JAVA集合:HashMap
本篇内容包括:HashMap 概述、底层数据结构、扩容机制、线程不安全性以及 HashMap 的使用。
一、HashMap 概述
HashMap 根据是一个键值对集合,采用 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。HashMap 最多只允许一条记录的键为 null。
HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。
二、底层数据结构
HashMap 的主体为数组,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。
JDK1.8 之后 HashMap 的组成多了红黑树,在满足下面两个条件之后,会执行链表转红黑树操作,以此来加快搜索速度。
- 链表长度大于阈值(默认为 8)
- HashMap 数组长度超过 64
我们用下面这张图来介绍HashMap 的结构。
1、JAVA7 实现
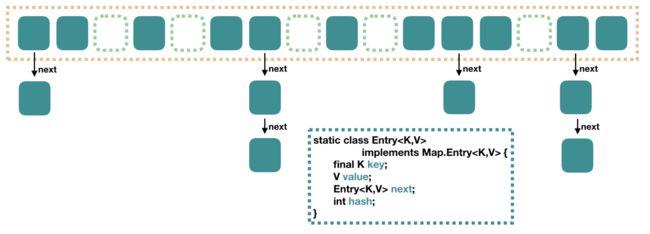
JDK1.8 之前 HashMap 里面是一个数组,数组中每个元素是一个单向链表。
上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key,value,hash 值和用于单向链表的 next
-
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。 -
loadFactor:负载因子,默认为 0.75。 -
threshold:扩容的阈值,等于capacity * loadFactor
2、JAVA8 实现
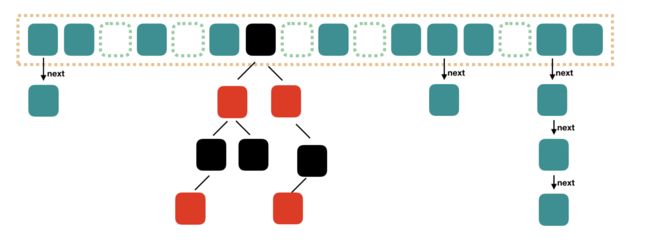
Java8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑树 组成。
根据 Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。为了降低这部分的开销,在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
三、HashMap 的扩容机制
为了方便说明,这里明确几个名词:
- capacity :即容量,默认16。
- loadFactor :加载因子,默认是0.75
- threshold :阈值,阈值=容量*加载因子。默认12。当元素数量超过阈值时便会触发扩容
1、什么时候触发扩容?
一般情况下,当元素数量超过阈值时便会触发扩容。每次扩容的容量都是之前容量的2倍
2、JDK7中的扩容机制
JDK7的扩容机制相对简单,有以下特性:
- 空参数的构造函数:以默认容量、默认负载因子、默认阈值初始化数组。内部数组是空数组。
- 有参构造函数:根据参数确定容量、负载因子、阈值等。
- 第一次put时会初始化数组,其容量变为不小于指定容量的2的幂数。然后根据负载因子确定阈值。
- 如果不是第一次扩容,则
新阈值 = 新容量 X 负载因子
3、JDK8的扩容机制
JDK8的扩容做了许多调整。
HashMap的容量变化通常存在以下几种情况:
- 空参数的构造函数:实例化的HashMap默认内部数组是null,即没有实例化。第一次调用put方法时,则会开始第一次初始化扩容,长度为16。
- 有参构造函数:用于指定容量。会根据指定的正整数找到不小于指定容量的2的幂数,将这个数设置赋值给阈值(threshold)。第一次调用put方法时,会将阈值赋值给容量,然后让
阈值 = 容量 X 负载因子(因此并不是我们手动指定了容量就一定不会触发扩容,超过阈值后一样会扩容!!) - 如果不是第一次扩容,则容量变为原来的2倍,阈值也变为原来的2倍。(容量和阈值都变为原来的2倍时,负载因子还是不变)
此外还有几个细节需要注意:
- 首次put时,先会触发扩容(算是初始化),然后存入数据,然后判断是否需要扩容;
- 不是首次put,则不再初始化,直接存入数据,然后判断是否需要扩容;
4、JDK7的元素迁移
JDK7中,HashMap的内部数据保存的都是链表。因此逻辑相对简单:在准备好新的数组后,map会遍历数组的每个“桶”,然后遍历桶中的每个Entity,重新计算其hash值(也有可能不计算),找到新数组中的对应位置,以头插法插入新的链表。
这里有几个注意点:
- 是否要重新计算hash值的条件这里不深入讨论,读者可自行查阅源码。
- 因为是头插法,因此新旧链表的元素位置会发生转置现象。
- 元素迁移的过程中在多线程情境下有可能会触发死循环(无限进行链表反转)。
5、JDK8的元素迁移
JDK8则因为巧妙的设计,性能有了大大的提升:由于数组的容量是以2的幂次方扩容的,那么一个Entity在扩容时,新的位置要么在原位置,要么在 原长度+原位置 的位置。原因如下图:
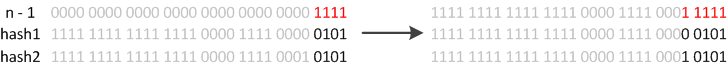
数组长度变为原来的2倍,表现在二进制上就是多了一个高位参与数组下标确定。此时,一个元素通过hash转换坐标的方法计算后,恰好出现一个现象:最高位是0则坐标不变,最高位是1则坐标变为“10000+原坐标”,即“原长度+原坐标”。如下图:
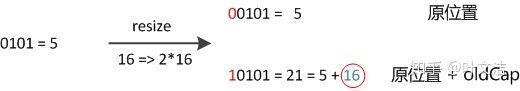
因此,在扩容时,不需要重新计算元素的hash了,只需要判断最高位是1还是0就好了。
JDK8的HashMap还有以下细节:
- JDK8在迁移元素时是正序的,不会出现链表转置的发生。
- 如果某个桶内的元素超过8个,则会将链表转化成红黑树,加快数据查询效率。
四、HashMap 的使用
1、私有属性
// 默认容量16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认负载因子0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 链表节点转换红黑树节点的阈值, 9个节点转
static final int TREEIFY_THRESHOLD = 8;
// 红黑树节点转换链表节点的阈值, 6个节点转
static final int UNTREEIFY_THRESHOLD = 6;
// 转红黑树时, table的最小长度
static final int MIN_TREEIFY_CAPACITY = 64;
// 链表节点, 继承自Entry
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// ... ...
}
// 红黑树节点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
// ...
}
2、构造方法
| 方法名 | 方法说明 | 方法名 | 方法说明 |
|---|---|---|---|
public HashMap() |
默认构造函数,构造一个具有默认初始容量(16)和默认负载因子(0.75)的空哈希映射 | public HashMap(int initialCapacity) |
用指定的初始值(初始容量)构造一个空的 HashMap ,负载因子使用默认的 |
public HashMap(int initialCapacity, float loadFactor) |
用指定的初始值(初始容量和负载因子)构造一个空的 HashMap | public HashMap(Map m) |
包含另一个“Map”的构造函数 |
3、常用方法
| 方法名 | 方法说明 | 方法名 | 方法说明 |
|---|---|---|---|
V put(K key, V value) |
元素添加 | V get(Object key) |
元素获取 |
V remove(Object key) |
删除元素 |
五、相关知识点
1、HashMap 的线程不安全
HashMap是线程不安全的,其主要体现:
- 在 Jdk1.7 中,在多线程环境下,扩容时会造成环形链或数据丢失。
- 在 Jdk1.8 中,在多线程环境下,会发生数据覆盖的情况。
关于死循环的问题,在Java8中个人认为是不存在了,在Java8之前的版本中之所以出现死循环是因为在resize的过程中对链表进行了倒序处理;在Java8中不再倒序处理,自然也不会出现死循环。
jdk7的时候,转移元素采用头插法处理。在HashMap的transfer函数中(如下代码),当table进行newTable扩容的时候需要将原先的数据进行转移,链表的顺序将发生翻转,而在此时若HashMap不断轮询,将产生死锁,酿成悲剧
假设一种情况,线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,问题出现:线程A会把线程B插入的数据给覆盖,发生线程不安全。
2、关于 LinkedHashMap
在使用 HashMap 的时候,可能会遇到需要按照当时 put 的顺序来进行哈希表的遍历。但我们知道 HashMap 中不存在保存顺序的机制。
LinkedHashMap 专为此特性而生。在 LinkedHashMap 中可以保持两种顺序,分别是插入顺序和访问顺序,这个是可以在 LinkedHashMap 的初始化方法中进行指定的。相对于访问顺序,按照插入顺序进行编排被使用到的场景更多一些,所以默认是按照插入顺序进行编排。
LinkedHashMap 相对于 HashMap,增加了双链表的结果(即节点中增加了前后指针),其他处理逻辑与 HashMap 一致,同样也没有锁保护,多线程使用存在风险。