Kettle基本使用(七) —— 脚本 & 作业 & 参数 的使用
一、脚本
01.执行SQL脚本_插入
insert into


02.执行SQL脚本_删除
delete


03.执行SQL脚本_更新
update



04.执行SQL脚本_查询
‘select


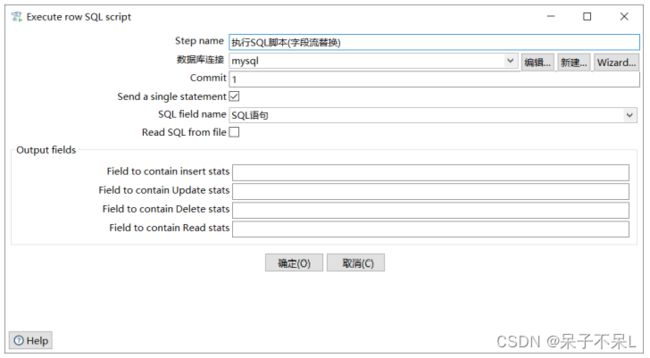
05.执行SQL脚本_字段流替换
执行SQL脚本(字段流替换):执行字段中的每行SQL语句
可执行的SQL语句:CREATE、ALTER、DROP、INSERT、UPDATE、DELETE等
也可执行SELECT语句,但不会返回查询结果,所以没有意义



06.公式
公式:通过计算公式新增字段
必须定义新字段的数据类型,否则报错
字段使用[]中括号引用,参数之间使用;分号分隔
金额:[数量] * [价格]
产品大类:mid([产品信息]; 1; find("-"; [产品信息]; 1) - 1)
产品小类:mid([产品信息]; find("-"; [产品信息]; 1)+1; len([产品信息]))
退货数量:IF(ISBLANK([退货日期]); 0; [数量])
处理前:

处理后:





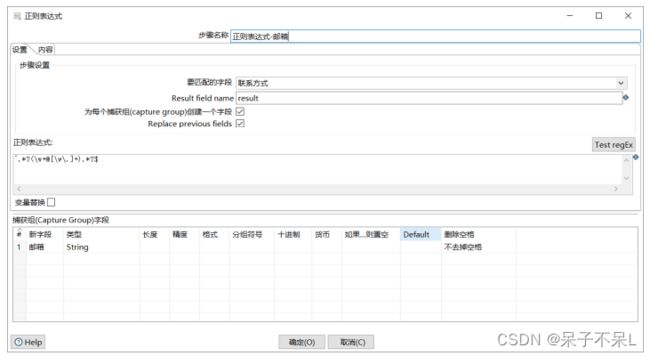
07.正则表达式
正则表达式:通过正则表达式新增字段
必须定义新字段的数据类型,否则报错
电话:^.*(\d{11}).*$
邮箱:^.*?(\w+@[\w.]+).*?$
处理前:

处理后:




二、作业
作业
并行与串行:
转换:并行执行;同一时刻执行多个操作
作业:串行执行;按顺序执行多个操作,同一时刻只能执行一个操作,上一步操作执行完成后再执行下 一步操作
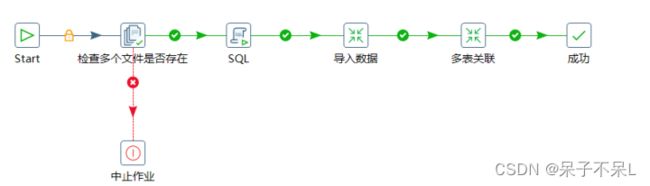
作业项:作业的基本构成部分,以图表形式展示,如检查多个文件是否存在、SQL、导入数据、多表关联等
上一个作业项执行完成后再执行下一个作业项
作业跳:作业项之间的连接线,决定作业的执行路径
执行路径:
上一个作业项无论是否执行成功,下一个作业项都会执行,带锁的蓝色连接线
当上一个作业项的执行结果为真时,执行下一个作业项,带钩的绿色连接线
当上一个作业项的执行结果为假时,执行下一个作业项,带叉的红色连接线
案例场景:检查多个文件是否存在(order、product、region),如不存在则中止作业,如存在则执行SQL
脚本建表(order、product、region、total),建表执行成功后,将本地多个文件导入数据库,导入数据执行成功后,再执行SQL查询语句,并将查询结果插入至total表,最后作业完成。
通用 -> 作业:作业中再运行另一个作业
通用 -> Dummy:空节点,用于占位,类似于python的pass


SQL脚本(SQL文件)
执行SQL脚本创建表
create table if not exists kettle.order (
order_id text,
product_id bigint,
region_id bigint,
order_date date,
quantity int,
price double
);
create table if not exists kettle.product (
product_id bigint,
product_name text,
category text,
subclass text
);
create table if not exists kettle.region (
region_id bigint,
province text,
region text
);
create table if not exists kettle.total (
order_id text,
product_id bigint,
region_id bigint,
order_date date,
quantity int,
price double,
product_name text,
category text,
subclass text,
province text,
region text
);
导入数据(转换)
将本地数据文件导入至数据库指定表


多表关联(转换)
执行SQL查询语句,并将查询结果插入至指定表
select
o.*
, p.product_name
, p.category
, p.subclass
, r.province
, r.region
from kettle.order o
left join kettle.product p on p.product_id = o.product_id
left join kettle.region r on r.region_id = o.region_id


三、参数
01.全局参数
全局参数在整个kettle程序中均有效,配置全局参数后必须重启kettle才会生效
菜单栏 > 编辑 > 编辑kettle.properties文件
变量名:category,值:'自行车',变量名:region,值:'南区'
勾选替换SQL语句里的变量:%%region%% 或 ${category}



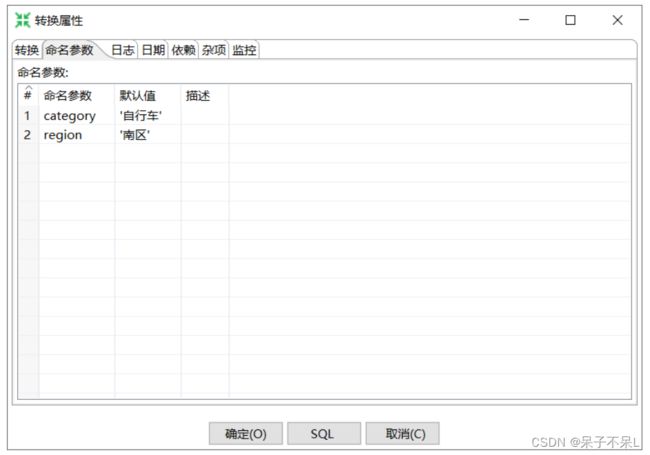
02.转换的命名参数
转换的命名参数为局部参数,局部参数仅在当前转换/作业中有效
空白的工作区 > 右键 > 转换设置 > 命名参数
命名参数:category,默认值:'自行车',命名参数:region,默认值:'南区'
勾选替换SQL语句里的变量:%%region%% 或 ${category}



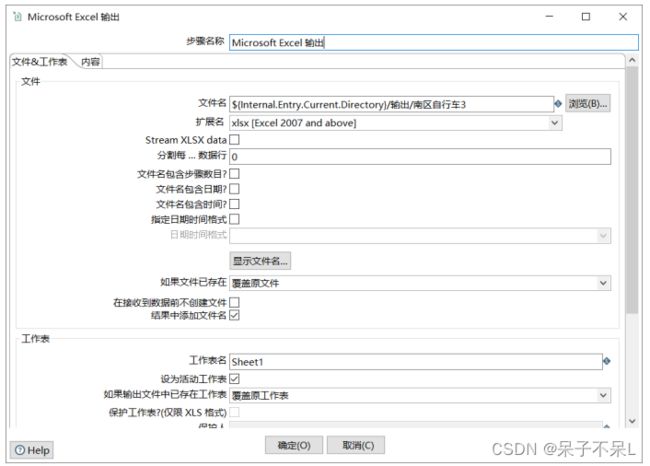
03.自定义常量数据传递参数
从上一步骤获取参数,如自定义常量数据
从步骤插入数据 > 自定义常量数据,不勾选替换SQL语句里的变量
常见的3种参数引用方式:
第1种:%%参数名称%%
第2种:${参数名称}
第3种(从上一步骤获取):?




04.设置变量与获取变量.kjb
转换程序 > 作业 > 设置变量
转换程序 > 作业 > 获取变量



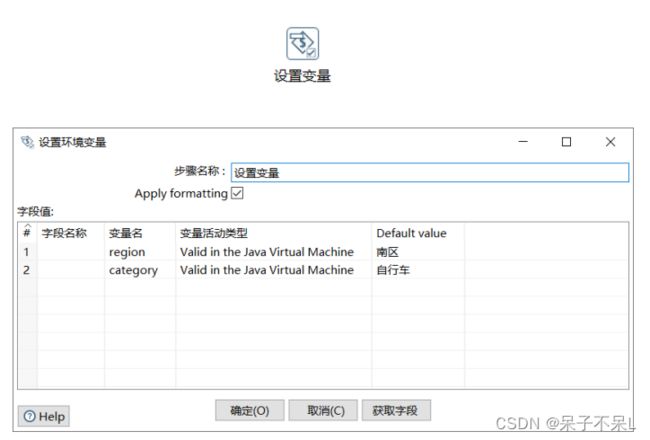
设置变量(转换)
转换程序 > 作业 > 设置变量
设置变量后不能在当前转换中马上使用,需要在作业的下一步骤使用
变量名:category,Default value:自行车,变量名:region,Default value:南区
注意:字符串无需引号!!!
变量活动类型:
Valid in the Java Virtual Machine:在Java虚拟机中有效(选择该项)
Valid in the parent job:在父作业中有效
Valid in the grand-parent job:在父级作业中有效
Valid in the root job:在根作业中有效
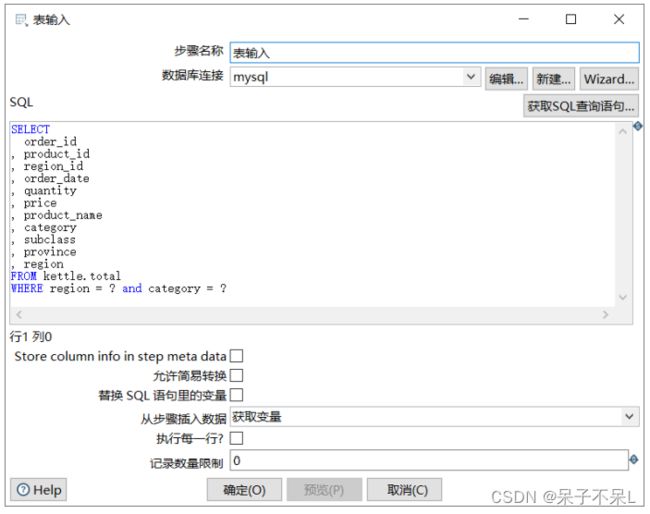
获取变量(转换)
转换程序 > 作业 > 获取变量
名称:value1,变量:${region},类型:String
名称:value2,变量:${category},类型:String
从步骤插入数据 > 获取变量,不勾选替换SQL语句里的变量
从上一步骤获取参数:?



05.作业的设置变量.kjb
作业程序 > 通用 > 设置变量
变量名:region,值:南区,变量名:category,值:自行车
注意:字符串无需引号!!!
变量有效范围:在JVM中有效(选择该项)、当前作业有效、在父作业中有效、在根作业中有效
获取变量:等同于《获取变量(转换)》


