到one-to-one时的样本混淆矛盾(GT在one-to-many有K个正样本而在one-to-one只有一个正样本,因此要把其余K-1个样本置为负样本,因此本文会出现多个样本同时被当做正样本和负样本的情况)
总体LOSS计算: L = L f cos + λ 1 ⋅ L p s s + λ 2 ⋅ L r a n k \mathcal{L}=\mathcal{L}_{f \cos }+\lambda_{1} \cdot \mathcal{L}_{p s s}+\lambda_{2} \cdot \mathcal{L}_{r a n k} L=Lfcos+λ1⋅Lpss+λ2⋅Lrank

2.5、整体结构梳理
输入端:RandomHorizontalFlip、ColorJitter、多尺度增强、Mosaic,Mixup
Backbone:CSPDarknet53
Neck:PAFPN
Head:主要亮点是采用Decoupled Head、Anchor-free、Multi positives,simOTA
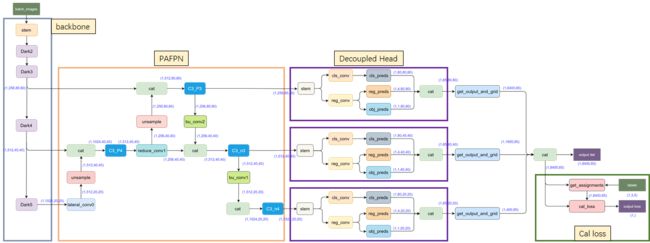
LOSS计算: loss = λ ⋅ loss r e g + loss o b j + loss c l s + loss l l \operatorname{loss}=\lambda \cdot \operatorname{loss}_{\mathrm{reg}}+\operatorname{loss}_{\mathrm{obj}}+\operatorname{loss}_{\mathrm{cls}}+\operatorname{loss}_{\mathrm{ll}} loss=λ⋅lossreg+lossobj+losscls+lossll
3、论文总结
本文贡献:
①在YOLO系列上改为ancho-free模型并采用解耦头预测
②采用SimOTA标签分配策略提高了速度及精度
③消融实验结果表明数据增强方法的使用也需要看具体的模型大小的

十三、YOLOR
1、论文简介
论文名称:《You Only Learn One Representation: Unified Network for Multiple Tasks》
论文链接:yolor
论文实现:[yolor实现](https:// github.com/ WongKinYiu/ yolor)
摘要:人类经验可以通过显性知识或潜意识(隐性知识)学习得到。本文提出一个统一网络,将隐性知识和显性知识编码在一起,这个网络可以生成统一的表达来同时服务于各种任务。在CNN中可以利用核空间对齐、预测精细化和多任务学习。研究表明在CNN中阴性知识有助于提高任务的性能,进一步分析从统一网络中学习到的隐形表征,在捕获不同任务的物理意义方面表现出了良好的能力。
问题:CNN提出的特征一般只能实现一个目标,不适用于其他类型的问题。
原因:只从神经元提取特征,没有使用CNN中丰富的隐形知识,因隐形知识可以帮助大脑(神经网络)处理各种任务。
CNN中知识的定义:
- 显性知识:从浅层获得的特征
- 隐性知识:从深层获得的特征
本文对知识的定义:
- 显性知识:直接能观察到的知识
- 隐性知识:模型观察不到或与观察无关的知识
解决:提出统一网络融合显性知识和阴性知识,确保模型包含一个统一的representation,这个统一的表征允许子表征也适用于其他任务。上述统一网络的构建是压缩感知和深度学习的结合。

2、论文结构
2.1、隐式知识的学习
a、流型空间约简
b、核空间对齐
若空间没有对齐,那么对输出特征和隐式表征进行加法和乘法运算,这样就可以对核空间进行变换、旋转和缩放,以此来对齐核空间。
应用:FPN大目标和小目标的特征对齐,知识蒸馏大模型和小模型的整合。
c、更多功能

提炼偏移量、提炼anchor超参数集、点乘特征选择
、论文总结
本文贡献:
- 提出一个能将显性知识和阴性知识结合起来的统一网络,学习一种可以完成各种任务的同一表征。该网络在增加了不到千分之一成本的条件上提高了模型的性能。
- 将核空间对齐、预测精细化和多任务学习引入到阴性知识学习过程中。
- 分别利用向量、矩阵、神经网络、矩阵分解作为隐形知识建模的工具。
- 提出的隐形表征学习方法能够准确地对应特定物理特征,并且以一种视觉的方式呈现出来。
- 结合SOTA模型,提出的模型与Scaled-YOLOv4-P7一样且速度提高了88%。
十四、NanoDet&NanoDet plus
NanoDet详解:https://zhuanlan.zhihu.com/p/306530300
NanoDet plus详解:https://zhuanlan.zhihu.com/p/449912627
NanoDet源码及部署:https://github.com/RangiLyu/nanodet
1、NanoDet简介
问题1:FCOS使用共享权重检测头为减少参数量,共享权重头对于轻量化模型来说有以下缺点:
- 移动端推理使用CPU计算,共享权重并不会对推理过程加速
- 检测头轻量的情况下,共享权重使得检测能力会进一步下降
解决1:共享权重头没有很大意义,还是选择每一层特征使用一组卷积。
问题2:FCOS使用GN归一化,GN虽较BN优点更多,但缺点是BN推理能够将其归一化的参数直接融合进卷积中,可省去此步计算,但GN不行。
解决2:将GN替换为BN
问题3:FCOS检测头使用4个256通道卷积作为一个分支,因此边框回归和分类这两个分支一共有8个256通道的卷积,计算量太大。
解决3:
- 深度可分离卷积替换普通卷积(深度可分离卷积:https://zhuanlan.zhihu.com/p/92134485)
- 卷积堆叠数量从4个减少为2组
- 通道数256压缩为96(为享受大部分推理框架的并行加速)
- 边框回归和分类使用同一组卷积计算,然后分成两份。
问题4:FCOS中centerness分支难以训练,且难以收敛
解决4:Generalized Focal Loss
1.1、NanoDet结构
a、backbone
shuffleNetV2,去掉最后一层卷积,抽取8、16、32倍下采样特征输入PAN做多尺度特征融合。使用torchvision的预训练权重
b、Neck:改进PAFPN
- 去掉PAFPN中所有卷积,只保留从Backbone特征提取后的1×1卷积来进行特征通道维度对齐
- 上采样和下采样都使用插值
- 多尺度不使用concatenate拼接,而是将得到的多尺度的特征图相加。

c、head

d、Gfocal loss
讲解参见:https://zhuanlan.zhihu.com/p/147691786
1、Focal loss支持0或1这样的离散类别的label,但是对于cls-obj联合表示,label是一个0~1之间的连续值。因此要使得新的focal loss具有以下特性:
- 能够平衡正负、难易样本
- 支持连续数值的监督
初始Focal Loss表达式: F L ( p ) = − ( 1 − p t ) γ log ( p t ) , p t = { p , when y = 1 1 − p , when y = 0 \mathbf{F L}(p)=-\left(1-p_{t}\right)^{\gamma} \log \left(p_{t}\right), p_{t}=\left\{\begin{aligned} p, & \text { when } y=1 \\ 1-p, & \text { when } y=0 \end{aligned}\right. FL(p)=−(1−pt)γlog(pt),pt={p,1−p, when y=1 when y=0
引出Quality Focal Loss: Q F L ( σ ) = − ∣ y − σ ∣ β ( ( 1 − y ) log ( 1 − σ ) + y log ( σ ) ) \mathbf{Q F L}(\sigma)=-|y-\sigma|^{\beta}((1-y) \log (1-\sigma)+y \log (\sigma)) QFL(σ)=−∣y−σ∣β((1−y)log(1−σ)+ylog(σ))
y为0~1的obj预测, σ \sigma σ为预测
2、用任意分布来建模框的表示,如果这个分布过于任意,网络学习效率可能会不高,原因是一个积分目标可能对应了无穷多种分布模式。因为真实的分布通常不会距离标注的位置太远。希望新的Focal loss具有以下特性:
- 网络能够快速聚焦到标注位置附近的数值,使得它们的概率尽可能大
引入Distribution Focal Loss: D F L ( S i , S i + 1 ) = − ( ( y i + 1 − y ) log ( S i ) + ( y − y i ) log ( S i + 1 ) ) \mathbf{D F L}\left(\mathcal{S}_{i}, \mathcal{S}_{i+1}\right)=-\left(\left(y_{i+1}-y\right) \log \left(\mathcal{S}_{i}\right)+\left(y-y_{i}\right) \log \left(\mathcal{S}_{i+1}\right)\right) DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))
解释该loss:以类似交叉熵的形式去优化与标签y最接近的一左一右两个位置的概率,从而让网络能够快速的聚集到目标位置的邻近区域的分布中去。
3、将QFL和DFL统一表示为Generalized Focal Loss: G F L ( p y l , p y r ) = − ∣ y − ( y l p y t + y r p y r ) ∣ β ( ( y r − y ) log ( p y t ) + ( y − y l ) log ( p y r ) ) \mathbf{G F L}\left(p_{y_{l}}, p_{y_{r}}\right)=-\left|y-\left(y_{l} p_{y_{t}}+y_{r} p_{y_{r}}\right)\right|^{\beta}\left(\left(y_{r}-y\right) \log \left(p_{y_{t}}\right)+\left(y-y_{l}\right) \log \left(p_{y_{r}}\right)\right) GFL(pyl,pyr)=−∣y−(ylpyt+yrpyr)∣β((yr−y)log(pyt)+(y−yl)log(pyr))
e、标签匹配
ATSS:虽然会根据IOU的均值和方差为每一层feature map动态选取匹配样本,但其本质上依然是基于先验信息(中心点和anchor)的静态匹配策略。
2、NanoDet-Plus简介

2.1、NanoDet-Plus结构
a、backbone
无改进,继续使用shuffleNetV2
b、Neck:Ghost-PAN
问题:NanoDet中使用的无卷积PAFPN太影响多尺度的特征融合效果了。
提出:Ghost-PAN,使用GhostNet中的GhostBlock作为处理多层之间特征融合的模块,基本结构单元由一组1×1卷积和3×3的depthwise卷积组成,计算量小。

c、head
背景:ThunderNet提出轻量级模型将深度可分离卷积的depthwise部分从3×改成5×5能够在增加较少的参数量的情况下提升检测器的感受野并提升性能。
提出:
- NanoDet-Plus也将检测头的depthwise卷积的卷积核大小也改成了5x5
- 在NanoDet的三层特征基础上增加一层下采样特征
d、标签匹配策略
动态匹配在小模型上的问题:检测头只是用两个深度可分离卷积同时预测分类和回归,而大模型都是对于分类和回归分别使用4组3×3的通道数为256的卷积层来预测,让如此简约的监测头从随机初始化状态去计算Matching Cost做匹配太牵强了!
解决方案1:可以用学习能力更强的网络去引导小模型的检测头进行匹配,想到了知识蒸馏,根据LAD所做,但是还需要训练教师网络,那么训练需要的资源就增加了。
解决方案2:根据IQDET设计了一种更简单更轻量的**训练辅助模块Assign Guidance Module(AGM)并配合动态的软标签分配策略Dynamic Soft Label Assigner(DSLA)**解决了轻量级模型中的最优标签匹配问题。
e、训练策略调整
- 优化器:SGD+momentum→AdamW
- 学习率下降策略:MultiStepLr→CosineAnnealingLR
- 反向传播计算梯度:加入梯度裁剪
- 模型平滑EMA策略
f、部署优化调整
NanoDet的head输出是多尺度(3个)的两种输出(分类、回归),总共有6个输出。
NanoDet-Plus的head输出经之前的输出reshape为相同的再concatenate。
优点:对模型结构理解不清晰的新手较友好
缺点:增加了操作量,略微影响模型后处理速度。


十五、Yolov7
1、论文简介
论文名称:《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》
论文链接:yolov7
论文源码:yolov7实现
摘要:YOLOv7在5~160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时物体检测器中具有最高的准确度 56.8% AP。 YOLOv7-E6 目标检测器(56 FPS V100,55.9% AP)比基于transformer的检测器 SWIN-L Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出 509% 和 2%,以及基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高 551%,准确率提高 0.7%。YOLOv7 的表现优于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR , DINO-5scale-R50, ViT-Adapter-B 和许多其他物体探测器在速度和准确度上。 此外,我们只在 MS COCO 数据集上从头开始训练 YOLOv7,而不使用任何其他数据集或预训练的权重。
动机:结构优化和训练步骤的优化
策略:加大训练损耗以提升准确率,不增加推理时间。本文优化方法称为可训练bag-of-freebies。
问题:在模型重参数化和动态标签分配提出后,训练OD有着许多的问题。
解决措施:
①对于模型结构重参化,用梯度传播路径的概念分析了适用于不同网络中各层结构重参化策略,提出了规划重参化模型。
②当使用动态标签分配策略时,多输出层的模型在训练时会产生新的问题,比如怎样才能为不同分支更好的输出分配动态目标,针对这个问题提出了引导标签分配策略。
关注点:使用提出的bag-of-freebies解决如下
①SOTA检测器的鲁棒loss函数问题
②SOTA检测器的标签分配方法
③SOTA检测器的训练方法
2、yolov5~yolov7中一些脱节的概念
2.1、模型重参数化
模型重参数化概念:在推理阶段将多个模块合并为一个计算模块,可看做一种集成技术,分为模块级集成和模型级集成。在训练过程中将一个整体模块分割为多个相同或不同的模块分支,但在推理过程中将多个分支集成到一个完全等价的模块中。
参数与重参数化概念:https://zhuanlan.zhihu.com/p/361090497
清华大学丁霄汉讲解ACNet重参数化:https://blog.csdn.net/duxinshuxiaobian/article/details/107873144
重参数化的应用:增强模型性能,改变模型结构(剪枝),NAS


模型级重参数化有两种操作:
- 用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。
- 对不同迭代次数下模型权重进行加权平均。
重参数化遇到的问题:不是所有提出的重参数化模块都可以完美应用于不同架构。
本文如何解决:提出新的重参数化模块,并为各种架构设计了相关的应用程序策略。

2.2、模型缩放
模型缩放通过扩大或缩小baseline,使其适用于不同的计算设备。模型缩放方法通常包括不同的缩放因子:输入图像大小、层数(depth)、通道数(width)、特征金字塔数量,从而在网络的参数量、计算量、推理速度和精度方面实现很好的权衡。
模型压缩的方法有:剪枝、量化、低秩逼近、知识蒸馏、NAS。
具体解释:https://blog.csdn.net/weixin_39653948/article/details/109244853
这几种压缩方法的特点及对比:https://blog.csdn.net/deephub/article/details/107424974
①剪枝:包括从训练好的网络中移除神经元或整个神经元、通道或卷积核之间的连接,这是通过将权重矩阵中的值清零或完全移除权重组来完成的。
②量化:通过减少权重的大小来压缩模型。量化通常是将大集合中的值映射到小集合中的值的过程,这意味着输出包含的可能值范围比输入小,理想情况下在该过程中不会丢失太多信息。
③低秩近似:由于深层神经网络往往参数化过度,不同层或通道之间存在许多相似性或冗余性,低秩近似的目标是使用较少卷积核的线性组合来近似一个层的大量冗余滤波器,以这种方式压缩层减少了网络的内存占用以及卷积运算的计算复杂性,并且可以产生显著的加速。
④知识蒸馏:将知识从一个大型的训练模型或模型集合转移到一个较小的模型中,方法是训练小模型来模拟较大模型的输出。简而言之它的动机在于训练和推理是不同的任务,因此应该为每个任务使用不同的模型。
⑤以上的压缩技术可以应用于给定的场景,当考虑到它们的组合时,可以探索的可能架构的数量会增加很多。然而这个难点就在于怎么选择最优的,这就是NAS的由来。NAS是对定义神经网络不同组成部分的一组决策的搜索,这是一种学习最佳模型架构的系统化、自动化的方法。这个想法是为了消除过程中的人为偏见,以达到比人类设计的更好的新架构。
模型压缩的背景:因为yolov7中应用的架构是级联的。
3、结构设计
3.1、聚合网络
高效网络的设计需要考虑的因素:参数量、计算量、计算密度,输入/输出信道比,架构分支数和元素级操作对网络推理速度的影响。执行模型压缩时还需考虑激活函数,即更多考虑卷积层输出张量中的元素数量。

ELAN是针对高效网络做出的设计,得出结论为:通过控制最短最长梯度路径,更深的网络可以有效地进行学习并更好地收敛。
大规模ELAN特点:无论梯度路径长度和计算模块堆叠数量如何,都能达到稳定的状态。但若是计算模块被无限堆叠,这种稳定状态会被破坏,参数利用率会降低。
解决大规模ELAN上述问题的方法:本文提出了E-ELAN,采用expand、shuffle、merge cardinality结构,实现在不破坏原始梯度路径的情况下,提高网络的学习能力。
E-ELAN策略:
- 架构方面:只改变计算块的架构,完全不改变过渡层架构。
- expand结构:使用组卷积expand计算块的通道数和基数,对计算层所有计算块应用相同的组参数和通道乘子。
- shuffle结构:每个计算块得到的特征图根据设置的组参数g被shuffle进g个组然后做concatenate。(这时每组特征图的通道数就等于初始架构的通道数了)
- merge cardinality结构:添加g组特征图来执行merge cardinality操作。
- 维持原始ELAN架构,且能引导不同组的计算块去学习更多样化的特征。
3.2、模型缩放
目的:调整模型的部分属性并产生不同规格的模型(tiny, s, m, l, x)以达到不同的推理速度。
考虑的因素:层数、通道数、分辨率、特征金字塔层数。
模型缩放存在的问题:若缩放是在PlainNet和ResNet上进行时,每一层的输入输出通道数不改变,这时还能独立分析每个缩放因子对于参数量和计算量的影响。但如果缩放方法应用到基于级联的架构中,若对depth进行放大/缩小,跟在基于级联的计算块之后的传输层的输入通道就会增多/减少。
解决方法:分析缩放因子只能一起考虑。当缩放一个计算块的depth因子时,还要计算出这个计算块的输出通道的变化,然后对其余的传输层做等量的width因子缩放,使得所有的传输层width对齐可以concatenate。此结构可以保持模型在初始设计时的特性并保持最优结构。

4、可训练策略
-
RepConv恒等连接会破坏ResNet残差结构和DenseNet的跨层连接,因此本文使用不带有恒等连接RepConvN构造了一种新的重参数化卷积,但本文原始和新的重参数化卷积都使用了。使用原则是只要带有残差连接或者级联的卷积层被重参数化卷积层取代,那么就不应该有恒等连接。

RepVGG中的RepConv的两种结构:
①第一种结构:在网络的初始阶段,仅包含conv1×1残差分支。
②第二种结构:在网络的较深阶段,包含conv1×1残差分支以及恒等残差结构,恒等分支可视为1×1卷积。这样复杂的残差结构使得网络在深层可以获得更加鲁棒的特征表示,更好地处理网络深层的梯度消失问题。


- 深度监督策略:加入辅助头,最后将辅助头和引导头(输出头)的权重做融合。
- 软标签分配策略:以引导头为主,通过引导头的预测来指引辅助头和自身的学习。即首先使用引导头的预测作为指导并生成由粗到细的层次标签,分别用于引导头和辅助头的学习。
label assigner:同时考虑网络的预测结果和GT再分配软标签的机制。
Lead head guided label assigner:主要由预测结果和GT进行计算,并通过优化函数生成软标签。这组软标签将作为辅助头和引导头的目标来训练模型,这样做的目的是使引导头具有较强的学习能力,由此产生的软标签更能代表源数据与目标之间的分布差异和相关性。特点是通过让较浅的辅助头直接学习引导头已经学习到的信息,引导头能更加专注于尚未学习到的残余信息。
Coarse-to-fine lead head guided label assigner: Coarse-to-fine引导头使用到了自身的预测和GT来生成软标签,引导标签进行分配。但此过程产生了两种软标签:粗标签和细标签,细标签与上面相同,粗标签是通过降低正样本分配的约束,允许GT中心点附近的网格作为正样本。这样做的原因是一个辅助头的学习能力没有引导头强,为避免需要学习的信息丢失,要提高辅助头的recall;对于引导头的输出,可以从precision中过滤出过滤出高精度值的结果作为最终输出。因超粗标签会产生错误的先验,因此为使得超粗正样本影响更小,在解码器中设置了限制。

-
BN层直接连到卷积层中,以方便在推理时将BN的均值和方差直接融合到卷积层的权重和偏差中。
-
应用YOLOR隐形知识与特征图相结合的加法和乘法方式:隐式知识可通过在推理阶段的预计算简化为向量,以便和卷积层做权重和偏差的融合(即重参数化推理阶段过程)
-
EMA模型:一个应用于mean teacher的技术,只在最后推理模型中使用。
mean teacher流程:
①构建一个普通的监督模型
②将监督模型copy,原模型叫student,另一个叫teacher
③每个训练步中,使用同样的minibatch输入到student与teacher模型中,但在输入数据前分别加入随机增强或者噪音
④加入student与teacher输出的一致性损失函数
⑤优化器只更新student的权重
⑥每个训练步之后,采用student权重的EMA更新teacher权重。
EMA(指数滑动平均):用公式表示为 M = ( 1 − λ ) M ′ + λ M M=(1-\lambda) M^{\prime}+\lambda M M=(1−λ)M′+λM,M是已得量,M`是当前迭代下得到的量, λ \lambda λ是动量系数。
EMA的应用:①带有动量的SGD优化器;②Pseudo label将模型输出的EMA作为伪标签;③mean teacher中将EMA模型的输出作为伪标签,而不是模型输出的EMA作为伪标签;④动量网络=mean teacher

5、 论文总结
本文贡献:
①使得YOLO实时检测器可以在不提高推理成本的情况下大大提高检测精度;
②提出E-ELAN模块解决了大规模ELAN因无限堆叠出现的问题,提出了“扩展”和“复合”的缩放方法,可以更加高效地利用参数和计算量;
③提出基于级联架构的模型缩放新策略;
④模型重参数化替代原始模块中提出了新的RepConvN,,解决了原始RepConv与ResNet恒等连接之间的矛盾问题。
⑤动态标签分配策略上,本文提出以引导头为主、辅助头为辅的策略,由引导头的预测作为指导生成由粗到细的标签来指导引导头和辅助头的学习,最后融合引导头和辅助头的权重。
⑥本文提出的方法可以有效地减少现有SOTA实时检测器40%的参数和50%的计算量,并且具备更快的推理速度和更高的检测精度。
引用
[1] 1.2 YOLO入门教程:YOLOv1(2)-浅析YOLOv1
[2] SSD论文解读
[3] 【论文精读】Focal Loss for Dense Object Detection(RetinaNet)全文翻译及重点总结
[4] 2.1 YOLO入门教程:YOLOv2(1)-解读YOLOv2
[5] 3.1 YOLO入门教程:YOLOv3(1)-解读YOLOv3
[6] 深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
[7] Bag of Freebies(免费包)和Bag-of-Specials(特赠包)
[8] 锚框:Anchor box综述 - 知乎 (zhihu.com)
[9] 【Anchor free】CornerNet 网络结构深度解析(全网最详细!) - 知乎 (zhihu.com)
[10] 【Anchor Free】CenterNet的详细解析 - 知乎 (zhihu.com)
[11] CenterNet: Keypoint Triplets for Object Detection_Wanderer001的博客-CSDN博客
[12] 文章解析:FCOS: Fully Convolutional One-Stage Object Detection | by zong fan | Medium
[13] YOLOX原始论文精读_钟良堂的博客-CSDN博客_yolox论文
[14] YOLOX深度解析(二)-simOTA详解 - 知乎 (zhihu.com)
[15] 目标检测: 一文读懂 YOLOX
[16] NanoDet
[17] NanoDet-Plus
总结
基于anchor的检测器:yolov2, yolov3, yolov4, yolov5, yolov7, SSD, RetinaNet, YOLOF, YOLOR
anchor-free检测器:yolov1, YOLOX, CornerNet, CenterNet, CenterNet++, FCOS, NanoDet, NanoDet-Plus
| 检测器 | anchor-based(0) or anchor-free(1) | one-stage(0) or two stage(1) |
|---|---|---|
| yolov1 | 1 | 0 |
| yolov2 | 0 | 0 |
| yolov3 | 0 | 0 |
| yolov4 | 0 | 0 |
| yolov5 | 0 | 0 |
| yolov7 | 0 | 0 |
| SSD | 0 | 0 |
| RetinaNet | 0 | 0 |
| YoloF | 0 | 0 |
| YoloR | 0 | 0 |
| YoloX | 1 | 0 |
| CornerNet | 1 | 0 |
| CenterNet | 1 | 0 |
| CenterNet++ | 1 | 0 |
| FCOS | 1 | 0 |
| NanoDet | 1 | 0 |
| NanoDet-Plus | 1 | 0 |
| RCNN | 0 | 1 |
| Fast-RCNN | 0 | 1 |
| Faster-RCNN | 0 | 1 |
| RFCN | 0 | 1 |
| Light-Haed RCNN | 0 | 1 |
| Cascade RCNN | 0 | 1 |
| Mask RCNN | 0 | 1 |