2019/5/12 由机器学习引入强化学习
任何强化学习方法的理论基础都分三部分,拿DQN举例。第一部分马尔科决策模型,无后效性,DQN做决策时可以只考虑当下不必回顾之前的选择。第二部分贝尔曼最优方程,证明了(特殊的值函数)步步最优全局最优,DQN每一步选择都可以才有贪婪策略。第三部分用奖励更新策略,基于模型的方法,值函数方法,策略搜索方法,DQN采用估计Q值与目标Q值的二次代价函数梯度下降更新网络。
一、机器学习
监督学习经典算法:支持向量机、线性判别、决策树、朴素贝叶斯,随机森林,深度学习中的CNN模型,LSTM模型;
无监督学习经典算法:k-聚类、主成分分析PCA等;
无监督学习常常被用于数据挖掘,用于在大量无标签数据中发现些什么。机器会主动学习数据的特征,并将它们分为若干类别,相当于形成「未知的标签」。
半监督学习经典算法:SVMs半监督支持向量机,S3VM、S4VM、CS4VM、TSVM;
参考链接:监督学习,非监督学习,半监督学习三者的区别是什么,举出一个最有代表性的算法?
https://www.zhihu.com/question/27138263?from=profile_question_card
学习资料:周志华机器学习 西瓜书(PDF) 斯坦福大学机器/深度学习视频 机器学习基石+技法 NLP
https://blog.csdn.net/ykallan/article/details/89076154
二、基于jym构建强化学习环境
1、物理引擎和环境引擎
仿真环境(仿真器)需要物理引擎和图像引擎。物理引擎模拟环境中物体运动规律,图像引擎显示环境中物体图像。
render()图像引擎 step()物理引擎2
2、强化学习定义
定义:强化学习解决序贯决策问题,该问题可以用马氏决策的数学工具建模。该数学问题的解法包括动态规划,蒙特卡洛,时序差分,值函数逼近和直接策略搜索。
目的:找到最优策略(决策序列) *使累计回报R(t)的期望最大:s
*使累计回报R(t)的期望最大:s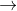 u*(s 状态 u 决策 )
u*(s 状态 u 决策 )
问题:监督学习,无监督学习解决的是单步分类回归问题。强化学习解决的是终极回报的问题,或者说一个多步过程,每步分类结合起来使结果最优。这样理解是否正确?
*注:R(t)是随机变量无法进行优化,无法作为目标函数,采用累计回报期望![]()
RL agent 的一些基本元素:
(1)策略:agent的动作函数(概率、分布)
(2)值函数:描述任一状态和动作有多好,是对未来奖励的预测。(空战游戏中,过错母舰和击中母舰都会使值函数下降,不管奖励是获得了还是未获得)
(G从Rt+1开始累加,这是一种个人习惯/理解,认为是动作后环境发生改变是另一个时间step,环境改变后的任何东西(提供奖励和状态转移)认为在下一个时间step的。)
(3)模型:agent对环境的认识/表达,agent眼中的环境。agent用模型来预测环境的变化,包括转移模型P(预测下一状态)和奖励模型R(预测下一奖励)



RL据agent元素的分类:
value based:agent只包含值函数,策略使不明确的。
policy based:明确表示出策略,如箭头般的数据结构。
model based:创建一个动态特性模型,来表征飞机该怎么飞。
model free:不会尝试去理解环境。通过值函数和策略,来获得最高奖励。
3、强化学习理论基础:马尔科夫决策过程和贝尔曼方程
把强化学习问题用马尔科夫决策的的框架表达并解决
马尔科夫性:当前状态
蕴含所有历史状态,无后效性:系统下一个状态仅与当前状态有关。
马尔科夫过程:随机过程(随机状态序列)的每个状态都是马尔科夫的,表示为二元组(S,P)
S有效状态集合、P状态转移概率(不包含动作)
马氏决策:将动作和回报考虑在内的马尔科夫过程,表示为五元组(S,A,P,R,y)
决策动作a可以看做对环境的一种控制量。但是强化学习相比最优化,假设不同,这里环境未知,原理不能直接 观测, 所以不管有没有用到最优控制的思路,得到的解往往是次优的、或者近似最优的。
状态集,动作集,转移概率(包含动作),回报函数,回报累计折扣因子
贝尔曼方程告诉我们值函数如何跟其自身联系起来,它的基本思想是对值函数进行递归分解。分解为两部分:立即奖励和后继状态的折扣值函数。MDP描述了RL的问题/环境。贝尔曼方程描述了值函数求解,通过平均将MDP还原为MRP,通过一个线性方程逆解值函数,提供强化学习问题一种解法。
贝尔曼最优方程,描述如何真正解决MDP等式,如何把最优值函数联系起来。每次只看一步,选择q*行为即可,即每一个状态上尽力争取最大值,不是立即回报的最大值,是当前最优决策和之后最优决策最优动态的最大值。一步一步,结束的时候就完成了最优策略。
具体的,我们不关心基于均匀策略可以获得多少奖励,我们要找到一个最优策略。MDP中,最优策略=最优值函数=最大的值函数,但是知道了最优值函数并不能告诉你最优策略,这时候就用到了贝尔曼最优方程。它证明了通过解出q*,每次选择q*就是最优策略。计算中有两个关键点,一个是求最大值,一个是求平均值。求最大值是选择最优的动作,求平均值是考虑状态转移带来的影响。(毕竟状态转移像扔色子一样,你不知道你会去哪里。)
注意!这里的max是对R和V综合考虑的,并不一定选当前最大的即时奖励~选最优的动作q*,和不一定选最大的R不冲突。
贝尔曼方程求解:matlab矩阵求逆
贝尔曼最优方程求解: 由于非线性,无法用上述方法求解。这个方程的求解不存在一个显式的公式。通过迭代解法:值迭代和策略迭代的动态规划方法,和value based方法。由此引出,多种多样的强化学习方法。


4、强化学习树

5、强化学习解决两个问题:
(1)预测:给定策略π, 求解该策略的状态价值函数v(π)。
(2)控制:求最优状态价值函数和策略。
6、对深度学习及强化学习的理解:
神经网络可以用来拟合函数,强化学习用交互数据来学习规则,深度学习用标定数据来学习规则。
二、一些概念性思考
1、强化学习为什么要基于马氏过程?
我们知道,马尔科夫决策过程是强化学习的数学描述。它以数学的形式将强化学习问题描述清楚,可以用来解决大部分的强化学习问题。那这种数学描述的优势是什么?
强化学习是基于历史信息和奖励解决序贯决策问题的方法。但如果每一次决策都要考虑历史,那数据量和计算空间太大,难以用来解决实际问题,方法失去研究价值。马氏特征决定了可以用状态代替历史,状态是对信息的总结,是关于历史的函数。状态以每一个时间步长t为单位构建,节省了数据空间。
2、强化学习可以学习到环境特征(环境规律、规则)吗?
我认为是无法准确学习到的,action使environment基于其内部规律发生改变,agent通过observation得到agent state。但是无法观测到到environment state,所以环境的特征和机理应该是无法准确学习到的。那要如何完成准确的控制?agent会对定义的状态和动作空间有一个把握,学习到如何应对输入,得到一个控制的次优解或者近似最优解。所谓的特征理解,可能是基于机械的,大数据计算上的理解。
3、序贯决策的两类问题:强化学习与规划
强化学习:环境未知,通过交互建模,策略提升。强化学习建立环境模型之后,可以用规划方法来解。
规划:完美环境已知,agent不需要与外界环境交互,根据模型进行内部运算。
三、推荐参考资料
郭宪《深入浅出强化学习》不建议作为主线学习材料,对一些概念的理解,不止于来龙去脉,缺乏描述。看过之后,往往会有很多问题,难以从中找到答案。可以从David的公开课入手,基础相对会更扎实一点。本篇笔记主要依据David课程前两节。
优质的系列参考文献:https://www.cnblogs.com/jinxulin/p/3560737.html 增强学习(四) ----- 蒙特卡罗方法(Monte Carlo Methods)