原理讲解-项目实战<->Mtcnn+Mobilent实现人脸口罩检测
点击上方“码农的后花园”,选择“星标” 公众号
精选文章,第一时间送达
文章目录
一、口罩识别的方案
二、利用Mtcnn+Mobilent 实现人脸检测
整体实现流程
1.什么是 Mtcnn
2.什么是Mobilent
3. 代码下载和环境设置
4.数据集和模型的训练
5.预测效果展示
一、一般口罩佩戴检测的两种方案
第一种:直接利用SSD和Yolo这种one-stage目标检测算法,在检测到人脸的同时判断是否佩戴了口罩。
第二种:利用现在比较成熟的人脸检测技术,如Mtcnn, 首先检测出人脸的位置,然后把人脸截取下来,再传入到一个新的神经网络里面,判断它是否正确的佩戴了口罩。缺点是:现在已经有的人脸检测技术是针对人脸面部是没有遮挡物的,就是完整的一张人脸,但是当我们佩戴口罩之后,人脸就有遮挡物了,所以这种方法检测效果会比较差一些,但是在光照充足的情况下,识别效果还是可以的。
二、利用Mtcnn+Mobilent实现人脸口罩检测
整体实现流程
首先利用Mtcnn检测人脸,再利用Mobilent对我们检测到的人脸进行是否佩戴口罩的识别。
1.什么是Mtcnn模型

总结:Mtcnn分为四步,分别是图像金字塔先把输入图片进行缩放,缩放完成之后,我们可以提取出大的人脸和小的人脸,使得网络提取的效果更有效。
然后Pnet网络会对图像金字塔得到的图像进行一个粗略的筛选,得到一大堆的人脸粗略框,然后对这些粗略框进行一个非极大值抑制筛选操作得到相对于好一点的框。再把这些相对好一点的粗略框传入到Rnet精修网络中。
Rnet会对这些粗略框的内部区域进行物体识别,判断是否是一张人脸,同时对框的长和宽进行修正,然后对调整好的粗略框进行非极大抑制操作筛选出相对上一步更好的框框。
最后这些经过Rnet调整好的相对较好的框框传入到Onet网络中,Onet依旧判断这些框的内部区域是否有人脸,同时对Rnet得到的这些框的长和宽再一次进行精修,使得这个框更好的符合人脸大小,最终再进行非极大值抑制操作,得到最终的人脸预测框,与此同时还会得到人脸的5个特征点的位置。
Mtcnn模型的构建: D:\Project\mask-recognize-master\net\mtcnn.py
Mtcnn详细讲解:原理讲解-项目实战 <-> Keras搭建Mtcnn人脸检测平台
2.什么是Mobilent模型
在检测到人脸之后,再利用mobilent检测人脸是否佩戴口罩,原理后期讲解
Mobilent模型的构建: D:\Project\mask-recognize-master\net\mobileNet.py
3.代码下载和环境设置
后台回复:项目实战,获取完整代码实现
环境
-
python==3.6
-
tensorflow-gpu==1.13.1
-
keras==2.1.5
4.数据集和模型的训练
数据集
口罩识别的数据集:https://github.com/X-zhangyang/Real-World-Masked-Face-Dataset
本次训练数据集:回复:项目实战,获取
模型的训练
1.项目结构:
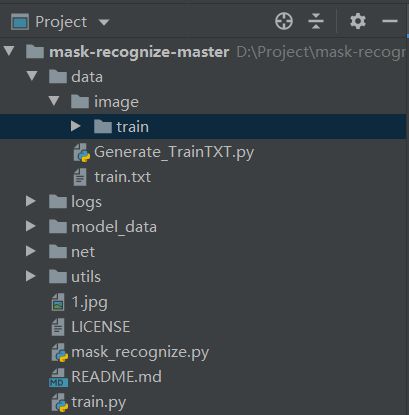
2.数据集
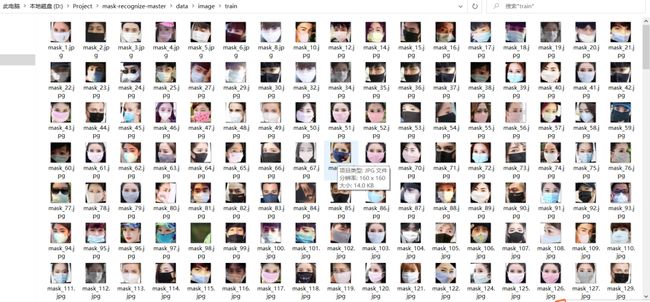
首先将我们的训练图片存放在data/image/train文件夹下,图片的命名形式为图片中人戴口罩了则命名为mask_x.jpg,没有佩戴口罩则命名为nomask_x.jpg,利用图片的名字就可以对我们的图片的类型进行判断,每一张图片的大小为Mobilenet模型输入的大小160*160。具体如下所示,下面的图片都是经过人脸对齐了的:
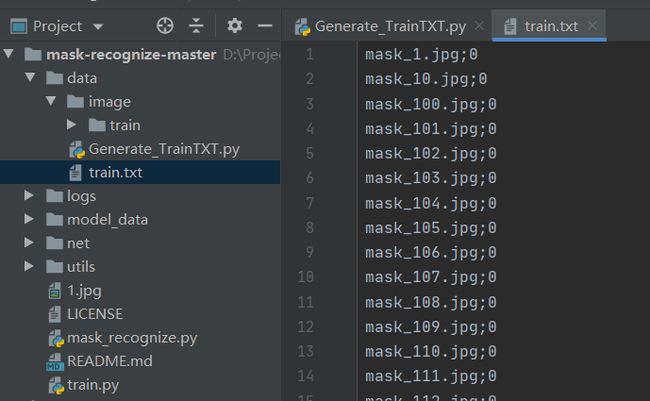
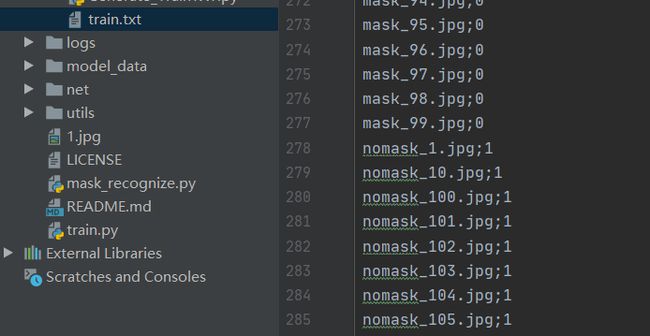
然后利用data/image/Gnerate_TrainTxT.py文件将训练图片生成为模型训练格式的数据集,以train.txt形式保存,如下所示:

利用Gnerate_TrainTxT.py生成的train.txt, 可以看到训练集中的每张训练图片之间以行隔开,每一行代表一张训练图片,每一行的“ ; ”前面是我们事先命名图片的名字,“ ; ”后面是指这张图片所属的标签, mask的标签是:0,nomask的标签是:1 。
训练的时候就会读取train.txt的每一行,获得每一张图片和其所属的标签。
3.模型的训练
这里主要针对Mobilent网络进行训练,首先设置训练模型保存权重的位置,保存在logs文件下,然后读取train.txt文件读取数据集中的每一张图片和其标签,再加载Mobilent模型以及其预训练权重,然后进行数据集的train和val的划分,进行图片数据的预处理(图片数据增强+图片归一化+图片标签的处理),最后定义训练的loss函数和优化器等训练操作,即可进行训练。如下图所示,训练好了的权重保存在logs文件夹下。
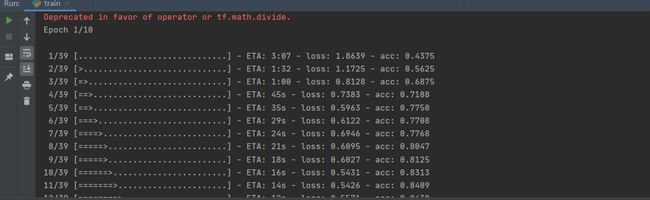
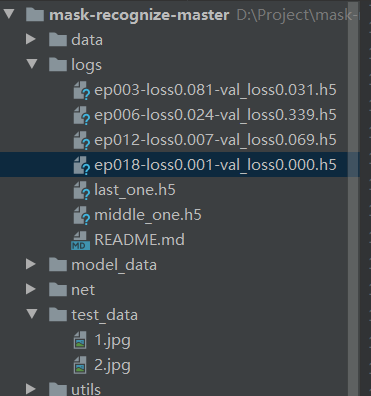
代码详情请见:train.py 文件
注意这里有部分网络不好的在从网上下载Mobilent的预训练权重的时候,会出现权重文件打不开的问题,
预训练权重下载地址:https://github.com/fchollet/deep-learning-models/releases
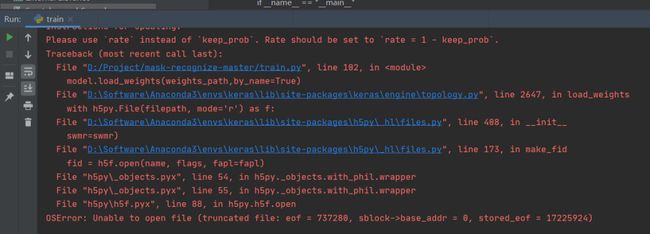
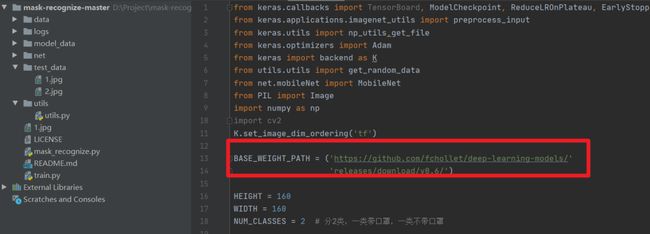
这是因为我们的预训练权重是实时从网络上获取,取决于我们的网速,当我们网速过慢就会下载不完整,会出现上面的问题,我们可以自己上网将这个预训练权重下载好放在项目的model_data文件夹下再加载即可。

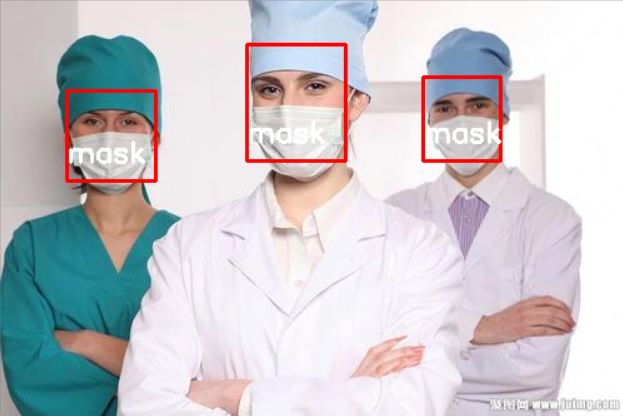
5.预测效果展示
预测的代码在mask_recognize.py文件,首先利用Opencv读取一张要检测的图片,然后定义口罩识别的类:首先加载mtcnn模型和mobielent模型,将上面我们训练好了的mobilenet的权重加载到模型当中,利用Mtcnn检测图片中的每一张人脸,再利用Mobilenet对每一张人脸进行是否佩戴口罩的检测,最后在原图中绘制。然后利用Opencv的cv2.imshow()进行绘制结果的展示,如下所示:
修改mask_model.load_weights()

效果图:
代码下载:微信号同名,回复:项目实战,自动获取代码下载地址。
精彩推荐:
原理讲解-项目实战 <-> Mtcnn + Facenet 搭建人脸识别平台(中奖名单公示)
原理讲解-项目实战 <-> Keras搭建Mtcnn人脸检测平台
Yolov3算法实现社交距离安全检测项目讲解和实战(Social Distance Detector)
万字长文,用代码的思想讲解Yolo3算法实现原理,Visdrone数据集和自己制作数据集两种方式在Pytorch训练Yolo模型