SpringCloud Alibaba-Sentinel保姆级教程
文章目录
- 1、Sentinel前奏
-
- 1.1、服务雪崩效应
- 1.2、常见容错方案
-
- 1、隔离
- 2、超时
- 3、限流
- 4、熔断
- 5、降级
- 1.3、常见容错组件
-
- 1、Hystrix
- 2、Resilience4J
- 3、Sentinel
- 2、Sentinel入门
-
- 2.1、什么是Sentinel
- 2.2、实战编码
-
- 1、安装Sentinel服务端
- 2、微服务引入Sentinel
- 2.3、Sentinel流控模式
-
- 1、直接
- 2、关联
- 3、链路
- 2.4、Sentinel流控效果
-
- 1、快速失败
- 2、Warm Up预热
- 3、排队等待
- 2.5、热点规则
-
- 1、参数限流
- 2、参数值限流
- 2.6、系统规则
-
- 1、配置全局限流规则
- 3、Sentinel服务熔断
-
- 3.1、编码实战
-
- 1、资源熔断降级
- 2、配置降级策略
- 6.3、降级策略
-
- 1、平均响应RT
- 2、异常比例
- 3、异常数
- 6.4、OpenFeign兼容Sentinel
-
- 1、添加依赖
- 2、开启Sentinel
- 3、Feign接口降级
- 4、测试
- 4、Sentinel和Hystrix区别
- 总结
1、Sentinel前奏
1.1、服务雪崩效应
- 在分布式系统中,由于网络原因或自身的原因,服务一般无法保证 100% 可用
- 如果一个服务出现了问题,调用这个服务就会出现线程阻塞的情况,此时若有大量的请求涌入,就会出现多条线程阻塞等待,进而导致服务瘫痪
- 由于服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是雪崩效应
如下图所示:
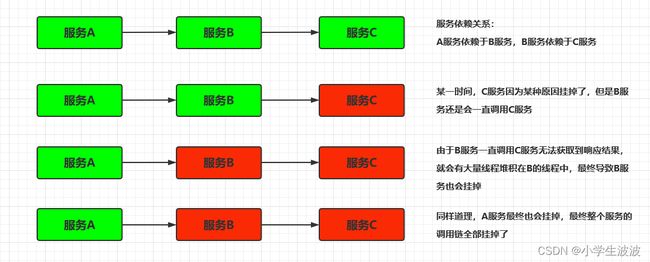
- 雪崩发生的原因多种多样,有不合理的容量设计,或者是高并发下某一个方法响应变慢,亦或是某台机器的资源耗尽
- 我们无法完全杜绝雪崩源头的发生,只有做好足够的容错,保证在一个服务发生问题,不会影响到其它服务的正常运行
- 也就是雪落而不雪崩
1.2、常见容错方案
要防止雪崩的扩散,就要做好服务的容错,容错说白了就是保护自己不被猪队友拖垮的一些措施, 下面介绍常见的服务容错思路和组件
常见的容错思路有隔离、超时、限流、熔断、降级等这几种,下面分别介绍一下:
1、隔离
- 它是指将系统按照一定的原则,划分为若干个服务模块,各个模块之间相对独立,无强依赖
- 当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其它模块,不影响整体的系统服务
- 常见的隔离方式有:线程池隔离和信号量隔离(Hystrix支持这两种隔离方式)

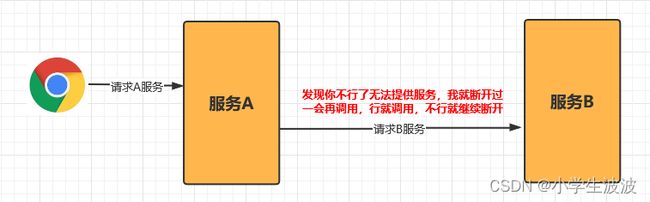
2、超时
在上游服务调用下游服务的时候,设置一个最大响应时间,如果超过这个时间,下游未作出反应,就断开请求,释放掉线程,如下图所示:

3、限流
- 限流就是限制系统的输入和输出流量,以达到保护系统的目的
- 为了保证系统的稳固运行,一旦达到的需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的

4、熔断
- 在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用
- 这种牺牲局部,保全整体的措施就叫做熔断
学过Hystrix的小伙伴们应该都知道,服务熔断一般有三种状态:
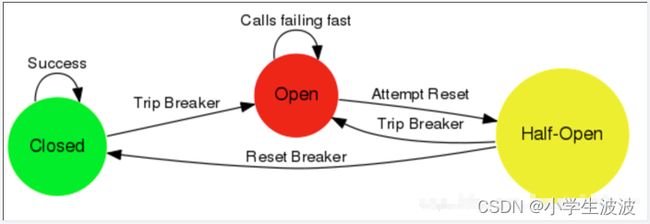
1、熔断关闭状态(Closed)
默认是关闭状态。服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
2、熔断开启状态(Open)
后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法
3、半熔断状态(Half-Open)
尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断关闭状态。
5、降级
降级其实就是为服务提供一个托底方案,一旦服务无法正常调用,就使用托底方案返回数据,不至于在你这个环节一直卡主

1.3、常见容错组件
1、Hystrix
Hystrix是由Netflflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提升系统的可用性与容错性
2、Resilience4J
Resilicence4J一款非常轻量、简单,并且文档非常清晰、丰富的熔断工具,这也是Hystrix官方推荐的替代产品。不仅如此,Resilicence4j还原生支持Spring Boot 1.x/2.x,而且监控也支持和prometheus等多款主流产品进行整合
3、Sentinel
Sentinel 是阿里巴巴开源的一款断路器实现,本身在阿里内部已经被大规模采用,非常稳定强大
下面是三个组件在各方面的对比:

2、Sentinel入门
2.1、什么是Sentinel
- Sentinel (分布式系统的流量防卫兵) 是阿里开源的一套用于服务容错的综合性解决方案
- 它以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来保护服务的稳定性
- Sentinel是通过限制并发线程的数量(即信号隔离)来减少不稳定资源的影响,而不是使用线程池,省去了线程切换的性能开销
Sentinel具有以下特征:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等
- 完备的实时监控:Sentinel 提供了实时的监控功能。通过控制台可以看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况
- 广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 SpringCloud、Dubbo、gRPC 的整合。只需要引入相应的依赖并进行简单的配置即可快速地接入Sentinel
- 完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo /Spring Cloud 等框架也有较好的支持
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器
2.2、实战编码
1、安装Sentinel服务端
Sentinel 提供了现成的服务端,https://github.com/alibaba/Sentinel/releases
这里我给大家准备好了,直接去下载即可
网盘连接:
链接:https://pan.baidu.com/s/1YJLfYmPsbii-zSHk6VWGRw
提取码:3065
OK,大家下载之后,可以通过命令行启动,使用cmd命令启动sentinel
java -jar -Dserver.port=1111 sentinel-dashboard-1.6.0.jar
- -Dsentinel.dashboard.auth.username=sentinel: 用于指定控制台的登录用户名为 sentinel;
- -Dsentinel.dashboard.auth.password=123456: 用于指定控制台的登录密码为 123456;如果省略这两个参数,默认用户和密码均为 sentinel
- -Dserver.servlet.session.timeout=7200: 用于指定 Spring Boot 服务端 session 的过期时间,如 7200 表示 7200 秒;60m 表示 60 分钟,默认为 30 分钟;
- -Dserver.port=1111:配置端口
启动成功的界面:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wghNPhrM-1666618011365)(images/image-20220213155559309-16661579811431.png)]
访问:http://localhost:1111 进入控制台,登录账号密码: sentinel/sentinel

注意:只有1.6.0及以上版本才有这个登录页面。
登录成功后的主页面效果如下:

目前还什么都没有做,所以这里是一片空白
那目前我们就将Sentinel服务端准备完毕了,接下来开始在微服务中引入Sentinel
2、微服务引入Sentinel
我们在用户服务的pom.xml中引入Sentinel:
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
然后在yml中配置Sentinel:
server:
port: 1011
spring:
application:
name: user-server
cloud:
# sentinel相关配置
sentinel:
transport:
dashboard: 127.0.0.1:1111
nacos:
#注册中心相关配置
discovery:
server-addr: 127.0.0.1:8848 #注册中心地址
#配置中心相关配置
config:
server-addr: 127.0.0.1:8848 #配置中心地址
file-extension: yaml #配置文件格式
prefix: application-user #配置前缀
group: DEFAULT_GROUP #默认分组
profiles:
active: dev #指定环境
Sentinel为我们提供了@SentinelResource注解标记需要限流的资源
我们来测试一下,在UserController中做修改,如下:
package cn.wujiangbo.controller;
import cn.wujiangbo.dto.User;
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 用户服务相关api接口
*
* @author 波波老师(微信 : javabobo0513)
*/
@RestController
@RequestMapping("/user")
public class UserController {
//获取配置文件中的值
@Value("${server.port}")
private String port;
@GetMapping("/getUserById/{id}")
//限流降级
@SentinelResource(value="getUserById", blockHandler="exceptionHandler")
public User getUserById(@PathVariable Long id){
return new User(id,"王天霸", "我是王天霸,你好吗?port=" + port);
}
// 限流与阻塞处理 : 参数要和被降级的方法参数一样
public User exceptionHandler(@PathVariable("userId") Long userId, BlockException ex) {
ex.printStackTrace();
return new User(-1L,"null","抱歉,Sentinel-限流");
}
}
这里通过@SentinelResource的value属性为资源取名为 “getUserById” ,后续我们可以根据该资源名来进行限流
同时这里通过 blockHandler 属性配置了一个限流降级方法,即当“getUserById”资源触发限流了,就会调用blockHandler指向的降级方法返回兜底数据,不至于抛出默认的限流异常信息给客户端(一串英文用户也看不懂) ,需要注意的是:降级方法要和被限流的方法参数一致,然后加上 BlockException 异常对象。
当然,也可以通过 blockHandlerClass 属性把降级方法写在一个专门的类中,如下:
@SentinelResource(value="getUserById",blockHandler="exceptionHandler",blockHandlerClass=ExceptionUtil.Class)
public final class ExceptionUtil {
//注意:这里的降级方法需要使用static修饰
public static User exceptionHandler(BlockException ex) {
//...
}
}
接下来我们就需要开始设置资源限流策略了
启动用户微服务,然后通过浏览器访问:http://localhost:1010/user/getUserById/13,不断刷新页面试试
然后登录Sentinel控制台刷新页面,在【实时监控】列表中可以看到资源的相关监控信息:

在【族点链路】列表中可以看到资源的调用链,并且可以通过【流控】按钮设置流控规则

也可以在【流控规则】菜单中针对资源进行限流规则的设置。如下:

这里我添加了一个流控规则,资源名对应客户端 @SentinelResource(value=“getUserById”)注解的资源,通过QPS限流(每秒请求数量),阈值是2 ,意思是“getUserById”这个资源每秒只能有2个请求进来,多余的请求会触发限流,返回降级数据
测试
通过浏览器访问用户服务,然后快速的刷新页面,当QPS大于2(每秒发送大于两个请求)就会触发限流,返回数据如下:

确实限流了,测试成功
2.3、Sentinel流控模式
1、直接
Sentinel默认的流控处理就是【直接->快速失败】,QPS达到阈值,当前资源直接失败。在【流控规则】菜单中配置如下:

2、关联
点击高级选项,关联的资源达到某个阈值,限流自己,如:

限流的资源是/user/delete ,关联的资源是/user/list,当/user/list达到阈值,限流user/delete
场景举例:支付并发太高,可以限制下单的流量
3、链路
限流调用的入口,如 /user/list 资源中调用了 /dept/list,有如下限流规则:

对/dept/list添加限流,当/dept/list达到阈值,其实限流的是/user/list,因为他是访问的入口
2.4、Sentinel流控效果
1、快速失败
快速失败:(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)是默认的流控方式,当流量达到阀值直接返回异常,QPS达到任何规则阈值后,后续请求就会立即拒绝,并抛出FlowException 异常。
简单理解:并发太高,直接请求拒绝
2、Warm Up预热
Warm Up预热:(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,根据codeFactor(默认3)的值,从(阀值/codeFactor)为初始阀值,经过预热时长,才到达设置的QPS的阀值,即预热/冷启动方式。
简单理解:慢慢的增大处理并发的能力

提示:初始的QPS阈值为 100 / 3 =33 ,也就是最开始的并发只能是33,但是10秒过后 QPS阈值就达到了100
当系统长期并发不高,流量突然增加可能会直接把系统压垮。让通过的流量缓慢增加,在一定时间内逐渐增加到阈值的上限,给系统一个预热的时间,避免系统被压垮。
场景:秒杀抢购
3、排队等待
排队等待:(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER),达到阈值之后的所有请求,我们可能更希望把这些请求放入队列,然后慢慢执行,而不是直接拒绝请求,这种方式严格控制请求通过的时间间隔,也就是让请求以均匀的速度通过,对应的是漏桶算法,这种方式主要用于处理间隔性突发的流量,例如消息队列。
简单理解:突发流量处理不过来,让请求排队。

解读:QPS阈值为100,超过100个请求的其他所有请求都会排队,排队超时时间为 10S
2.5、热点规则
还有一种特殊的动态限流规则,用于限制动态的热点资源,比如对同一个用户的请求频率做限定,比如对参数进行限定,比如对参数的值做限定(比如对商品ID为1的资源做限流)。
1、参数限流
参数限流就是:对资源的参数进行限流,
我们来编写一个方法,接受两个参数:p1和p2并设置好限流降级:
//限流降级
@SentinelResource(value="/parameterLimit",blockHandler="parameterLimitHandler")
@GetMapping(value="/parameterLimit")
public String parameterLimit(@RequestParam("p1") String p1 ,@RequestParam("p2") String p2){
return "parameterLimit方法调用成功...";
}
// 限流与阻塞处理
public String parameterLimitHandler(@RequestParam("p1") String p1 ,@RequestParam("p2") String p2,BlockException ex) {
return "限流了...";
}
配置热点规则,对第一个参数限流 ,当第一个参数超过了1的QPS就熔断降级:

2、参数值限流
对某一个参数的值满足某种条件的时候就进行限流。
上面的参数限流配置完毕后,点击后面的【编辑】按钮,如下配置:
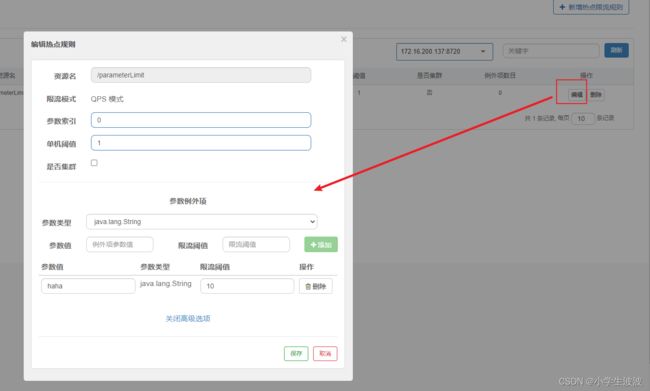
上面配置的意思是:第一个参数的值为 haha 的时候限流阈值为10 , 超过 QPS > 10的并发就限流。
场景:应用场景比如说商品名称为“华为p40”的商品并发特别高,我们可以针对参数商品名为“华为p40”的商品进行限流
2.6、系统规则
1、配置全局限流规则
系统规则可以看做是总的限流策略,所有的资源都要受到系统规则的限制:

上面的意思是最大并发只能允许 10 个线程数,并且是作用于全局的
3、Sentinel服务熔断
3.1、编码实战
1、资源熔断降级
修改用户微服务工程,修改UserController ,通过@SentinelResource注解的 fallback 属性指定降级方法
package cn.wujiangbo.controller;
import cn.wujiangbo.dto.User;
import com.alibaba.csp.sentinel.annotation.SentinelResource;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 用户服务相关api接口
*
* @author 波波老师(微信 : javabobo0513)
*/
@RestController
@RequestMapping("/user")
public class UserController {
//获取配置文件中的值
@Value("${server.port}")
private String port;
@GetMapping("/getUserById/{id}")
//限流降级
@SentinelResource(value="getUserById", blockHandler="exceptionHandler", fallback = "getUserByIdFallback")
public User getUserById(@PathVariable Long id){
int i = 1 / 0; //方法异常,触发熔断
return new User(id,"王天霸", "我是王天霸,你好吗?port=" + port);
}
// 限流与阻塞处理 : 参数要和 被降级的方法参数一样
public User exceptionHandler(@PathVariable("userId") Long userId, BlockException ex) {
ex.printStackTrace();
return new User(-1L,"null","抱歉,Sentinel-限流");
}
// 熔断降级,参数和返回值与源方法一致
public User getUserByIdFallback(@PathVariable("userId") Long userId){
return new User(userId,"null", "抱歉,Sentinel-熔断");
}
}
我在【getUserById】方法中通过 int i = 1 / 0 模拟发生异常,然后会熔断触发降级调用降级方法,通过 fallback 属性指定熔断的降级方法 ,熔断方法参数也要和被熔断方法参数一致。
开始测试,浏览器访问:http://localhost:1010/user/getUserById/13,结果如下:

符合预期,测试成功
注意:这里可以通过 @SentinelResource 注解中的 exceptionsToTrace 属性可以设置忽略某种异常,即针对某个异常不熔断
2、配置降级策略
在Sentinel控制台,在【族点链路】菜单中找到“getUserById”资源,然后点击【降级】按钮添加降级策略,如下:

这里的降级策略为“RT”,大概意思是:如果并发数大于5 (QPS > 5) ,然后平均响应时间大于200毫秒,那么接下来的2秒钟之内对该资源的请求会被熔断降级。
6.3、降级策略
资源在什么情况下会触发熔断降级?
调用异常,达到流控,调用超时 都会触发熔断降级,在上面的案例中我们看到资源的降级策略有 RT、异常比例、异常数这三种方式,我们可以通过这三种方式来定义资源是否稳定,决定是否要进行熔断降级。
1、平均响应RT
平均响应时间 (DEGRADE_GRADE_RT):当资源的平均响应时间超过阈值(DegradeRule 中的 count,以 ms 为单位)之后,资源进入准降级状态。详细说明:如果 1s 内持续进入 5 个请求(即 QPS >= 5),它们的 RT 都持续超过这个阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。
是不是很生涩难懂?我们根据下面这个配置来理解:

这里配置的RT是200意思是:对资源的多次请求平均响应时间都超过200毫秒,总体意思是1s 内持续进入 5 个请求(即 QPS >= 5),这五个请求的平均响应时间都超过了200,后续的2秒之内(时间窗口),请求这个方法都会被熔断,触发降级,2秒之后恢复正常。
总结一下:RT其实就是平均响应时间太长,资源熔断。
2、异常比例
异常比例(DEGRADE_GRADE_EXCEPTION_RATIO):每秒请求量 > 5 ,当资源的每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
根据下面这个配置来理解:

上面配置的意思就是:“getUserById”这个资源的异常比例超过了0.3,即10个请求有3个都异常了,资源就会被熔断,2秒之后恢复正常。
总结一下:异常比例就是按照资源的请求失败率来熔断。
3、异常数
异常数 (DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态。
根据下面这个配置来理解:

这里的意思是:62秒超过6个异常请求,服务进行熔断。后续请求都拒绝。
注意:异常降级仅针对业务异常,对 Sentinel 限流降级本身的异常(BlockException)不生效
总结一下:异常数就是按照 一分钟的异常的数量 来熔断。
6.4、OpenFeign兼容Sentinel
OpenFeign与Sentinel组件集成除了引入sentinel-starter依赖关系之外,还需要在yml配置文件中启用Sentinel支持:feign.sentinel.enabled=true
1、添加依赖
修改支付服务的pom文件(这个工程我们之前集成了OpenFeign),添加下面依赖:
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
2、开启Sentinel
修改支付微服务的yml文件,新增下面配置:
feign:
sentinel:
enabled: true #开启熔断
#hystrix:
# enabled: true #开启熔断功能
3、Feign接口降级
这里跟Feign开启Hystrix降级一样,还是可以使用fallback和fallbackFactory属性,如下:
package cn.wujiangbo.feign.client;
import cn.wujiangbo.dto.User;
import cn.wujiangbo.feign.fallback.UserFeignClientFallback;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
/**
* Feign的客户端接口
*
* @author 波波老师(微信 : javabobo0513)
*/
@FeignClient(value = "user-server", fallbackFactory = UserFeignClientFallback.class)
public interface UserFeignClient {
@GetMapping("/user/getUserById/{id}")
User getUserById(@PathVariable Long id);
}
编写降级类,返回托底数据:
package cn.wujiangbo.feign.fallback;
import cn.wujiangbo.dto.User;
import cn.wujiangbo.feign.client.UserFeignClient;
import feign.hystrix.FallbackFactory;
import org.springframework.stereotype.Component;
/**
* 兜底类
*
* @author 波波老师(微信 : javabobo0513)
*/
@Component
public class UserFeignClientFallback implements FallbackFactory<UserFeignClient> {
@Override
public UserFeignClient create(Throwable throwable) {
return new UserFeignClient(){
@Override
public User getUserById(Long userId) {
//打印异常信息,方便从控制台查看触发兜底的原因
throwable.printStackTrace();
return new User(userId, "null", "User服务不可用,返回兜底数据");
}
};
}
}
4、测试
启动用户服务和支付服务,然后浏览器访问:http://localhost:1030/pay/getUserById/13,开始是可以正常返回数据的,然后我们停掉用户服务,再刷新页面,就会这样了:

符合预期,测试成功
4、Sentinel和Hystrix区别
两者的原则是一致的, 都是当一个资源出现问题时, 让其快速失败, 不要波及到其它服务,但是在限制的手段上, 确采取了完全不一样的方法:
- Hystrix 默认采用的是线程池隔离的方式,优点是做到了资源之间的隔离,缺点是增加了线程切换的成本
- Sentinel 采用的是通过并发线程的数量和响应时间来对资源做限制
总结
本文针对Sentinel的服务容错的特性,介绍了其中各种知识点的使用方式,相信大家在开发中会使用了,赶紧写个Demo测试下吧