redis过期策略和内存淘汰机制
Redis的过期策略
1 定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
2 惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
3 定期过期
redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。Redis 默认会每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
- 从过期字典中随机 20 个 key,删除这 20 个 key 中已经过期的 key;
- 如果过期的 key 比率超过 1/4,那就重复步骤 1;
redis默认是每隔 100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
4 Redis 同时惰性过期和定期过期两种过期策略
Redis过期删除采用的是定期删除,默认是每100ms检测一次,遇到过期的key则进行删除,这里的检测并不是顺序检测,而是随机检测。那这样会不会有漏网之鱼?显然Redis也考虑到了这一点,当我们去读/写一个已经过期的key时,会触发Redis的惰性删除策略,直接回干掉过期的key
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
8种数据淘汰策略
Redis 4.0开始,共有8种数据淘汰机制:
| 淘汰策略名称 | 策略含义 |
|---|---|
| noeviction | 默认策略,不淘汰数据;大部分写命令都将返回错误(DEL等少数除外) |
| allkeys-lru | 从所有数据中根据 LRU 算法挑选数据淘汰 |
| volatile-lru | 从设置了过期时间的数据中根据 LRU 算法挑选数据淘汰 |
| allkeys-random | 从所有数据中随机挑选数据淘汰 |
| volatile-random | 从设置了过期时间的数据中随机挑选数据淘汰 |
| volatile-ttl | 从设置了过期时间的数据中,挑选越早过期的数据进行删除 |
| allkeys-lfu | 从所有数据中根据 LFU 算法挑选数据淘汰(4.0及以上版本可用) |
| volatile-lfu | 从设置了过期时间的数据中根据 LFU 算法挑选数据淘汰(4.0及以上版本可用) |
除 noeviction 比较特殊外,allkeys 开头的将从所有数据中进行淘汰,volatile 开头的将从设置了过期时间的数据中进行淘汰。淘汰算法又核心分为 lru、random、ttl、lfu 几种。如下图所示:

Redis的LRU、LFU算法
1 LRU算法
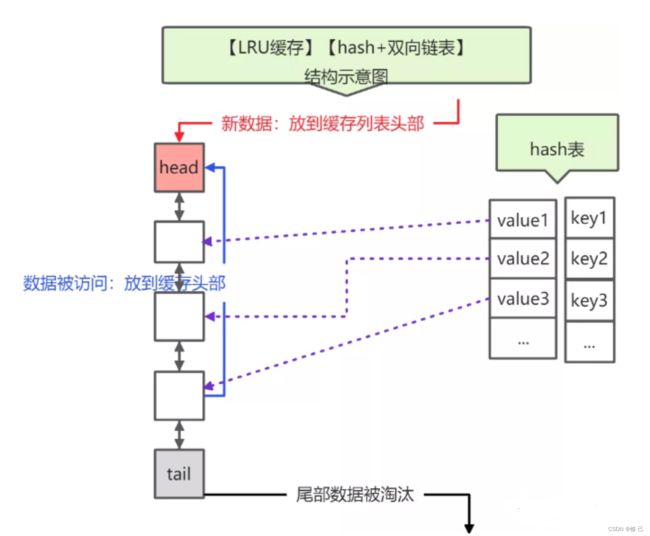
LRU(Least Recently Used)最近最少使用。优先淘汰最近未被使用的数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。LRU底层结构是 hash 表 + 双向链表。hash 表用于保证查询操作的时间复杂度是O(1),双向链表用于保证节点插入、节点删除的时间复杂度是O(1)。
为什么是 双向链表而不是单链表呢?单链表可以实现头部插入新节点、尾部删除旧节点的时间复杂度都是O(1),但是对于中间节点时间复杂度是O(n),因为对于中间节点c,我们需要将该节点c移动到头部,此时只知道它的下一个节点,要知道其上一个节点需要遍历整个链表,时间复杂度为O(n)。
LRU GET操作:如果节点存在,则将该节点移动到链表头部,并返回节点值;
LRU PUT操作:①节点不存在,则新增节点,并将该节点放到链表头部;②节点存在,则更新节点,并将该节点放到链表头部。
【LRU缓存】【hash+双向链表】结构示意图如下:
2 近似LRU算法原理(approximated LRU algorithm)
Redis为什么不使用原生LRU算法?
- 原生LRU算法需要 双向链表 来管理数据,需要额外内存;
- 数据访问时涉及数据移动,有性能损耗;
- Redis现有数据结构需要改造;
在Redis中,Redis的key的底层结构是 redisObject,redisObject 中 lru: LRU_BITS 字段用于记录该key最近一次被访问时的Redis时钟 server.lruclock(Redis在处理数据时,都会调用lookupKey方法用于更新该key的时钟)。不太理解Redis时钟的,可以将其先简单理解成时间戳(不影响我们理解近似LRU算法原理。
# Redis的key的底层结构,源码位于:server.h
typedef struct redisObject {
unsigned type:4; // 类型
unsigned encoding:4; // 编码
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; // 引用计数
void *ptr; // 指向存储实际值的数据结构的指针,数据结构由 type、encoding 决定。
} robj;
当 mem_used > maxmemory 时,Redis通过 freeMemoryIfNeeded 方法完成数据淘汰。LRU策略淘汰核心逻辑在 evictionPoolPopulate(淘汰数据集合填充) 方法。
Redis 近似LRU 淘汰策略逻辑:
首次淘汰:随机抽样选出【最多N个数据】放入【待淘汰数据池 evictionPoolEntry】;
- 数据量N:由 redis.conf 配置的 maxmemory-samples 决定,默认值是5,配置为10将非常接近真实LRU效果,但是更消耗CPU;
再次淘汰:随机抽样选出【最多N个数据】,只要数据比【待淘汰数据池 evictionPoolEntry】中的【任意一条】数据的 lru 小,则将该数据填充至 【待淘汰数据池】;
执行淘汰:挑选【待淘汰数据池】中 lru 最小的一条数据进行淘汰;
Redis为了避免长时间或一直找不到足够的数据填充【待淘汰数据池】,代码里(dictGetSomeKeys 方法)强制写死了单次寻找数据的最大次数是 [maxsteps = count*10; ],count 的值其实就是 maxmemory-samples。
[
](https://blog.csdn.net/qq_37286668/article/details/110631680)
Redis的LFU算法
LFU:Least Frequently Used,使用频率最少的(最不经常使用的):
优先淘汰最近使用的少的数据,其核心思想是“如果一个数据在最近一段时间很少被访问到,那么将来被访问的可能性也很小”。
3 LFU与LRU的区别
如果一条数据仅仅是突然被访问(有可能后续将不再访问),在 LRU 算法下,此数据将被定义为热数据,最晚被淘汰。但实际生产环境下,我们很多时候需要计算的是一段时间下key的访问频率,淘汰此时间段内的冷数据。LFU 算法相比 LRU,在某些情况下可以提升 数据命中率,使用频率更多的数据将更容易被保留。
| 对比项 | 近似LRU算法 | LFU算法 |
|---|---|---|
| 最先过期的数据 | 最近未被访问的 | 最近一段时间访问的最少的 |
| 适用场景 | 数据被连续访问场景 | 数据在一段时间内被连续访问 |
| 缺点 | 新增key将占据缓存 | 历史访问次数超大的key淘汰速度取决于lfu-decay-time |
4 LFU算法原理
LFU 使用 Morris counter 概率计数器,仅使用几比特就可以维护 访问频率,Morris算法利用随机算法来增加计数,在 Morris 算法中,计数不是真实的计数,它代表的是实际计数的量级。
LFU数据淘汰策略下,redisObject 的 lru:LRU_BITS 字段(24位)将分为2部分存储:
- Ldt:last decrement time,16位,精度分钟,存储上一次 LOG_C 更新的时间。
- LOG_C:logarithmic counter,8位,最大255,存储key被访问频率。
注意:
- LOG_C 存储的是访问频率,不是访问次数;
- LOG_C 访问频率随时间衰减;
- 为什么 LOG_C 要随时间衰减?比如在秒杀场景下,热key被访问次数很大,如果不随时间衰减,此部分key将一直存放于内存中。
- 新对象 的 LOG_C 值 为 LFU_INIT_VAL = 5,避免刚被创建即被淘汰。
Redis 数据淘汰示意图:
