pytorch 报错 RuntimeError: CUDA error: no kernel image is available for execution on the device
环境:
- python 3.8.3
- pytorch 1.7.1
- cuda10.1
- GPU: GeForce 920M
问题
用GPU运行代码时报错如下

因为我的cuda是配好了的,用tensorflow时就没问题,本来运行以下测试的时候发现也是没问题的。
In [2]: torch.cuda.is_available()
Out[2]: True
但是再测试一下其它的
In [3]: torch.empty(3,4,device='cuda')
或者
In [5]: torch.Tensor([1,2]).cuda()
就又会报错RuntimeError: CUDA error: no kernel image is available for execution on the device
说明pytorch的cuda环境还是没配好
解决方法
出现这个问题的原因应该是 cuda或pytorch 与显卡算力不区配
1.查看显卡算力
有下面两种方法
方法1: 终端进到装CUDA的目录C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\demo_suite>
然后输入deviceQuery,如下所示
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\extras\demo_suite>deviceQuery
deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce 920M"
CUDA Driver Version / Runtime Version 10.1 / 10.1
CUDA Capability Major/Minor version number: 3.5
Total amount of global memory: 2048 MBytes (2147483648 bytes)
( 2) Multiprocessors, (192) CUDA Cores/MP: 384 CUDA Cores
GPU Max Clock rate: 954 MHz (0.95 GHz)
Memory Clock rate: 900 Mhz
Memory Bus Width: 64-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.1, CUDA Runtime Version = 10.1, NumDevs = 1, Device0 = GeForce 920M
Result = PASS
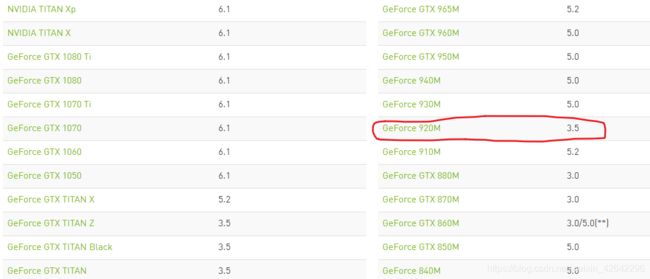
这样就可以看到显卡信息了,上面第二行的3.5就是我的显卡算力了.
方法2: 进入这个链接,找到你对应的显卡就能看到了
2.找到问题
在python 里输入如下命令
In [1]: import torch
In [2]: torch.cuda.get_arch_list()
Out[2]: ['sm_37', 'sm_50', 'sm_60', 'sm_70']
(如果嫌麻烦下面这一步可以省略)
或者从这个gitee上下到collect_env.py
然后执行结果如下:
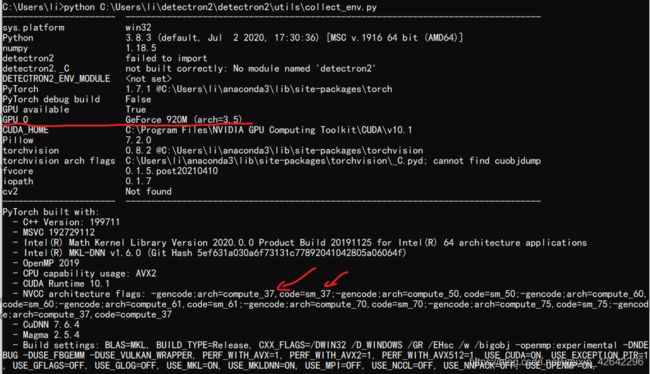
上面显示我的算力是3.5,但是下面提示我装的cuda或者pytorch最低支持3.7,所以我一用gpu它就会报错
因为新版的cuda或者pytorch对老显卡支持不太好,所以我们需要换一个老一点的版本。
那么到底应该是装旧版的cuda还是旧版的pytorch呢,我在一个装有pytorch1.7.1 + cuda9.2的服务上再测试刚才的colllect_env.py,结果如下:
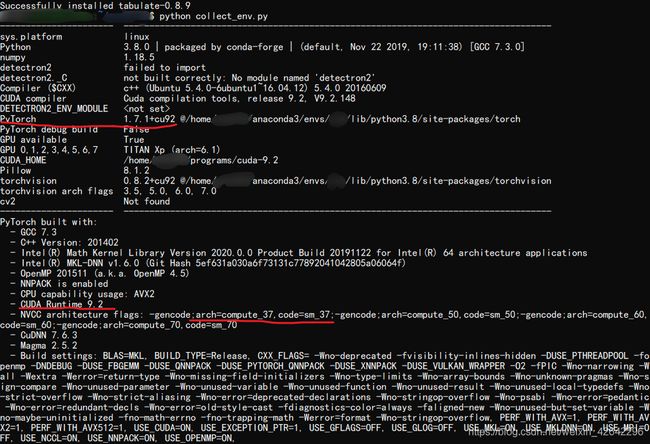
可见,在同样的pytorch版本,不同的cuda下,它对算力的要求是一样的,所以问题出在pytorch上
但是cuda10以下好像不支持算力3.0以下了,所以其实与cuda也有关系
3.解决办法
解决方法具我所知应该有两个
方法1:安装老版本的pytorch
但具体要装的版本号是多少呢,
网好像并没有公布每个pytorch版本与显卡算力的对应关系,所以只能靠试了
以下是Pytoch的讨论区里找的别人试出来的,所以综合来看,cuda与pytorch版本都不能高了
原话是"I extracted the compute capabilities for which each pytorch package on conda is compiled:"
| package | pyton | cuda | cudnn | architectures |
|---|---|---|---|---|
| pytorch-1.0.0 | py3.7 | cuda10.0.130 | cudnn7.4.1_1 | sm_30, sm_35, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.0.0 | py3.7 | cuda8.0.61 | cudnn7.1.2_1 | sm_20, sm_35, sm_37, sm_50, sm_52, sm_53, sm_60, sm_61 |
| pytorch-1.0.0 | py3.7 | cuda9.0.176 | cudnn7.4.1_1 | sm_35, sm_37, sm_50, sm_52, sm_53, sm_60, sm_61, sm_70 |
| pytorch-1.0.1 | py3.7 | cuda10.0.130 | cudnn7.4.2_0 | sm_35, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.0.1 | py3.7 | cuda10.0.130 | cudnn7.4.2_2 | sm_35, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.0.1 | py3.7 | cuda8.0.61 | cudnn7.1.2_0 | sm_35, sm_37, sm_50, sm_52, sm_53, sm_60, sm_61 |
| pytorch-1.0.1 | py3.7 | cuda8.0.61 | cudnn7.1.2_2 | sm_35, sm_37, sm_50, sm_52, sm_53, sm_60, sm_61 |
| pytorch-1.0.1 | py3.7 | cuda9.0.176 | cudnn7.4.2_0 | sm_35, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.0.1 | py3.7 | cuda9.0.176 | cudnn7.4.2_2 | sm_35, sm_50, sm_60, sm_70 |
| pytorch-1.1.0 | py3.7 | cuda10.0.130 | cudnn7.5.1_0 | sm_35, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.1.0 | py3.7 | cuda9.0.176 | cudnn7.5.1_0 | sm_35, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.2.0 | py3.7 | cuda9.2.148 | cudnn7.6.2_0 | sm_35, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.2.0 | py3.7 | cuda10.0.130 | cudnn7.6.2_0 | sm_35, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.2.0 | py3.7 | cuda9.2.148 | cudnn7.6.2_0 | sm_35, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.3.0 | py3.7 | cuda10.0.130 | cudnn7.6.3_0 | sm_30, sm_35, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.3.0 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_30, sm_35, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.3.0 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_35, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.3.1 | py3.7 | cuda10.0.130 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.3.1 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.3.1 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.4.0 | py3.7 | cuda10.0.130 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.4.0 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.4.0 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.5.0 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.5.0 | py3.7 | cuda10.2.89 | cudnn7.6.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.5.0 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.5.1 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.5.1 | py3.7 | cuda10.2.89 | cudnn7.6.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.5.1 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.6.0 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.6.0 | py3.7 | cuda10.2.89 | cudnn7.6.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.6.0 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.7.0 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.7.0 | py3.7 | cuda10.2.89 | cudnn7.6.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.7.0 | py3.7 | cuda11.0.221 | cudnn8.0.3_0 | sm_37, sm_50, sm_60, sm_61, sm_70, sm_75, sm_80 |
| pytorch-1.7.0 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.7.1 | py3.7 | cuda10.1.243 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.7.1 | py3.7 | cuda10.2.89 | cudnn7.6.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.7.1 | py3.7 | cuda11.0.221 | cudnn8.0.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75, sm_80 |
| pytorch-1.7.1 | py3.7 | cuda9.2.148 | cudnn7.6.3_0 | sm_37, sm_50, sm_60, sm_61, sm_70 |
| pytorch-1.8.0 | py3.7 | cuda10.1 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.8.0 | py3.7 | cuda10.2 | cudnn7.6.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.8.0 | py3.7 | cuda11.1 | cudnn8.0.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75, sm_80, sm_86 |
| pytorch-1.8.1 | py3.7 | cuda10.1 | cudnn7.6.3_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.8.1 | py3.7 | cuda10.2 | cudnn7.6.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75 |
| pytorch-1.8.1 | py3.7 | cuda11.1 | cudnn8.0.5_0 | sm_35, sm_37, sm_50, sm_60, sm_61, sm_70, sm_75, sm_80, sm_86 |
但是上面的结果与我的有点不太一样,我在cuda10.1.243、CuDNN 7.6.4的情况下测试了pytorch1.7.1和1.6.0,所以就很怪
以下两个是我测的
pytorch1.7.1 : ['sm_37', 'sm_50', 'sm_60', 'sm_70']
pytorch1.6.0 :['sm_37', 'sm_50', 'sm_60', 'sm_61', 'sm_70', 'sm_75', 'compute_37']
测试就是看一下这个的输出(好像从pytorch1.4 以下pytorch就没有这个属性)
In [2]: torch.cuda.get_arch_list()
Out[2]: ['sm_37', 'sm_50', 'sm_60', 'sm_70']
在cuda不变的情况下 我从1.7.1 装回1.6.0到1.4.0都不行,我又新开了个pyton3.6的虚拟环境装好了pytorch1.3.1,但仍然不行,如果换个低版本的cuda没准可以,但是我不想试了,因为我看到人家就可以,我的不行,不知道是为啥,我抽空去用源码安装一下试试
未完待续。。。
方法2:
从源码编译安装pytorch,然后在源码里面设置一下应该就好了,但可惜的是我不会,感觉有些麻烦,听说要弄好几个小时
还有的听说要在什么Makefile文件里面添加类似于下面这样的东西,但我一直没找到到底在添加在哪
-gencode arch=compute_30,code=[sm_30,compute_30]
-gencode arch=compute_35,code=[sm_35,compute_35] \
这个问题会继续探索,如果有新发现了我再更新