Elasticsearch-索引、文档、查询DSL
Elasticsearch入门
Elasticsearch 的官方地址:https://www.elastic.co/cn/
Elasticsearch最新的版本是8.1.3,我们选择7.8.0版本
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
Elasticsearch分为Linux和Windows版本,基于我们主要学习的是Elasticsearch的Java客户端的使
用,所以使用的是安装较为简便的Windows版本。
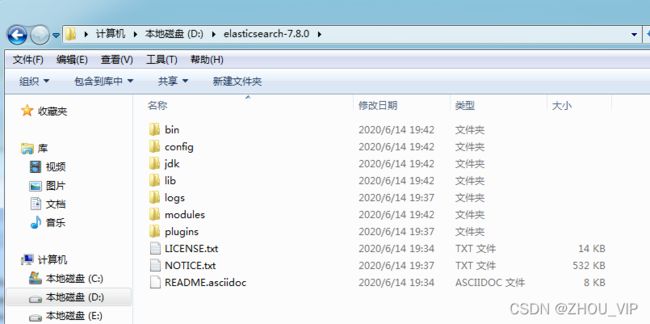
Windows版的Elasticsearch的安装很简单,解压即安装完毕,解压后的Elasticsearch的目录结构如
下

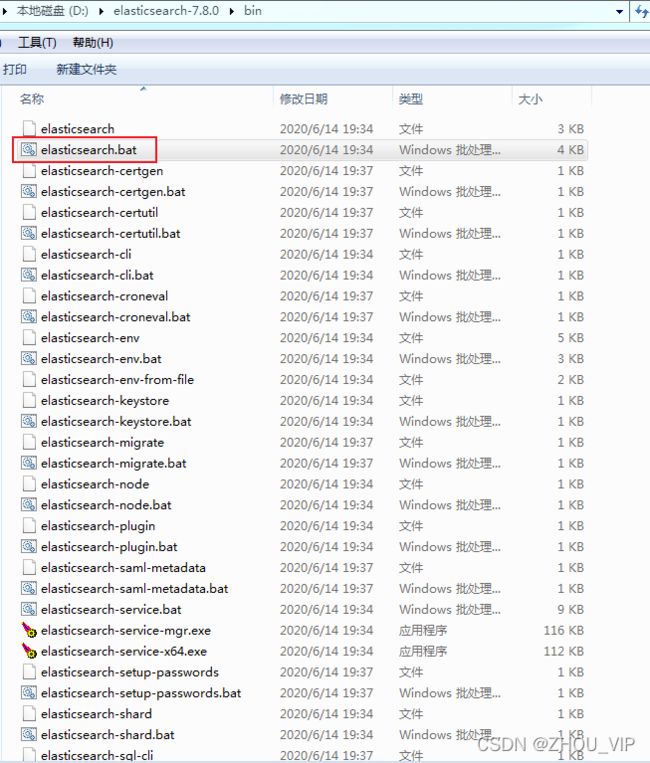
解压后,进入 bin文件目录,点击elasticsearch.bat文件启动ES服务

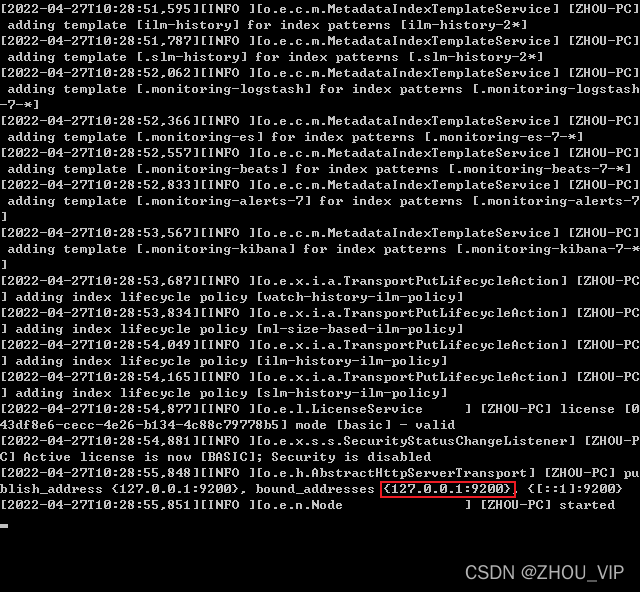
注意:9300端口为Elasticsearch集群间组件的通信端口,9200端口为浏览器访问的http协议
RESTful 端口。
打开浏览器(推荐使用谷歌浏览器),输入地址:http://localhost:9200,测试结果

附加说明:

Elasticsearch基本操作
数据格式
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档。为了方便大家理解,
我们将Elasticsearch里存储文档数据和关系型数据库MySQL存储数据的概念进行一个类比
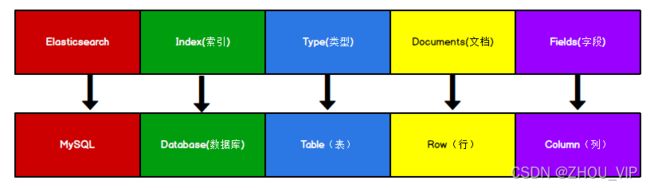 ES里的Index可以看做一个库,而Types相当于表,Documents 则相当于表的行。
ES里的Index可以看做一个库,而Types相当于表,Documents 则相当于表的行。
这里Types的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个
type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
注意:ES 7.x之后,type已经被淘汰了,其他的没变。只要玩ES,那么这个图就要牢牢地记在自
己脑海里,后续的名词解释不再过多说明,就是操作这幅图中的东西。
索引操作
1) 创建索引
对比关系型数据库,创建索引就等同于创建数据库
在Postman中,向ES服务器发PUT请求:http://127.0.0.1:9200/shopping

{
"acknowledged"【响应结果】: true, # true 操作成功
"shards_acknowledged"【分片结果】: true, # 分片操作成功
"index"【索引名称】: "shopping"
}
# 注意:创建索引库的分片数默认1片,在7.0.0之前的Elasticsearch版本中,默认5片如果重复添加索引,会返回错误信息

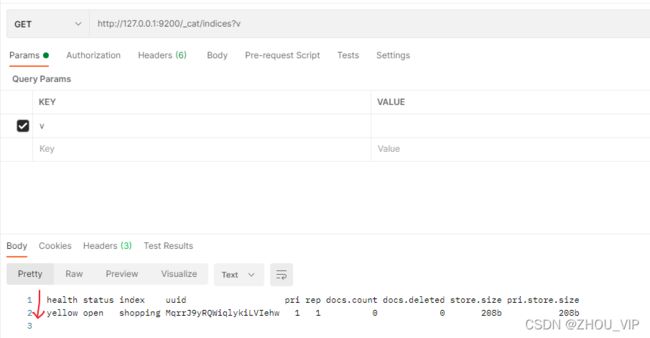
2) 查看所有索引
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/_cat/indices?v
这里请求路径中的_cat 表示查看的意思,indices表示索引,所以整体含义就是查看当前ES
服务器中的所有索引,就好像 MySQL 中的show tables的感觉
3) 查看单个索引
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/shopping
查看索引向 ES 服务器发送的请求路径和创建索引是一致的。但是 HTTP 方法不一致。这里
可以体会一下 RESTful 的意义。
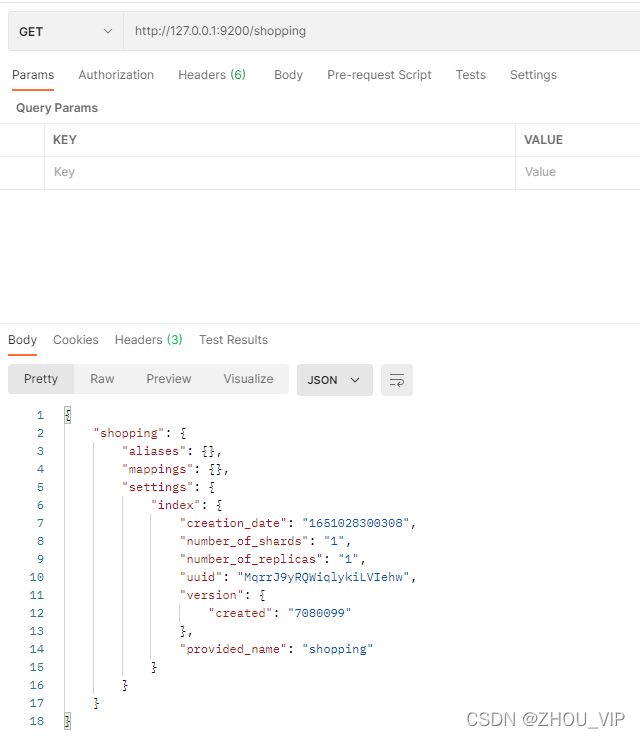
{
"shopping"【索引名】: {
"aliases"【别名】: {
},
"mappings"【映射】: {
},
"settings"【设置】: {
"index"【设置-索引】: {
"creation_date"【设置-索引-创建时间】: "1614265373911",
"number_of_shards"【设置-索引-主分片数量】: "1",
"number_of_replicas"【设置-索引-副分片数量】: "1",
"uuid"【设置-索引-唯一标识】: "eI5wemRERTumxGCc1bAk2A",
"version"【设置-索引-版本】: {
"created": "7080099"
},
"provided_name"【设置-索引-名称】: "shopping"
}
}
}
}4) 删除索引
在Postman中,向ES服务器发DELETE请求:http://127.0.0.1:9200/shopping
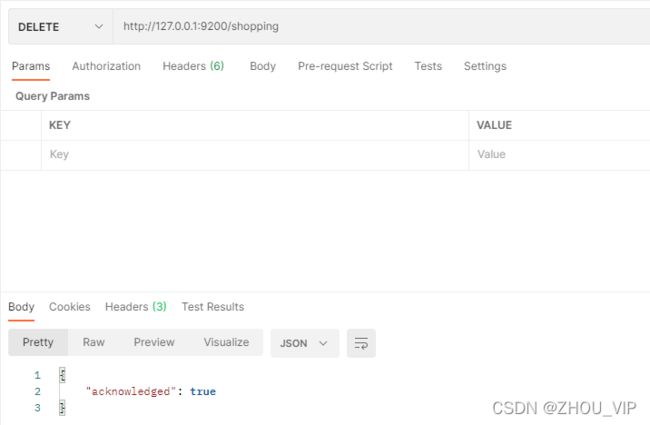
重新访问索引时,服务器返回响应:
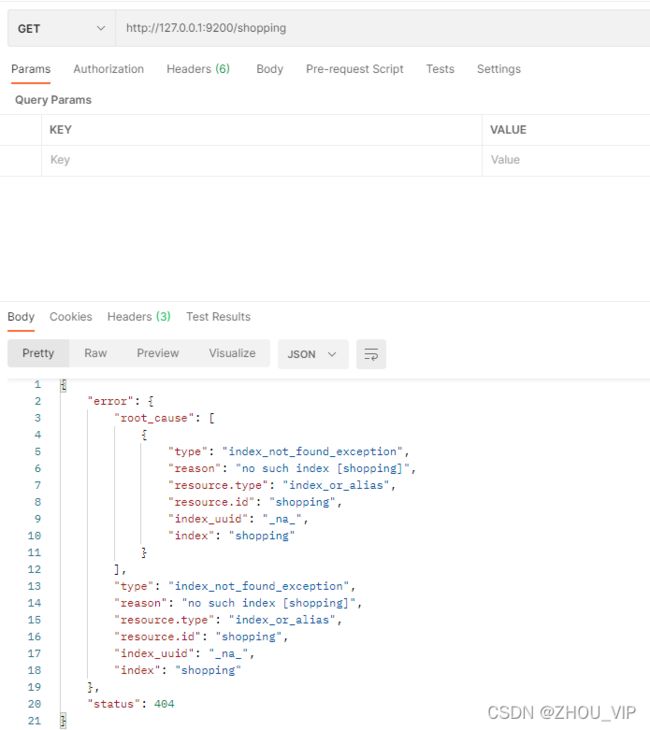
文档操作
1) 创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数
据库中的表数据,添加的数据格式为JSON格式
在Postman中,向ES服务器发POST请求:http://127.0.0.1:9200/shopping/phone
此处发送请求的方式必须为POST,不能是PUT,否则会发生错误


{
"_index"【索引】: "shopping",
"_type"【类型-文档】: "phone",
"_id"【唯一标识】: "Xhsa2ncBlvF_7lxyCE9G",#可以类比为MySQL中的主键,随机生成"_version"【版本】: 1,
"result"【结果】: "created",#这里的create表示创建成功
"_shards"【分片】: {
"total"【分片-总数】: 2,
"successful"【分片-成功】: 1,
"failed"【分片-失败】: 0
},
"_seq_no": 0,
"_primary_term": 1
}上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机
生成一个。
如果想要自定义唯一性标识,需要在创建时指定:http://127.0.0.1:9200/shopping/phone/1

此处需要注意:如果增加数据时明确数据主键,那么请求方式也可以为 PUT
2) 查看文档
查看文档时,需要指明文档的唯一性标识,类似于MySQL中数据的主键查询
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/shopping/phone/1

{
"_index"【索引】: "shopping",
"_type"【文档类型】: "phone",
"_id": "1",
"_version": 2,
"_seq_no": 2,
"_primary_term": 2,
"found"【查询结果】: true,#true表示查找到,false表示未查找到
"_source"【文档源信息】: {
"title": "小米手机",
"category": "小米",
"images": "http://www.xiaomi.com/xm.jpg",
"price": 3999.00
}
}3) 修改文档
和新增文档一样,输入相同的URL地址请求,如果请求体变化,会将原有的数据内容覆盖
在 Postman 中,向ES服务器发POST请求 :http://127.0.0.1:9200/shopping/phone/1
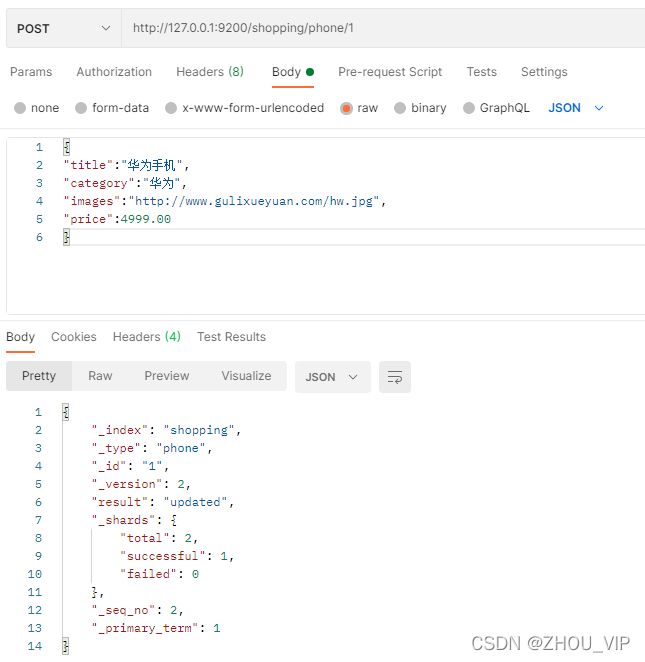
{
"_index": "shopping",
"_type": "phone",
"_id": "1",
"_version"【版本】: 2,
"result":【结果】 "updated",# updated 表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}查询修改结果
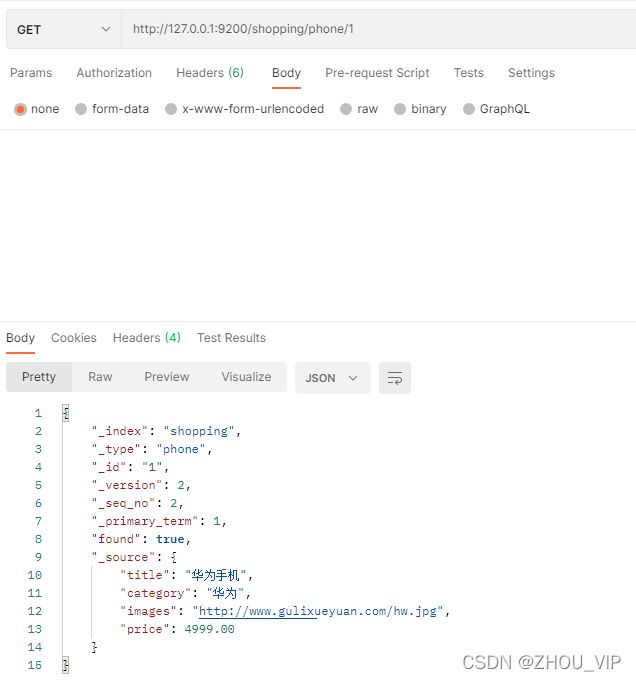
4) 修改字段
修改数据时,也可以只修改某一给条数据的局部信息
在Postman中,向ES服务器发POST请求 :http://127.0.0.1:9200/shopping/phone/1/_update
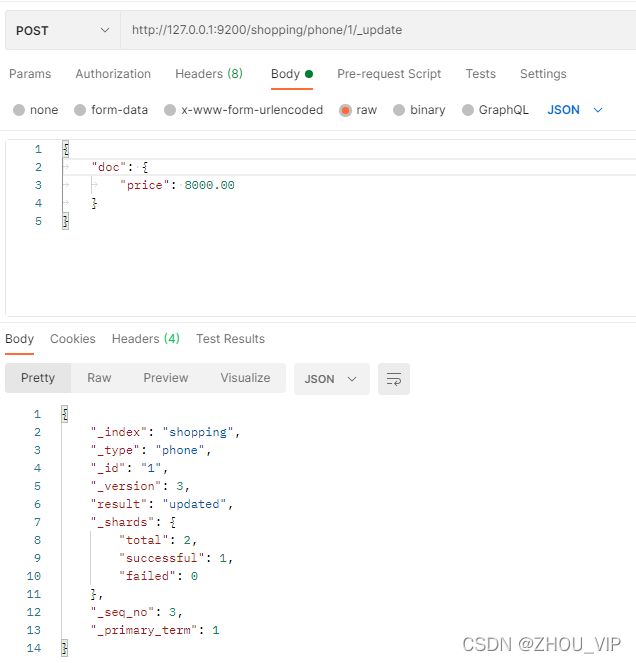
查询结果

5) 删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
在Postman中,向ES服务器发DELETE请求 :http://127.0.0.1:9200/shopping/phone/1

{
"_index": "shopping",
"_type": "phone",
"_id": "1",
"_version"【版本】: 4,#对数据的操作,都会更新版本
"result"【结果】: "deleted",# deleted 表示数据被标记为删除
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}删除后再查询当前文档信息

如果删除一个并不存在的文档
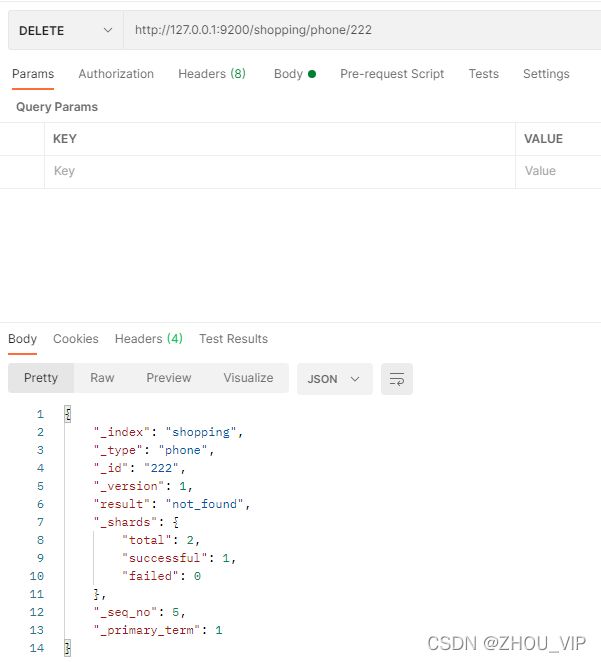
{
"_index": "shopping",
"_type": "phone",
"_id": "222",
"_version": 1,
"result"【结果】: "not_found",# not_found 表示未查找到
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1
}6) 条件删除文档
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数
据进行删除
首先分别增加多条数据
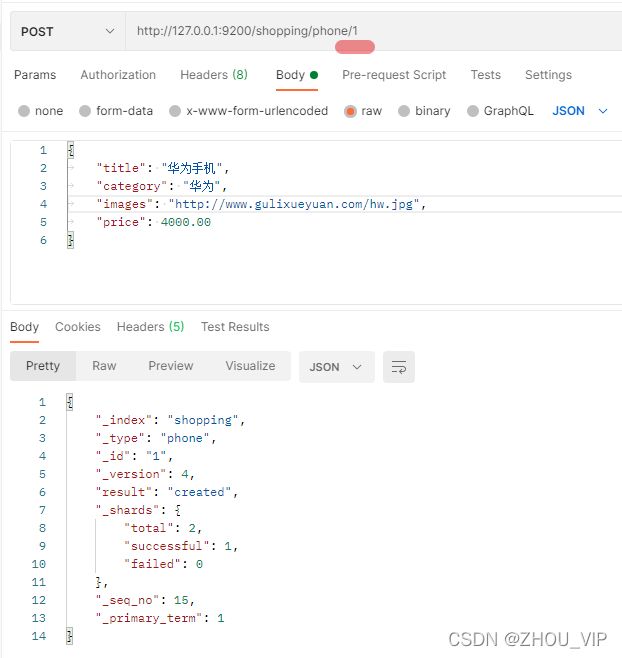
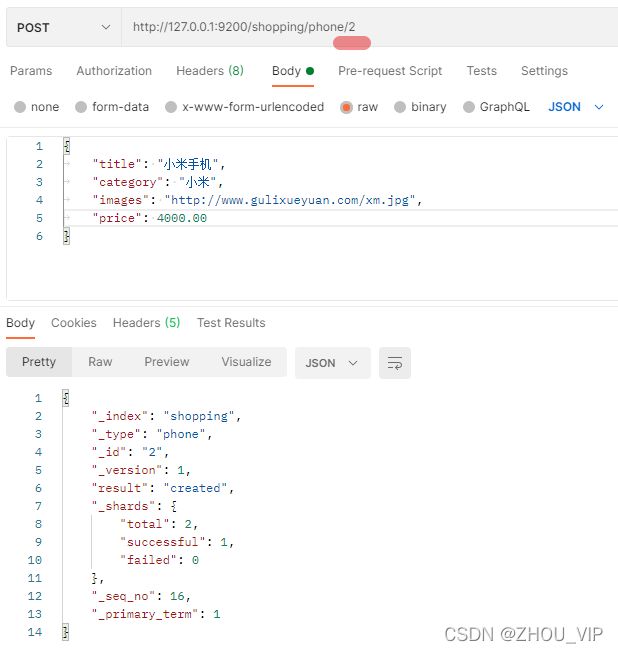
向ES服务器发POST请求:http://127.0.0.1:9200/shopping/_delete_by_query
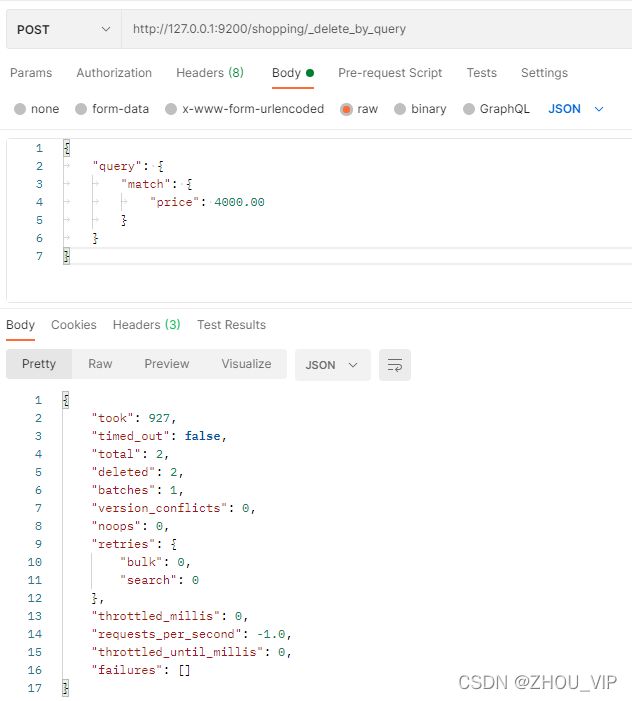
{
"took"【耗时】: 927,
"timed_out"【是否超时】: false,
"total"【总数】: 2,
"deleted"【删除数量】: 2,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1.0,
"throttled_until_millis": 0,
"failures": []
}映射操作
有了索引库,等于有了数据库中的 database
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型
下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
就相当于:在做mysql数据库中的表结构( 字段构建嘛:字段名、类型... )
1) 创建映射
在Postman中,向ES服务器发PUT请求:http://127.0.0.1:9200/student/_mapping
在创建映射前先创建student索引:http://127.0.0.1:9200/student
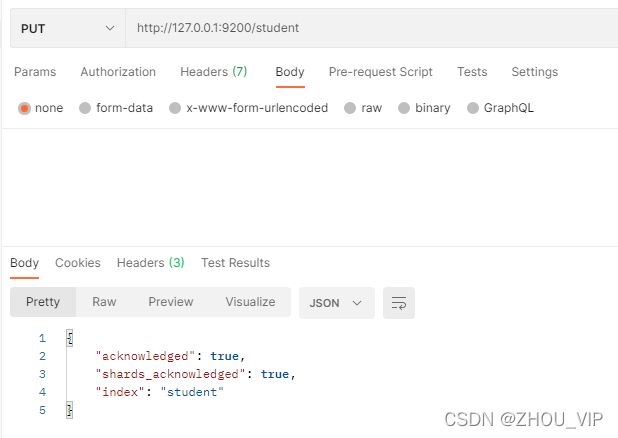
然后创建映射:http://127.0.0.1:9200/student/_mapping
{
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}


2) 查看映射
在Postman 中,向ES服务器发GET 请求:http://127.0.0.1:9200/student/_mapping
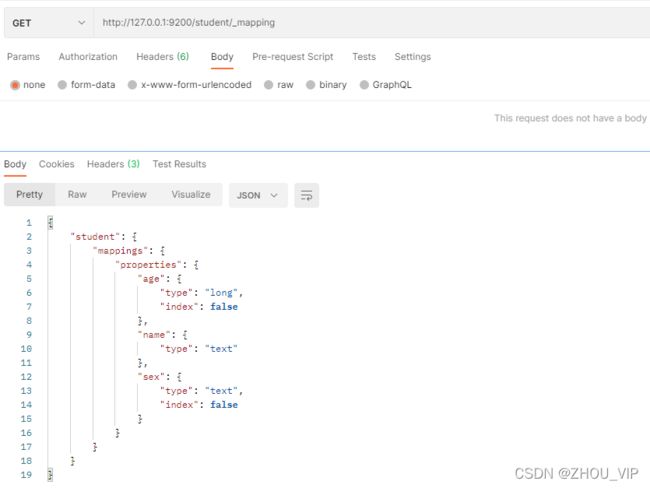
3) 索引映射关联
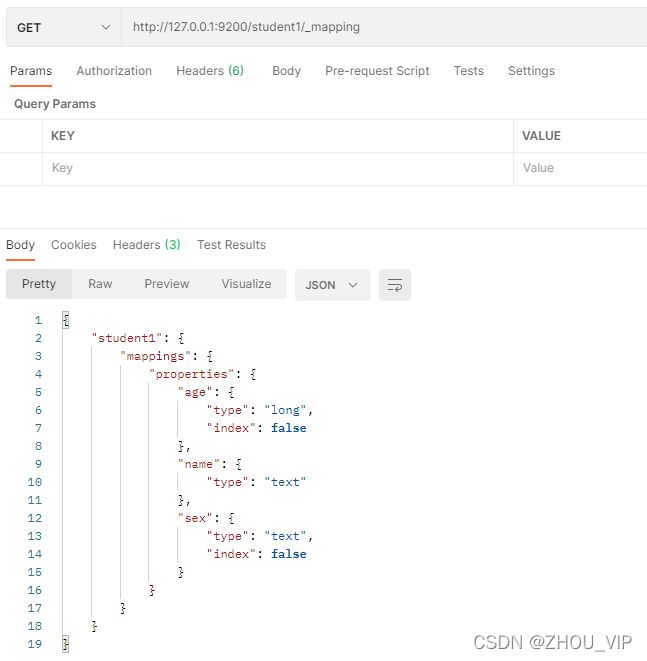
在Postman中,向ES服务器发PUT请求:http://127.0.0.1:9200/student1
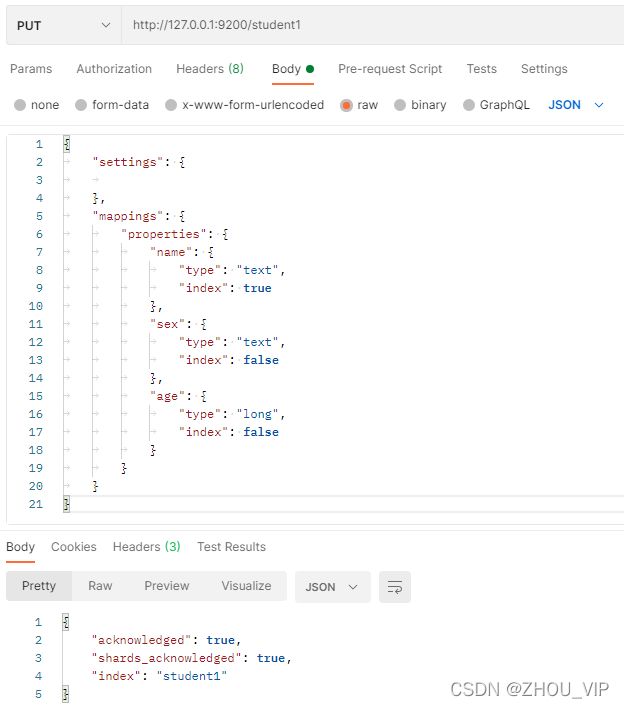
查询下http://127.0.0.1:9200/student1/_mapping,发现自动创建了索引student1和映射
高级查询
Elasticsearch提供了基于JSON提供完整的查询DSL来定义查询
定义数据 :
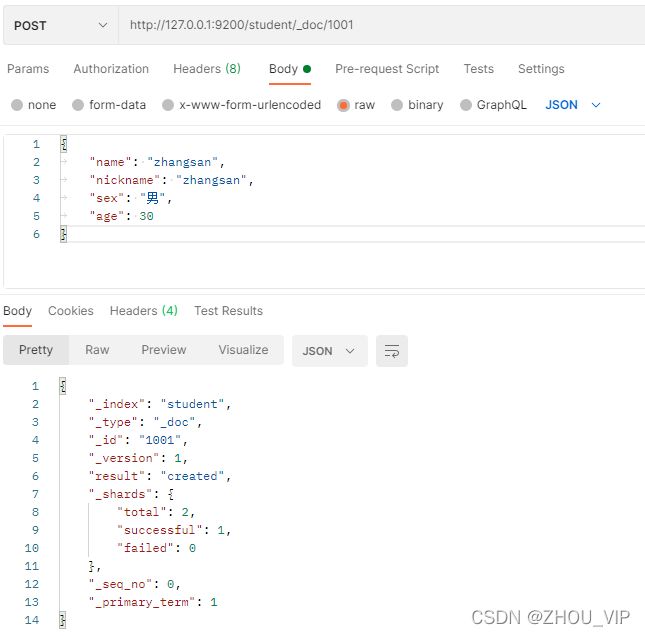
#POST/student/_doc/1001
{
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
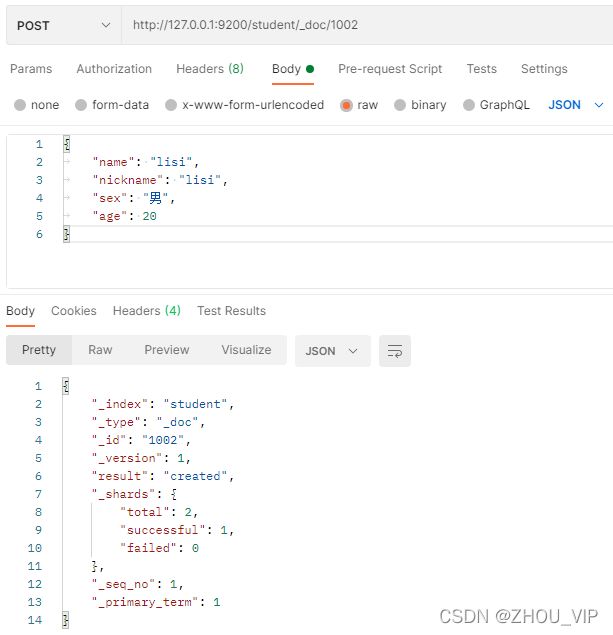
#POST/student/_doc/1002
{
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
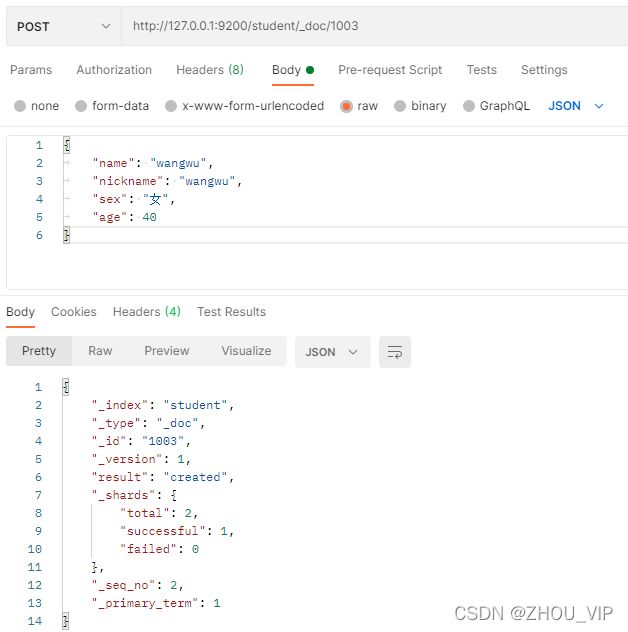
#POST/student/_doc/1003
{
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
#POST/student/_doc/1004
{
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
#POST/student/_doc/1005
{
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}


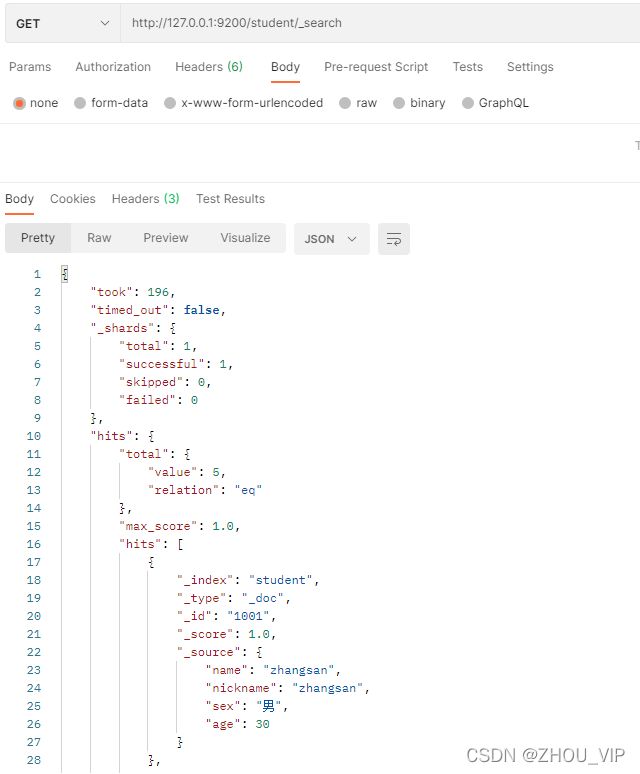
1) 查询所有文档
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/student/_search
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.0,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.0,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1.0,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1.0,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1.0,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}{
"query": {
"match_all": {
}
}
}
#"query":这里的query代表一个查询对象,里面可以有不同的查询属性
#"match_all":查询类型,例如:match_all(代表查询所有),match,term,range等等
#{查询条件}:查询条件会根据类型的不同,写法也有差异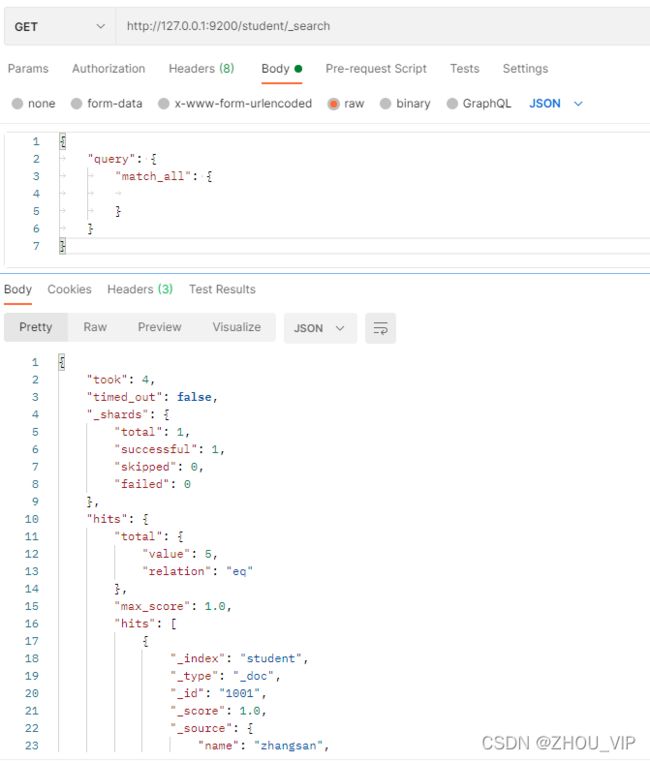
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.0,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.0,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1.0,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1.0,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1.0,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}注释:
{
"took"【查询花费时间,单位毫秒】: 4,
"timed_out"【是否超时】: false,
"_shards"【分片信息】: {
"total"【总数】: 1,
"successful"【成功】: 1,
"skipped"【忽略】: 0,
"failed"【失败】: 0
},
"hits"【搜索命中结果】: {
"total"【搜索条件匹配的文档总数】: {
"value"【总命中计数的值】: 5,
"relation"【计数规则】: "eq" # eq 表示计数准确, gte 表示计数不准确
},
"max_score"【匹配度分值】: 1.0,
"hits"【命中结果集合】: [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.0,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.0,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1.0,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1.0,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1.0,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
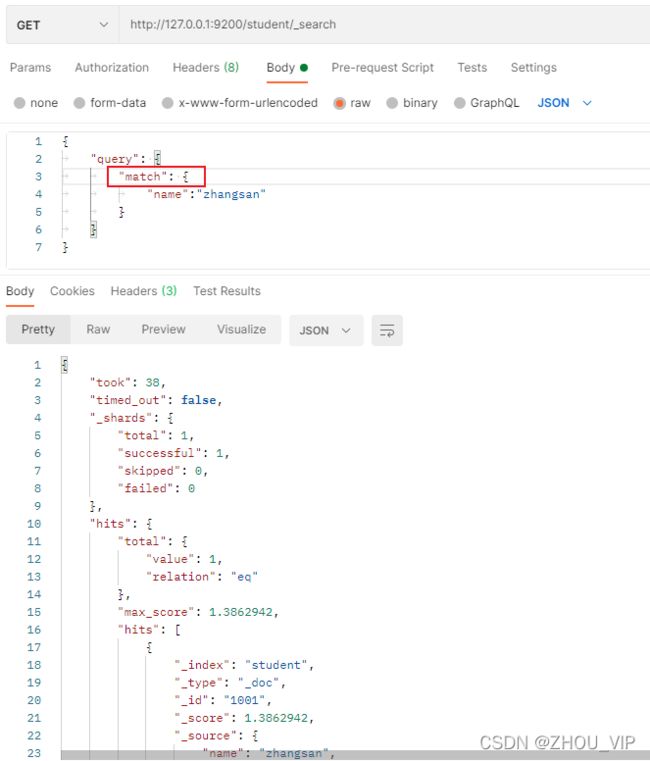
}2) 匹配查询
match匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/student/_search
注意是match不是match_all
{
"took": 38,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
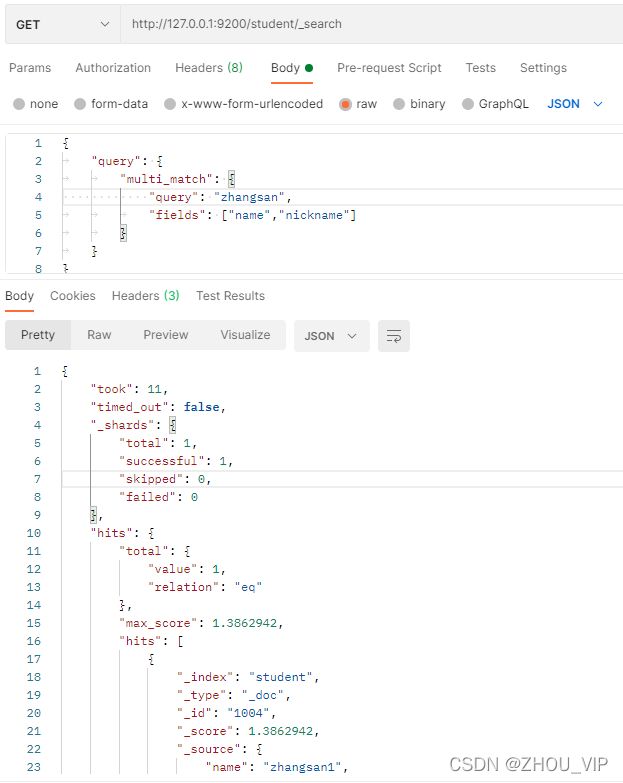
}3) 字段匹配查询
multi_match与match类似,不同的是它可以在多个字段中查询。
在Postman中,向ES服务器发GET 请求:http://127.0.0.1:9200/student/_search
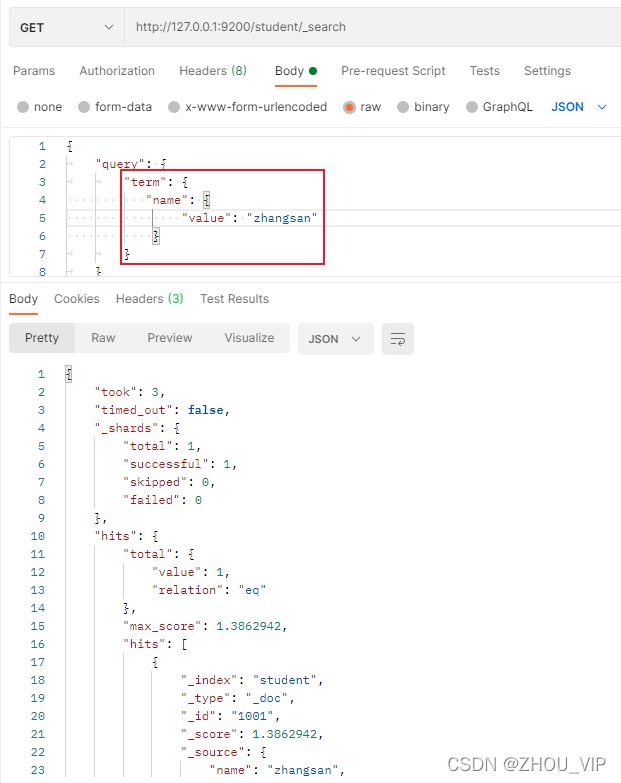
4) 关键字精确查询
term查询,精确的关键词匹配查询,不对查询条件进行分词。
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/student/_search
5) 多关键字精确查询
terms查询和term查询一样,但它允许你指定多值进行匹配。
如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于mysql的in
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/student/_search

{
"took": 24,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.0,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.0,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
}
]
}
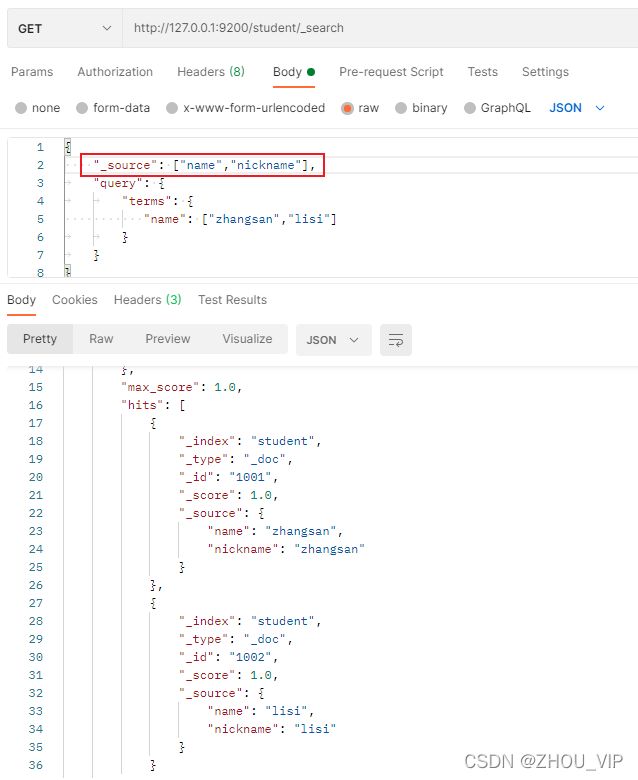
}6) 指定查询字段
默认情况下,Elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
在Postman中,向ES服务器发GET请求 :http://127.0.0.1:9200/student/_search
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.0,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.0,
"_source": {
"name": "lisi",
"nickname": "lisi"
}
}
]
}
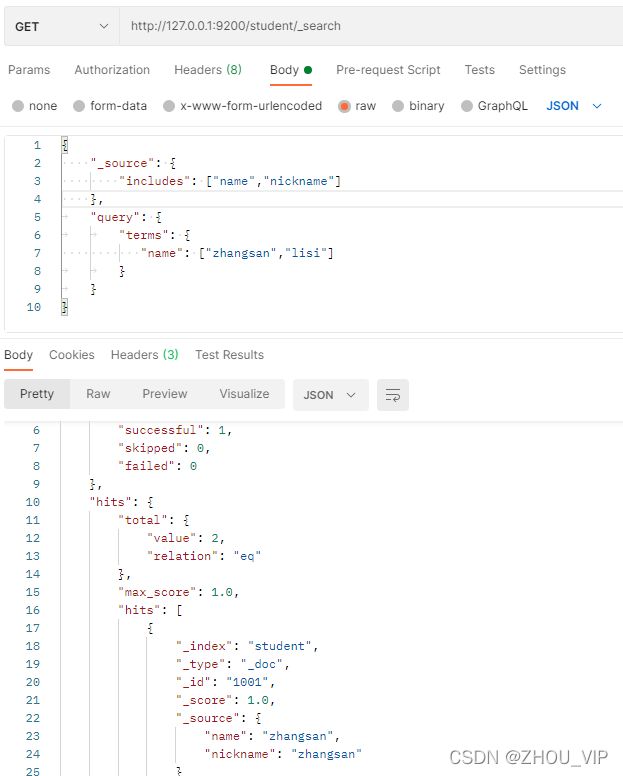
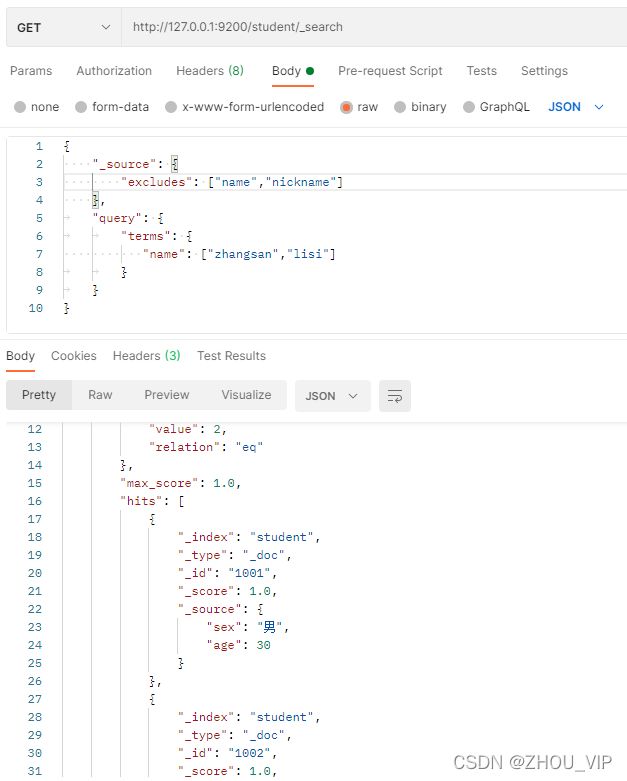
}7) 过滤字段
我们也可以通过:
includes:来指定想要显示的字段
excludes:来指定不想要显示的字段
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/student/_search
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.0,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan"
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.0,
"_source": {
"name": "lisi",
"nickname": "lisi"
}
}
]
}
}
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.0,
"_source": {
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1.0,
"_source": {
"sex": "男",
"age": 20
}
}
]
}
}8) 组合查询
`bool`把各种其它查询通过`must`(必须 )、`must_not`(必须不)、`should`(应该)的方
式进行组合
在Postman中,向ES服务器发GET请求:http://127.0.0.1:9200/student/_search
{
"query": {
"bool": {
"must": [{
"match": {
"name": "zhangsan"
}
}],
"must_not": [{
"match": {
"age": "40"
}
}],
"should": [{
"match": {
"sex": "男"
}
}]
}
}
}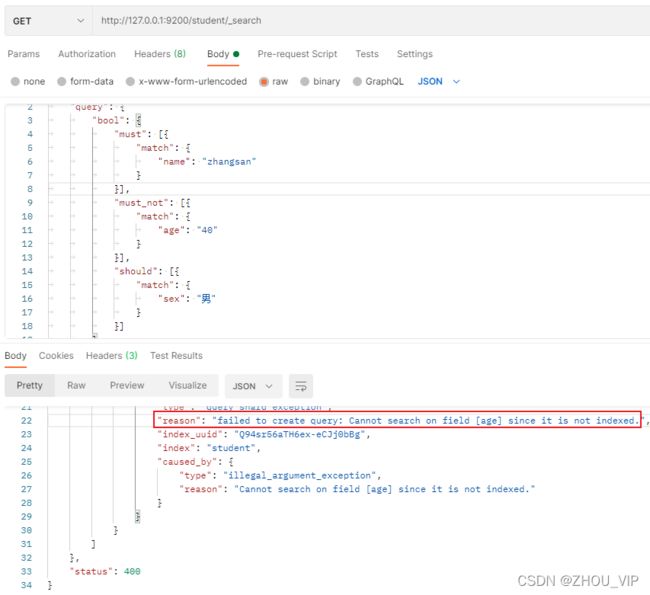

结果报错:"failed to create query: Cannot search on field [age] since it is not indexed.",
老师文档上没报错,我一步步操作竟然报错,坑,我得排查排查
为什么报这个错?其实已经告知得很清楚了:
field [age] since it is not indexed 属性age不支持被检索
查询下映射:
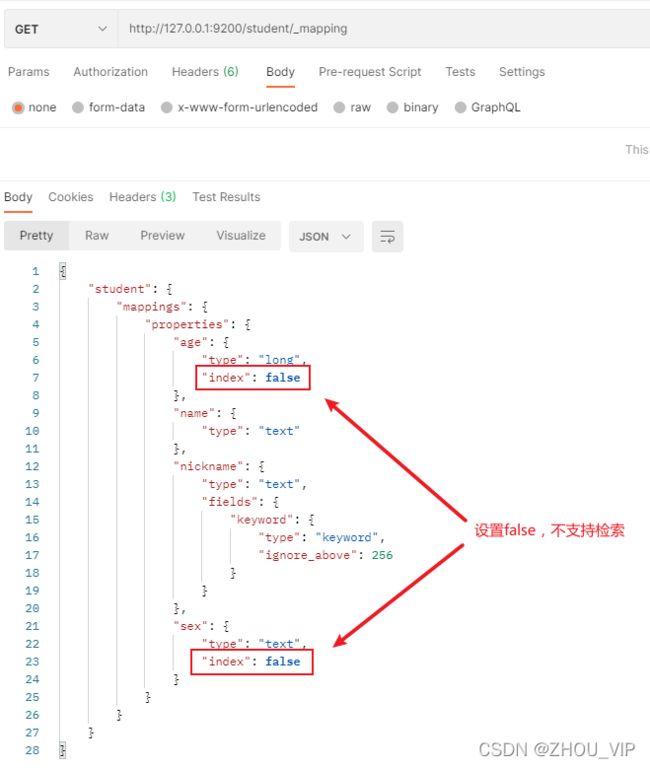
为了验证正确性,我重新建了索引zhou和映射,设置的都是true

#POST/zhou/_doc/1001
{
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
#POST/zhou/_doc/1002
{
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
#POST/zhou/_doc/1003
{
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
#POST/zhou/_doc/1004
{
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
#POST/zhou/_doc/1005
{
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
测试ok:

{
"took": 457,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.261763,
"hits": [
{
"_index": "zhou",
"_type": "_doc",
"_id": "1001",
"_score": 2.261763,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}实践出真理,尽信书不如无书呀!
基于ELK的ElasticSearch 7.8.x 技术整理1 - 基础语法篇 - 更新完毕 - 紫邪情 - 博客园