时序预测方法总结
时序预测
本人博客只是平时学习中做的笔记,若文中有错误请大家指出!
一、单变量时间预测
1、AR — AutoRegression 自回归
自回归基于输入变量的线性组合为输出建模
输入:先前时间步长的值;输出:下一步的值
在时间序列中,鉴于当前和先前时间步长的观测值,我们可以预测下一时间步长的值
![]()
“ p”是自回归趋势参数,可以从自相关图确定p的理想值
note:该方法适用于没有趋势和季节成分的时间序列
# Import libraries
from statsmodels.tsa.ar_model import AutoReg #直接导入自回归模型
from random import random
# Generate a sample dataset
data = [x + random() for x in range(1, 100)]
# 拟合模型
model = AutoReg(data, lags=1) #数据喂入模型进行拟合即可
model_fit = model.fit()
# 预测
yhat = model_fit.predict(len(data), len(data))
print(yhat)
2、MA — Moving Average 移动平均
残差:观测值和预测值之间的差异;residual error = observed — predicted
移动平均法也称为残差模型,该方法将序列中的下一步建模为残差的线性函数,![]()
“ q”是移动平均趋势参数,可以从局部自相关图确定q的理想值
note:该方法适用于没有趋势和季节成分的时间序列
# Import libraries 和AR一样,直接导入模型,传入数据训练即可
from statsmodels.tsa.arima_model import ARMA
from random import random
# Generate a sample dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = ARMA(data, order=(0, 1))
model_fit = model.fit(disp=False)
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
3、ARMA — AutoRegression Moving Average 自回归移动平均线
该方法将原始观测值和残差用于预测,对单个的AR和MA模型进行了改进;因此该方法将序列的下一步建模为观测值和先前时间步长的残差的线性函数;
note:
必须为该模型的两个组件指定参数p和q
note:该方法适用于没有趋势和季节成分的时间序列
# Import libraries
from statsmodels.tsa.arima_model import ARMA
from random import random
# Generate a sample dataset
data = [random() for x in range(1, 100)]
# fit model
model = ARMA(data, order=(2, 1))
model_fit = model.fit(disp=False)
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
4、ARIMA — AutoRegression Integrated Moving Average 自回归综合移动平均线
该方法增加一个步骤作为预处理,即对时间序列求差(d)以使其稳定;
将自回归(AR)模型和移动平均(MA)模型以及序列的差分预处理步骤组合在一起以使序列平稳的方法,称为积分(I)
note:该方法适用于具有趋势且没有季节性成分的时间序列
# Import libraries
from statsmodels.tsa.arima_model import ARIMA
from random import random
# Generate a sample dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit(disp=False)
# make prediction
yhat = model_fit.predict(len(data), len(data), typ='levels')
print(yhat)
5、SARIMA—Seasonal Autoregressive Integrated Moving Average 季节性自回归综合移动平均线
该方法是ARIMA模型的扩展,可以处理季节性数据,它分为该系列的季节和非季节组件建模;
除了ARIMA的3个参数以外,还添加了4个其他季节性参数
非季节性参数与ARIMA相同:p – 自回归阶 ,差分阶;q – 移动平均阶 ;
季节性参数: p – 季节性自回归阶数 d:季节性微分阶数 q:季节性移动平均阶数;单个季节性周期的时间步数
note:该方法适用于具有趋势和/或季节成分的时间序列
# Import libraries
from statsmodels.tsa.statespace.sarimax import SARIMAX
from random import random
#随机产生数据
data = [x + random() for x in range(1, 100)]
#拟合数据
model = SARIMAX(data, order=(1, 1, 1), seasonal_order=(1, 1, 1, 1))
model_fit = model.fit(disp=False)
#预测
yhat = model_fit.predict(len(data), len(data))
print(yhat)
二、多元时间序列预测
在多元时间序列中,将每个变量建模为自身的过去值与系统中其他变量的过去值的线性组合
1、VAR – Vector Auto-Regression 向量自回归
可以预测多个并行的平稳时间序列,在系统中每个变量包含一个方程,每个方程的右侧包含一个常数和系统中所有变量的滞后
要决定的参数:系统中应包含多少变量(K)和多少滞后§
# Import libraries
from statsmodels.tsa.vector_ar.var_model import VAR
from random import random
data = list()
for i in range(100):
v1 = i + random()
v2 = v1 + random()
row = [v1, v2]
data.append(row)
model = VAR(data)
model_fit = model.fit()
yhat = model_fit.forecast(model_fit.y, steps=1)
print(yhat)
2、VMA — Vector Moving Average 向量移动平均线
该方法可以预测多个并行的固定时间序列
# Import libraries
from statsmodels.tsa.statespace.varmax import VARMAX
from random import random
data = list()
for i in range(100):
v1 = i+ random()
v2 = v1 + random()
row = [v1, v2]
data.append(row)
model = VARMAX(data, order=(0, 1)) #参数p设置为0
model_fit = model.fit(disp=False)
yhat = model_fit.forecast()
print(yhat)
3、VARMA — Vector Auto Regression Moving Average 向量自回归移动平均值
该方法是VAR和ARMA模型的通用版本,可以预测多个并行的平稳时间序列
需要’p’和’q’参数,若参数’q’=0 则为VAR模型;若参数’p’=0 ,则为VMA模型
# Import libraries
from statsmodels.tsa.statespace.varmax import VARMAX
from random import random
data = list()
for i in range(100):
v1 = random()
v2 = v1 + random()
row = [v1, v2]
data.append(row)
model = VARMAX(data, order=(1, 1))
model_fit = model.fit(disp=False)
yhat = model_fit.forecast()
print(yhat)
4、prophet — Facebook 2017
该方法是在2017年由谷歌提出,可以用prophet通过修改季节参数来拟合季节性,修改趋势参数来拟合趋势信息,指定假期来拟合假期信息等
本质:prophet由四个组件的自加性回归模型,分别用不同的部分来拟合时间序列不同的趋势,叠加起来则是整个时间序列模型;曲线拟合
采用了L-BGFS的方式进行优化求得各个参数的最大后验估计
从论文上的描述来看,这个 prophet 算法是基于时间序列分解和机器学习的拟合来做的
详见论文:Forecasting at scale
三、机器学习方法
1、SVM — Support Machine Vector 支持向量机
建立在统计学习 VC 维理论和结构风险最小化原理基础上的机器学习方法,最早被用来解决分类。
SVM 通过核函数将低维非线性问题映射成高维线性问题,对 SVM 的预测性能起到关键性作用
time,single1,single2,single3 = 你的数据
# 需要预测的长度是多少
long_predict = 20
def svm_timeseries_prediction(c_parameter,gamma_paramenter):
X_data = time
Y_data = single1
print(len(X_data))
# 整个数据的长度
long = len(X_data)
# 取前多少个X_data预测下一个数据
X_long = 1
error = []
svr_rbf = SVR(kernel='rbf', C=c_parameter, gamma=gamma_paramenter)
# svr_rbf = SVR(kernel='rbf', C=1e5, gamma=1e1)
# svr_rbf = SVR(kernel='linear',C=1e5)
# svr_rbf = SVR(kernel='poly',C=1e2, degree=1)
X = []
Y = []
for k in range(len(X_data) - X_long - 1):
t = k + X_long
X.append(Y_data[k:t])
Y.append(Y_data[t + 1])
y_rbf = svr_rbf.fit(X[:-long_predict], Y[:-long_predict]).predict(X[:])
for e in range(len(y_rbf)):
error.append(Y_data[X_long + 1 + e] - y_rbf[e])
return X_data,Y_data,X_data[X_long+1:],y_rbf,error
2、BN— Bayesian Network 贝叶斯网络
BN是贝叶斯方法与图形理论的有机结合,又称信念网络、有向无环图模型,是一种概率图模型.
使用条件概率表达各个信息要素之间的相关关系,能在有限的、不完整的、不确定的信息条件下进行学习和推理,因此其具有强大的不确定性问题处理能力
# 从sklearn.datasets里导入新闻数据抓取器 fetch_20newsgroups
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
#从#csklearn.feature_extraction.text里导入文本特征向量化模块
from sklearn.feature_extraction.text import CountVectorizer
# 从sklean.naive_bayes里导入朴素贝叶斯模型
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
#1.数据获取
news = fetch_20newsgroups(subset='all')
#2.数据预处理:训练集和测试集分割,文本特征向量化
# 随机采样25%的数据样本作为测试集
X_train,X_test,y_train,y_test = train_test_split( news.data, news.target, test_size=0.25, random_state=33)
#文本特征向量化
vec = CountVectorizer()
X_train = vec.fit_transform(X_train)
X_test = vec.transform(X_test)
#3.使用朴素贝叶斯进行训练
mnb = MultinomialNB() # 使用默认配置初始化朴素贝叶斯
mnb.fit(X_train,y_train) # 利用训练数据对模型参数进行估计
y_predict = mnb.predict(X_test) # 对参数进行预测
3、RF — Random Forest 随机森林
随机森林属于集成学习,具有抗过拟合能力强、抗干扰能力强和泛化能力强等特点,
其基本单元是决策树。在时间序列预测问题中,随机森林的输出通常是所有决策树输出
的平均值
import pandas as pd
from sklearn import preprocessing
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import load_boston
boston_house = load_boston()
boston_feature_name = boston_house.feature_names
boston_features = boston_house.data
boston_target = boston_house.target
rgs = RandomForestRegressor(n_estimators=15) ##随机森林模型
rgs = rgs.fit(boston_features, boston_target)
rgs.predict(boston_features)
四、深度学习方法
1、RNN — Recurrent Neural Network
- RNN是一类以序列数据为输入,在序列的演进方向进行递归且所有节点按链式连接的递归神经网络;
- 具有记忆性、参数共享并且图灵完备
- RNN的缺点:出现梯度消失现象,无法解决长时依赖的问题
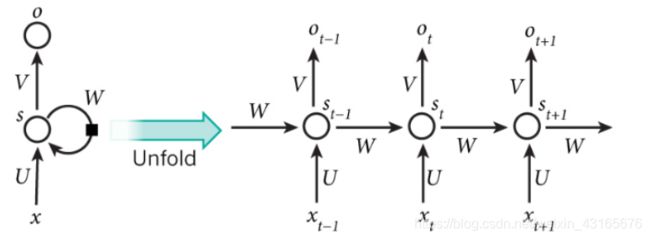
用pyTorch搭建RNN
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN(
input_size=input_size, # 输入特征
hidden_size=hidden_size,# 隐藏层个数
num_layers=num_layers, # RNN层数
batch_first=True, #True:batch的纬度放在第一位
)
self.output_layer = nn.Linear(in_feature, out_feature)
def forward(self, x, h_state):
# x (batch, time_step, input_size)
# h_state (n_layers, batch, hidden_size)
# rnn_out (batch, time_step, hidden_size)
rnn_out, h_state = self.rnn(x, h_state)
# 因为rnn_out 包含了所有时间步长中RNN的输出,需要拿到每一时刻RNN的输出
# 然后在输入到输出层
out=[]
for time in range(rnn_out.size(1)):
every_time_out = rnn_out[:, time, :]
out.append(self.output_layer(every_time_out))
# torch.stack扩成[1, output_size, 1]
return torch.stack(out, dim=1), h_state
LSTM — Long-Short Term Memory
LSTM通过cell门开关实现时间上的记忆功能,并防止梯度消失.(原理不多介绍)
LSTM由三个部分组成:
- 遗忘门,控制哪些部分保留,哪些部分舍弃;
- 输入门,sigmoid这条线负责选择更新的信息,tanh这条线负责添加新候选信息;
- 输出门,控制哪些部分被输出。

用pyTorch的LSTM的使用
import torch
import torch.nn as nn
from torch.autograd import *
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
def SeriesGen(N):
x = torch.arange(1,N,0.01)
return torch.sin(x)
def trainDataGen(seq,k):
dat = list()
L = len(seq)
for i in range(L-k-1):
indat = seq[i:i+k]
outdat = seq[i+1:i+k+1]
dat.append((indat,outdat))
return dat
def ToVariable(x):
tmp = torch.FloatTensor(x)
return Variable(tmp)
y = SeriesGen(10)
dat = trainDataGen(y.numpy(),10)
class LSTMpred(nn.Module):
def __init__(self,input_size,hidden_dim):
super(LSTMpred,self).__init__()
self.input_dim = input_size
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(input_size,hidden_dim)
self.hidden2out = nn.Linear(hidden_dim,1)
self.hidden = self.init_hidden()
def init_hidden(self):
return (Variable(torch.zeros(1, 1, self.hidden_dim)),
Variable(torch.zeros(1, 1, self.hidden_dim)))
def forward(self,seq):
lstm_out, self.hidden = self.lstm(
seq.view(len(seq), 1, -1), self.hidden)
outdat = self.hidden2out(lstm_out.view(len(seq),-1))
return outdat
model = LSTMpred(1,6)
loss_function = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(10):
print(epoch)
for seq, outs in dat[:700]:
seq = ToVariable(seq)
outs = ToVariable(outs)
#outs = torch.from_numpy(np.array([outs]))
optimizer.zero_grad()
model.hidden = model.init_hidden()
modout = model(seq)
loss = loss_function(modout, outs)
loss.backward()
optimizer.step()
predDat = []
for seq, trueVal in dat[700:]:
seq = ToVariable(seq)
trueVal = ToVariable(trueVal)
predDat.append(model(seq)[-1].data.numpy()[0])
fig = plt.figure()
plt.plot(y.numpy())
plt.plot(range(700,890),predDat)
plt.show()
GRU — Gate Recurrent Unit
GRU是RNN的一种,和LSTM一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的;
GRU由两部分组成:
- 重置门,将输入与之前的状态结合起来;
- 更新门,多少的输入和状态被保留。

用pyTorch的GRU的使用
gru = nn.GRU(input_size=20,hidden_size=50,num_layers=2)
将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态

2、seq2seq - Attention
seq2seq本质上是一种encoder-decoder框架;由于encoder与decoder两端处理的都是序列数据,所以被称为sequence-to-sequence,简称seq2seq。
- 编码器:编码器负责单步执行输入时间步骤,并将整个序列编码为一个固定长度的向量,称为上下文向量(context vector)。
- 解码器:解码器负责逐步执行输出时间步骤,并从上下文向量读取信息。
- 目前应用最多的编/解码器是RNN(LSTM,GRU),但编/解码器并不限于RNN,如也有人拿MLP作为编码器;
- Attention机制是对解决这个限制的体系结构的扩展。它首先提供从编码器到解码器的更丰富的上下文,以及一种学习机制,在该机制中,解码器可以在预测输出序列中的每个时间步的输出时,在更丰富的编码中学习应注意的位置。

class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super(EncoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output = embedded
output, hidden = self.gru(output, hidden)
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size
self.output_size = output_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.dropout = nn.Dropout(self.dropout_p)
self.gru = nn.GRU(self.hidden_size, self.hidden_size)
self.out = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
embedded = self.dropout(embedded)
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = F.log_softmax(self.out(output[0]), dim=1)
return output, hidden, attn_weights
def initHidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)
3、DeepAR
DeepAR是Amazon于2017年提出的基于深度学习的时间序列预测方法;基于神经网络的 DeepAR 方法可以很方便地将额外的特征纳入考虑,且其预测目标是序列在每个时间步上取值的概率分布
Deep AR: Probabilistic Forecasting with Autoregressive Recurrent Networks
import tensorflow as tf
import tensorflow_probability as tfp
class DeepAR(tf.keras.models.Model):
"""
DeepAR 模型
"""
def __init__(self, lstm_units):
super().__init__()
# 注意,文章中使用了多层的 LSTM 网络,为了简单起见,本 demo 只使用一层
self.lstm = tf.keras.layers.LSTM(lstm_units, return_sequences=True, return_state=True)
self.dense_mu = tf.keras.layers.Dense(1)
self.dense_sigma = tf.keras.layers.Dense(1, activation='softplus')
def call(self, inputs, initial_state=None):
outputs, state_h, state_c = self.lstm(inputs, initial_state=initial_state)
mu = self.dense_mu(outputs)
sigma = self.dense_sigma(outputs)
state = [state_h, state_c]
return [mu, sigma, state]
def log_gaussian_loss(mu, sigma, y_true):
"""
Gaussian 损失函数
"""
return -tf.reduce_sum(tfp.distributions.Normal(loc=mu, scale=sigma).log_prob(y_true))
#实例化模型,指定优化器
LSTM_UNITS = 16
EPOCHS = 5
# 实例化模型
model = DeepAR(LSTM_UNITS)
# 指定优化器
optimizer = tf.keras.optimizers.Adam()
# 使用 RMSE 衡量误差
rmse = tf.keras.metrics.RootMeanSquaredError()
# 定义训练步
def train_step(x, y):
with tf.GradientTape() as tape:
mu, sigma, _ = model(x)
loss = log_gaussian_loss(mu, sigma, y)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
rmse(y, mu)
# 数据处理(略)
# train_data = do_something()
# 训练
for epoch in range(EPOCHS):
for x, y in train_data:
train_step(x, y)
print('Epoch %d, RMSE %.4f' % (epoch + 1, rmse.result()))
rmse.reset_states()
4、CNN
CNN用于序列预测时使用的是一维卷积,也就是我们熟悉的离散序列的卷积和;对序列做卷积,就是找到一个窗口大小为kernel_size的序列,与原序列做卷积得到新的序列表达,一般卷积网络中还包括池化操作,就是对卷积提取的特征进行筛选得到最有用的特征,采用max-pooling方法比较多;
卷积公式:
已知序列
a={a0,a1,a2,…,am},L(a)=m+1
b={b0,b1,b2,…,bk},L(b)=k+1;
用ab表示a与b卷积后得到的一个新序列;记ab中第n个元素为(ab)n,则
(ab)n=a0bn + a1bn-1 +…+an-1b1 +anb0=∑akbn-k
L(a*b)=L(a)+L(b)-1
#用pyTorch构建模型
class CNN_Series(nn.Module):
def __init__(self):
super(CNN_Series,self).__init__()
self.conv1= nn.Sequential(
nn.Conv1d(
in_channels = 1,
out_channels = 8,
kernel_size = 3
),
nn.MaxPool1d(kernel_size = 2)
)
self.conv2= nn.Sequential(
nn.Conv1d(
in_channels = 8,
out_channels = 16,
kernel_size = 3
),
nn.MaxPool1d(kernel_size = 2)
)
self.fc = nn.Linear(384, 1)
def forward(self,indata):
x = self.conv1(indata)
x = self.conv2(x)
x = x.view(x.size(0), -1)
out = self.fc(x)
return out
model = CNN_Series()
lossfunc = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(),lr =0.001)
6、WaveNet
WaveNet的核心是扩张的因果卷积层,它允许它正确处理时间顺序并处理长期依赖,而不会导致模型复杂性的爆炸;(利用卷积层的效率,同时减轻在大量时间步长(1000+)内学习长期依赖性的挑战)
因果卷积
-
常常用于CNN网络来处理序列问题,针对序列问题x1,…xt,和y1,…,yt-1来预测yt
只允许输入连接到因果结构中的未来时间步输出,确保模型不会违反建模数据的顺序 -
即对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据,它是单向的结构,不是双向的

扩张卷积
- 在扩张的卷积层中,滤波器不以简单的顺序方式应用于输入,而是跳过恒定的扩张速率在它们处理的每个输入之间输入;可以使模型在层数不大的情况下有非常大的感受野;
- 一般的Causal CNN网络,当层数增加,涵盖的范围是线性增加;而在扩张卷积网络中,范围是指数增加。因此只要增加一层,就可以多关联至一倍的时间范围;
非线性表现更好

7、TCN --Temporal convolutional network 时间卷积网络
TCN直接利用卷积强大的特性,跨时间步提取特征;
TCN结构很像Wavenet,paper作者也表示确实借鉴了Wavenet的结构,TCN的结构在paper中表示如下,这是一个kernel size=3,dilations=[1,2,4]的TCN
残差连接(Residual Connections)
通过简单的残差连接,一定程度上消除了深度网络部分梯度消失和爆炸的影响。并且残差连接被证明是训练深层网络的有效方法,它使得网络可以以跨层的方式传递信息;
一个残差块包含两层的卷积和非线性映射,在每层中还加入了WeightNorm和Dropout来正则化网络
import torch
import torch.nn as nn
from torch.nn.utils import weight_norm
class Chomp1d(nn.Module):
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
return x[:, :, :-self.chomp_size].contiguous()
class TemporalBlock(nn.Module):
def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):
super(TemporalBlock, self).__init__()
self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp1 = Chomp1d(padding)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp2 = Chomp1d(padding)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,
self.conv2, self.chomp2, self.relu2, self.dropout2)
self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None
self.relu = nn.ReLU()
self.init_weights()
def init_weights(self):
self.conv1.weight.data.normal_(0, 0.01)
self.conv2.weight.data.normal_(0, 0.01)
if self.downsample is not None:
self.downsample.weight.data.normal_(0, 0.01)
def forward(self, x):
out = self.net(x)
res = x if self.downsample is None else self.downsample(x)
return self.relu(out + res)
class TemporalConvNet(nn.Module):
def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):
super(TemporalConvNet, self).__init__()
layers = []
num_levels = len(num_channels)
for i in range(num_levels):
dilation_size = 2 ** i
in_channels = num_inputs if i == 0 else num_channels[i-1]
out_channels = num_channels[i]
layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,
padding=(kernel_size-1) * dilation_size, dropout=dropout)]
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
后续会继续补充