GAMES202 Real-time Shadows
文章目录
- 前言
- Lecture 1
- Lecture 2 基础图形学知识回顾
-
- 基本的渲染管线
- OpenGL
- 着色语言(shading language)
- Debugging Shaders
- 渲染方程(The Rendering Equation)
- Lecture 3 Real-time Shadows 1
-
- 普通阴影渲染的问题
- PCSS(Percentage closer soft shadows)
-
- Percentage Closer Filtering (PCF)
- PCSS
- Lecture 4 Real-Time Shadows 2
-
- Variance soft shadow mapping
-
- VSSM 流程梳理
- 快速求均值
- Moment shadow mapping
- SDF
前言
课程录播:
https://www.bilibili.com/video/BV1YK4y1T7yY?p=5
课程主页:
https://sites.cs.ucsb.edu/~lingqi/teaching/games202.html
课程BBS:
http://games-cn.org/forums/forum/games202/
Lecture 1
一般达到 30 FPS(frames per second)就叫 real time 的。而有的领域比如 VR/AR 甚至要求要 90 FPS.
interactive FPS 一般则要求低一些。
这门课的四个话题:

Neural Rendering:

目前而言,只要用到神经网络,基本上就不能 real time 和 high quality(因为很多神经网络出来的东西,需要手调,手调就是比如做出10000张结果,选出有1000张最好的,这个做法叫 cherry picking)。所以这部分基本不会提。
科普的概念:AoE(Anywhere on Earth)
怎么判断画面是否好:看画面是否明亮
Lecture 2 基础图形学知识回顾
基本的渲染管线

OpenGL
CPU端执行,负责调度GPU(安排GPU应该干什么)。OpenGL本身拿什么语言写一点关系也没有,我们更关心GPU是怎么执行。
坏处:C风格,没有面向对象一说;很碎片化(有多个不同的版本)。
步骤(类比油画):
- 放置物体/模型
- 设置画架的位置
- 在画架上贴上画布
- 画在画布上
- (如果想画更多的东西,把这块画布扯下来换成别的画布接着画)
- (之前画过的画,在后续的过程可以拿来使用)

回到 OpenGL(比如要渲染 3D 场景):
A. 把物体和模型放在特定的位置,模型该如何摆放
如何确定模型呢?通过 Vertex buffer object (VBO),即GPU上的一块区域,用来存储模型。存储的时候就是存一堆顶点的位置、法向、连接方式、UV坐标等。即以一定的格式组织了物体应该放在GPU的哪。和.obj非常相似。
如何摆放,通过一些矩阵给出位置,如 glTranslate、glMultMatrix 等。
B. 放置画架
这里体现了两个东西:一是视图变换(即放置相机,正交 or 透视投影,例如函数 gluPerspective),二是framebuffer,即用哪个画架。
C. 固定画布、E. multiple render target
用一个 framebuffer,可以指定它输出很多不同的纹理。一个特殊的渲染目标是直接渲染到屏幕(现在一般不推荐,一般有双重缓冲三重缓冲)
D. 画在油画上
如何表现着色。顶点/片段 着色器。
可以自己写深度测试,OpenGL也会自动地帮你做深度测试。

当所有东西都在GPU之后才开始渲染(立即模式除外)。
着色语言(shading language)

上古时代:在GPU上写汇编。
之后诞生了着色语言,编译成 GPU 上的汇编。
流程:

创建好顶点着色器和片段着色器后就是编译,然后会 attach shader to program,所谓program就是集合了写的所有自定义的shader,然后做一个着色器之间的链接,就是去看比如顶点和片段着色器之间对不对的上。最后告诉OpenGL要用这一套着色器(即链接了的这些程序)。
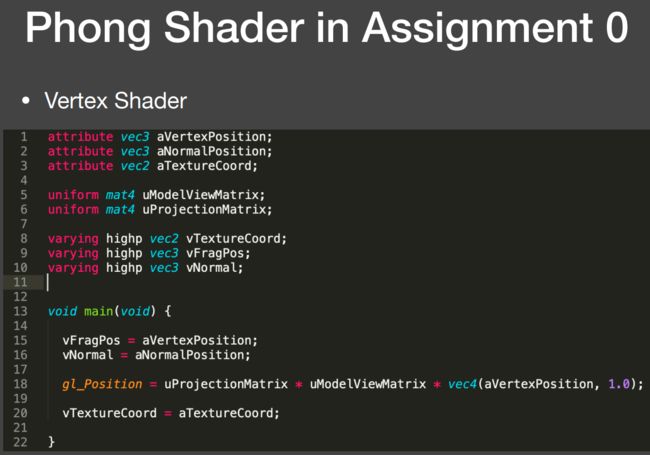
attribute:顶点的属性(因此只有顶点着色器有这个关键字,在建立VBO就有了,这里告诉是顶点的位置、法线、UV)。
varying:顶点着色器要写好并送给片段着色器的东西。这些量到了fragment shader是已经被插值好了的(因此片段着色器也要有一一对应的量)。
uniform:全局变量。直接从 CPU 丢到 GPU 的。
highp 是定义的精度,暂时忽略它。
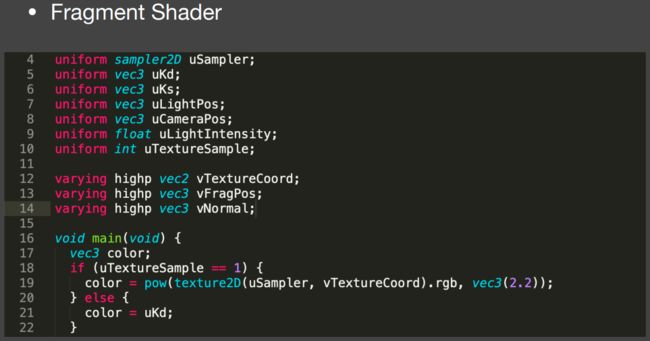
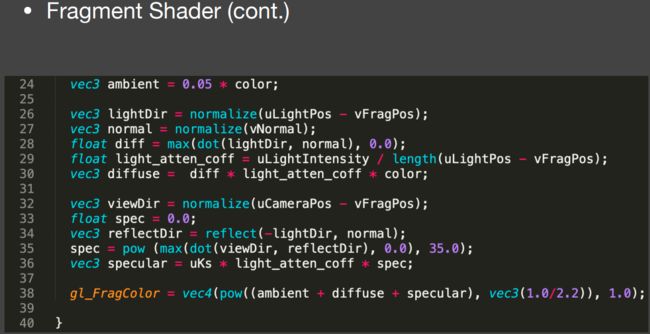
Debugging Shaders
若干年前很困难。因为在 GPU 端运行。
现在:

老师的经验:把值当成颜色,然后显示出来。
渲染方程(The Rendering Equation)
我的笔记:https://zhuanlan.zhihu.com/p/427854383


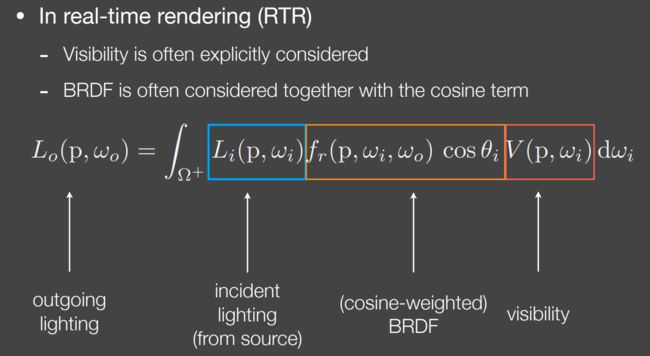
RTR中,说BRDF有可能是BRDF,也有可能是BRDF和那个cosine term在一块。还有一个就是引入了visibility可见性这样的概念。
其实这个和之前的渲染方程是一样的(但是去掉自发光项),这里的 incident lighting 加上 visibility 一块其实就是前面的 incident radiance。只不过 RTR 中喜欢显示地拆出来。
Lecture 3 Real-time Shadows 1
普通阴影渲染的问题
普通的 2-Pass shadow mapping 缺点:自遮挡现象与走样现象(self occlusion and aliasing issues)
比如下图,由于数值精度的问题地上有一圈一圈的黑纹(这不是摩尔纹)。因此需要加一个 bias
但是 bias 过大了会丢失一些本来应该有阴影的问题。

还有就是走样:

实时渲染常见的一个约等式:

例如渲染方程的简化(并且我们还能分析出对于点光源(只有一个点)和方向光(只有一个方向)都是准的):

PCSS(Percentage closer soft shadows)
面光源->半影(Penumbra):

Percentage Closer Filtering (PCF)
不是作软阴影的,是用来解决走样问题的。这里的 filter 既不是对已有阴影作filter也不是对shadow map进行filter。
之前普通渲染阴影是把 shading point 对 shadow map 中的一个像素进行深度比较(非0即1),PCF 则是把这个 shading point 和 shadow map 周围一圈的像素进行深度比较,比出来的一些 0/1 的结果再取一个平均(这个最终结果应该可以当作半透明值):

因此他没有对shadow map或者最终结果做一个模糊,而是对和shadow map那一小个区域的比较结果做了一个 filter
pcf 本来要调最终那个比较的参数来得到一个较好的结果,但是后来人们就在想用到软阴影上去。
PCSS
软阴影,思考之前那个半影的图,其实和阴影接受物的某个位置到阴影投射物的对应位置是近还是远有关。因此我们就想用根据这个距离值(我们叫做 blocker distance)来定义不同的 Filter size。这里的 Filter size 其实就是和 Wpenumbra 正相关的,例如 shading point 离 blocker 越近(例如上图的笔尖)阴影理应越硬,那么就不应该用很大的 Filter size(即 pcf 的搜索区域范围),而 Wpenumbra 越大则表示 shading point 离 blocker 越远,因此应该用很大的 Filter size
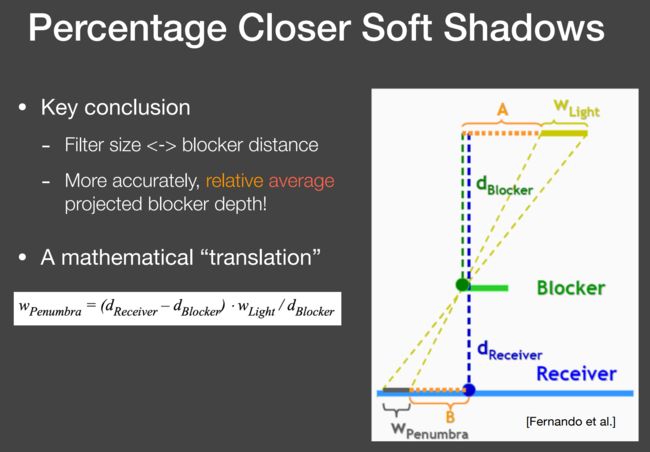
(注:面光源肯定不能搞一个shadow map出来,所以大家常先用点光源生成一个shadow map,再根据面光源参数来确定阴影的软硬)
PCSS流程:
- 对shading point,找到对应的shadow map的那个像素,然后对这个像素周围的一块区域进行比较(比如 5 * 5,或者更好的用面光源的参数来算,如下图):若在阴影中则标记为blocker,然后对这些 blocker 取平均(如果被遮挡的话,shadow map记录的深度也就是 blocker 的深度了)

- 有了 blocker 的深度,我们就可以计算 filter 有多大,然后就回到了 PCF 的流程了。
Lecture 4 Real-Time Shadows 2
Variance soft shadow mapping
PCSS因为要多次采样,太慢了,于是出来了 Variance soft shadow mapping(VSMM),其实际上可以看成 PCSS 的快速版本,不过现在降噪手段越来越多,大家还是PCSS用的多一点?
VSMM的思想是,我不需要那么精准的数据,我只需要大概知道我的 shading point 对应的 shadow map 那一段采样区域内的平均值大概排什么水平(之前PCF的时候说过shadow map一块区域都会和shading point的深度值进行非零即一的比较),我们直接假设这一段分布是正态分布的,要获得正态分布的曲线我们只需要求均值和方差即可。
对shadow map的一个矩形区域快速求均值可以用 mipmap 或者 summed area tables(SAT)
那么求方差只需要按方差公式即可:

因此我们还需要额外的一张shadow map(其实可以直接记录在一张 RT 的不同的通道里,在生成shadow map的时候顺手往其他通道写入深度平方的数据)。
而有了均值方差之后,我们接着就是根据pcf的那个平均值,求出对应的 CDF 值(如下图),也就知道了有百分之多少的地方比我的深度小。
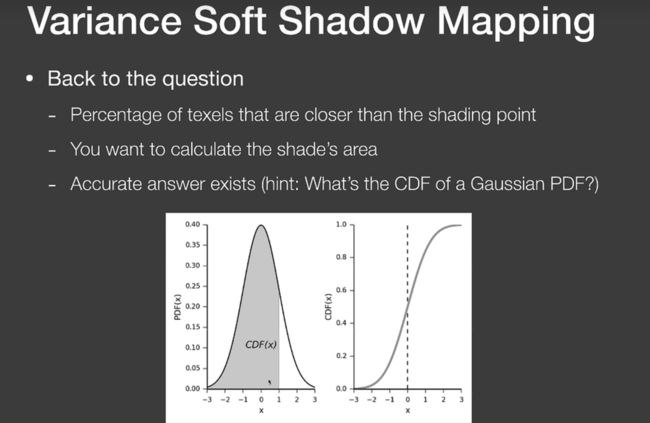
而这个积分求解可以直接通过读表来做,但其实VSMM用的是切比雪夫不等式(也就没有用正态分布公式了实际上):
重新回到PCSS流程,我们还需要知道 Blocker 的深度距离,我们应该用那一块区域内的遮挡深度求平均。
VSSM 流程梳理
例子:shading point 深度为7,PCSS 第一步的范围为 5 * 5,这个shadow map在该范围内的深度值如下图:

(这里假设可以通过 mipmap 或者 summed area tables(SAT)得到一个矩形区域内的深度平均值或者深度的方差)
- 第一个 pass,我们要生成 shadow map,生成的同时把深度的平方写入第二个通道
- 这一步实际上是优化PCSS的求bloker的步骤:获取shading point的深度值(假设为7)。我们有了这个 55 矩形的深度平均值,我们假设大于shading point的那些深度值都为7(即上图红色的所有值我们都当作7来算,再根据这个55内的深度平均值算出遮挡物的深度:

其实就是,PCSS第一步希望求 Zocc (即蓝色区域平均值),我们先假设 Zunocc 直接为 shading point 的深度值,然后通过该 5*5 矩阵的平均深度来计算出 Zocc,从而求出 PCSS 第一步的所需的那个 blocker distance (这样就避免了采样) - PCSS第二步,根据 blocker distance 计算出需要采样区域的大小(PCF 的 filter 的大小)。
- 对于第三步得出的区域(假设 7 * 7),得出这个区域的深度均值与方差,由切比雪夫不等式,可以知道这个区域大于shading point的深度的概率,也即 PCF 要求的那个值了。
快速求均值
之前说了可以用 mipmap 或者 summed area tables(SAT),用 mipmap 如果矩阵不是2的幂之类的就势必要双线性或是三线性插值,不太方便;我们可以用 summed area tables(SAT),就是一个经典的二维前缀和罢了?不过构建的时候原本是 O(n)的复杂度,但是可以写成并行去构建。
Moment shadow mapping
之前的 VSSM 存在的问题是,如果真正的分布并不那么正态,如下图,那么还用正态分布去描述的话就会出问题(阴影黑一点倒是没啥,人们不希望的是阴影突然变白了):
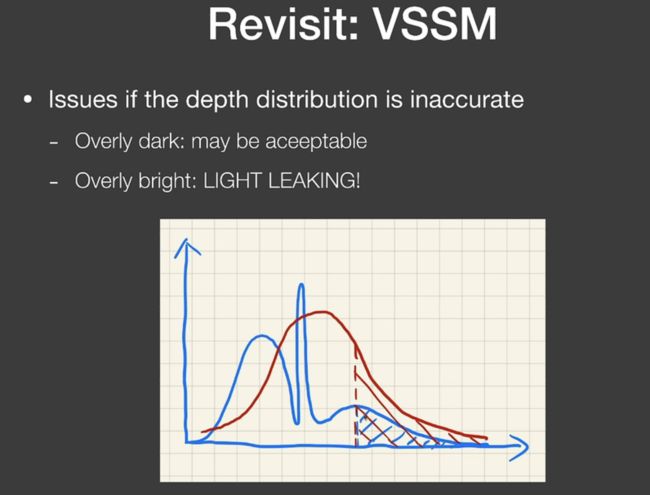
因此人们想要VSSM对遮挡分布的描述更准,于是引入更高阶的moments:

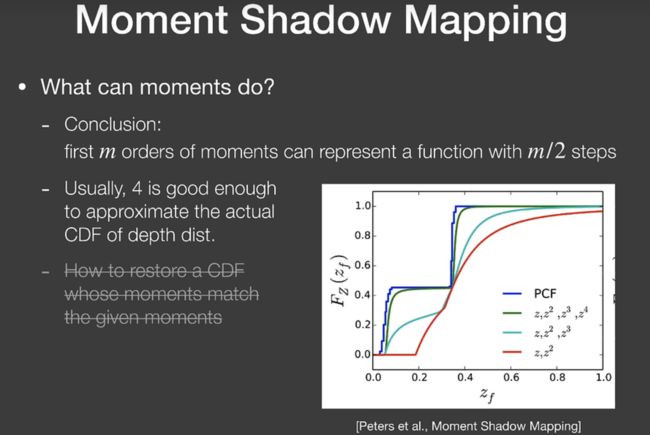
其实就是某个展开而已。
SDF
我的笔记:
https://zhuanlan.zhihu.com/p/398656596?