Python第三方库pandas学习笔记
Python第三方库pandas学习笔记
- pandas简介
- pandas操作命令
-
- pandas的常用数据类型
- pandas基本操作
-
- 显示基本属性
- pandas索引和切片
- 索引
- 切片
- pandas进一步操作
- 如何创建Series和DataFrame数据
-
- 读取外部数据
- 写在后面
pandas简介
都一起学习pandas了,肯定对这个库有所了解了。
pandas操作命令
pandas的常用数据类型
在讲基本操作的时候,我们应该先对要操作的东西有个了解。相比起numpy,pandas能够操作的数据类型更加多样。而在pandas中,数据通常通过两种方式进行组织。
- Series,一维的带标签数组
- DataFrame,二维的Series容器
下面这个图能够很直观地看出两种数组组织方式的特点

其中,每一列都是一个Series,然后多列组合在一起就构成了一个二维的Series容器。那么,当数据以DataFrame的格式进行组织的时候,要确定某一行某一列,需要怎么索引定位?在numpy中我们直接通过下标的方式就可以实现这一操作。而在pandas中类似,只是这个下标有时候不再是单纯的数字。
那么,从现在开始,假设我们生成了如上表的随机数据。我们可以做的操作如下
pandas基本操作
#生成上面数据的代码(来源:https://zhuanlan.zhihu.com/p/100064394)
import pandas as pd
import numpy as np
boolean=[True,False]
gender=["男","女"]
color=["white","black","yellow"]
data=pd.DataFrame({
"height":np.random.randint(150,190,10),
"weight":np.random.randint(40,90,10),
"smoker":[boolean[x] for x in np.random.randint(0,2,10)],
"gender":[gender[x] for x in np.random.randint(0,2,10)],
"age":np.random.randint(15,90,10),
"color":[color[x] for x in np.random.randint(0,len(color),10) ]
}
)
对于上面生成的随机数据,我们可以通过data.index查看他的索引,data.columns查看他的列标签。

这个索引在生成的时候,由于我们没有添加额外的信息。所以他只能默认为数字。因此,在pandas中,我们最基本的操作就是:
- 通过
data.index = 标签序列来改变数据的标签 - 也可以通过
data.set_index()来设置标签

- 同样地,还可以通过
data.colums = ['col1', 'col2'...]来改变Series的列标签
显示基本属性
DataFrame的基本属性主要有

当然,当我们获取到一些DataFrame数据的第一时间,我们还可以通过data.info()和data.describe()来快速浏览数据相关的信息
pandas索引和切片
在我们设定好合适的index和columns以后,就可以进行索引和切片操作了
索引
先讲对于Series的索引操作。对于一个DataFrame的数据组合,我们可以通过选择具体的某一列来确定一个Series。仍然用上面生成的数据为例:

这时候的height_data就是pandas里面的Series类型数据。可以进行如下操作
height_data[i]height_data[a:b:step]- 也可以进行
bool索引:height_data>170 - 也可以通过
height_data.isna()判断元素是否为NaN - 如果
index是字符串,那么我们还可以通过height_data[['小A','小B']]这样的方式显示小A和小B的身高数据
此外,在pandas中,对于DataFrame类型的数据,还可以通过标签和位置索引行数据
data.loc通过行标签进行行索引data.iloc根据位置获取行数据

切片
进而就是常用的切片操作,在bool索引的基础上,我们可以很快地根据需要进行切片操作。
- 当切片对象是
series时,通过height_data[height_data>170]可以快速的完成切片操作 - 当然,也可以利用**索引2.**进行切片
当切片对象是DataFrame的时候,可以通过如下两种方式进行切片
-
直接切片
data[1:5:2] -
根据某一个特征进行选择切片。比如我们想筛选不吸烟的所有个体。
data[data['smoker'] == False] -
当然,也可以根据身高大于等于175且不吸烟的男性进行筛选

pandas进一步操作
前面提到,在我们刚拿到数据的时候,我们可以做一些简单的操作。比如,通过.info()和.describe()等方法查看数据的基本信息。而当我们需要对数据进行统计分析的时候。比如,查看年龄最大的几个人、有多少人是不吸烟的等。因此,我们需要对数据进行排序、或者计数。
data.sort_values('height', ascending=False)将整个数据组,按照身高进行降序排序data['color'].value_counts()进行肤色频次统计
当然,我们仍然可以对int64和float数据进行基本的数理统计
data.mean()
data.max()
data.std()
data.median()
如何创建Series和DataFrame数据
直观地讲,Series里面的数据有点像字典,其中index对应的是键,而列对应的值则是键值。所以,可以直接将字典类型数据转换成pandas里面的Series数据类型。
而当字典类型包含多个值时,这个字典类型的键就会转换成DataFrame中的columns而非index。这要求每个键对应的值个数相同
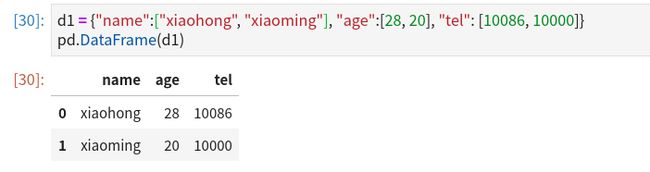
读取外部数据
很多时候,我们会通过各种途径得到一系列数据文件。以csv为例,我们直接使用pd.read_csv即可。只是刚读取得到的数据,也许需要做一些数据预处理工作。比如缺省数据如何处理
写在后面
到目前为止,只是把基本的pandas所涉及到的知识点复述了一遍。完全没有任何工作难度。权当做了个笔记。准备这周抽空将csv实例分析整理一下。那才是让我进阶不少的东西。尽管折腾也很多