多线程面试相关技术点
只是记录多线程可能的面试点
具体细节和多线程体系还请系统学习
1、线程启动run和start 的区别
run 只是执行了一个方法
start 开启了一个线程
2、线程状态和之间的转换
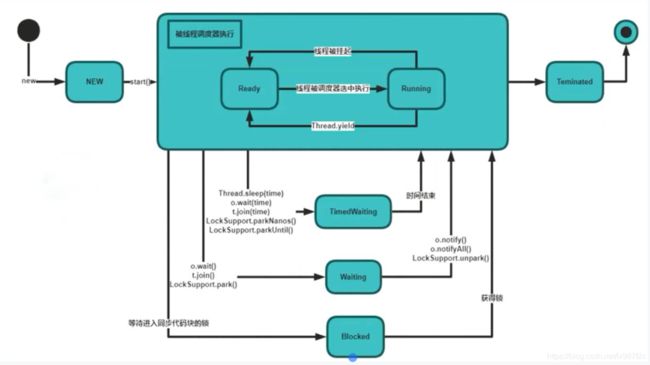
1 new 被创建出来 还没调用start
2 runnable 调用start方法之后,被线程调度器执行,也就是操作系统执行。整个状态叫runnable,runnable 内部有两个状态,一个叫ready就绪,在CPU的等待队列,一个叫running。
挂起就是线程执行时间片到了,CPU需要执行下一个线程了
3 timedwaiting
4 waiting
5 blocked 阻塞,比如同步代码块中没有得到锁就会进入到阻塞状态。
6 teminated 结束
3、synchronized
synchronized 实现
mark word 在被锁的对象的对象头(64位)上面拿两位出来标记是否被锁以及锁类型
sync (Object)
markword 记录这个线程ID (偏向锁)
如果线程争用:升级为自旋锁
10次以后,
升级为重量级锁 - OS
执行时间短(加锁代码),线程数少,用自旋
执行时间长,线程数多,用系统锁
一开始不加锁
在对象的对象头标记这个线程
如果下次还是这个线程就直接可以获取
如果不是这个线程就升级为自旋锁
循环十次如果还拿不到就升级为重量级锁
这个线程就去wait了
https://www.cnblogs.com/mingyueyy/p/13054296.html
线程抛出异常将会释放锁 其他线程会抢占锁
不能用基础数据类型加锁,因为:
锁这个概念是不存在基本数据类型中的,因为基本数据类型中的所有字节空间都是用来存放数据的,并没有额外空间存放锁,自然也就没有锁这个概念。Java需要从内存地址中获取”锁“, 获取被锁对象的对象头,加锁。
public class T_synchronized {
public void m1(){
synchronized(this){}
}
//和m1是相同的效果
public synchronized void m2(){}
//synchronized加载静态方法上相当锁住了当前类.class
public static synchronized void m3(){}
//相当于m3
public void m4(){
synchronized(T_synchronized.class){}
}
}
4、volatile 和MESI
4.1 保证线程可见性
一个线程修改,另外一个线程不能马上读到,这就是线程不可见
volatile 只能保证可见性 不能保证原子性
1进程把 i 变为1
2进程和3进程也读到了 i 为1 分别变为2
放回去 这时候 i 应该为3 但是结果为2
example:
/**
* 十个线程 每个线程加10000次 结果应该是十万 但是肯定到达不了十万
*/
public class T_volatile {
volatile int count = 0;
void add() {
for(int i=0; i<10000; i++) count++;
}
public static void main(String[] args) {
T_volatile t = new T_volatile();
List<Thread> threads = new ArrayList<Thread>();
for(int i=0; i<10; i++) {
threads.add(new Thread(t::add, "thread-"+i));
}
threads.forEach((o)->o.start());
threads.forEach((o)->{
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(t.count);
}
}
4.2 禁止指令重排序
CPU级别的重排序禁止不了
JVM级别的可以保证
锁住某个对象的时候
这个对象发生改变,就有可能导致锁有问题
所以在创建这个对象的时候加上final
不要用基础数据类型用来加锁
volatile 引用类型(包括数组)只能保证引用本身的可见性,不能保证内部字段的可见性
4.3 java怎么实现的volatile?
1)volatile变量执行写操作,会在写之前插入StoreStore Barriers,在写之后插入StoreLoad Barriers。
解释:volatile变量在执行写操作之前插入StoreStore Barriers,代表在执行volatile变量写之前的所有Store操作都已执行,数据同步到了内存中(将store buffer中的store操作刷新到内存);写之后插入StoreLoad Barriers,代表该volatile变量的写操作也会立即刷新到内存中,其他线程会看到最新值。
2)volatile变量执行读操作,会在读之前插入LoadLoad Barriers,在读之后插入LoadStore Barriers。
解释:volatile变量在执行读操作之前插入LoadLoad Barriers,代表在执行volatile变量读之前的所有Load从内存中获取最新值;在读之后插入LoadStore Barriers,代表该读取volatile变量获得是内存中最新的值。
读懂上面这段需要了解
MESI缓存一致性协议
4.4 内存屏障
如果不要volatile去增加内存屏障?如何解决?
手动增加屏障,通过Unsafe来解决。
Unsafe通过BootStwp被加载,否则抛异常。JVM的双亲委派机制
通过反射来获取。
loadFence(),storeFence(),fulFence()。
loadFence() 表示该方法之前的所有load操作在内存屏障之前完成。
storeFence()表示该方法之前的所有store操作在内存屏障之前完成。
fullFence()表示该方法之前的所有load、store操作在内存屏障之前完成。
public class T_volatile2 {
private static int x = 0, y = 0;
private static volatile int a = 0, b =0;
public static void reflectGetUnsafe1() {
a = 1; //是读还是写?store,volatile写
//storeload ,读写屏障,不允许volatile写与第二步volatile读发生重排
x = b; // 读还是写?读写都有,先读volatile,写普通变量
//分两步进行,第一步先volatile读,第二步再普通写
}
//若没有volatile修饰
public static void reflectGetUnsafe2() {
a = 1; //是读还是写? 普通写
//手动加内存屏障
T_volatile2.reflectGetUnsafe().storeFence();
x = b; // 读还是写?读写都有,先普通读,再普通写
//storeFence() 的时候强制将CPU store buffer里面的数据写到主内存。
}
public static Unsafe reflectGetUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
5、 CAS
参考 https://blog.csdn.net/ls5718/article/details/52563959
是CPU原语级别的支持,执行过程不会被打断。
在CPU中,使用cmpxchg指令。
在Java发展初期,java语言是不能够利用硬件提供的这些便利来提升系统的性能的。而随着java不断的发展,Java本地方法(JNI)的出现,使得java程序越过JVM直接调用本地方法提供了一种便捷的方式,因而java在并发的手段上也多了起来。而在Doug Lea提供的cucurenct包中,CAS理论是它实现整个java包的基石。
独占锁是一种悲观锁,synchronized就是一种独占锁,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。而另一个更加有效的锁就是乐观锁。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁用到的机制就是CAS,Compare and Swap
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。
通常将 CAS 用于同步的方式是从地址 V 读取值 A,执行多步计算来获得新 值 B,然后使用 CAS 将 V 的值从 A 改为 B。如果 V 处的值尚未同时更改,则 CAS 操作成功。
类似于 CAS 的指令允许算法执行读-修改-写操作,而无需害怕其他线程同时 修改变量,因为如果其他线程修改变量,那么 CAS 会检测它(并失败),算法 可以对该操作重新计算。
CAS存在的问题
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作
1 ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。
从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
2 循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
3 只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
6 reentrantlock
可以先尝试获取锁,在几秒内或得到就执行
reentrantlock 是否为公平锁?
一个线程启动,先检测等待队列是否有等待的线程就是公平锁
直接去竞争就是非公平锁。
reentrantlock在初始化的时候可以选择。
6.1 与synchronized区别:
(1)synchronized是独占锁,加锁和解锁的过程自动进行,易于操作,但不够灵活。ReentrantLock也是独占锁,加锁和解锁的过程需要手动进行,不易操作,但非常灵活。
(2)synchronized可重入,因为加锁和解锁自动进行,不必担心最后是否释放锁;ReentrantLock也可重入,但加锁和解锁需要手动进行,且次数需一样,否则其他线程无法获得锁。
(3)synchronized不可响应中断,一个线程获取不到锁就一直等着;ReentrantLock可以相应中断。
6.2 使用:
1 lock和unlock
private static final Lock lock = new ReentrantLock();
public void testReentrantLock(){
try{
lock.lock(); // 加锁
// 业务处理
}catch (Exception e){
//log
}finally {
lock.unlock(); // 解锁
}
}
2 公平锁和非公平锁实现
private static final Lock fair = new ReentrantLock(true); //公平
private static final Lock unfair = new ReentrantLock(false); //非公平
3 响应中断
响应中断就是当前线程中断ReentrantLock会给予一个中断回应,不会傻傻的一直等下去。
private static final ReentrantLock lock = new ReentrantLock();
public void testReentrantLock(){
try{
lock.lockInterruptibly(); // 如果当前线程未被中断,则获取锁
// 业务处理
}catch (InterruptedException e){
//log
}finally {
if (lock.isHeldByCurrentThread()){ // 解锁
lock.unlock();
}
}
}
线程中断函数:
thread.interrupt();
4 限时等待
通过ryLock方法来实现,可以选择传入时间参数,表示等待指定的时间
无参则表示立即返回锁申请的结果:true表示获取锁成功,false表示获取锁失败。
我们可以将这种方法用来解决死锁问题。
private static final Lock lock = new ReentrantLock();
public void testReentrantLock(){
try{
if (lock.tryLock(3, TimeUnit.SECONDS)) { //3秒内拿到锁就执行业务逻辑
// 业务处理
}
}catch (Exception e){
//log
}finally {
lock.unlock();// 解锁
}
}
6.3 实现原理
https://blog.csdn.net/lx9876lx/article/details/118463729
https://www.cnblogs.com/waterystone/p/4920797.html
http://ifeve.com/java-special-troops-aqs/
7 countdownlatch
拴住,每个线程执行完 门栓-1,countdown
所有线程执行完门栓打开,才能往下走
CountDownLatch是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
public class T_CountDownLatch {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(3);
final CountDownLatch latch = new CountDownLatch(3);
for (int i = 0; i < 3; i++) {
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
System.out.println("子线程" + Thread.currentThread().getName() + "开始执行");
Thread.sleep((long) (Math.random() * 10000));
System.out.println("子线程" + Thread.currentThread().getName() + "执行完成");
latch.countDown();//当前线程调用此方法,则计数减一
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
service.execute(runnable);
}
try {
System.out.println("主线程" + Thread.currentThread().getName() + "等待子线程执行完成...");
latch.await();//阻塞当前线程,直到计数器的值为0
System.out.println("主线程" + Thread.currentThread().getName() + "开始执行...");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
service.shutdown();
}
}
}
执行结果:
主线程main等待子线程执行完成...
子线程pool-1-thread-3开始执行
子线程pool-1-thread-1开始执行
子线程pool-1-thread-2开始执行
子线程pool-1-thread-2执行完成
子线程pool-1-thread-1执行完成
子线程pool-1-thread-3执行完成
主线程main开始执行...
8 CyclicBarrier
栅栏类似于闭锁,它能阻塞一组线程直到某个事件的发生。栅栏与闭锁的关键区别在于,所有的线程必须同时到达栅栏位置,才能继续执行。闭锁用于等待事件,而栅栏用于等待其他线程。
CyclicBarrier可以使一定数量的线程反复地在栅栏位置处汇集。当线程到达栅栏位置时将调用await方法,这个方法将阻塞直到所有线程都到达栅栏位置。如果所有线程都到达栅栏位置,那么栅栏将打开,此时所有的线程都将被释放,而栅栏将被重置以便下次使用。
public class T_CyclicBarrier {
// 自定义工作线程
private static class Worker extends Thread {
private CyclicBarrier cyclicBarrier;
public Worker(CyclicBarrier cyclicBarrier) {
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
super.run();
try {
System.out.println(Thread.currentThread().getName() + "开始等待其他线程");
//调用await方法的线程告诉CyclicBarrier自己已经到达同步点,然后当前线程被阻塞。直到parties个参与线程调用了await方法,CyclicBarrier同样提供带超时时间的await和不带超时时间的await方法:
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName() + "开始执行");
// 工作线程开始处理,这里用Thread.sleep()来模拟业务处理
Thread.sleep(1000);
System.out.println(Thread.currentThread().getName() + "执行完毕");
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
int threadCount = 3;
CyclicBarrier cyclicBarrier = new CyclicBarrier(threadCount);
for (int i = 0; i < threadCount; i++) {
System.out.println("创建工作线程" + i);
Worker worker = new Worker(cyclicBarrier);
worker.start();
}
}
}
执行结果:
创建工作线程0
创建工作线程1
创建工作线程2
Thread-0开始等待其他线程
Thread-1开始等待其他线程
Thread-2开始等待其他线程
Thread-2开始执行
Thread-0开始执行
Thread-1开始执行
Thread-2执行完毕
Thread-1执行完毕
Thread-0执行完毕
9 ReentrantReadWritelock
ReentrantReadWriteLock是Lock的另一种实现方式
ReentrantReadWriteLock允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。相对于排他锁,提高了并发性。在实际应用中,大部分情况下对共享数据(如缓存)的访问都是读操作远多于写操作,这时ReentrantReadWriteLock能够提供比排他锁更好的并发性和吞吐量。
读写锁内部维护了两个锁,一个用于读操作,一个用于写操作。所有 ReadWriteLock实现都必须保证 writeLock操作的内存同步效果也要保持与相关 readLock的联系。也就是说,成功获取读锁的线程会看到写入锁之前版本所做的所有更新。
ReentrantReadWriteLock 也是基于AQS实现的,它的自定义同步器(继承AQS)需要在同步状态(一个整型变量state)上维护多个读线程和一个写线程的状态,使得该状态的设计成为读写锁实现的关键。如果在一个整型变量上维护多种状态,就一定需要“按位切割使用”这个变量,读写锁将变量切分成了两个部分,高16位表示读,低16位表示写。
ReentrantReadWriteLock支持以下功能:
1)支持公平和非公平的获取锁的方式;
2)支持可重入。读线程在获取了读锁后还可以获取读锁;写线程在获取了写锁之后既可以再次获取写锁又可以获取读锁;
3)还允许从写入锁降级为读取锁,其实现方式是:先获取写入锁,然后获取读取锁,最后释放写入锁。但是,从读取锁升级到写入锁是不允许的;
4)读取锁和写入锁都支持锁获取期间的中断;
5)Condition支持。仅写入锁提供了一个 Conditon 实现;读取锁不支持 Conditon ,readLock().newCondition() 会抛出 UnsupportedOperationException。
通常在 collection 数据很多,读线程访问多于写线程并且 entail 操作的开销高于同步开销时尝试这么做。
public class T_ReentrantReadWriteLock {
static Lock lock = new ReentrantLock();
private static int value;
static ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
static Lock readLock = readWriteLock.readLock();
static Lock writeLock = readWriteLock.writeLock();
public static void read(Lock lock) {
try {
lock.lock();
Thread.sleep(1000);
System.out.println("read over!");
//模拟读取操作
} catch (InterruptedException e) {
// log
} finally {
lock.unlock();
}
}
public static void write(Lock lock, int v) {
try {
lock.lock();
Thread.sleep(1000);
value = v;
System.out.println("write over!");
//模拟写操作
} catch (InterruptedException e) {
// log
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
//Runnable readR = ()-> read(lock); //这种方式,第二个线程需要第一个线程读完
Runnable readR = () -> read(readLock); //这种方式,多个线程一块读
//Runnable writeR = ()->write(lock, new Random().nextInt());
Runnable writeR = () -> write(writeLock, new Random().nextInt());
for (int i = 0; i < 18; i++) new Thread(readR).start();
for (int i = 0; i < 2; i++) new Thread(writeR).start();
}
}
10 Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
Semaphore可以用于做流量控制,特别公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,
因为都是IO密集型任务,我们可以启动几十个线程并发的读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,
这时我们必须控制只有十个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,我们就可以使用Semaphore来做流控
在代码中,虽然有30个线程在执行,但是只允许10个并发的执行。Semaphore的构造方法Semaphore(int permits) 接受一个整型的数字,表示可用的许可证数量。Semaphore(10)表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用Semaphore的acquire()获取一个许可证,使用完之后调用release()归还许可证。还可以用tryAcquire()方法尝试获取许可证。
其他方法
Semaphore还提供一些其他方法:
int availablePermits() :返回此信号量中当前可用的许可证数。
int getQueueLength():返回正在等待获取许可证的线程数。
boolean hasQueuedThreads() :是否有线程正在等待获取许可证。
void reducePermits(int reduction) :减少reduction个许可证。是个protected方法。
Collection getQueuedThreads() :返回所有等待获取许可证的线程集合。是个protected方法。
https://ifeve.com/concurrency-semaphore/#more-14753
https://ifeve.com/tag/semaphore/
public class T_Semaphore {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors
.newFixedThreadPool(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
//虽然循环了30次,但是同时只有十个线程在运行
for (int i = 0; i < THREAD_COUNT; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
s.acquire();
System.out.println("save data");
TimeUnit.SECONDS.sleep(30);
s.release();
} catch (InterruptedException e) {
}
}
});
}
threadPool.shutdown();
}
}
10 LockSupport
LockSupport是一个线程工具类,所有的方法都是静态方法,可以让线程在任意位置阻塞,也可以在任意位置唤醒。
它的内部其实两类主要的方法:park(停车阻塞线程)和unpark(启动唤醒线程)。
public static void park(Object blocker); // 暂停当前线程
public static void parkNanos(Object blocker, long nanos); // 暂停当前线程,不过有超时时间的限制
public static void parkUntil(Object blocker, long deadline); // 暂停当前线程,直到某个时间
public static void park(); // 无期限暂停当前线程
public static void parkNanos(long nanos); // 暂停当前线程,不过有超时时间的限制
public static void parkUntil(long deadline); // 暂停当前线程,直到某个时间
public static void unpark(Thread thread); // 恢复当前线程
public static Object getBlocker(Thread t);
unpark() :
如果给定线程的许可尚不可用,则使其可用。如果线程在park上受阻塞,则他将解除其阻塞状态。
否则,保证下一次调用park不会受阻塞,如果给定线程尚未启动,则无法保证此操作有任何效果。
park和unpark可以实现类似wait和notify的功能,但是并不和wait和notify交叉,也就是说unpark不会对wait起作用,notify也不会对park起作用。
park和unpark的使用不会出现死锁的情况
blocker的作用是在dump线程的时候看到阻塞对象的信息
使用wait,notify来实现等待唤醒功能至少有两个缺点:
1.wait和notify都是Object中的方法,在调用这两个方法前必须先获得锁对象,这限制了其使用场合:只能在同步代码块中。
2.当对象的等待队列中有多个线程时,notify只能随机选择一个线程唤醒,无法唤醒指定的线程。
LockSupport就是通过控制变量_counter来对线程阻塞唤醒进行控制的。原理有点类似于信号量机制。
当调用park()方法时,会将_counter置为0,同时判断前值,小于1说明前面被unpark过,则直接退出,否则将使该线程阻塞。
当调用unpark()方法时,会将_counter置为1,同时判断前值,小于1会进行线程唤醒,否则直接退出。
形象的理解,线程阻塞需要消耗凭证(permit),这个凭证最多只有1个。当调用park方法时,如果有凭证,则会直接消耗掉这个凭证然后正常退出;但是如果没有凭证,就必须阻塞等待凭证可用;而unpark则相反,它会增加一个凭证,但凭证最多只能有1个。
unpark可以先于park调用
为什么可以先唤醒线程后阻塞线程?
因为unpark获得了一个凭证,之后调用park因为有凭证消费,故不会阻塞。
为什么唤醒两次后阻塞两次会阻塞线程。
因为凭证的数量最多为1,连续调用两次unpark和调用一次unpark效果一样,只会增加一个凭证;而调用两次park却需要消费两个凭证。
https://www.cnblogs.com/takumicx/p/9328459.html
https://www.jianshu.com/p/f1f2cd289205
https://baijiahao.baidu.com/s?id=1666548481761194849&wfr=spider&for=pc
public class T_LockSupport {
public static void main(String[] args) {
Thread parkThread = new Thread(new ParkThread());
parkThread.start();
System.out.println("开始线程唤醒");
LockSupport.unpark(parkThread);
System.out.println("结束线程唤醒");
}
static class ParkThread implements Runnable {
@Override
public void run() {
System.out.println("开始线程阻塞");
LockSupport.park();
System.out.println("结束线程阻塞");
}
}
}
运行结果:
开始线程唤醒
结束线程唤醒
开始线程阻塞
结束线程阻塞
11 threadlocal
11.1 是什么:
ThreadLocal 是 JDK java.lang 包中的一个用来实现相同线程共享不同的线程数据隔离的一个工具。 JDK 源码中解释:
这个类提供线程局部变量。
线程中这个变量与平常类的变量不同,不同在于每一个线程在访问它自己的ThreadLocal实例的时候(通过其get或set方法),都有自己独立的、已经初始化的局部变量副本。
ThreadLocal实例通常是类中的私有静态属性,目的是希望将这个属性状态与线程关联起来(例如,用户ID或事务ID)。
ThreadLocal 解决的是线程数据隔离的问题,并不是多线程共享数据的问题。
11.2 使用:
public class T_threadlocal {
private static ThreadLocal<String> name = new ThreadLocal<String>();
private static ThreadLocal<Integer> age = new ThreadLocal<Integer>();
public static void main(String[] args) throws InterruptedException {
int threads = 9;
Random random = new Random();
for (int i = 0; i < threads; i++) {
Thread thread = new Thread(() -> {
name.set(Thread.currentThread().getName());
age.set(random.nextInt(30));
System.out.println("threadLocal.get()================>" + name.get() + "---" + age.get());
}, "执行线程 - " + i);
thread.start();
}
}
}
11.3 原理:
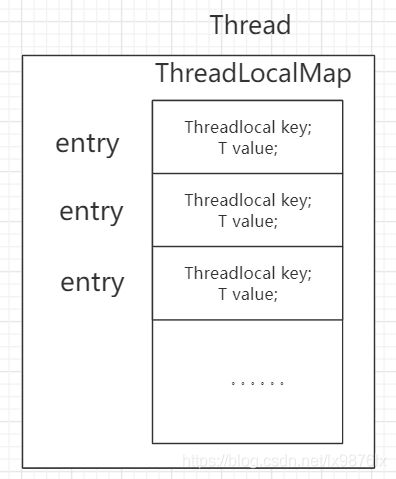
threadLocals是thread的一个属性,
类型为threadlocalmap,
threadlocalmap为 threadlocal的内部类,
threadlocalmap内部有一个继承了WeakReference的Entry内部类和一个Entry数组。
使用Threadlocal时Thread内部结构:
去掉杂七杂八的核心代码:
public class Thread implements Runnable {
ThreadLocal.ThreadLocalMap threadLocals = null;
}
public class ThreadLocal<T> {
private final int threadLocalHashCode = nextHashCode();
private static final int HASH_INCREMENT = 0x61c88647;
// 获取当前key的hashcode 其实就是一个int值每次在内存偏移递增
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
public T get() {
Thread t = Thread.currentThread();
//获取当前线程的属性 threadLocals,取出当前threadlocal存放的值
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
T result = (T) e.value;
return result;
}
}
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
//获取当前线程的属性 threadLocals,threadLocals是ThreadLocalMap类型
// ThreadLocalMap里面有个数组,数组的值为Entry,Entry有两个属性 key为ThreadLocal,value为传进来的值
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
//调用下面的remove方法
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
//将线程的threadLocals属性返回
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
//初始化一个ThreadLocalMap
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
//ThreadLocalMap为ThreadLocal的一个内部类
static class ThreadLocalMap {
//Entry为ThreadLocalMap的一个内部类 并继承了WeakReference
//将Entry内部的属性key设置为虚引用,key为ThreadLocal类型
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
//ThreadLocalMap内部的数组,用来存储不同的ThreadLocal
private Entry[] table;
private int size = 0;
//初始化
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
//根据传进来key的hashcode,跟数组长度-1与运算就能获取对应Entry的下标并取出Entry
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
//根据传进来key的hashcode,跟数组长度-1与运算就能获取对应Entry的下标
//初始化Entry并存入对应位置
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
tab[i] = new Entry(key, value);
int sz = ++size;
}
//根据传进来key的hashcode,跟数组长度-1与运算就能获取对应Entry的下标并删除
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
}
}
1 怎么实现隔离
看完源码,原理就是Thread内部维护一个数据结构,
将数据存入,其他线程也就拿不到了。
2 为什么要用弱引用
threadlocal是在线程外声明的,比如在main方法内,
如果是强引用,线程内的方法执行完了,但是main方法没有执行完,
强引用指向了线程开辟的内存,导致线程执行完了开辟的内存无法回收。
所以使用了弱引用。GC的时候main方法的threadlocal直接回收掉。
如果threadlocal回收掉了,线程还没死,比如线程池的核心线程不回收一直在重复使用,回收掉的threadlocal指向的线程内部的那块内存,也就是Entry的value就一直回收不了。就造成了内存泄露。所以在线程执行完之后要调用theadlocal的remove 方法,及时回收内存。