CART决策树算法
在进行自动识别窃漏电用户分析实战时,用到了CART决策树算法,所以整理记录该算法的内容。内容整理参考文档决策树——CART算法及其后的参考文章。
一、CART(classification and regression tree)分类与回归树,既可用于分类,也可用于回归。
CART分类树生成
CART分类树算法使用基尼系数来选择特征。基尼系数Gini(D)表示集合D的不确定性(纯度),Gini(D,A)表示根据特征A的某个值a分割后集合D的不确定性(纯度)。基尼系数数值越小,样本纯度越高。对于给定的样本D,假设有K个类别,第k个类别的数量为 C k C_{k} Ck,则样本D的基尼系数表达式为: G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini\left ( D \right )=1-\sum_{k=1}^{K}\left ( \frac{|C_{k}|}{|D|} \right )^{2} Gini(D)=1−k=1∑K(∣D∣∣Ck∣)2
对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分,则在特征A的条件下,D的基尼系数表达式为: G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini\left ( D,A \right )=\frac{|D_{1}|}{|D|}Gini\left ( D_{1} \right )+\frac{|D_{2}|}{|D|}Gini\left ( D_{2} \right ) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
CART分类树建立算法的具体流程
算法输入是训练集D、基尼系数的阈值、样本个数阈值,输出是决策树T。从根节点开始:
1、对于当前节点的数据集D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前节点停止递归。
2、计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前节点停止递归。
3、计算当前节点现有的各个特征的各个特征值对数据集D的基尼系数,选择基尼系数最小的特征A和对应的特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分D1和D2,同时建立当前节点的左右节点,左节点的数据集D为D1,右节点的数据集D为D2。
4、对左右的子节点递归调用1-3步,生成决策树。
CART回归树生成
CART回归树和CART分类树的建立算法大部分是类似的,不同的地方有:
1、样本输出:分类树输出离散值,回归树输出连续值。
2、划分点选择方法:分类树使用基尼系数,回归树使用误差平方最小化。
3、预测方式:分类树采用叶子节点里概率最大的类别作为当前节点的预测类别,回归树采用最终叶子的均值或者中位数来预测输出结果。
CART回归树的度量目标是,对于任意划分特征A,对应的任意划分点s两边划分成的数据集D1和D2,求出使D1和D2各自集合的均方差最小,同时D1和D2的均方差之和最小所对应的特征和特征值划分点。表达式为:

其中,c1为D1数据集的样本输出均值,c2为D2数据集的样本输出均值。
CART树算法的剪枝
CART剪枝采用CCP(Cost Complexity Pruning)代价复杂剪枝法,从决策树低端剪去一些子树,使得决策树变小变简单,从而防止过拟合。其剪枝算法可以概括为两步,第一步是从原始决策树生成各种剪枝效果的决策树,第二步是用交叉验证来检验剪枝后的预测能力,选择泛化预测能力最好的剪枝后的树作为最终的CART树。在剪枝的过程中,对于任意一棵子树T,其损失函数为: C α ( T t ) = C ( T t ) + α ∣ T t ∣ C_{\alpha }\left ( T_{t} \right )=C\left ( T_{t} \right )+\alpha |T_{t}| Cα(Tt)=C(Tt)+α∣Tt∣
其中,α为正则化参数, C ( T t ) C\left ( T_{t} \right ) C(Tt)为训练数据的预测误差,分类树是用基尼系数度量,回归树是均方差。 ∣ T t ∣ |T_{t}| ∣Tt∣是子树T的叶子节点的数量。如果将任意一棵子树T剪枝,仅保留根节点,则损失是: C α ( T ) = C ( T ) + α C_{\alpha }\left ( T \right )=C\left ( T \right )+\alpha Cα(T)=C(T)+α
如果 T t T_{t} Tt与T有同样的损失,且T的节点更少,那么T比 T t T_{t} Tt更可取,所以剪掉 T t T_{t} Tt。此时 α = C ( T ) − C ( T t ) ∣ T t ∣ − 1 \alpha =\frac{C\left ( T \right )-C\left ( T_{t} \right )}{|T_{t}|-1} α=∣Tt∣−1C(T)−C(Tt)
这表示剪枝后的误差增加率。其中 C ( T ) = c ( t ) ∗ p ( t ) C\left ( T \right )=c\left ( t \right )*p\left ( t \right ) C(T)=c(t)∗p(t),c(t)是节点的误差率,p(t)是节点上的数据占所有数据的比例。
具体剪枝过程:
1、自下而上计算每个内部结点的误差增加率,选择最小的来剪枝,生成新的树。
2、如果新的树不是由根节点及两个叶节点构成的树,则递归上一步。
3、采用交叉验证法在上述两步中选择最优的子树作为最后的结果。
二、建立模型实现后,评估模型用到了ROC曲线,所以整理ROC相关内容。
ROC曲线如下所示,设置了两个指标:分别是TPR与FPR,它是以TPR为纵坐标,FPR为横坐标画出的曲线。TPR是正例的覆盖率(正确预测到的正例数/实际正例总数),FPR是将实际的0错误地预测为1的概率(预测错误的正例数/实际负例总数)。

ROC曲线越远离对角线,模型效果越好。曲线下的面积可以定量地评价模型的效果,记作AUC,AUC代表着分类器预测精度。
AUC>0.9,说明模型有较高准确性;
0.7≤AUC≤0.9,说明模型有一定准确性;
0.5≤AUC<0.7,说明模型有较低准确性。
三、进行自动识别窃漏电用户实战,建模的目标是归纳出窃漏电用户的关键特征,构建窃漏电用户的识别模型。
首先进行搭建数据模型准备:
1、数据筛选,可以将用户进行分类(如按规模、性质),可能某些种类用户不存在窃漏电行为,可以将这些类别用户剔除。
2、数据探索,总结窃漏电用户的行为规律,再从数据中提炼出窃漏电用户的特征指标。
根据数据探索及业务理解,最终构建的窃漏电评价指标体系如下:
(1)电量趋势下降指标,以前后几天作为统计窗口期,利用电量做直线拟合得到的斜率衡量,如果斜率随时间不断下降,那用户的窃漏电可能性就很大。
(2)线损指标,用户发生窃漏电时,线损率会上升。可以计算前后几天(如前5天、后5天)的线损率平均值,判断增长率是否大于给定阈值。
(3)告警类指标,计算发生与窃漏电相关的终端报警的总次数。
接着收集指标样本数据,案例得到的样本共291条,部分如下所示:

窃漏电用户识别可以通过构建分类预测模型来实现,实践中选择了逻辑回归模型和CART决策树模型分别实现,通过ROC曲线进行模型评估,相关代码如下:
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
import numpy as np
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
#ROC曲线绘制
def roc(test,predict): #test是实际类别数据,predict是预测类别数据
fpr, tpr, thresholds = roc_curve(test, predict, pos_label=1) #获得FPR、TPR,pos_label=1是指在预测值中标签为1的是标准阳性,其余值是阴性。
roc_auc = auc(fpr, tpr) #计算AUC
plt.plot(fpr, tpr, 'b', label='auc=%0.2f' % roc_auc) #绘制ROC曲线
plt.legend(loc='lower right') #设置图例位置
plt.plot([0, 1], [0, 1], 'r--') #绘制对角线
plt.xlim([0.0, 1.0]) #设置坐标轴范围
plt.ylim([0.0, 1.0])
plt.xlabel("fpr") #设置坐标轴名称
plt.ylabel("tpr")
plt.show()
data = pd.read_csv('CART.csv',encoding='gbk') #读取源数据
#print(data.shape)
array = data.values #转化为多维数组
p=0.7 #训练数据占总数据量的0%
train=array[:int(len(array)*p),:] #获得训练数据
test=array[int(len(array)*p):,:] #获得测试数据
X_train = train[:, 2:5] #分离特征和类别
Y_train = train[:, 5].astype('int')
X_test = test[:, 2:5]
Y_test = test[:, 5].astype('int')
model = LogisticRegression() #加载逻辑回归模型
model.fit(X_train, Y_train) #训练数据
scores = cross_val_score(model, X_train, Y_train, cv=10) #交叉验证评估模型的预测性能
print("准确率", np.mean(scores)) #交叉验证准确率
predictions = model.predict(X_test) #预测数据
roc(Y_test,predictions) #绘制ROC曲线
tree=DecisionTreeClassifier() #加载决策树
tree.fit(X_train,Y_train) #训练数据
scores = cross_val_score(tree, X_train, Y_train, cv=10) #交叉验证评估模型的预测性能
print("准确率", np.mean(scores)) #交叉验证准确率
predict_result=tree.predict(X_test) #预测数据
roc(Y_test,predict_result) #绘制ROC曲线
两个模型的ROC曲线分别如下:
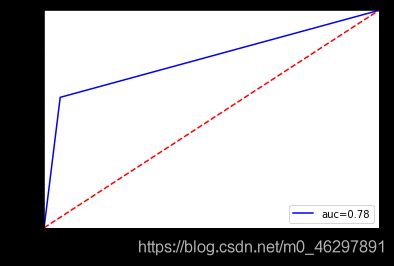

查看训练集上的交叉验证准确率,逻辑回归模型为0.892,CART决策树模型为0.887,两者差别不大。但是从ROC曲线可以看出,CART模型的曲线更加靠近左上角,AUC值直接表明了这一点,逻辑回归模型为0.78,CART决策树模型为0.87,说明CART决策树模型预测效果更好。