【数据结构基础】之图的介绍,生动形象,通俗易懂,算法入门必看
前言

本文为数据结构基础【图】 相关知识,下边将对图的基本概念,图的存储结构,图的遍历包含广度优先遍历和深度优先遍历,循环遍历数组,最小生成树,拓扑排序等进行详尽介绍~
博主主页:小新要变强 的主页
Java全栈学习路线可参考:【Java全栈学习路线】最全的Java学习路线及知识清单,Java自学方向指引,内含最全Java全栈学习技术清单~
算法刷题路线可参考:算法刷题路线总结与相关资料分享,内含最详尽的算法刷题路线指南及相关资料分享~
Java微服务开源项目可参考:企业级Java微服务开源项目(开源框架,用于学习、毕设、公司项目、私活等,减少开发工作,让您只关注业务!)

目录
文章标题
- 前言
- 目录
- 一、图的基本概念
-
- 1️⃣图的定义
- 2️⃣图的种类
- 3️⃣邻接点和度
- 4️⃣路径和回路
- 5️⃣连通图和连通分量
- 6️⃣权
- 二、图的存储结构
-
- 1️⃣邻接矩阵
- 2️⃣邻接表
- 三、图的遍历
-
- 1️⃣广度优先搜索
- 2️⃣深度优先搜索
- 四、最小生成树
-
- 1️⃣最小生成树概念
- 2️⃣克鲁斯卡尔(Kruskal)算法
- 3️⃣普里姆(Prim)算法
- 五、拓扑排序
-
- 1️⃣拓扑排序介绍
- 2️⃣拓扑排序的算法图解
- 3️⃣拓扑排序的代码实现
- 后记
一、图的基本概念
1️⃣图的定义
定义: 图(graph)是由一些点(vertex)和这些点之间的连线(edge)所组成的;其中,点通常被成为"顶点(vertex)“,而点与点之间的连线则被成为"边或弧”(edege)。通常记为,G=(V,E)。
2️⃣图的种类
根据边是否有方向,将图可以划分为:无向图 和有向图。
(1)无向图

上面的图G0是无向图,无向图的所有的边都是不区分方向的。G0=(V1,{E1})。其中:
- (1)V1={A,B,C,D,E,F}。 V1表示由"A,B,C,D,E,F"几个顶点组成的集合。
- (2)E1={(A,B),(A,C),(B,C),(B,E),(B,F),(C,F), (C,D),(E,F),(C,E)}。E1是由边(A,B),边(A,C)…等组成的集合。其中,(A,C)表示由顶点A和顶点C连接成的边。
(2)有向图
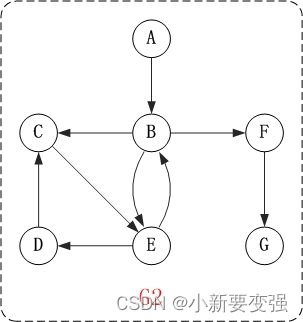
上面的图G2是有向图。和无向图不同,有向图的所有的边都是有方向的! G2=(V2,{A2})。其中:
- (1)V2={A,C,B,F,D,E,G}。 V2表示由"A,B,C,D,E,F,G"几个顶点组成的集合。
- (2)A2={
3️⃣邻接点和度
(1)邻接点
- (1)一条边上的两个顶点叫做邻接点。 例如,上面无向图G0中的顶点A和顶点C就是邻接点。
- (2)在有向图中,除了邻接点之外;还有"入边"和"出边"的概念。顶点的入边,是指以该顶点为终点的边。而顶点的出边,则是指以该顶点为起点的边。例如,上面有向图G2中的B和E是邻接点;
(2)度
- (1)在无向图中,某个顶点的度是邻接到该顶点的边(或弧)的数目。 例如,上面无向图G0中顶点A的度是2。
- (2)在有向图中,度还有"入度"和"出度"之分。某个顶点的入度,是指以该顶点为终点的边的数目。而顶点的出度,则是指以该顶点为起点的边的数目。 顶点的度=入度+出度。例如,上面有向图G2中,顶点B的入度是2,出度是3;顶点B的度=2+3=5。
4️⃣路径和回路
- 路径: 如果顶点(Vm)到顶点(Vn)之间存在一个顶点序列。则表示Vm到Vn是一条路径。
- 路径长度: 路径中"边的数量"。
- 简单路径: 若一条路径上顶点不重复出现,则是简单路径。
- 回路: 若路径的第一个顶点和最后一个顶点相同,则是回路。
- 简单回路: 第一个顶点和最后一个顶点相同,其它各顶点都不重复的回路则是简单回路。
5️⃣连通图和连通分量
- 连通图: 对无向图而言,任意两个顶点之间都存在一条无向路径,则称该无向图为连通图。 对有向图而言,若图中任意两个顶点之间都存在一条有向路径,则称该有向图为强连通图。
- 连通分量: 非连通图中的各个连通子图称为该图的连通分量。
6️⃣权
在学习"哈夫曼树"的时候,了解过"权"的概念。图中权的概念与此类似。
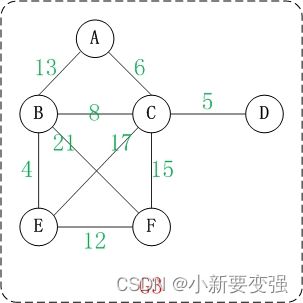
上面就是一个带权的图。
二、图的存储结构
图的存储结构,常用的是"邻接矩阵"和"邻接表"。
1️⃣邻接矩阵
邻接矩阵是指用矩阵来表示图。它是采用矩阵来描述图中顶点之间的关系(及弧或边的权)。
假设图中顶点数为n,则邻接矩阵定义为:

下面通过示意图来进行解释。

图中的G1是无向图和它对应的邻接矩阵。

图中的G2是无向图和它对应的邻接矩阵。
通常采用两个数组来实现邻接矩阵:一个一维数组用来保存顶点信息,一个二维数组来用保存边的信息。
邻接矩阵的缺点就是比较耗费空间。
2️⃣邻接表
邻接表是图的一种链式存储表示方法。它是改进后的"邻接矩阵",它的缺点是不方便判断两个顶点之间是否有边,但是相对邻接矩阵来说更省空间。
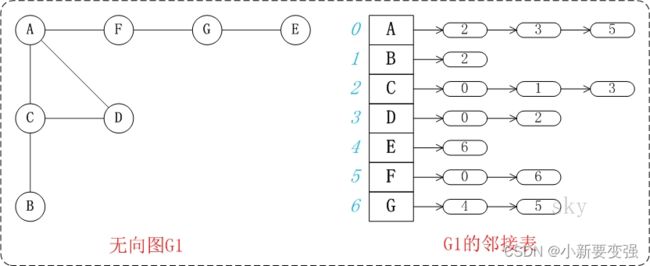
图中的G1是无向图和它对应的邻接矩阵。

图中的G2是无向图和它对应的邻接矩阵。
三、图的遍历
对于图而言,我们常用的遍历方式有bfs和dfs两种:
- bfs:广度优先搜索算法,英文Breadth First Search。广度优先搜索会优先访问当前顶点的所有邻接结点。
- dfs:深度优先搜索算法,英文Depth First Search。深度优先搜索会优先顺延访问当前节点分支进行访问,直到不能深入,每个节点只访问一次。
1️⃣广度优先搜索
(1)广度优先搜索介绍
- 广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索",简称BFS。
- 它的思想是:从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
- 换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远,依次访问和v有路径相通且路径长度为1,2…的顶点。
(2)广度优先搜索图解
无向图的广度优先搜索:
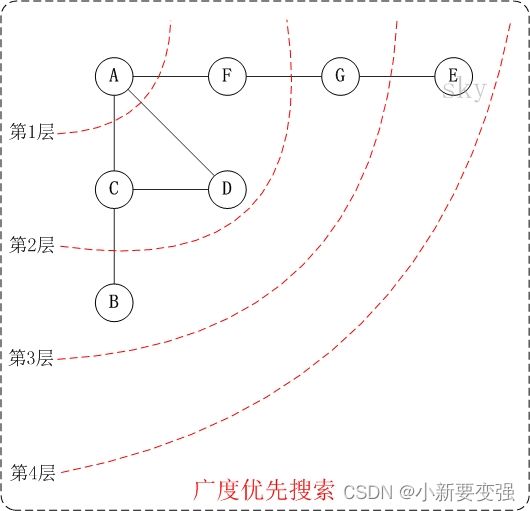
- 第1步:访问A。
- 第2步:依次访问C,D,F。在访问了A之后,接下来访问A的邻接点。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,C在"D和F"的前面,因此,先访问C。再访问完C之后,再依次访问D,F。
- 第3步:依次访问B,G。在第2步访问完C,D,F之后,再依次访问它们的邻接点。首先访问C的邻接点B,再访问F的邻接点G。
- 第4步:访问E。 在第3步访问完B,G之后,再依次访问它们的邻接点。只有G有邻接点E,因此访问G的邻接点E。
因此访问顺序是:A -> C -> D -> F -> B -> G -> E
有向图的广度优先搜索:

- 第1步:访问A。
- 第2步:访问B。
- 第3步:依次访问C,E,F。在访问了B之后,接下来访问B的出边的另一个顶点,即C,E,F。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,因此会先访问C,再依次访问E,F。
- 第4步:依次访问D,G。 在访问完C,E,F之后,再依次访问它们的出边的另一个顶点。还是按照C,E,F的顺序访问,C的已经全部访问过了,那么就只剩下E,F;先访问E的邻接点D,再访问F的邻接点G。
因此访问顺序是:A -> B -> C -> E -> F -> D -> G
(3)广度优先搜索代码实现
public class Graph {
/**
* 定义顶点的抽象
* @param
*/
public static class Vertex<T>{
// 要保存的数据
private T t;
// 其他和我管理的邻接节点
private List<Vertex<T>> neighborList;
private boolean visited = false;
public Vertex(T t) {
this.t = t;
}
}
// bfs 广度优先遍历算法
public static <T> void bfs(Vertex<T> vertex){
// 1、定义一个临时存储的空间,使用队列
Queue<Vertex<T>> queue = new ArrayBlockingQueue<>(8);
// 2、增加一个用来保存已经遍历过的数据的集合
HashSet<Vertex<T>> mome = new HashSet<>(8);
// 3、将第一个顶点放入队列
queue.add(vertex);
while (!queue.isEmpty()){
// 将第一个元素拿出来
Vertex<T> temp = queue.poll();
// 进行操作
if (!mome.contains(temp)){
System.out.println(temp.t);
mome.add(temp);
}
// 将他所有的邻接节点放进去
if(temp.neighborList != null){
queue.addAll(temp.neighborList);
}
}
}
}
2️⃣深度优先搜索
(1)深度优先搜索介绍
- 图的深度优先搜索(Depth First Search),和树的先序遍历比较类似。
- 它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
- 深度优先搜索是一个递归的过程。
(2)深度优先搜索图解
无向图的深度优先搜索:

对上面的图G1进行深度优先遍历,从顶点A开始
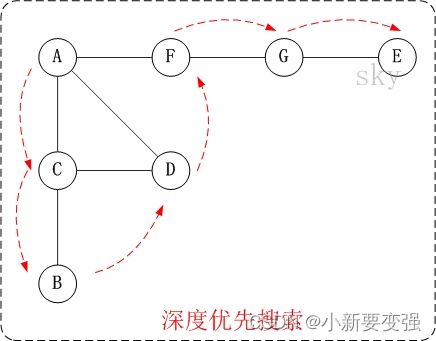
- 第1步:访问A。
- 第2步:访问(A的邻接点)C。 在第1步访问A之后,接下来应该访问的是A的邻接点,即"C,D,F"中的一个。但在本文的实现中,顶点ABCDEFG是按照顺序存储,C在"D和F"的前面,因此,先访问C。
- 第3步:访问(C的邻接点)B。 在第2步访问C之后,接下来应该访问C的邻接点,即"B和D"中一个(A已经被访问过,就不算在内)。而由于B在D之前,先访问B。
- 第4步:访问(C的邻接点)D。 在第3步访问了C的邻接点B之后,B没有未被访问的邻接点;因此,返回到访问C的另一个邻接点D。
- 第5步:访问(A的邻接点)F。 前面已经访问了A,并且访问完了"A的邻接点B的所有邻接点(包括递归的邻接点在内)";因此,此时返回到访问A的另一个邻接点F。
- 第6步:访问(F的邻接点)G。
- 第7步:访问(G的邻接点)E。
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
有向图的深度优先搜索:

对上面的图G2进行深度优先遍历,从顶点A开始。

- 第1步:访问A。
- 第2步:访问B。 在访问了A之后,接下来应该访问的是A的出边的另一个顶点,即顶点B。
- 第3步:访问C。在访问了B之后,接下来应该访问的是B的出边的另一个顶点,即顶点C,E,F。在本文实现的图中,顶点ABCDEFG按照顺序存储,因此先访问C。
- 第4步:访问E。 接下来访问C的出边的另一个顶点,即顶点E。
- 第5步:访问D。 接下来访问E的出边的另一个顶点,即顶点B,D。顶点B已经被访问过,因此访问顶点D。
- 第6步:访问F。 接下应该回溯"访问A的出边的另一个顶点F"。
- 第7步:访问G。
因此访问顺序是:A -> B -> C -> E -> D -> F -> G
(3)深度优先搜索代码实现
public class Graph {
/**
* 定义顶点的抽象
* @param
*/
public static class Vertex<T>{
// 要保存的数据
private T t;
// 其他和我管理的邻接节点
private List<Vertex<T>> neighborList;
private boolean visited = false;
public Vertex(T t) {
this.t = t;
}
}
// dfs 深度优先遍历算法
public static <T> void dfs(Vertex<T> vertex){
// 1、定义一个临时存储的空间
Stack<Vertex<T>> stack = new Stack<>();
// 2、将第一个顶点放入栈中
stack.push(vertex);
while (!stack.isEmpty()){
// 3、将栈顶的元素取出
Vertex<T> temp = stack.pop();
// 4、执行操作
if(!temp.visited){
System.out.println(temp.t);
temp.visited = true;
}
// 5、将邻接节点压栈
if(temp.neighborList != null){
stack.addAll(temp.neighborList);
}
}
}
}
四、最小生成树
1️⃣最小生成树概念
在含有n个顶点的连通图中选择n-1条边,构成一棵极小连通子图,并使该连通子图中n-1条边上权值之和达到最小,则称其为连通网的最小生成树。
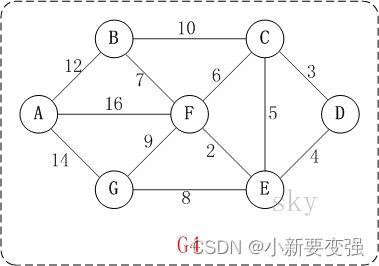
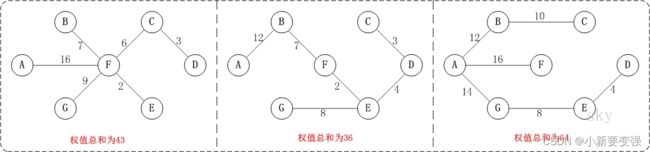
例如,对于如上图G4所示的连通网可以有多棵权值总和不相同的生成树。
2️⃣克鲁斯卡尔(Kruskal)算法
(1)克鲁斯卡尔算法介绍
- 克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。
- 基本思想: 按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
- 具体做法: 首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
(2)克鲁斯卡尔算法图解
以上图G4为例,来对克鲁斯卡尔进行演示(假设,用数组R保存最小生成树结果)。
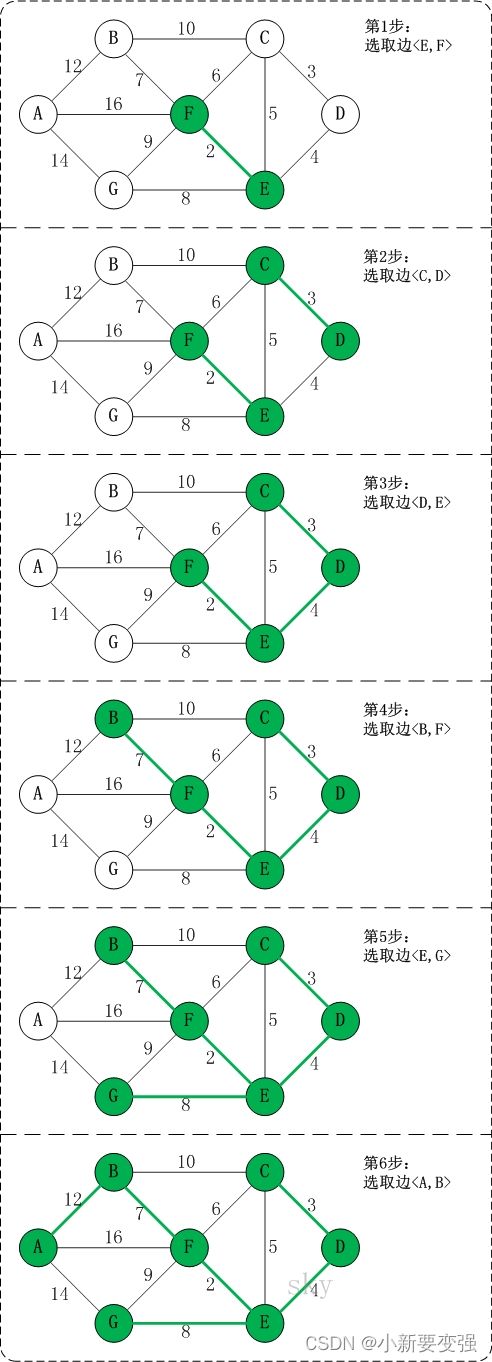
- 第1步:将边
- 第2步:将边
- 第3步:将边
- 第4步:将边
- 第5步:将边
- 第6步:将边
此时,最小生成树构造完成!它包括的边依次是:
(3)克鲁斯卡尔算法代码实现
这里选取"邻接矩阵"对克鲁斯卡尔算法进行说明。
// 边的结构体
private static class EData {
char start; // 边的起点
char end; // 边的终点
int weight; // 边的权重
public EData(char start, char end, int weight) {
this.start = start;
this.end = end;
this.weight = weight;
}
}
// 邻接矩阵边对应的结构体
public class MatrixUDG {
private int mEdgNum; // 边的数量
private char[] mVexs; // 顶点集合
private int[][] mMatrix; // 邻接矩阵
private static final int INF = Integer.MAX_VALUE; // 最大值
...
}
/*
* 克鲁斯卡尔(Kruskal)最小生成树
*/
public void kruskal() {
int index = 0; // rets数组的索引
int[] vends = new int[mEdgNum]; // 用于保存"已有最小生成树"中每个顶点在该最小树中的终点。
EData[] rets = new EData[mEdgNum]; // 结果数组,保存kruskal最小生成树的边
EData[] edges; // 图对应的所有边
// 获取"图中所有的边"
edges = getEdges();
// 将边按照"权"的大小进行排序(从小到大)
sortEdges(edges, mEdgNum);
for (int i=0; i<mEdgNum; i++) {
int p1 = getPosition(edges[i].start); // 获取第i条边的"起点"的序号
int p2 = getPosition(edges[i].end); // 获取第i条边的"终点"的序号
int m = getEnd(vends, p1); // 获取p1在"已有的最小生成树"中的终点
int n = getEnd(vends, p2); // 获取p2在"已有的最小生成树"中的终点
// 如果m!=n,意味着"边i"与"已经添加到最小生成树中的顶点"没有形成环路
if (m != n) {
vends[m] = n; // 设置m在"已有的最小生成树"中的终点为n
rets[index++] = edges[i]; // 保存结果
}
}
// 统计并打印"kruskal最小生成树"的信息
int length = 0;
for (int i = 0; i < index; i++)
length += rets[i].weight;
System.out.printf("Kruskal=%d: ", length);
for (int i = 0; i < index; i++)
System.out.printf("(%c,%c) ", rets[i].start, rets[i].end);
System.out.printf("\n");
}
3️⃣普里姆(Prim)算法
(1)普里姆算法介绍
- 普里姆(Prim)算法,是用来求加权连通图的最小生成树的算法。
- 基本思想 : 对于图G而言,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U用于存放G的最小生成树中的顶点,T存放G的最小生成树中的边。从所有uЄU,vЄ(V-U) (V-U表示出去U的所有顶点)的边中选取权值最小的边(u, v),将顶点v加入集合U中,将边(u, v)加入集合T中,如此不断重复,直到U=V为止,最小生成树构造完毕,这时集合T中包含了最小生成树中的所有边。
(2)普里姆算法图解

以上图G4为例,来对普里姆进行演示(从第一个顶点A开始通过普里姆算法生成最小生成树)。

初始状态:V是所有顶点的集合,即V={A,B,C,D,E,F,G};U和T都是空!
- 第1步:将顶点A加入到U中。 此时,U={A}。
- 第2步:将顶点B加入到U中。 上一步操作之后,U={A}, V-U={B,C,D,E,F,G};因此,边(A,B)的权值最小。将顶点B添加到U中;此时,U={A,B}。
- 第3步:将顶点F加入到U中。 上一步操作之后,U={A,B}, V-U={C,D,E,F,G};因此,边(B,F)的权值最小。将顶点F添加到U中;此时,U={A,B,F}。
- 第4步:将顶点E加入到U中。 上一步操作之后,U={A,B,F}, V-U={C,D,E,G};因此,边(F,E)的权值最小。将顶点E添加到U中;此时,U={A,B,F,E}。
- 第5步:将顶点D加入到U中。 上一步操作之后,U={A,B,F,E},V-U={C,D,G};因此,边(E,D)的权值最小。将顶点D添加到U中;此时,U={A,B,F,E,D}。
- 第6步:将顶点C加入到U中。 上一步操作之后,U={A,B,F,E,D}, V-U={C,G};因此,边(D,C)的权值最小。将顶点C添加到U中;此时,U={A,B,F,E,D,C}。
- 第7步:将顶点G加入到U中。 上一步操作之后,U={A,B,F,E,D,C}, V-U={G};因此,边(F,G)的权值最小。将顶点G添加到U中;此时,U=V。
此时,最小生成树构造完成!它包括的顶点依次是:A B F E D C G。
(3)普里姆算法代码实现
这里以"邻接矩阵"为例对普里姆算法进行说明。
// 邻接矩阵对应的结构体
public class MatrixUDG {
private char[] mVexs; // 顶点集合
private int[][] mMatrix; // 邻接矩阵
private static final int INF = Integer.MAX_VALUE; // 最大值
...
}
/*
* prim最小生成树
*
* 参数说明:
* start -- 从图中的第start个元素开始,生成最小树
*/
public void prim(int start) {
int num = mVexs.length; // 顶点个数
int index=0; // prim最小树的索引,即prims数组的索引
char[] prims = new char[num]; // prim最小树的结果数组
int[] weights = new int[num]; // 顶点间边的权值
// prim最小生成树中第一个数是"图中第start个顶点",因为是从start开始的。
prims[index++] = mVexs[start];
// 初始化"顶点的权值数组",
// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
for (int i = 0; i < num; i++ )
weights[i] = mMatrix[start][i];
// 将第start个顶点的权值初始化为0。
// 可以理解为"第start个顶点到它自身的距离为0"。
weights[start] = 0;
for (int i = 0; i < num; i++) {
// 由于从start开始的,因此不需要再对第start个顶点进行处理。
if(start == i)
continue;
int j = 0;
int k = 0;
int min = INF;
// 在未被加入到最小生成树的顶点中,找出权值最小的顶点。
while (j < num) {
// 若weights[j]=0,意味着"第j个节点已经被排序过"(或者说已经加入了最小生成树中)。
if (weights[j] != 0 && weights[j] < min) {
min = weights[j];
k = j;
}
j++;
}
// 经过上面的处理后,在未被加入到最小生成树的顶点中,权值最小的顶点是第k个顶点。
// 将第k个顶点加入到最小生成树的结果数组中
prims[index++] = mVexs[k];
// 将"第k个顶点的权值"标记为0,意味着第k个顶点已经排序过了(或者说已经加入了最小树结果中)。
weights[k] = 0;
// 当第k个顶点被加入到最小生成树的结果数组中之后,更新其它顶点的权值。
for (j = 0 ; j < num; j++) {
// 当第j个节点没有被处理,并且需要更新时才被更新。
if (weights[j] != 0 && mMatrix[k][j] < weights[j])
weights[j] = mMatrix[k][j];
}
}
// 计算最小生成树的权值
int sum = 0;
for (int i = 1; i < index; i++) {
int min = INF;
// 获取prims[i]在mMatrix中的位置
int n = getPosition(prims[i]);
// 在vexs[0...i]中,找出到j的权值最小的顶点。
for (int j = 0; j < i; j++) {
int m = getPosition(prims[j]);
if (mMatrix[m][n]<min)
min = mMatrix[m][n];
}
sum += min;
}
// 打印最小生成树
System.out.printf("PRIM(%c)=%d: ", mVexs[start], sum);
for (int i = 0; i < index; i++)
System.out.printf("%c ", prims[i]);
System.out.printf("\n");
}
五、拓扑排序
1️⃣拓扑排序介绍
- 拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph简称DAG)进行排序进而得到一个有序的线性序列。
- 通过简单的例子进行说明:例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序,它就是用来确定事物发生的顺序的。
- 在拓扑排序中,如果存在一条从顶点A到顶点B的路径,那么在排序结果中B出现在A的后面。
2️⃣拓扑排序的算法图解
拓扑排序算法的基本步骤:
- 1.构造一个队列Q(queue) 和 拓扑排序的结果队列T(topological);
- 2.把所有没有依赖顶点的节点放入Q;
- 3.当Q还有顶点的时候,执行下面步骤:
- 3.1 从Q中取出一个顶点n(将n从Q中删掉),并放入T(将n加入到结果集中);
- 3.2 对n每一个邻接点m(n是起点,m是终点):
- 3.2.1 去掉边
- 3.2.2 如果m没有依赖顶点,则把m放入Q。
- 3.2.1 去掉边
注:顶点A没有依赖顶点,是指不存在以A为终点的边。
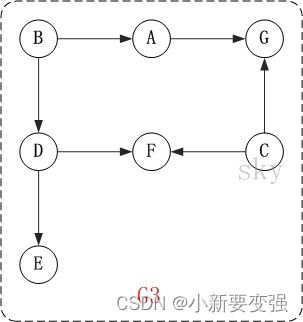
以上图为例,来对拓扑排序进行演示。
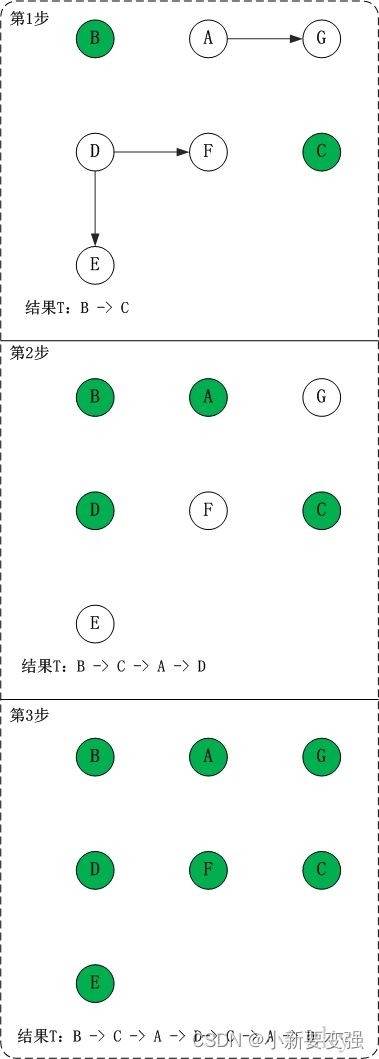
- 第1步:将B和C加入到排序结果中。顶点B和顶点C都是没有依赖顶点,因此将C和C加入到结果集T中。假设ABCDEFG按顺序存储,因此先访问B,再访问C。访问B之后,去掉边
- (1) 将B加入到排序结果中,然后去掉边
- (2) 将C加入到排序结果中,然后去掉边
- (1) 将B加入到排序结果中,然后去掉边
- 第2步:将A,D依次加入到排序结果中。第1步访问之后,A,D都是没有依赖顶点的,根据存储顺序,先访问A,然后访问D。访问之后,删除顶点A和顶点D的出边。
- 第3步:将E,F,G依次加入到排序结果中。
因此访问顺序是:B -> C -> A -> D -> E -> F -> G
3️⃣拓扑排序的代码实现
拓扑排序是对有向无向图的排序。下面以邻接表实现的有向图来对拓扑排序进行说明。
// 邻接表对应的结构体
public class ListDG {
// 邻接表中表对应的链表的顶点
private class ENode {
int ivex; // 该边所指向的顶点的位置
ENode nextEdge; // 指向下一条弧的指针
}
// 邻接表中表的顶点
private class VNode {
char data; // 顶点信息
ENode firstEdge; // 指向第一条依附该顶点的弧
};
private VNode[] mVexs; // 顶点数组
...
}
/*
* 拓扑排序
*
* 返回值:
* -1 -- 失败(由于内存不足等原因导致)
* 0 -- 成功排序,并输入结果
* 1 -- 失败(该有向图是有环的)
*/
public int topologicalSort() {
int index = 0;
int num = mVexs.size();
int[] ins; // 入度数组
char[] tops; // 拓扑排序结果数组,记录每个节点的排序后的序号。
Queue<Integer> queue; // 辅组队列
ins = new int[num];
tops = new char[num];
queue = new LinkedList<Integer>();
// 统计每个顶点的入度数
for(int i = 0; i < num; i++) {
ENode node = mVexs.get(i).firstEdge;
while (node != null) {
ins[node.ivex]++;
node = node.nextEdge;
}
}
// 将所有入度为0的顶点入队列
for(int i = 0; i < num; i ++)
if(ins[i] == 0)
queue.offer(i); // 入队列
while (!queue.isEmpty()) { // 队列非空
int j = queue.poll().intValue(); // 出队列。j是顶点的序号
tops[index++] = mVexs.get(j).data; // 将该顶点添加到tops中,tops是排序结果
ENode node = mVexs.get(j).firstEdge;// 获取以该顶点为起点的出边队列
// 将与"node"关联的节点的入度减1;
// 若减1之后,该节点的入度为0;则将该节点添加到队列中。
while(node != null) {
// 将节点(序号为node.ivex)的入度减1。
ins[node.ivex]--;
// 若节点的入度为0,则将其"入队列"
if( ins[node.ivex] == 0)
queue.offer(node.ivex); // 入队列
node = node.nextEdge;
}
}
if(index != num) {
System.out.printf("Graph has a cycle\n");
return 1;
}
// 打印拓扑排序结果
System.out.printf("== TopSort: ");
for(int i = 0; i < num; i ++)
System.out.printf("%c ", tops[i]);
System.out.printf("\n");
return 0;
}
后记

Java全栈学习路线可参考:【Java全栈学习路线】最全的Java学习路线及知识清单,Java自学方向指引,内含最全Java全栈学习技术清单~
算法刷题路线可参考:算法刷题路线总结与相关资料分享,内含最详尽的算法刷题路线指南及相关资料分享~