【论文阅读笔记】Deep High-Resolution Representation Learning for Human Pose Estimation
论文地址:https://arxiv.org/abs/1902.09212
代码地址:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
论文总结
论文总得来说是提出了一种网络架构的思想:以前的模型都是下采样后再上采样,从而达到预期的分辨率。而本文的网络HRNet则一直维持高分辨率分支,通过融合低分辨率分支上采样带来的high level信息,达到重复多尺度信息的融合。网络结构入下图所示:由一个高分辨率的子网开始,后面逐渐维持多个低分辨率的子网并行进行,形成多通道子网进行联合forward的网络结构。最后只在高分辨率分支来得到预测的关键点heatmap输出。
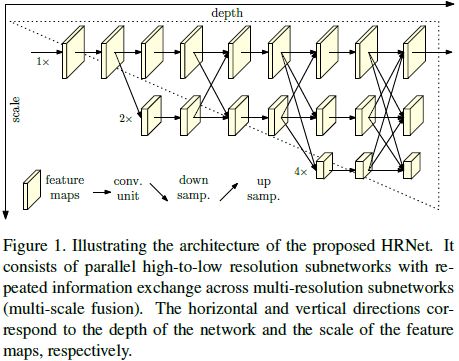
HRNet是top-down检测网络,即单人姿态估计。HRNet的训练不使用中间监督。
论文介绍
作者认为,维持高分辨率分支,而不是从低到高恢复分辨率,可以使得heatmap在空间上预测关节点更准确。
Heatmap的产生来自于最后一个融合的高分辨率特征中,直接进行回归。使用标准差为1的2D高斯核作用于ground truth heatmap,用MSE进行监督。
本文自己定了一种交换单元(exchange units),用于跨平行运行的子网进行特征融合,每个子网重复收到来自子网的信息。结构如下图所示,下面是数个exchange blocks,每个block由3个平行的卷积单元和一个跨单元的交换单元组成。
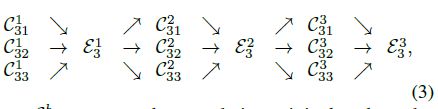
在网络的设计上,借鉴了ResNet在每个stage上的深度和每个分辨率上的channel数。
HRNet的主体部分,由4个并行的子网组成的4个阶段组成:其分辨率逐渐降低到一半,相应的宽度(channels)增加到两倍。第一阶段包含4个残差单元(residual units),每个残差单元于ResNet50相同,由宽度(channels)为64的bottleneck组成,然后接一个 3 ∗ 3 3*3 3∗3的卷积将特征的宽度映射到C。第2,3,4阶段分别包含了1、4、3个exchange blocks。每一个交换模块包含4个残差单元,每个残差单元包含2个 3 ∗ 3 3*3 3∗3的卷积在每个分辨率上。最后一共有8个交换单元,即8个多尺度融合。
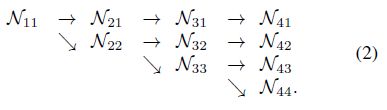
文中的实验,网络模型有两个HRNet-W32和HRNET-W48, 32 32 32和 48 48 48是表示HRNET高分辨率子网在最后3个阶段通道数。对于HRNET-W32,其他三个平行子网的通道数分别为 64 , 128 , 256 64,128,256 64,128,256;对于HRNET-W48,其他三个平行子网的通道数分别为 96 , 192 , 384 96,192,384 96,192,384。
论文实验
COCO数据集
HRNET是一个top-down模型,需要进行抠图。需要将人类检测框的高宽比扩展到 h e i g h t : w i d t h = 4 : 3 height:width=4:3 height:width=4:3,然后从这个图片中扣出来,resize到一个固定值( 256 ∗ 192 256*192 256∗192或 384 ∗ 288 384*288 384∗288)。数据增强为随机旋转( [ − 45 ° , 45 ° ] [-45°,45°] [−45°,45°]),随机尺度( [ 0.65 , 1.35 ] [0.65,1.35] [0.65,1.35])和翻转,以及涉及到半身数据的数据增强。使用的优化器为Adam,初始学习率为1e-3,在170个epoch时掉到1e-4,在200个epoch掉到1e-5,一共210个epoch。
在测试时,使用人体检测器检测人体实例,然后检测关键点。使用flip进行测试,关键点为heatmap最高点到第二点的四分之一偏差。
在验证集上,HRNET-W32,以 256 ∗ 192 256*192 256∗192分辨率作为网络输入,结果如下表所示,能达到 73.4 73.4 73.4AP,优于其他相同输入大小的方法。下面的pretrain,是在ImageNet进行分类问题的训练,能带来1个点的受益。HRNET-W48在分辨率 256 ∗ 192 256*192 256∗192和 384 ∗ 288 384*288 384∗288都有更高的受益。
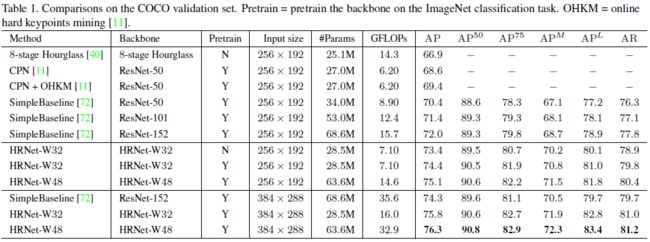
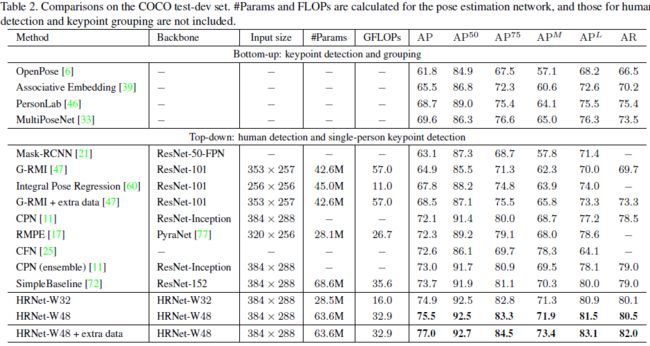
在测试集上,结果如下表所示:
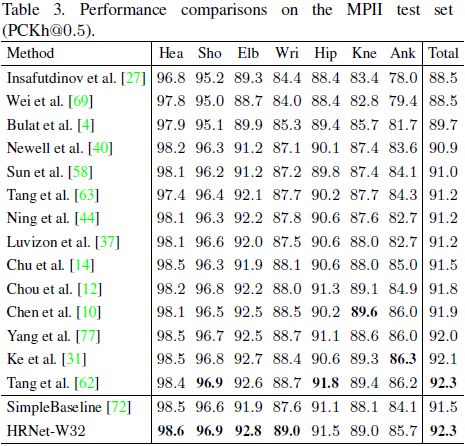
MPII
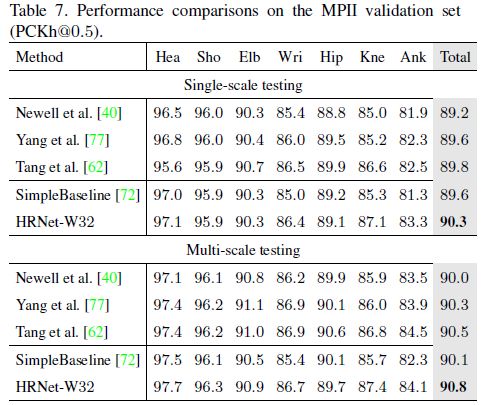
测试时,使用提供的人类检测框代替检测的人类框。输入分辨率为 256 ∗ 256 256*256 256∗256,验证指标为PCKh。结果如下图所示:
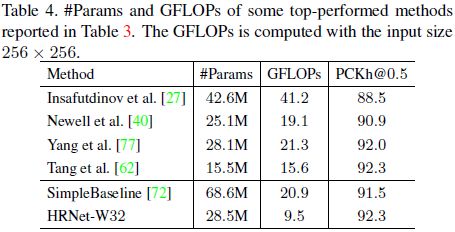
多尺度测试,对比实验如下:
PoseTrack
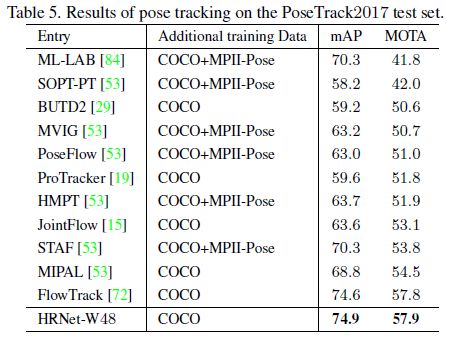
在PoseTrack数据集下的表现如下图所示:
消融学习
多尺度融合
三个交换单元导致的网络的变种:(a)没有中间的exchange units,只有最后一个exchange units;(b)只有跨stage的exchange unit,没有平行子网之间的exchange;(b)跨stage和同一个stage的exchange,是本文所建议的方法。对比结果如下图所示:

HRNet网络的变体:4个子网都从头给输入,且具有相同的深度和融合方案。该变体网络的AP为72.5,而对应的小网络HRNET-W32为73.4AP。作者认为这是因为小分辨率网络在早期提取的低级特征上并没有提供多达的帮助。此外,参数和计算复杂度相似的简单高分辨率网络,在没有低分辨率并行子网的情况下,其性能要低得多。
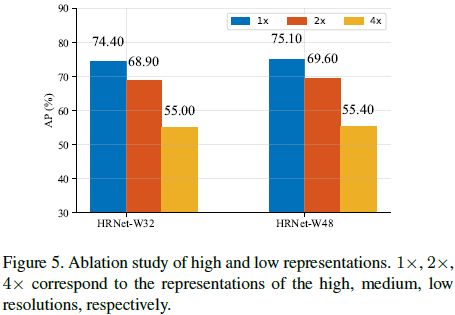
heatmap分辨率的影响,产生不同分辨率的heatmap,从高到低输出几个响应图,如下图所示:
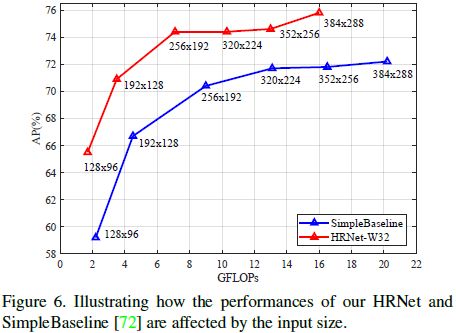
输入分辨率的影响,与SimpleBaseline对比,如下图所示,在小分辨率输入上,HRNET的优势更明显一点。