CS231n-assignment3-Transformer_Captioning
之前已经实现了一个vanilla RNN和用于生成图像标题的任务。在本笔记本中,您将实现变压器解码器的关键部分,以完成相同的任务。
跟之前一样
ln[1]:
# Setup cell.
import time, os, json
import numpy as np
import matplotlib.pyplot as plt
from cs231n.gradient_check import eval_numerical_gradient, eval_numerical_gradient_array
from cs231n.transformer_layers import *
from cs231n.captioning_solver_transformer import CaptioningSolverTransformer
from cs231n.classifiers.transformer import CaptioningTransformer
from cs231n.coco_utils import load_coco_data, sample_coco_minibatch, decode_captions
from cs231n.image_utils import image_from_url
#%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # Set default size of plots.
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
%load_ext autoreload
%autoreload 2
def rel_error(x, y):
""" returns relative error """
return np.max(np.abs(x - y) / (np.maximum(1e-8, np.abs(x) + np.abs(y))))
ln[2]:
# Load COCO data from disk into a dictionary.
data = load_coco_data(pca_features=True)
# Print out all the keys and values from the data dictionary.
for k, v in data.items():
if type(v) == np.ndarray:
print(k, type(v), v.shape, v.dtype)
else:
print(k, type(v), len(v))
Transformer: Multi-Headed Attention
对于同一个文本,一个Attention获得一个表示空间,如果多个Attention,则可以获得多个不同的表示空间
Multi-Head Attention为Attention提供了多个“representation subspaces”。因为在每个Attention中,采用不同的Query / Key / Value权重矩阵,每个矩阵都是随机初始化生成的。然后通过训练,将词嵌入投影到不同的“representation subspaces(表示子空间)”中。
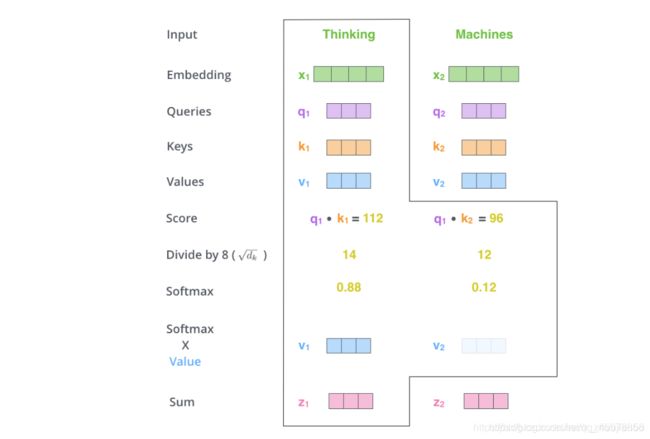
在transformer中,我们执行self-attention,这意味着values、keys和查询都来自输入∈ℝℓ×,其中ℓ是我们的序列长度。具体来说,我们学习参数矩阵,,∈ℝ×来映射我们的输入如下:

在multi-headed注意的情况下,我们学习每个head的参数矩阵,使模型更能表达注意输入的不同部分。设ℎ为head数,为 h e a d head_ headi的注意力输出。因此,我们学习单个矩阵,和。保持我们的整体计算的head的情况下,我们选择∈ℝ×/ℎ ∈ℝ×/ℎ和∈ℝ×/ℎ。在上面简单的点积上加上一个比例项 1 d / h \frac{1}{\sqrt{d/h}} d/h1,我们得到
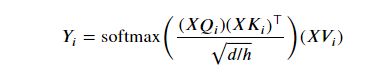
其中∈ℝℓ×/ℎ,ℓ为序列长度。
在我们的实现中,我们在这里应用dropout(尽管实际上它可以在任何步骤中使用):
![]()
最后,自我注意的输出是heads级联的线性变换:=[1;…;ℎ] (∈ℝ×和[1;…;ℎ]∈ℝℓ×)
完成cs231n/transformer_layers.py中MultiHeadAttention
class MultiHeadAttention(nn.Module):
"""
A model layer which implements a simplified version of masked attention, as
introduced by "Attention Is All You Need" (https://arxiv.org/abs/1706.03762).
Usage:
attn = MultiHeadAttention(embed_dim, num_heads=2)
# self-attention
data = torch.randn(batch_size, sequence_length, embed_dim)
self_attn_output = attn(query=data, key=data, value=data)
# attention using two inputs
other_data = torch.randn(batch_size, sequence_length, embed_dim)
attn_output = attn(query=data, key=other_data, value=other_data)
"""
def __init__(self, embed_dim, num_heads, dropout=0.1):
"""
Construct a new MultiHeadAttention layer.
Inputs:
- embed_dim: Dimension of the token embedding
- num_heads: Number of attention heads
- dropout: Dropout probability
"""
super().__init__()
assert embed_dim % num_heads == 0
# We will initialize these layers for you, since swapping the ordering
# would affect the random number generation (and therefore your exact
# outputs relative to the autograder). Note that the layers use a bias
# term, but this isn't strictly necessary (and varies by
# implementation).
self.key = nn.Linear(embed_dim, embed_dim)
self.query = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.proj = nn.Linear(embed_dim, embed_dim)
############################################################################
# TODO: Initialize any remaining layers and parameters to perform the #
# attention operation as defined in Transformer_Captioning.ipynb. We will #
# also apply dropout just after the softmax step. For reference, our #
# solution is less than 5 lines. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
self.num_heads = num_heads
self.dropout = nn.Dropout(dropout)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
def forward(self, query, key, value, attn_mask=None):
"""
Calculate the masked attention output for the provided data, computing
all attention heads in parallel.
In the shape definitions below, N is the batch size, S is the source
sequence length, T is the target sequence length, and E is the embedding
dimension.
Inputs:
- query: Input data to be used as the query, of shape (N, S, E)
- key: Input data to be used as the key, of shape (N, T, E)
- value: Input data to be used as the value, of shape (N, T, E)
- attn_mask: Array of shape (T, S) where mask[i,j] == 0 indicates token
i in the target should not be influenced by token j in the source.
Returns:
- output: Tensor of shape (N, S, E) giving the weighted combination of
data in value according to the attention weights calculated using key
and query.
"""
N, S, D = query.shape
N, T, D = value.shape
# Create a placeholder, to be overwritten by your code below.
output = torch.empty((N, T, D))
############################################################################
# TODO: Implement multiheaded attention using the equations given in #
# Transformer_Captioning.ipynb. #
# A few hints: #
# 1) You'll want to split your shape from (N, T, E) into (N, T, H, E/H), #
# where H is the number of heads. #
# 2) The function torch.matmul allows you to do a batched matrix multiply.#
# For example, you can do (N, H, T, E/H) by (N, H, E/H, T) to yield a #
# shape (N, H, T, T). For more examples, see #
# https://pytorch.org/docs/stable/generated/torch.matmul.html #
# 3) For applying attn_mask, think how the scores should be modified to #
# prevent a value from influencing output. Specifically, the PyTorch #
# function masked_fill may come in handy. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
H = self.num_heads
Q = self.query(query).view(N, S, H, D // H).transpose(1, 2) # N, H, S, K
K = self.key(key).view(N, T, H, D // H).transpose(1, 2) # N, H, T, K
V = self.value(value).view(N, T, H, D // H).transpose(1, 2) # N, H, T, K
# N, H, S, T <- N, H, S, K * N, H, K, T
E = Q.matmul(K.transpose(2, 3)) / torch.sqrt(torch.Tensor([D / H]))
# mask before softmax
if attn_mask is not None: # attn_mast: T, S, so maybe here is a mistake
E = E.masked_fill(attn_mask == False, -float('inf'))
A = torch.softmax(E, dim=3) # N, H, S, ->T<-
A = self.dropout(A)
# N, H, S, K <- N, H, S, T * N, H, T, K
Y = A.matmul(V)
output = self.proj(Y.transpose(1, 2).reshape(N, S, D))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return output
下面的代码将检查您的实现。相对误差应小于1e-3。
ln[3]:
torch.manual_seed(231)
# Choose dimensions such that they are all unique for easier debugging:
# Specifically, the following values correspond to N=1, H=2, T=3, E//H=4, and E=8.
batch_size = 1
sequence_length = 3
embed_dim = 8
attn = MultiHeadAttention(embed_dim, num_heads=2)
# Self-attention.
data = torch.randn(batch_size, sequence_length, embed_dim)
self_attn_output = attn(query=data, key=data, value=data)
# Masked self-attention.
mask = torch.randn(sequence_length, sequence_length) < 0.5
masked_self_attn_output = attn(query=data, key=data, value=data, attn_mask=mask)
# Attention using two inputs.
other_data = torch.randn(batch_size, sequence_length, embed_dim)
attn_output = attn(query=data, key=other_data, value=other_data)
expected_self_attn_output = np.asarray([[
[-0.2494, 0.1396, 0.4323, -0.2411, -0.1547, 0.2329, -0.1936,
-0.1444],
[-0.1997, 0.1746, 0.7377, -0.3549, -0.2657, 0.2693, -0.2541,
-0.2476],
[-0.0625, 0.1503, 0.7572, -0.3974, -0.1681, 0.2168, -0.2478,
-0.3038]]])
expected_masked_self_attn_output = np.asarray([[
[-0.1347, 0.1934, 0.8628, -0.4903, -0.2614, 0.2798, -0.2586,
-0.3019],
[-0.1013, 0.3111, 0.5783, -0.3248, -0.3842, 0.1482, -0.3628,
-0.1496],
[-0.2071, 0.1669, 0.7097, -0.3152, -0.3136, 0.2520, -0.2774,
-0.2208]]])
expected_attn_output = np.asarray([[
[-0.1980, 0.4083, 0.1968, -0.3477, 0.0321, 0.4258, -0.8972,
-0.2744],
[-0.1603, 0.4155, 0.2295, -0.3485, -0.0341, 0.3929, -0.8248,
-0.2767],
[-0.0908, 0.4113, 0.3017, -0.3539, -0.1020, 0.3784, -0.7189,
-0.2912]]])
print('self_attn_output error: ', rel_error(expected_self_attn_output, self_attn_output.detach().numpy()))
print('masked_self_attn_output error: ', rel_error(expected_masked_self_attn_output, masked_self_attn_output.detach().numpy()))
print('attn_output error: ', rel_error(expected_attn_output, attn_output.detach().numpy()))

Positional Encoding(位置编码)
虽然Transformer能够很容易地关注其输入的任何部分,但注意机制没有顺序的概念。然而,对于许多任务(特别是自然语言处理),相对标记顺序非常重要。为了恢复这一点,作者在单个单词标记的嵌入中添加了位置编码。
定义一个矩阵∈ℝ×
_{} Pij= { sin ( i ⋅ 1000 0 − j d ) if j is even cos ( i ⋅ 1000 0 − ( j − 1 ) d ) otherwise \begin{cases} \text{sin}\left(i \cdot 10000^{-\frac{j}{d}}\right) & \text{if j is even} \\ \text{cos}\left(i \cdot 10000^{-\frac{(j-1)}{d}}\right) & \text{otherwise} \\ \end{cases} ⎩⎨⎧sin(i⋅10000−dj)cos(i⋅10000−d(j−1))if j is evenotherwise
我们没有直接向我们的网络传递输入∈ℝ×,而是传递+。
完成cs231n/transformer_layers.py的PositionalEncoding
class PositionalEncoding(nn.Module):
"""
Encodes information about the positions of the tokens in the sequence. In
this case, the layer has no learnable parameters, since it is a simple
function of sines and cosines.
"""
def __init__(self, embed_dim, dropout=0.1, max_len=5000):
"""
Construct the PositionalEncoding layer.
Inputs:
- embed_dim: the size of the embed dimension
- dropout: the dropout value
- max_len: the maximum possible length of the incoming sequence
"""
super().__init__()
self.dropout = nn.Dropout(p=dropout)
assert embed_dim % 2 == 0
# Create an array with a "batch dimension" of 1 (which will broadcast
# across all examples in the batch).
pe = torch.zeros(1, max_len, embed_dim)
############################################################################
# TODO: Construct the positional encoding array as described in #
# Transformer_Captioning.ipynb. The goal is for each row to alternate #
# sine and cosine, and have exponents of 0, 0, 2, 2, 4, 4, etc. up to #
# embed_dim. Of course this exact specification is somewhat arbitrary, but #
# this is what the autograder is expecting. For reference, our solution is #
# less than 5 lines of code. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
col = torch.arange(0, max_len).unsqueeze(1)
row = 10000**(-torch.arange(0, embed_dim, 2) / embed_dim)
m = col * row
pe[:, :, 0::2] = torch.sin(m)
pe[:, :, 1::2] = torch.cos(m)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
# Make sure the positional encodings will be saved with the model
# parameters (mostly for completeness).
self.register_buffer('pe', pe)
def forward(self, x):
"""
Element-wise add positional embeddings to the input sequence.
Inputs:
- x: the sequence fed to the positional encoder model, of shape
(N, S, D), where N is the batch size, S is the sequence length and
D is embed dim
Returns:
- output: the input sequence + positional encodings, of shape (N, S, D)
"""
N, S, D = x.shape
# Create a placeholder, to be overwritten by your code below.
output = torch.empty((N, S, D))
############################################################################
# TODO: Index into your array of positional encodings, and add the #
# appropriate ones to the input sequence. Don't forget to apply dropout #
# afterward. This should only take a few lines of code. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
output = x + self.pe[:, :S, :]
output = self.dropout(output)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return output
完成之后,运行以下命令对实现执行一个简单的测试。您应该看到e-3或更小的错误。
ln[4]:
torch.manual_seed(231)
batch_size = 1
sequence_length = 2
embed_dim = 6
data = torch.randn(batch_size, sequence_length, embed_dim)
pos_encoder = PositionalEncoding(embed_dim)
output = pos_encoder(data)
expected_pe_output = np.asarray([[[-1.2340, 1.1127, 1.6978, -0.0865, -0.0000, 1.2728],
[ 0.9028, -0.4781, 0.5535, 0.8133, 1.2644, 1.7034]]])
print('pe_output error: ', rel_error(expected_pe_output, output.detach().numpy()))
![]()
内联问题1
在设计我们上面介绍的dot product attention时,我们做出了几个关键的设计决策。解释为什么以下选择是有益的:
1.使用多个attention heads而不是一个。
2.在应用softmax函数之前除以 d / h \sqrt{d/h} d/h。回想一下, d d d是特征维数, h h h是head的数目。
3.在注意操作的输出上增加一个线性变换。如果我们直接叠加注意力操作会发生什么?
你的答案:
1.防止过度拟合。使模型更多地关注输入的相关特征,而不是一些偏的不相关的特征。(可能与单词嵌入一起工作)
2.大量的相似性将导致softmax饱和,并会导致梯度消失。假设x和y是常数(如a),维数为d/h。那么 ∣ x ∣ = a d / h |x| = a\sqrt{d/h} ∣x∣=ad/h
3.没有线性变换,输出将只是V的某个线性组合,因此输出是有限的,模型的容量也是有限的。
基于小数据的过拟合Transformer字幕模型
运行以下操作,在与RNN相同的小数据集上对基于transformer的字幕模型进行过拟合。
ln[5]:
torch.manual_seed(231)
np.random.seed(231)
data = load_coco_data(max_train=50)
transformer = CaptioningTransformer(
word_to_idx=data['word_to_idx'],
input_dim=data['train_features'].shape[1],
wordvec_dim=256,
num_heads=2,
num_layers=2,
max_length=30
)
transformer_solver = CaptioningSolverTransformer(transformer, data, idx_to_word=data['idx_to_word'],
num_epochs=100,
batch_size=25,
learning_rate=0.001,
verbose=True, print_every=10,
)
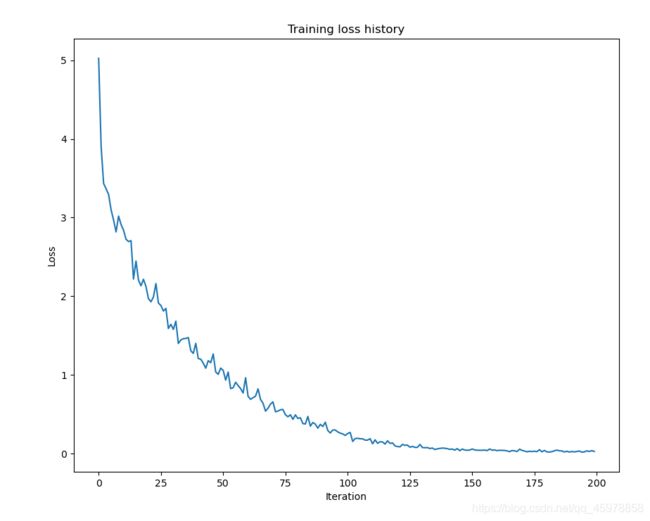
transformer_solver.train()
# Plot the training losses.
plt.plot(transformer_solver.loss_history)
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Training loss history')
plt.show()
ln[6]:
print('Final loss: ', transformer_solver.loss_history[-1])

Test Time
ln[7]:
# If you get an error, the URL just no longer exists, so don't worry!
# You can re-sample as many times as you want.
for split in ['train', 'val']:
minibatch = sample_coco_minibatch(data, split=split, batch_size=2)
gt_captions, features, urls = minibatch
gt_captions = decode_captions(gt_captions, data['idx_to_word'])
sample_captions = transformer.sample(features, max_length=30)
sample_captions = decode_captions(sample_captions, data['idx_to_word'])
for gt_caption, sample_caption, url in zip(gt_captions, sample_captions, urls):
img = image_from_url(url)
# Skip missing URLs.
if img is None: continue
plt.imshow(img)
plt.title('%s\n%s\nGT:%s' % (split, sample_caption, gt_caption))
plt.axis('off')
plt.show()


