【李宏毅机器学习笔记】2、error产生自哪里?
【李宏毅机器学习笔记】1、回归问题(Regression)
【李宏毅机器学习笔记】2、error产生自哪里?
【李宏毅机器学习笔记】3、gradient descent
【李宏毅机器学习笔记】4、Classification
【李宏毅机器学习笔记】5、Logistic Regression
【李宏毅机器学习笔记】6、简短介绍Deep Learning
【李宏毅机器学习笔记】7、反向传播(Backpropagation)
【李宏毅机器学习笔记】8、Tips for Training DNN
【李宏毅机器学习笔记】9、Convolutional Neural Network(CNN)
【李宏毅机器学习笔记】10、Why deep?(待填坑)
【李宏毅机器学习笔记】11、 Semi-supervised
【李宏毅机器学习笔记】 12、Unsupervised Learning - Linear Methods
【李宏毅机器学习笔记】 13、Unsupervised Learning - Word Embedding(待填坑)
【李宏毅机器学习笔记】 14、Unsupervised Learning - Neighbor Embedding(待填坑)
【李宏毅机器学习笔记】 15、Unsupervised Learning - Auto-encoder(待填坑)
【李宏毅机器学习笔记】 16、Unsupervised Learning - Deep Generative Model(待填坑)
【李宏毅机器学习笔记】 17、迁移学习(Transfer Learning)
【李宏毅机器学习笔记】 18、支持向量机(Support Vector Machine,SVM)
【李宏毅机器学习笔记】 19、Structured Learning - Introduction(待填坑)
【李宏毅机器学习笔记】 20、Structured Learning - Linear Model(待填坑)
【李宏毅机器学习笔记】 21、Structured Learning - Structured SVM(待填坑)
【李宏毅机器学习笔记】 22、Structured Learning - Sequence Labeling(待填坑)
【李宏毅机器学习笔记】 23、循环神经网络(Recurrent Neural Network,RNN)
【李宏毅机器学习笔记】 24、集成学习(Ensemble)
------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av10590361?p=5
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
-------------------------------------------------------------------------------------------------------

在上一篇笔记中可以知道,使用越高次(复杂)的模型,虽然对于training data可能会有比较好的拟合效果,但在testing data上不一定就会有很好的拟合效果。为了能更好地改进模型,需要知道error来自什么地方,才能选择合适的模型进行改进。所以这次会讲error是哪里产生的。
先给出结论,error来源于方差(variance)和bias。
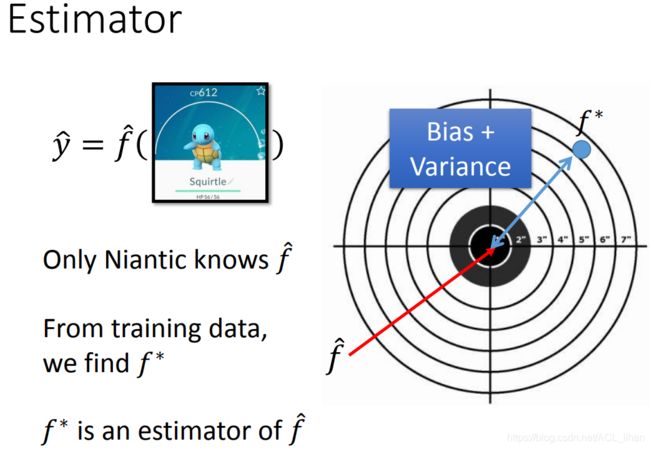
这个是上次的例子,输入一只神奇宝贝,输出它进化后的CP值。这里的 f \hat函数的输出结果代表实际中游戏的结果,但这个函数只有神奇宝贝的开发商Niantic知道。我们能做的就是根据training data,找到一个尽可能接近 f \hat的 。
。
如图,靶中心为实际的f \hat的估测值,而蓝色点是的估测值,它到中心点的距离(即error)就可能是variance和bias导致的。

图中蓝色的小点是不同的的估测值,而蓝色的较大的点是的期望值。蓝色的较大的点和中心的距离就是Bias,而蓝色的小点和蓝色的大点的距离就是Variance。
error来源1:方差(Variance)

这里假设使用的model都是 ![]() ,但是由于training data不一样,所以最后的还是会不一样。
,但是由于training data不一样,所以最后的还是会不一样。
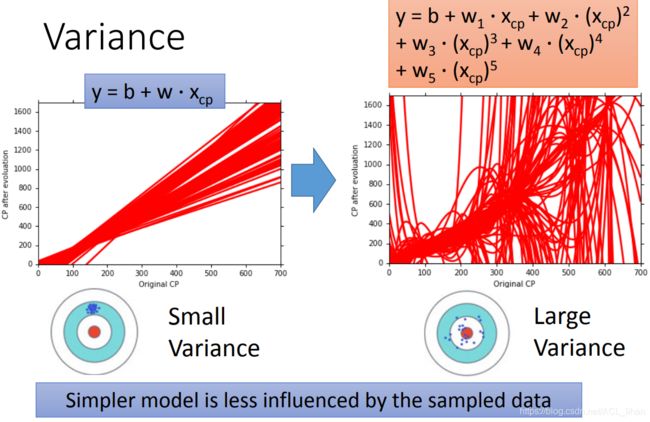
左边的model只有一次方,而右边的model最高有5次方。进行一百次实验,每次的training data都不一样,最终可以看到左边的model比较集中,而右边的已经乱掉了。
所以我们可以看出,简单的model的variance会比较小,因为它不怎么会受training data的不同所造成的影响。
error来源2:Bias

将的估测结果取期望值,就会得到![]() ,
,![]() 距离中心点(实际的结果)的距离就是bias。
距离中心点(实际的结果)的距离就是bias。
右图假设f \hat 是实际计算CP的function(即游戏设定好的)。
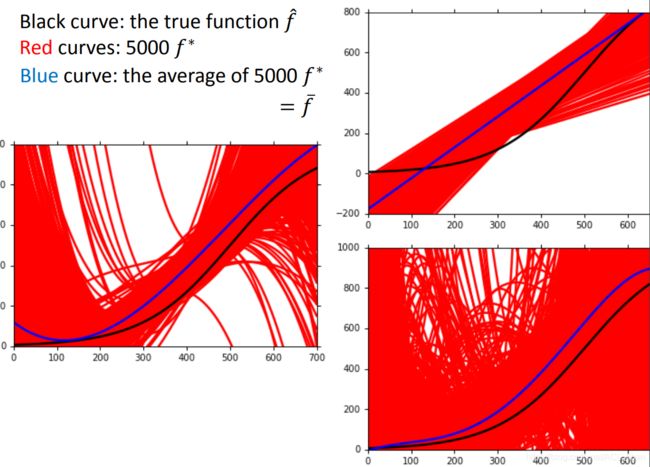
分别进行用一次的模型(结果为右上角的图)、三次的模型(结果为右上角的图)、五次的模型(结果为右上角的图)进行5000次实验。可以看到随着模型变得更复杂,对他们的结果取平均(蓝色线)会更接近实际游戏设定的function(黑色线)。
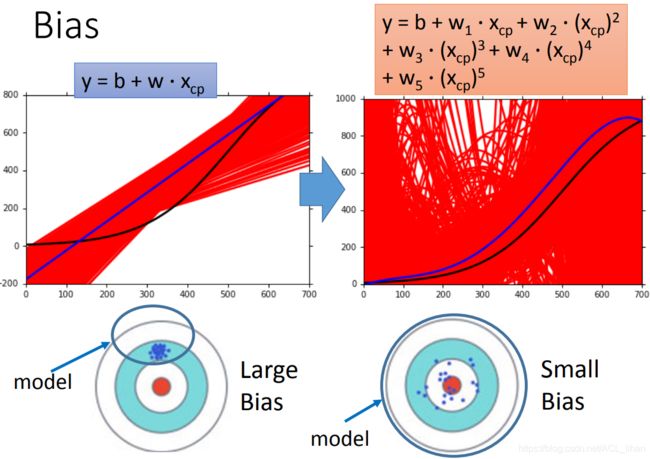
之所以越高次(越复杂)的模型能获得比较低的bias是因为,如图。
一次方的模型它能表示的范围如蓝色圆圈所示,所以所有估测值都集中在那一小块,估测值平均起来的点还是在这附近,所以它的bias会比较高。
而5次方的模型它能表示的范围会大得多,所以虽然估测值看起来比较分散,它平均起来的话,它的bias会比较低。

总结一下就是:
随着模型越复杂,bias会逐渐降低,但方差(variance)会变高
如果是方差(variance)太大,则会产生过拟合(overfitting);如果是bias太大,则会产生欠拟合(underfitting)
怎么解决这两个问题呢?
解决bias过大

如果是bias过大,那再怎么增加data也没用,所以可以使用以下两个方法:
- 增加更多features如神奇宝贝的HP,重量,高度等
- 重新设计一个更复杂的模型
解决方差(variance)过大
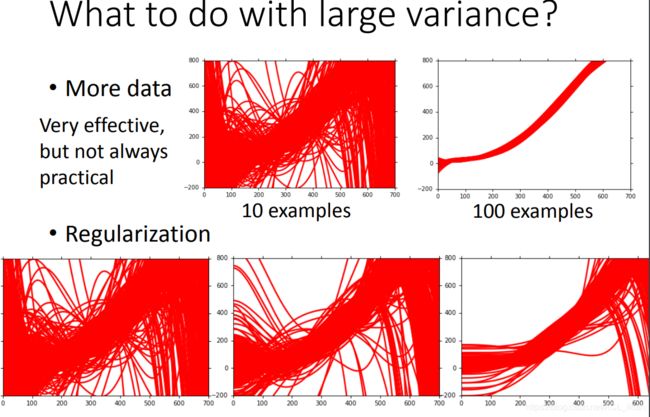
如果是方差(variance)过大,则可以
- 增加更多training data,效果如图。(这个方法只会减小variance,不会加大bias)
- 增加regularization(上一篇笔记讲到的那种方法),效果如图,随着正则项的的影响加大,曲线越光滑。(这个方法在减小variance的同时,可能会造成bias的增大,因为加了正则项之后会减小函数的表示范围,所以需要选择合适的
 ,别让正则项的影响太大)
,别让正则项的影响太大)
讲了error的来源,接下来讲下如何选择合适的model。
选择model
交叉验证(Cross validation)

上图是一种常见的做法,
- 在training data上训练出3个model
- 在testing data上得到error最小的model 3作为最后要选择的模型。
但是这个模型在实际的另一些testing data上可能会产生更大的error,我们没有多余的testing set来测试。
所以需要进行交叉验证(Cross validation)。

如图,步骤如下
- 将training set分为training set和validation set,利用training set训练出三个model。
- 选取在validation set上error最小的model 3 作为比较理想的model
- 在testing set(图中绿色的)上测试error多大
可以看到对比前面多了一步,此时的testing set(绿色)就相当于之前图中的testing set(橙色),这时的error才更能代表model在没看过的data上的结果。
(可以看成是双重保险,在将model运用在真正的testing set(图中橙色的)之前,通过自己所拥有的两层testing set(validation set和绿色的testing set)来挑选model)
这里不建议做一件事:就是看到在testing set(绿色)的error比较大就立刻回去调整model重新训练,如果这样做的话就是把testing set(绿色)也考虑进去,这样testing set(绿色)就不是一个完全没看过的data,model在testing set(绿色)就没办法就反应在真正的testing set(橙色)上的结果。(但是实际你看到testing set(绿色)的error比较大肯定还是会回去调参数,所以这你自己斟酌尽量不要改动太大)
这时你可能担心将training set分为training set和validation set,会不会每次分出来的data set 不同而导致最终的结果会不一样。所以你可以使用N-fold Cross Validation。
N-fold Cross Validation
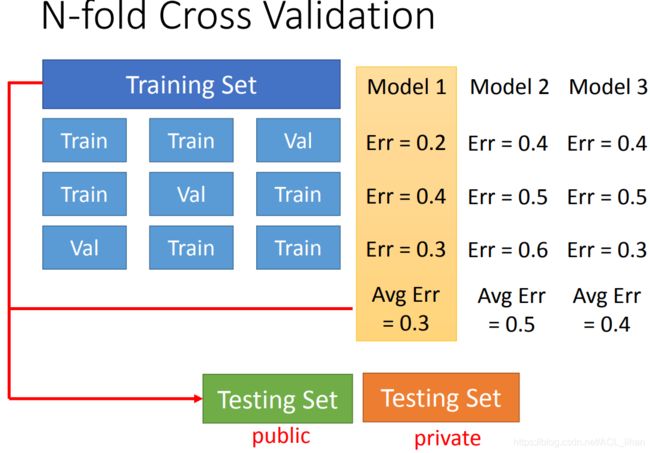
将training set分成三份。
第一次试验第1、2份当training data,第3份做validation data。然后在validation data上计算三个model的error
第二次试验第1、3份当training data,第2份做validation data。然后在validation data上计算三个model的error
第三次试验第2、3份当training data,第1份做validation data。然后在validation data上计算三个model的error
将三个实验得出的结果做平均,就是每个model的error。此时可以看出model 1是最好的。然后再将model 1 根据总的training data(拆分之前的)再训练一次。最后就应用在testing set上。