手把手教你:基于python的文本分类(sklearn-决策树和随机森林实现)
系列文章
- 第十二章 手把手教你:岩石样本智能识别系统
- 第十一章 手把手教你:基于TensorFlow的语音识别系统
- 第十章 手把手教你:基于Django的用户画像可视化系统
目录
- 系列文章
- 一、项目简介
- 二、任务介绍
- 三.数据简介
- 三、代码功能介绍
-
- 1.依赖环境集IDE
- 2.读取文本数据
- 3.数据预处理
- 4.文字特征向量构建
- 5.构建并训练模型
-
- 5-1 决策树
- 5-2 随机森林
- 6.文本分类预测
-
- 6-1 加载模型
- 6-2 文本特征构建
- 6-3 输出类别并转码
- 四、代码下载地址
一、项目简介
本文主要介绍如何使用python的sk-learn机器学习框架搭建一个或多个:文本分类的机器学习模型,如果有毕业设计或者课程设计需求的同学可以参考本文。本项目使用了决策树和随机森林2种机器学习方法进行实验,完整代码在最下方,想要先看源码的同学可以移步本文最下方进行下载。
博主也参考过文本分类相关模型的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个可视化系统即可。
也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。
如果您有以上想法,那就找对地方了!
不多废话,直接进入正题!
二、任务介绍
本次任务是一个传统的机器学习实现文本分类的任务。
前期为输入一个文本,其中为对相关事务的一个口语化的描述,这里是对一些生活常见的垃圾的一个描述。我们需要使用模型对这个描述中涉及到的垃圾进行分类,主要分为四类:
- 可回收垃圾
- 有害垃圾
- 厨余垃圾
- 其他垃圾
最终我们需要实现的效果为:不需要准确输入垃圾的名称,只需要它的描述,就可以识别它是哪一种垃圾。
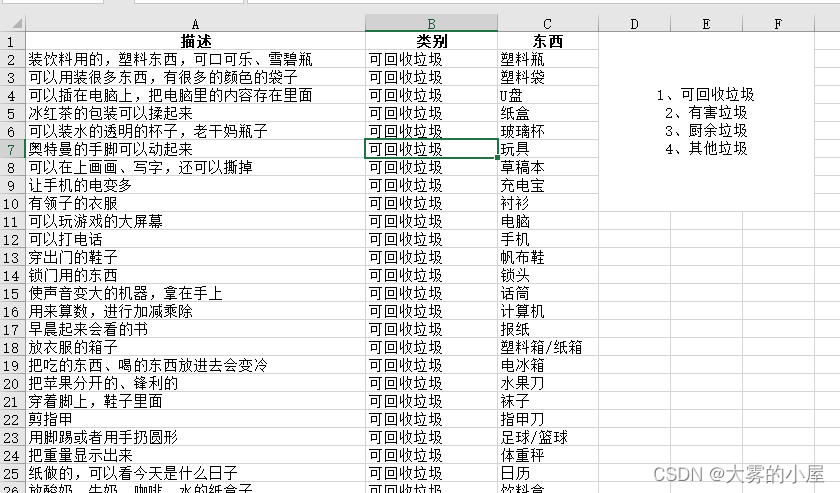
三.数据简介
本次使用的数据为标注后的文本,见下图:

三、代码功能介绍
1.依赖环境集IDE
本项目使用的是anaconda的jupyter notebook编译环境,如不清楚如何使用的同学可以参考csdn上其他博主的基础教程,这里就不进行赘述。
- TensorFlow-GPU,版本:2.0及以上
- sklearn
- pandas
- word2vec
- 完整代码下载地址
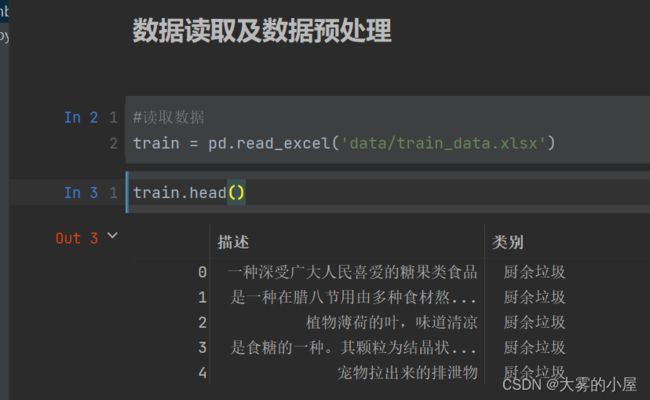
2.读取文本数据
- 读取所有的文本标注数据,共计4类。
3.数据预处理
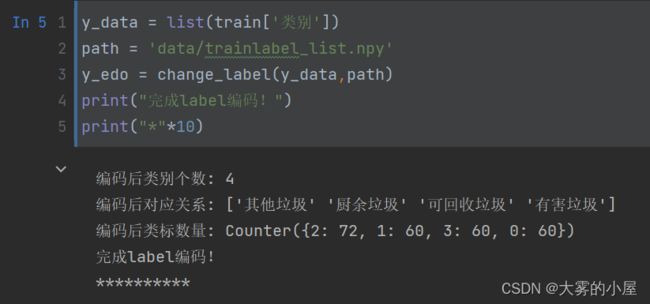
- 对文本标注的类别进行编码:
# 类别编码函数
def change_label(label,path):
from sklearn.preprocessing import LabelEncoder
le_credit_level = LabelEncoder().fit(label)
new_label = le_credit_level.transform(label)
label_counts = len(Counter(label))
# 保存编码对应关系
lb_list = le_credit_level.classes_
print("编码后类别个数:",label_counts)
print("编码后对应关系:",lb_list)
print("编码后类标数量:",Counter(new_label))
np.save(path, lb_list)
return new_label
- 文本text内容数据清洗:
# 定义数据清洗方法
def g_replace(texts):
new_test = []
for i in range(len(texts)):
# 句子去除标点符号
new_sentence = texts[i].replace(',',' ').replace(',',' ').replace('/',' ').replace('。',' ').replace('、',' ')
new_test.append(new_sentence)
return new_test
4.文字特征向量构建
我们使用word2vec对文本的内容进行特征向量构建。这里的思路为对每个字构建为一个200维的特征向量,然后将这句话所有涉及的文字的特征向量加总后求平均值。也就是说构建完成后,每个训练数据中每句话都对应了一个200维的特征向量。
# 定义文字特征构建函数
def my_word_vec(texts):
word_vec_list = []
for sentence in tqdm(texts):
sentence = sentence.replace(' ','')
# 每行文字特征向量
row = 0
for word in sentence:
row += model.wv[word]
row = row/len(sentence)
word_vec_list.append(row)
return word_vec_list
5.构建并训练模型
由于模型构建代码较多,这里就不一一进行展示,感兴趣的同学可以在文章下方找到完整代码下载地址。
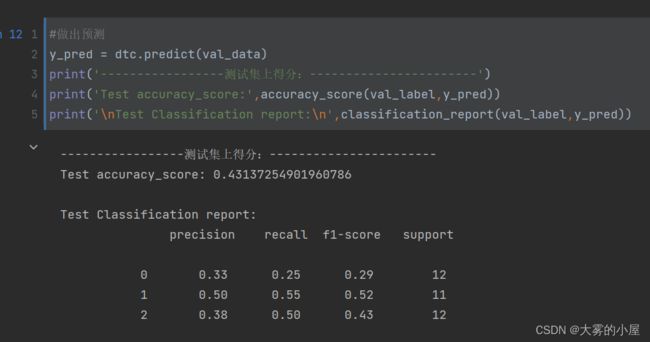
5-1 决策树
5-2 随机森林

6.文本分类预测
我们想要达到的效果为输入一段文本描述,模型即可将文本正确分类为描述的是哪种类型的垃圾,主要涉及几个步骤:加载模型——>输入文本的特征向量构建——>输出类别——>类别转码。
6-1 加载模型
# 加载word2vec模型
w2v_model = Word2Vec.load('model/model_word2vec.m')
# 加载决策树模型
dtc_model = joblib.load('model/model_dtc.m')
# 加载随机森林模型
rfc_model = joblib.load('model/model_rf_grid.m')
6-2 文本特征构建
# 定义文字特征构建函数
def my_word_vec(sentence,model):
sentence = sentence.replace(' ','')
# 每行文字特征向量
count,row = 0,0
for word in sentence:
try:
row += model.wv[word]
count += 1
except:
pass
if count == 0:
row = np.zeros(200)
else:
row = row/count
return row
6-3 输出类别并转码
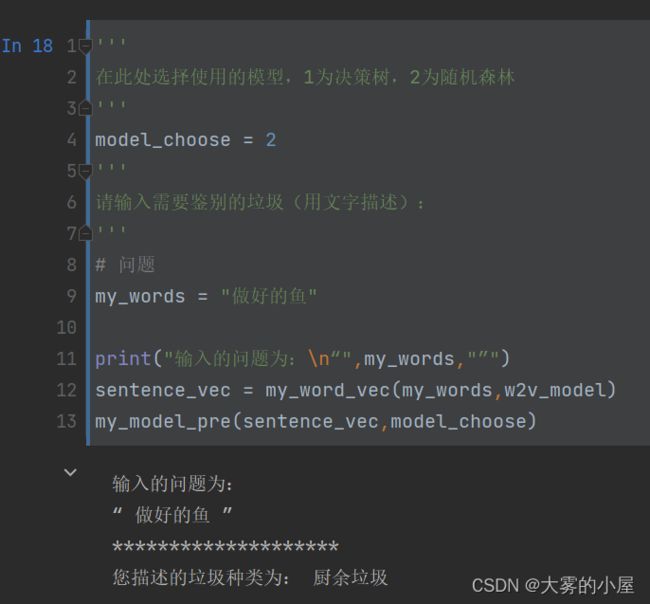
我们这里输入了一段文字 “做好的鱼” 选择了2:随机森林的模型对这段文本描述进行分类,最终分类的类别为:厨余垃圾,可以看到模型将这段描述正确分类了。
四、代码下载地址
由于项目代码量和数据集较大,感兴趣的同学可以直接下载代码,使用过程中如遇到任何问题可以在评论区进行评论,我都会一一解答。
代码下载:
- 【代码分享】基于python的文本分类(sklearn-决策树和随机森林实现)