计算机体系结构实验 (实验报告)
目录
- 1. MIPS 指令系统和 MIPS 体系结构
-
- 编写 MIPS 汇编程序
- 观察程序的执行情况
- 2. 流水线及流水线的冲突
- 3. 指令调度和延迟分支
-
- 编写 MIPS 汇编程序
- 不加任何优化操作
- 开启定向
- 指令调度
- 循环展开
- 分支延迟
-
- 从前调度
- 从目标处调度
- 从失败处调度
- 循环展开 + 分支延迟
- 4. Cache 性能分析
-
- 不同的 Cache 容量对不命中率的影响
- 相联度对不命中率的影响
- Cache 块大小对不命中率的影响
- 替换算法对不命中率的影响
- 5. Tomasulo 算法
- 6. 再定序缓冲(ROB)工作原理
- 7. 多 Cache 一致性—— 监听协议
- 8. 多 Cache 一致性—— 目录协议
1. MIPS 指令系统和 MIPS 体系结构
编写 MIPS 汇编程序
- 编写计算两个数最大公约数以及最小公倍数的程序。主要是利用辗转相除法求出最大公约数,之后再用原来两数的乘积除以最大公约数就得到了最小公倍数
- 下面是对应的 C++ 程序 (计算 6 和 9 的最大公约数以及最小公倍数):
#include - 对照 C++ 程序编写出 MIPS 汇编程序,相应说明已经写在程序注释中,总体来说还是比较简单的:
.text
main:
# 求 a 和 b 的最大公约数及最小公倍数
ADDI $r1, $r0, 6 # r1: a
ADDI $r2, $r0, 9 # r2: b
MULT $r1, $r2 # a * b -> (LO, HI)
MFLO $r5 # a * b -> r5
Loop:
BLEZ $r2, EXIT
DIV $r1, $r2 # a / b -> (LO, HI)
ADD $r1, $r2, $r0 # a = b
MFHI $r2 # b = a % b
B Loop
EXIT:
# 计算最小公倍数
DIV $r5, $r1
MFLO $r6 # r6 -> 最小公倍数 (a * b / 最小公约数)
# r1 -> 最大公约数
TEQ $r0, $r0
观察程序的执行情况
- 首先载入上面编写好的程序并设置为“非流水”执行方式:
- 在程序运行之前,注意到
PC的值为0x00000000
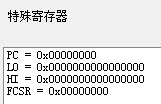
- 单步执行
ADDI $r1, $r0, 6;观察到寄存器r1的值变为了 6,即r1中存储数 a a a 的值。同时PC值加 4,这是因为 MIPS 采用定长指令格式,每条指令长度均为 4 字节,因此如果没有跳转指令的话,每顺序执行一条指令PC的值都会加 4
- 单步执行
ADDI $r2, $r0, 9;观察到寄存器r2的值变为了 9,即r2中存储数 b b b 的值

- 单步执行
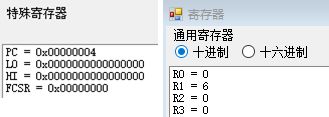
MULT $r1, $r2;观察到寄存器LO的值变为了 0x36,即 a × b a\times b a×b 的值 54
- 单步执行
MFLO $r5;观察到寄存器r5的值变为了 54,即将寄存器LO的值传送到寄存器r5
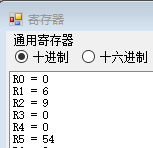
- 单步执行
BLEZ $r2, 4;其测试条件为r2的值小于等于 0,如果满足则跳转到目标地址0x00A1001A处,也即当前指令地址 + 5 条指令的偏移量后得到的地址 (4 条指令的偏移量 + PC 原本就要增加的 1 条指令的偏移量);同时注意到标号EXIT被替换为了相对 PC 值的偏移量 4;此时不满足条件,因此不跳转,可以看到 PC 值为0x00000014

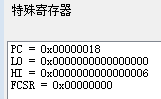
- 单步执行
DIV $r1, $r2,可以看到,寄存器LO值为 0,HI值为 6,表明除法后的余数为 6,商为 0
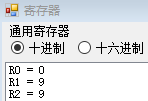
- 单步执行
ADD $r1, $r2, $r0,可以看到,r1的值变为了r2的值 9
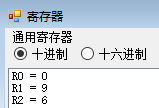
- 单步执行
MFHI $r2,可以看到,r2的值变为了刚才计算得到的余数 6;至此已完成了辗转相除法的第一轮循环
- 单步执行
BEQ $r0, $r0, Loop;注意到这条机器指令是由无条件跳转指令B Loop编译得到的,它的判断条件r0 = r0永远为真,因此总是跳转到目标地址Loop处;可以观察到,指令执行完毕后,PC变为了标号Loop的地址0x00000010
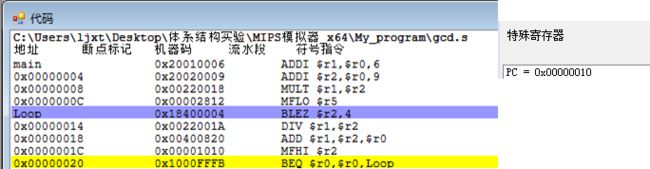
- 下面不断进行上述循环,直至
r2 <= 0条件成立,下面直接打上断点,执行到r2 <= 0条件成立的时候,如下图所示,此时r2 == 0,因此跳转条件满足。同时注意到r1 = 3,这里r1保存的即为计算完的最大公约数;指令执行完毕后,PC值变为0x00000024,表明成功跳转至指令DIV $r5, $r1
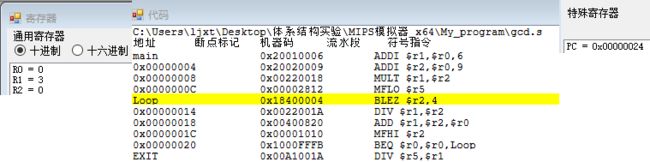
- 单步执行
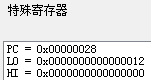
DIV $r5, $r1,即用原来两个数的积除以最大公约数,此时LO为0x12,HI为 0,表明商为 18,余数为 0,这个 18 即为计算出的最小公倍数
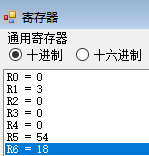
- 单步执行
MFLO $r6,r6的值变为LO的值 18,此时r6用于保存最后得到的最小公倍数
2. 流水线及流水线的冲突
3. 指令调度和延迟分支
这两个实验都是优化同一段程序,因此就把报告写在一起了
编写 MIPS 汇编程序
- 首先编写如下代码,它的主要功能为将内存地址
0xA0处的数据转换为 10 进制形式显示,转换后的数字存储在内存地址0xA8中
# v1: data hazard + control hazard
.text # 将 16 进制数转为 10 进制数进行显示
main:
ADDIU $r8, $r0, 160 # r8 = 160 (0xA0) ; 要转换的数(半字,16位,小端对齐)存在内存地址 160 处
ADDIU $r9, $r0, 168 # r9 = 168 (0xA8) ; 转换完毕的数存在内存地址 168 处
LHU $r1, 0($r8) # r1 = memory[r8]
ADDIU $r10, $r0, 10 # r10 = 10
ADDIU $r4, $r0, 0
loop1:
DIVU $r1, $r10
MFHI $r2 # r2 = r1 % 10
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
OR $r3, $r2 # r3 |= r2
MFLO $r1 # r1 /= 10
# stall (RAW)
BGTZ $r1, loop1 # while(r1 > 0)
SW $r3, 0($r9) # 存字
TEQ $r0, $r0
不加任何优化操作
- 载入程序,模式设置为流水方式,首先将内存地址
0xA0内的数据改为0xA0,即十进制数 160
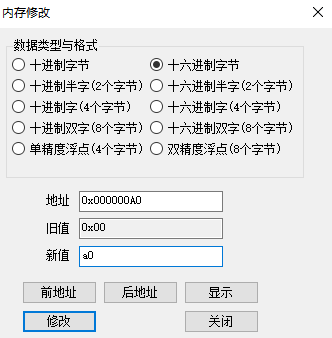
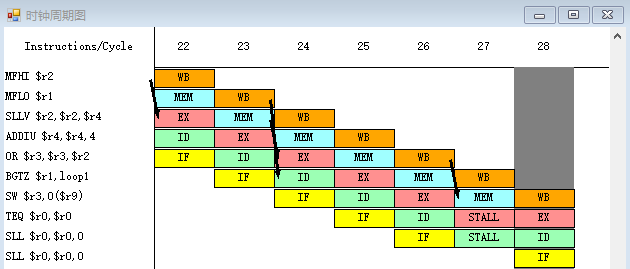
- 执行程序,发现此时停顿周期数为 21,总的执行时钟周期为 50 (之后会不断优化,将总的执行时钟周期降低到 28);下面分析出现的流水线冲突 (忽略“自陷冲突”)


- (1)
ADDIU $r8, $r0, 160与LHU $r1, 0($r8)存在 RAW 冲突,LHU $r1, 0($r8)必须 stall 一个周期

- (2)
ADDIU $r10, $r0, 10与DIVU $r1, $r10存在 RAW 冲突,DIVU $r1, $r10必须 stall 一个周期

- (3)
MFHI $r2与SLLV $r2, $r2, $r4存在 RAW 冲突,SLLV $r2, $r2, $r4必须 stall 两个周期
- (4)
SLLV $r2, $r2, $r4与OR $r3, $r2存在 RAW 冲突,OR $r3, $r2必须 stall 一个周期

- (4)
MFLO $r1与BGTZ $r1, loop1存在 RAW 冲突,BGTZ $r1, loop1必须 stall 两个周期

- (5)
BGTZ $r1, loop1与之后执行的指令存在控制冲突,后续指令必须等到BGTZ $r1, loop1的 ID 段结束,也就是判断出分支是否跳转以及跳转的目的地址之后才能继续执行。这里 stall 了一个周期

- (1)
这里并没有结构冲突;如果有结构冲突的话,可以通过重复设置功能部件来解决
开启定向
- 使用定向技术减少数据冲突引起的停顿。定向技术的关键思想是在发生写后读相关的情况下,在计算结果尚未出来之前,后面等待使用该结果的指令并不见得马上就要使用该结果。如果能够将该计算结果从其产生的位置(ALU的出口)直接送到其他指令需要它的位置(ALU的入口),那么就可以避免停顿
- 下面开启定向技术,执行程序,发现此时停顿周期数只有 7,相比之前减少了 14 个 RAW 停顿,大幅提高了流水线执行效率。同时程序的总的执行周期数缩减到了 36 个时钟周期

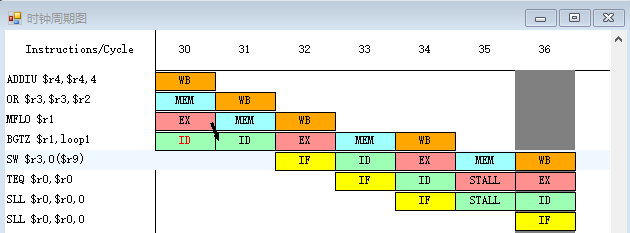
- 以之前提到的
ADDIU $r8, $r0, 160与LHU $r1, 0($r8)存在的 RAW 冲突为例,当开启定向技术后,LHU $r1, 0($r8)不再需要 stall 一个周期,而是直接由流水寄存器MEM/WB.ALUOUT取得需要的r8的值,进而在 EX 段进行计算;其他 RAW 冲突的解决也同理

- 现在剩余的流水线冲突有两处:
- (1)
BGTZ $r1, loop1与之后执行的指令存在控制冲突,后续指令必须等到BGTZ $r1, loop1的 ID 段结束,也就是判断出分支是否跳转以及跳转的目的地址之后才能继续执行。这里 stall 了一个周期 - (2)
MFLO $r1与BGTZ $r1, loop1存在 RAW 冲突,由于分支指令的跳转地址必须在 ID 段计算,而 ID 段时MFLO $r1的 EX 段还未执行完成,因此BGTZ $r1, loop1必须 stall 一个周期

- (1)
指令调度
- 下面重点解决剩余的 RAW 冲突;下面代码主要做的修改就是将
MFLO $r1移到了前面,让它尽快将r1中的数算出,以避免 RAW 冲突
# v2: software scheduling -> eliminate data hazards
.text # 将 16 进制数转为 10 进制数进行显示
main:
ADDIU $r8, $r0, 160 # r8 = 160 (0xA0) ; 要转换的数(半字,16位,小端对齐)存在内存地址 160 处
ADDIU $r9, $r0, 168 # r9 = 168 (0xA8) ; 转换完毕的数存在内存地址 168 处
LHU $r1, 0($r8) # r1 = memory[r8]
ADDIU $r10, $r0, 10 # r10 = 10
ADDIU $r4, $r0, 0
loop1:
DIVU $r1, $r10
MFHI $r2 # r2 = r1 % 10
MFLO $r1 # r1 /= 10 # 将本指令提前执行
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
OR $r3, $r2 # r3 |= r2
BGTZ $r1, loop1 # while(r1 > 0)
SW $r3, 0($r9) # 存字
TEQ $r0, $r0
- 下面执行程序,发现此时停顿周期数只有 4,完全消除了 RAW 停顿。同时程序的总的执行周期数缩减到了 33 个时钟周期

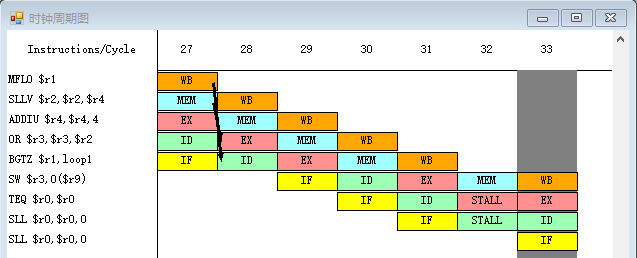
- 现在剩余的流水线冲突仅有控制冲突:
- (1)
BGTZ $r1, loop1与之后执行的指令存在控制冲突,后续指令必须等到BGTZ $r1, loop1的 ID 段结束,也就是判断出分支是否跳转以及跳转的目的地址之后才能继续执行。这里 stall 了一个周期

- (1)
循环展开
- 一般来说,循环展开是用于将循环多次展开后进行寄存器重命名以更方便地进行软件调度来消除数据冲突的方法。但同时,它也可以减少循环带来的额外开销
- 在下面的代码中,我默认转换后得到的十进制数占 3 位,也就是循环要执行 3 次,因此我将循环展开了 3 次,这样就可以减少 2/3 的循环开销
# v2: loop unrolling to avoid loop overheads
.text # 将 16 进制数转为 10 进制数进行显示
main:
ADDIU $r8, $r0, 160 # r8 = 160 (0xA0) ; 要转换的数(半字,16位,小端对齐)存在内存地址 160 处
ADDIU $r9, $r0, 168 # r9 = 168 (0xA8) ; 转换完毕的数存在内存地址 168 处
LHU $r1, 0($r8) # r1 = memory[r8]
ADDIU $r10, $r0, 10 # r10 = 10
ADDIU $r4, $r0, 0
# unroll the loop 3 times (Assuming the decimal number has 3n bits) and omit the register renaming
# can decrease the loop overheads
loop1:
DIVU $r1, $r10
MFHI $r2 # r2 = r1 % 10
MFLO $r1 # r1 /= 10
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
OR $r3, $r2 # r3 |= r2
DIVU $r1, $r10
MFHI $r2 # r2 = r1 % 10
MFLO $r1 # r1 /= 10
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
OR $r3, $r2 # r3 |= r2
DIVU $r1, $r10
MFHI $r2 # r2 = r1 % 10
MFLO $r1 # r1 /= 10
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
OR $r3, $r2 # r3 |= r2
BGTZ $r1, loop1 # while(r1 > 0)
SW $r3, 0($r9) # 存字
TEQ $r0, $r0
- 下面执行程序,发现此时停顿周期数只有 2,其中控制停顿由 3 减少到了 1。同时程序的总的执行周期数缩减到了 29 个时钟周期


分支延迟
- 循环展开只能减少一部分的循环开销来达到减少控制冲突的目的,但如果想完全消除控制冲突,就需要使用分支延迟槽
- 其中,分支延迟槽的调度策略又可以分为从前调度、从目标处调度、从失败处调度
从前调度
- 编写如下代码,相比软件调度的代码,唯一的修改就是将
BGTZ $r1, loop1与OR $r3, $r2交换顺序,这就相当于手动将OR $r3, $r2调度到了分支延迟槽中。这样当开启分支延迟槽时,在BGTZ $r1, loop1未决定是否跳转以及跳转的地址时,系统就会自动执行OR $r3, $r2以避免产生 stall - 值得一提的是,采用从前调度的方法时,不管分支跳转还是不跳转,分支延迟槽中执行的永远是有意义的指令,因此程序得到的加速效果最大
# v4: specialized for delayed branch
.text # 将 16 进制数转为 10 进制数进行显示
main:
ADDIU $r8, $r0, 160 # r8 = 160 (0xA0) ; 要转换的数(半字,16位,小端对齐)存在内存地址 160 处
ADDIU $r9, $r0, 168 # r9 = 168 (0xA8) ; 转换完毕的数存在内存地址 168 处
LHU $r1, 0($r8) # r1 = memory[r8]
ADDIU $r10, $r0, 10 # r10 = 10
ADDIU $r4, $r0, 0
# fill branch delay slot from before
loop1:
DIVU $r1, $r10
MFHI $r2 # r2 = r1 % 10
MFLO $r1 # r1 /= 10
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
BGTZ $r1, loop1 # while(r1 > 0)
OR $r3, $r2 # r3 |= r2
SW $r3, 0($r9) # 存字
TEQ $r0, $r0
- 下面执行程序,发现此时停顿周期数只有 1,其中控制停顿与 RAW 停顿均已被完全消除。同时程序的总的执行周期数缩减到了 30 个时钟周期


- 在下图中可以注意到,在分支指令还未决定是否跳转时,系统先执行分支延迟槽中的指令
OR $r3, $r2以填补计算分支指令是否跳转的时间间隔

从目标处调度
- 编写如下代码,相比软件调度的代码,唯一的修改就是将分支跳转语句的目标指令
DIVU $r1, $r10移动到了分支指令之后,同时在循环之前增添了一条DIVU $r1, $r10指令,这就相当于手动将目标处指令DIVU $r1, $r10调度到了分支延迟槽中。这样当开启分支延迟槽时,在BGTZ $r1, loop1未决定是否跳转以及跳转的地址时,系统就会自动执行DIVU $r1, $r10以避免产生 stall - 值得一提的是,采用从目标处调度的方法时,只有当分支跳转时,分支延迟槽中执行的才是有意义的指令,因此程序得到的加速效果比从前调度稍差;另外,需要保证分支延迟槽中执行的指令在分支不跳转时,不会影响后续指令的正确性,这里的代码满足了该要求
# v4: specialized for delayed branch
.text # 将 16 进制数转为 10 进制数进行显示
main:
ADDIU $r8, $r0, 160 # r8 = 160 (0xA0) ; 要转换的数(半字,16位,小端对齐)存在内存地址 160 处
ADDIU $r9, $r0, 168 # r9 = 168 (0xA8) ; 转换完毕的数存在内存地址 168 处
LHU $r1, 0($r8) # r1 = memory[r8]
ADDIU $r10, $r0, 10 # r10 = 10
ADDIU $r4, $r0, 0
# fill branch delay slot from target
DIVU $r1, $r10
loop1:
MFHI $r2 # r2 = r1 % 10
MFLO $r1 # r1 /= 10
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
OR $r3, $r2 # r3 |= r2
BGTZ $r1, loop1 # while(r1 > 0)
DIVU $r1, $r10
SW $r3, 0($r9) # 存字
TEQ $r0, $r0
- 下面执行程序,发现此时停顿周期数只有 1,其中控制停顿与 RAW 停顿均已被完全消除。同时程序的总的执行周期数缩减到了 31 个时钟周期. 注意到相比从前调度,从目标处调度的方法在总时钟周期上增加了一个时钟周期,原因是程序中执行了 3 次循环,在最后一个循环时,分支语句不跳转,因此分支延迟槽中执行的命令其实是没有意义的,因此要多出一个时钟周期的开销


- 在下图中可以注意到,在分支指令还未决定是否跳转时,系统先执行分支延迟槽中的指令
DIVU $r1, $r10以填补计算分支指令是否跳转的时间间隔

从失败处调度
- 从失败处调度的代码与软件调度的代码相比没有区别,只需要设置开启分支延迟槽即可,这就相当于手动将分支不跳转时需要执行的指令
SW $r3, 0($r9)调度到了分支延迟槽中。这样当开启分支延迟槽时,在BGTZ $r1, loop1未决定是否跳转以及跳转的地址时,系统就会自动执行SW $r3, 0($r9)以避免产生 stall - 值得一提的是,采用从失败处调度的方法时,只有当分支不跳转时,分支延迟槽中执行的才是有意义的指令,因此程序得到的加速效果比从前调度稍差;另外,需要保证分支延迟槽中执行的指令在分支跳转时,不会影响后续指令的正确性,这里的代码满足了该要求
# v4: specialized for delayed branch
.text # 将 16 进制数转为 10 进制数进行显示
main:
ADDIU $r8, $r0, 160 # r8 = 160 (0xA0) ; 要转换的数(半字,16位,小端对齐)存在内存地址 160 处
ADDIU $r9, $r0, 168 # r9 = 168 (0xA8) ; 转换完毕的数存在内存地址 168 处
LHU $r1, 0($r8) # r1 = memory[r8]
ADDIU $r10, $r0, 10 # r10 = 10
ADDIU $r4, $r0, 0
# fill branch delay slot from fall through
loop1:
DIVU $r1, $r10
MFHI $r2 # r2 = r1 % 10
MFLO $r1 # r1 /= 10
SLLV $r2, $r2, $r4 # r2 左移 r4 位
ADDIU $r4, $r4, 4 # r4 += 4
OR $r3, $r2 # r3 |= r2
BGTZ $r1, loop1 # while(r1 > 0)
SW $r3, 0($r9) # 存字
TEQ $r0, $r0
- 下面执行程序,发现此时停顿周期数只有 1,其中控制停顿与 RAW 停顿均已被完全消除。同时程序的总的执行周期数缩减到了 32 个时钟周期. 注意到相比从前调度,从失败处调度的方法在总时钟周期上增加了两个时钟周期,原因是程序中执行了 3 次循环,前两个循环时,分支语句跳转,因此分支延迟槽中执行的命令其实是没有意义的,因此要多出两个时钟周期的开销

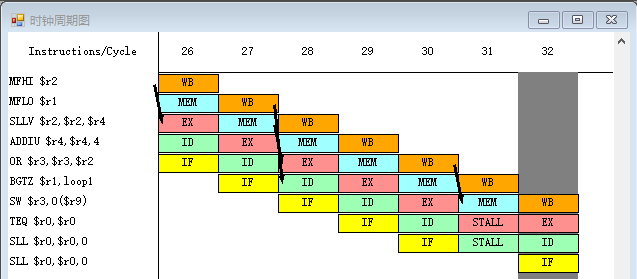
- 在下图中可以注意到,在分支指令还未决定是否跳转时,系统先执行分支延迟槽中的指令
SW $r3, 0($r9)以填补计算分支指令是否跳转的时间间隔

循环展开 + 分支延迟
- 下面采用循环展开 + 分支延迟 (从失败处调度) 的方法,代码于循环展开的代码相同,唯一区别是在配置中开启了分支延迟
- 下面执行程序,发现此时停顿周期数只有 1,其中控制停顿与 RAW 停顿均已被完全消除。同时程序的总的执行周期数缩减到了 28 个时钟周期. 这应该是目前能做到的最好的优化效果,因为每个时钟周期都执行的是有意义的指令,并且循环带来的开销也被降到了最低

4. Cache 性能分析
不同的 Cache 容量对不命中率的影响
- 选择不同的 Cache 容量,包括 2KB、4KB、8KB、 16KB、32KB、64KB、128KB 和 256KB。分别执行模拟器(单击“执行到底”按钮即可执行),然后在下表中记录各种情况下的不命中率

- 以容量为横坐标,画出不命中率随 Cache 容量变化而变化的曲线

- 根据该模拟结果,你能得出什么结论?
- 可以看到,增加 Cache 容量可以有效降低不命中率,同时当 Cache 容量增加到一定程度时,不命中率降低的效果也越来越不明显
- 不过,这种方法不但会增加成本还可能增加命中时间。这种方法在片外 Cache 中用得比较多
相联度对不命中率的影响
- (1)用鼠标单击“复位”按钮,把各参数设置为默认值。此时的 Cache 容量为 64KB
- (2) 选择一个地址流文件
- (3) 选择不同的 Cache 相联度,包括 2 路、4 路、8 路、16 路和 32 路。分别执行模拟器,然后在下表中记录各种情况下的不命中率

- (4)把 Cache 的容量设置为 256KB,重复(3)的工作,并填写下表

- (5)以相联度为横坐标,画出在 64KB 和 256KB 的情况下不命中率随 Cache 相联度变化而变化的曲线
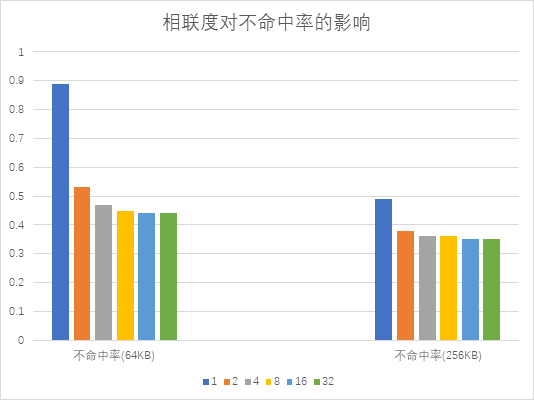
- (6)根据该模拟结果,你能得出什么结论?
- 增加相联度有助于降低不命中率
- 在增加相联度到 4 时,优化效果比较明显;继续增加相联度后优化效果不太明显
- 同时,更大的相联度也会增加命中时间和硬件复杂度
Cache 块大小对不命中率的影响
- (1) 用鼠标单击“复位”按钮,把各参数设置为默认值。
- (2) 选择一个地址流文件。
- (3) 选择不同的 Cache 块大小,包括 16B、32B、64B、128B 和 256B。对于 Cache 的各种容量,包括 2KB、8KB、 32KB、64KB、128KB 和 512KB。分别执行模拟器,然后在下表中记录各种情况下的不命中率
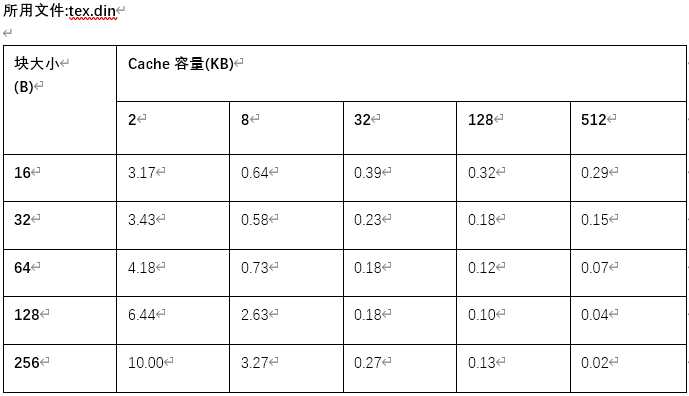
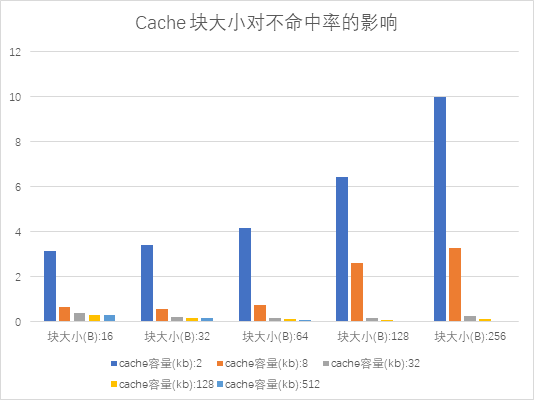
- (4)分析 Cache 块大小对不命中率的影响
- 可以看出,对于给定的 Cache 容量,当块大小从 16B 开始增加时,不命中率开始下降,但后来反而上升了。增加块大小会产生双重作用
- (1) 增加了空间局部性,减少了强制性不命中
- (2) 减少了 Cache 中块的数目,所以有可能增加冲突不命中
- 在块比较小的情况下,上述的第一种作用会超过第二种作用,从而使不命中率下降。但等到块较大时,第二种作用超过了第一种作用,反而使不命中率上升了,所有选择块大小时,要综合考虑各方面的因素
- 可以看出,对于给定的 Cache 容量,当块大小从 16B 开始增加时,不命中率开始下降,但后来反而上升了。增加块大小会产生双重作用
替换算法对不命中率的影响
- (1) 用鼠标单击“复位”按钮,把各参数设置为默认值
- (2) 选择地址流文件 all. din
- (3) 对于不同的替换算法、Cache 容量和相联度,分别执行模拟器,然后在下中记录各种情况下的不命中率
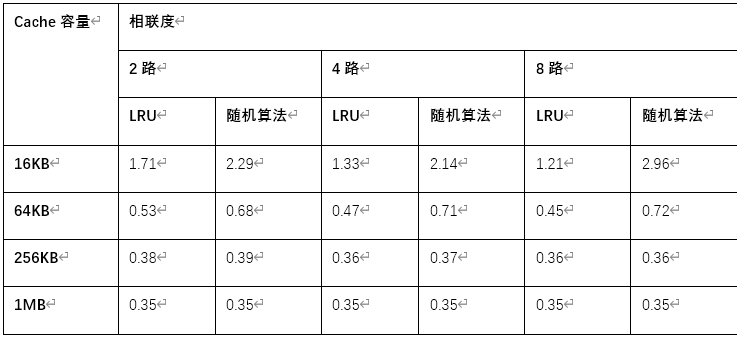
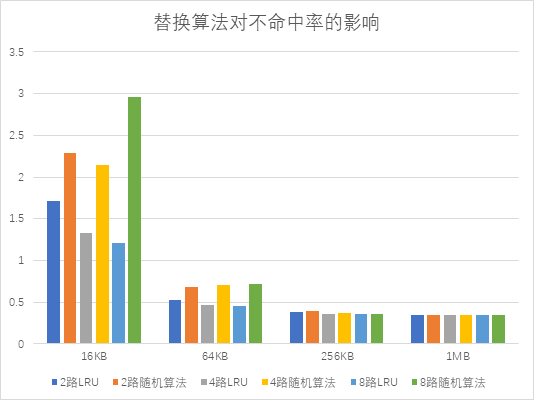
- (4)分析不同的替换算法对 Cache 不命中率的影响
- 当 Cache 容量较小时 (16 KB, 64 KB),LRU 替换算法优于随机算法
- 当 Cache 容量较大时 (256 KB, 1 MB),LRU 替换算法与随机算法效果差不多
5. Tomasulo 算法
- 各功能部件的执行时间如下:

- 执行的指令序列如下:
CC 代表 Clock
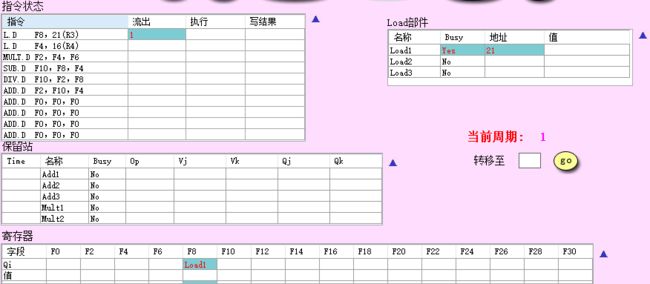
- CC1: 第一条指令流出,对应的保留站状态变为 Busy,由于有效地址还未计算出,因此地址暂时为立即数偏移量;同时对应的寄存器的 Q i Q_i Qi 字段记录将要写该寄存器的保留站号
- CC2: 无结构冲突,因此第二条 load 指令顺利发射;同时第一条指令已经计算出了有效地址
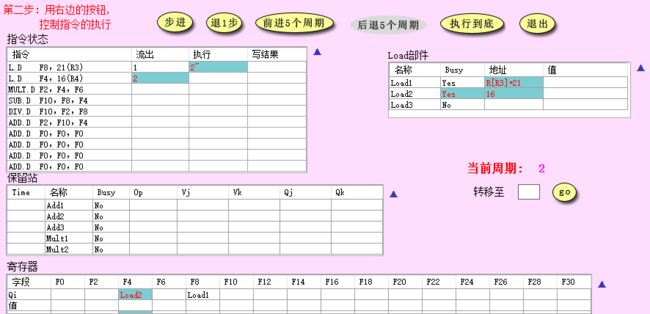
- CC3:无结构冲突,因此第 3 条乘法指令顺利发射进入对应的保留站,保留站中记录其操作码,同时读到了寄存器 F6 的值,注意到这里存在 RAW 冲突,F4 的值还未写入,因此 V j V_j Vj 为空,由 Q j Q_j Qj 记录将要写 F6 的保留站名;同时第一条 load 指令已经从内存中读出了值,第二条 load 指令也计算出了有效地址

- CC4: 第一条 load 指令将从内存中读到的数写回寄存器 F8,指令执行完成,Busy 状态更新为 No;第二条 load 指令计算出了有效地址;第 3 条指令由于产生了 RAW 冲突,需要继续等待 load2 的完成;第 4 条指令由于无结构冲突,被顺利发射出来
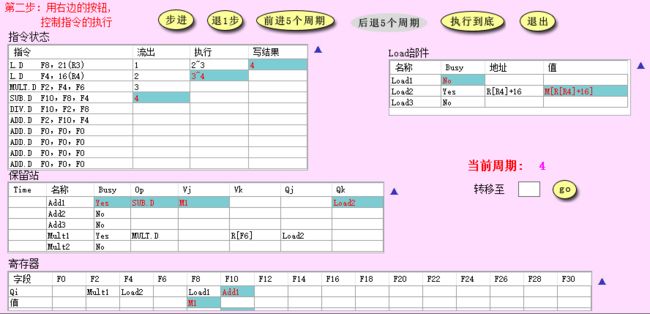
- CC5: load2 执行完成,将从内存中读到的数发往 CDB,在写入 F4 的同时,Add1 和 Mult2 也从总线上得到了 load2 的结果 (F4 的值),于是更新对应的 V i V_i Vi 或 V j V_j Vj 为 F4 的值,清空对应的 Q i Q_i Qi 或 Q j Q_j Qj;同时除法指令由于没有结构冲突,也被发射了出来

- CC6: Add1 和 Mult1 得到了源操作数,开始执行;同时加法指令由于没有没有结构冲突,也被发射了出来
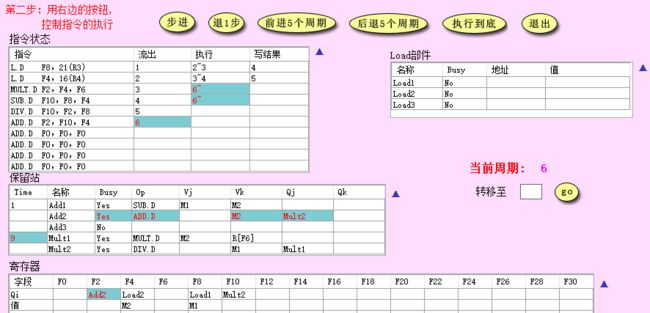
- CC7: 发射第 7 条加法指令
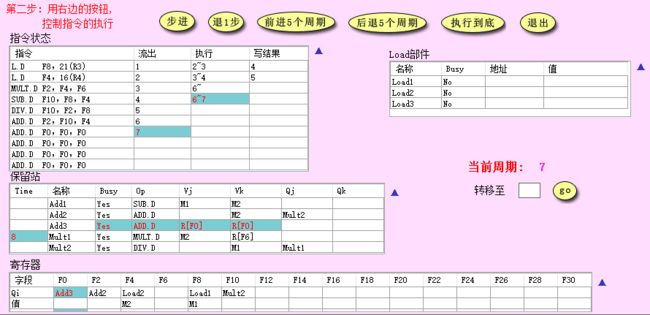
- CC8: 发射第 8 条加法指令,同时减法指令执行完毕

- CC9: 注意到这里产生了结构冲突:加法指令没有了足够多的保留站,因此无法发射下一条加法指令
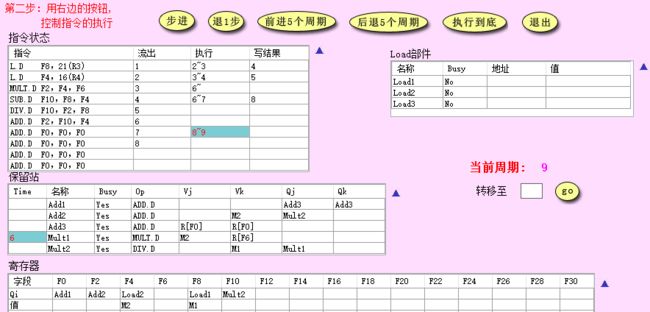
- CC10: 一条加法指令执行完成,此时才能继续发射下一条加法指令
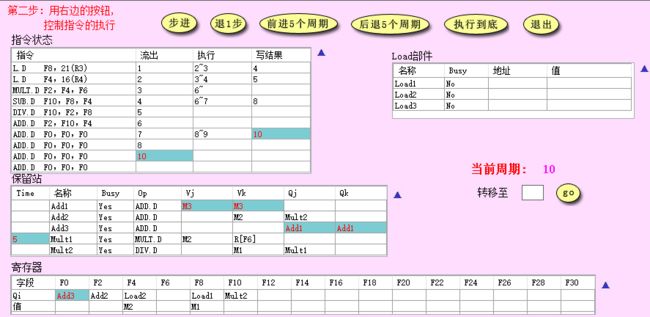
- 之后的分析与上面类似。执行结束后可以观察到,所有指令都是顺序发射、乱序执行、乱序完成的;而且通过上面的分析,可以知道,在 Tomasulo 算法中,结构冲突是通过在发射时检查是否有空余的保留站,如果没有则暂时不发射来解决的;RAW 冲突是通过在保留站的 Q i Q_i Qi 或 Q j Q_j Qj 中记录提供数据的保留站名,等到对应指令执行完毕将数据发送到 CDB 上时就能得到想要的源操作数;WAW 和 WAR 冲突都是通过利用保留站换名来解决的

6. 再定序缓冲(ROB)工作原理
- 各功能部件的执行时间如下:
- 执行的指令序列如下:
- ROB 的执行流程与 Tomasulo 很类似,下面只介绍它与 Tomasulo 不同的地方
- 首先可以看到,它与 Tomasulo 最大的不同就是增加了再定序缓冲器
- 再定序缓冲器相当于一个循环队列,用 HEAD 和 TAIL 来标记队列的首尾,每次都只能提交队列首的指令,而新加入的指令都只能放入队列尾,这样就保证了顺序提交,实现了精准中断
- 同时如果有预先执行完毕但不该执行的语句 (可能因为分支预测错误),则可以很方便的通过 ROB 清空它们而不提交,以免影响程序的正确性。这样就能消除控制相关
- 因为指令在执行完成后不直接将结果写入寄存器,因此 ROB 还负责在指令完成到指令提交这一阶段为其他指令提供数据。此外,保留站中记录的目的地以及 Q j , Q k Q_j,Q_k Qj,Qk 都变成了 ROB 的项号,这意味着保留站中的指令执行完毕后会直接写入 ROB 而非寄存器,并且保留站在遇到 RAW 冲突时,会在 CDB 上监听写往 ROB 指定项号的数据以获得想要的源操作数
- 如下图所示,保留站 Mult1 的目的地址为 #3,即保留站中记录的对应指令项号,而 Q j Q_j Qj 为 #2,即第二条 load 指令在保留站中的项号,如果第二条 load 指令完成,对应的 load 缓冲器就会向 CDB 发数据,目标地址为它对应的 ROB 项号 #2,此时 Mult1 就能得到它想要的源数据
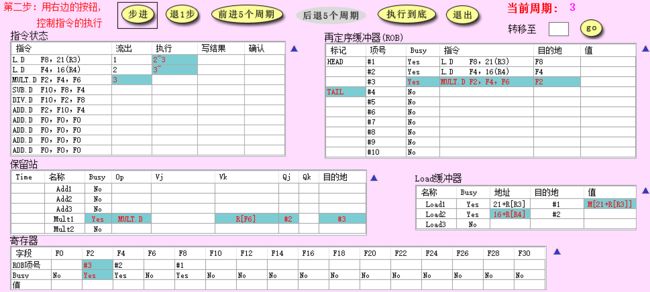
- ROB 其余的执行流程与 Tomasulo 一样
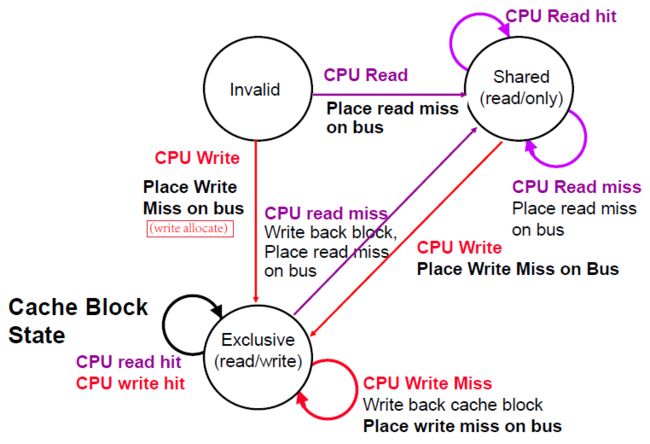
7. 多 Cache 一致性—— 监听协议
- 下面主要针对状态转换图中的每种状态转换进行实验:
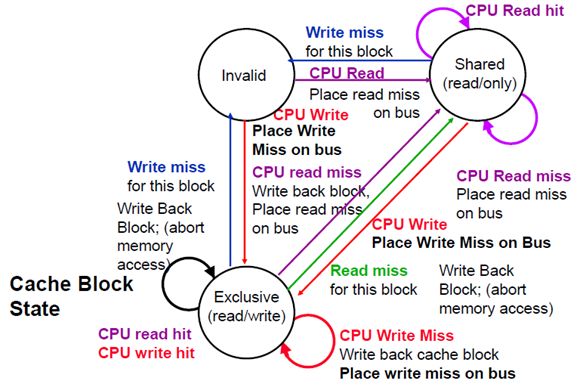
- 首先实验 CPU 读写对状态转移的影响:
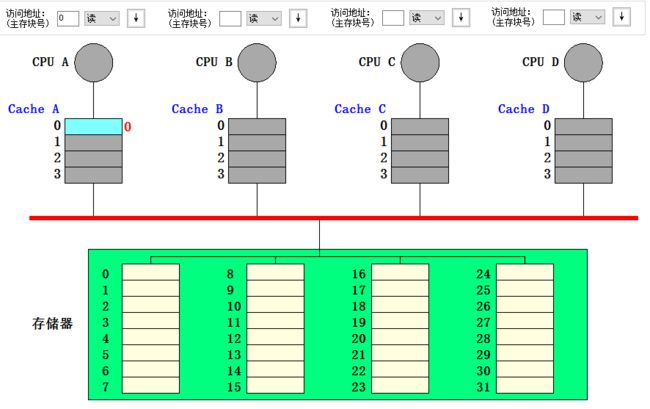
- CPU A 读块 0,由于是直接映射,且 Cache A 的行 0 状态为无效,因此 CPU 向总线上发 Read miss 信号,最后从主存中读出块 0,Cache A 的行 0 状态变为共享
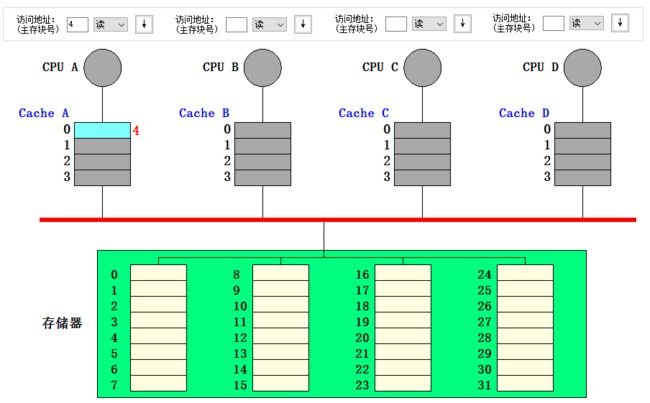
- CPU A 继续读块 0,由于 Cache A 的行 0 状态为共享且标记为块 0,因此读命中
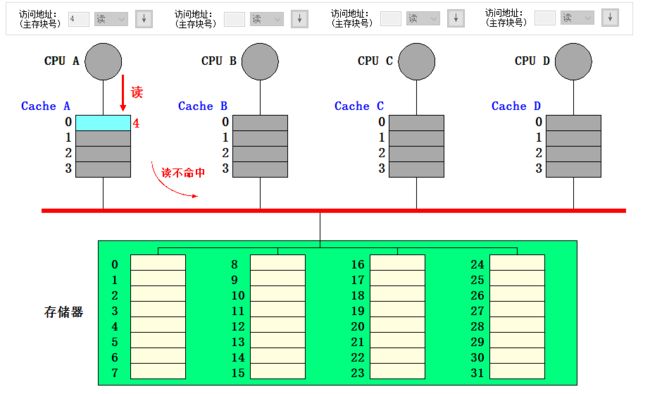
- CPU A 读块 4,由于 Cache A 的行 0 状态为共享但标记为块 0,因此读失效,CPU A 向总线发 read miss 信号,将块 4 读入行 0
- CPU A 写块 4,向总线发 write miss 信号,同时行 0 的状态变为独占;

- 此时不管是写块 4 (write hit) 还是读块 4 (read hit),都是直接读写 Cache 中的数据,且 Cache 行的状态保持为独占
- 此时如果写块 0,由于 Write miss 且行 0 为独占状态,CPU A 会先将行 0 中的数据写回主存的块 4,然后向总线发 Write miss 信号,并读入块 0;此时行 0 仍为独占状态

- 此时如果读块 4,由于 read miss,CPU A 会先将行 0 中的数据写回主存的块 0,再向总线发 read miss 信号并读入块 4,此时行 0 变为共享状态
- 现在进行复位。CPU A 的 Cache 行 0 状态变为无效。此时写块 0,CPU A 向总线发 Write miss 信号,同时读入块 0,行 0 的状态变为独占
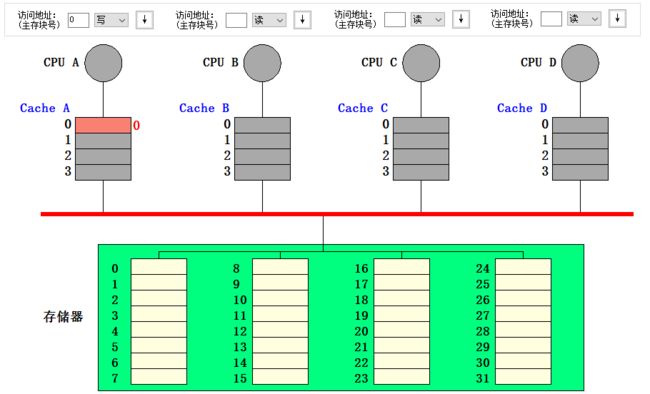
- 最后实验总线上的信号对状态转移的影响 (接着刚才的状态进行实验)
- CPU B 写块 0,向总线发 Write miss 信号。CPU A 在监听到该信号后,将行 0 (对应块 0) 写回到存储器的块 0 中,CPU A 的行 0 状态变为无效
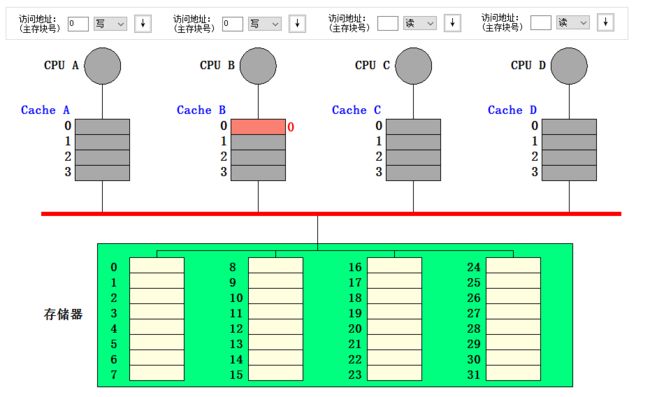
- 此时 CPU A 读块 0,像总线发出 read miss 信号。CPU B 在监听到该信号后,主动将自己 Cache 的行 0 中的数据提供给 CPU A,同时将行 0 写入内存的块 0,CPU B 的行 0 的状态变为共享 (模拟器中的动画展示的是 CPU B 先将行 0 写到内存,CPU A 再从内存中读取数据,但我觉得实际的流程应该是我之前描述的)
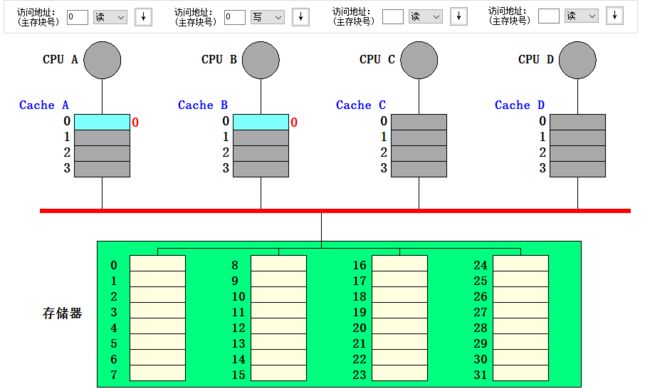
- 此时 CPU B 写块 0,向总线发 Write miss 信号,CPU A 监听到该信号后将行 0 的状态变为无效

8. 多 Cache 一致性—— 目录协议
- 目录协议与监听协议主要的思想差不多,最大的不同就是监听协议采用分布式控制,而目录协议采用集中式控制。在目录协议中,宿主表示存储单元和用于记录共享集合的目录,本地表示发送访存请求的 CPU 的 Cache,远程表示含有对应主存副本的 CPU 的 Cache
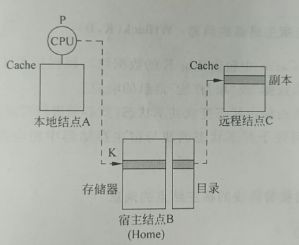
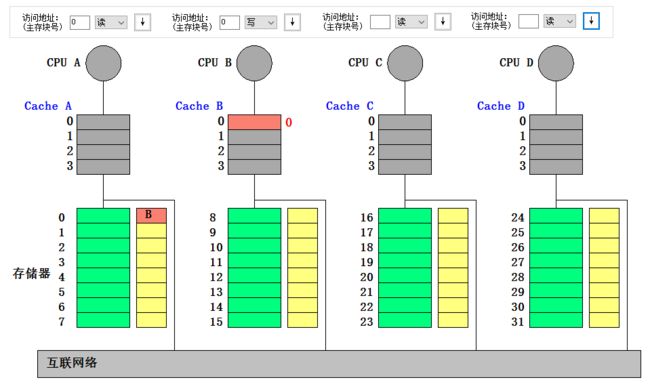
- CPU A 读主存块 0:读不命中。于是本地向宿主结点发读不命中(A,0)消息,宿主把数据块送给本地结点,同时更新共享集合为 {A},最后 Cache A 把第 0 块的内容送给 CPU A

- CPU B 读主存块 0:读不命中。于是本地向宿主结点发读不命中(B,0)消息,宿主把数据块送给本地结点,同时更新共享集合为 {A, B},最后 Cache B 把第 0 块的内容送给 CPU B (这里本地与宿主的通信需要经过互连网络)

- CPU B 写块 0:写命中。本地向宿主结点发写命中(B,0)消息,宿主查询共享集合,向共享集合内除 B 以外的结点发作废(0)消息,然后将共享集合更新为 {B}。最后 CPU B 把新数据写入 Cache B 行 0
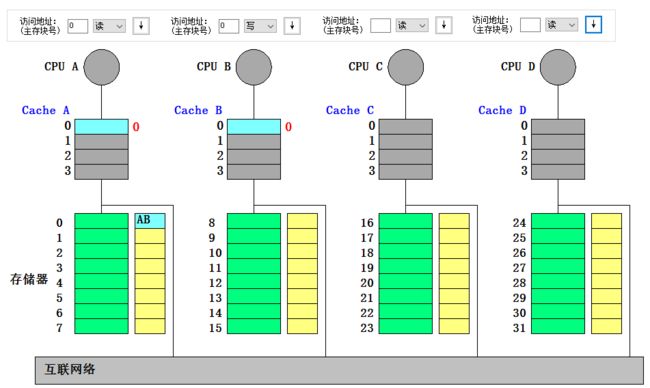
- CPU A 读块 0:读失效。本地向宿主结点发读不命中(A,0)消息,宿主给远程结点发取数据块(0)的消息,远程把数据块送给宿主结点,宿主把数据块送给本地结点,并更新共享集合为 {A,B};最后 Cache A 把第 0 块的内容送给 CPU A
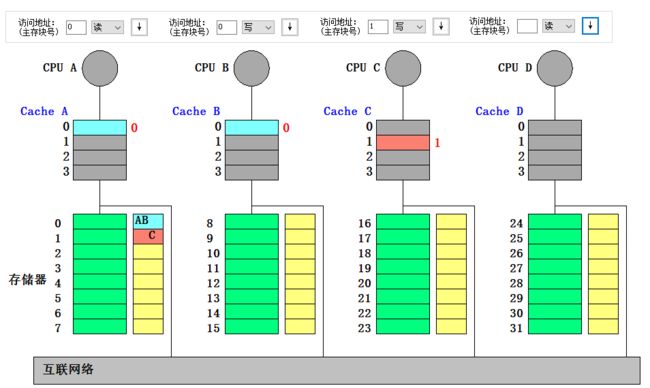
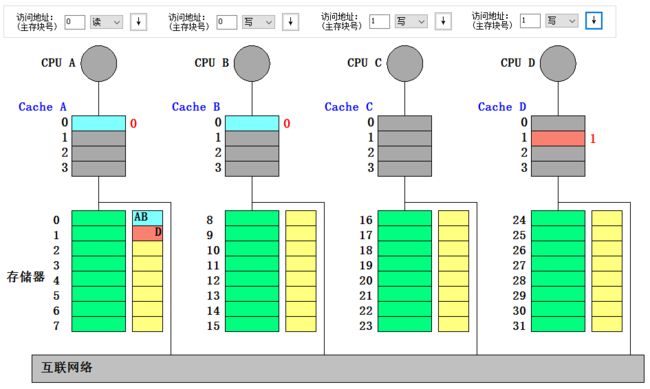
- CPU C 写块 1: 写不命中。本地向宿主结点发写不命中(C,1)消息, 宿主把数据块送给本地结点并更新共享集合为 {C},最后 CPU C 把新数据写入 Cache C 行 1
- CPU D 写块 1: 写不命中; 本地向宿主结点发写不命中(D,1)的消息,宿主给远程结点发送取并作废(1)的消息,远程把数据块送给宿主结点,把 Cache 中的该行作废,宿主把把数据块送给本地结点并更新共享集合为 {D},最后 CPU D 把新数据写入 Cache D 行 1
- CPU D 读块 5: 读不命中。本地向被替换的宿主结点发写回并修改共享集(D,1)消息,本地向宿主结点发读不命中(D,5)消息,宿主把数据块送给本地结点并更新共享集合为 {D},Cache D 把第 5 块的内容送给 CPU D