要么干要么滚!推特开始裁员了;深度学习产品应用·随书代码;可分离各种乐器音源的工具包;Transformer教程;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | @韩信子
解散Twitter董事会,代码审查,裁员25%,收每月20美元认证费···马斯克那些骚操作···
埃隆·马斯克 (Elon Musk) 抱着洗手池入主 Twitter 后,狂风骤雨已经一波波袭来——首先解雇了CEO、CFO等一众高管,解散了整个Twitter董事会,并亲自上阵担任CEO开始整顿。
之前放出的『裁员75%』的消息被验证不实,但第一波25%的确定性裁员已在进行中了,第二波第三波或许正在路上。马斯克从旗下公司特斯拉等抽调了50多名工程师进入Twitter工作,来审核Twitter员工的代码。据内部信息称,具体方法让员工打印出近期代码并解释和重写,写不出来或说不清楚的话,大概率就进入第一批裁员名单了。
随后马斯克又发出下马威:11月第1周要上线新的『Twitter Blue 付费验证』功能,将每月 4.99 美元的可选订阅服务更改为 19.99 美元,并且只对付费订阅用户的账户进行验证标记。面对这个impossible deadline,项目负责经理正带领团队成员加班加点,每周7天轮班工作12小时,就为了赶上这个DDL。毕竟要么干要么只能走人了。

工具&框架
『Demucs (v3)』音源分离工具包,可分离各种乐器
https://github.com/facebookresearch/demucs
Facebook提供了一个用于音乐源分离的Hybrid Demucs的实现,它既在MusDB HQ数据集上训练,又有内部的额外训练数据。它可以将鼓、低音和人声从其他部分分离出来,并在2021年索尼音乐DemiXing挑战赛(MDX)上取得了第一名的成绩。
Demucs基于U-Net卷积架构,灵感来自Wave-U-Net。最新版本的特点是混合谱图/波形分离,以及压缩剩余分支、局部注意和奇异值正则化。Demucs是目前唯一支持真正的端到端混合模型训练的模型,在各域之间共享信息,而不是训练后的模型混合。

『PromptCLUE』支持最多中文Prompt任务的开源多任务模型
https://github.com/clue-ai/PromptCLUE
https://www.cluebenchmarks.com/clueai.html
PromptCLUE 是一个多任务中文模型,基于t5模型,使用1000亿中文token(字词级别)进行大规模预训练,并且在100+任务上进行多任务学习获得。
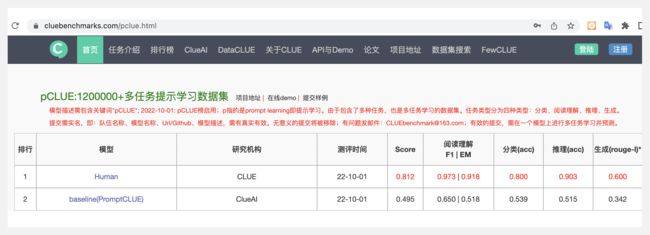
PromptCLUE 支持众多中文任务,并具有零样本学习能力。 针对理解类任务,如分类、情感分析、抽取等,可以自定义标签体系;针对生成任务,可以进行采样自由生成。
『Transformers-Tutorials』HuggingFace Transformers库实例教程集
https://github.com/NielsRogge/Transformers-Tutorials
这个资源库包含了作者用HuggingFace制作的Transformers的演示。目前,所有这些都是在PyTorch中实现的。如果你不熟悉HuggingFace和/或Transformers,可以查看这个完整教程,它向你介绍了几种Transformer架构(如BERT、GPT-2、T5、BART等),以及HuggingFace库的概况,包括Transformers、Tokenizers、Datasets、Accelerate和the hub。
『hot-lib-reloader』无需重新启动应用重新加载Rust代码
https://github.com/rksm/hot-lib-reloader-rs
hot-lib-reloader是一个开发工具,它使得你能重新加载一个正在运行的Rust程序的功能。也就是说支持"实时编程",即修改代码并立即看到运行中的程序的效果。它是围绕着libloading crate建立的,需要你把你需要热加载的代码放在Rust库(dylib)中。
『NiceGUI』易用的Python UI框架
https://github.com/zauberzeug/nicegui
NiceGUI 是一个易于使用、基于Python的用户界面框架,它显示在Web浏览器里,可创建按钮,对话框,markdown,3D场景,绘图等。它非常适用于小型网页应用、仪表盘、机器人项目、智能家居解决方案和类似的场景。
博文&分享
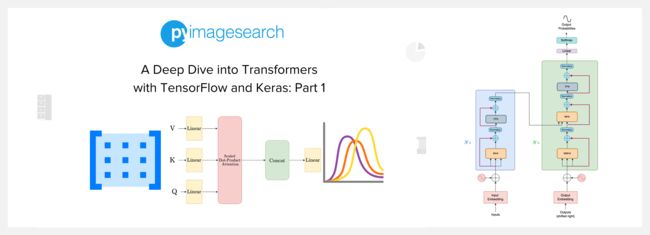
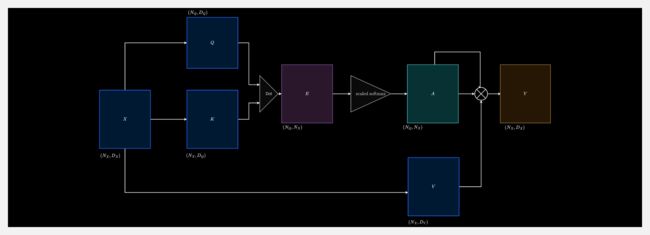
『A Deep Dive into Transformers with TensorFlow and Keras』使用 TensorFlow 和 Keras 深入了解 Transformer
A Deep Dive into Transformers with TensorFlow and Keras: Part 1
https://pyimagesearch.com/2022/09/05/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-1/
这是 Transformer 系列教程的第1篇,讲解以下内容:
- The Transformer Architecture:Encoder / 编码器、Decoder / 解码器
- Evolution of Attention:Version 0、Version 1、Version 2、Version 3、Version 4 (Cross-Attention)、Version 5 (Self-Attention)、Version 6 (Multi-Head Attention)
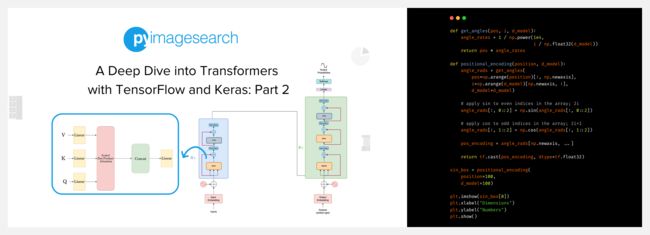
A Deep Dive into Transformers with TensorFlow and Keras: Part 2
https://pyimagesearch.com/2022/09/26/a-deep-dive-into-transformers-with-tensorflow-and-keras-part-2/
这是系列教程的第2篇,讲解 Transformers 架构中将编码器和解码器连接在一起的部分(Connecting Wires),包含四部分:
- Skip Connection / 跳过连接
- Layer Normalization / 层标准化
- Feed-Forward Network / 前馈网络
- Positional Encoding / 位置编码
『Production-Ready Applied Deep Learning』深度学习产品应用·随书代码
https://github.com/PacktPublishing/Production-Ready-Applied-Deep-Learning
本书侧重于通过详细的示例缩小理论与应用之间的差距。虽然有很多关于针对不同问题介绍各种 AI 模型的书籍,但我们看到真正困难的资源有限,即部署。这本书是我们从大规模部署数百个基于人工智能的服务中获得的知识的集合。
由于本书强调如何大规模部署机器学习系统,因此具有一定机器学习或软件工程知识的读者会发现内容更容易理解。然而,这并不是一个硬性要求,因为我们假设读者是该领域的新手,并讨论了理论和技术背景。
- Effective Planning of Deep Learning Driven Projects(深度学习驱动项目的有效规划)
- Data Preparation for DL projects(深度学习项目的数据准备)
- Developing a Powerful Deep Learning Model(开发强大的深度学习模型)
- Experiments Tracking, Model Management, and Dataset Versioning(实验跟踪、模型管理和数据集版本控制)
- Data Preparation on Cloud(云端数据准备)
- Efficient Model Training(高效模型训练)
- Revealing the secret of DL models(揭开深度学习模型的秘密)
- Simplifying Deep Learning Model Deployment(简化深度学习模型部署)
- Scaling Deep Learning Pipeline(扩展深度学习管道)
- Improving inference efficiency(提高推理效率)
- Deep Learning on Mobile Devices(移动设备上的深度学习)
- Monitoring and maintenance at production level(生产层面的监控和维护)
- Reviewing the Completed Deep Learning Project(回顾已完成的深度学习项目)
数据&资源
『Awesome Face Restoration & Enhancement』人脸恢复与增强论文资源列表
https://github.com/sczhou/Awesome-Face-Restoration
- Papers
- Face Image Restoration
- Face Video Restoration
- Survey
- Datasets
- High-Resolution
- Low-Resolution
- Video Face
- Other Face Dataset
『Spectral Indices』遥感光谱指数相关资源大列表
https://github.com/awesome-spectral-indices/awesome-spectral-indices
光谱指数广泛用于遥感社区。本存储库跟踪不同遥感应用的经典和新颖的光谱指数。存储库中的所有光谱索引都经过精心策划,可用于不同的环境和编程语言。如果想在本地环境中使用,可以使用 CSV 和 JSON 格式。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.10.03 『图像生成』 From Face to Natural Image: Learning Real Degradation for Blind Image Super-Resolution
- \2022. 10.04 『语言模型』 Knowledge Unlearning for Mitigating Privacy Risks in Language Models
- 2022.09.29 『图像分割』 3D UX-Net: A Large Kernel Volumetric ConvNet Modernizing Hierarchical Transformer for Medical Image Segmentation
⚡ 论文:From Face to Natural Image: Learning Real Degradation for Blind Image Super-Resolution
论文时间:3 Oct 2022
领域任务:Image Generation, Image Super-Resolution,图像生成,超分辨率变换
论文地址:https://arxiv.org/abs/2210.00752
代码实现:https://github.com/csxmli2016/redegnet
论文作者:Xiaoming Li, Chaofeng Chen, Xianhui Lin, WangMeng Zuo, Lei Zhang
论文简介:Notably, face images, which have the same degradation process with the natural images, can be robustly restored with photo-realistic textures by exploiting their specific structure priors./值得注意的是,人脸图像与自然图像具有相同的退化过程,通过利用其特定的结构先验,可以用照片般真实的纹理进行稳健的恢复。
论文摘要:设计适当的训练对对现实世界的低质量(LQ)图像进行超级解算至关重要,但在获取成对的地面真实HQ图像或合成照片般逼真的退化观测值方面存在困难。最近的工作主要是通过用手工制作的或估计的退化参数来模拟退化来规避这一问题。然而,现有的合成退化模型没有能力模拟复杂的真实退化类型,导致对这些场景的改进有限,比如老照片。值得注意的是,人脸图像与自然图像有相同的退化过程,通过利用其特定的结构先验,可以用照片般真实的纹理进行稳健的修复。在这项工作中,我们使用这些现实世界的LQ脸部图像和它们修复后的HQ对应物来模拟复杂的真实退化(即ReDegNet),然后将其转移到HQ自然图像上,以合成其现实的LQ。具体来说,我们把这些成对的HQ和LQ脸部图像作为输入,明确地预测退化感知和内容无关的表征,这些表征控制着退化图像的生成。随后,我们将这些真实的退化表征从人脸转移到自然图像,以合成退化的LQ自然图像。实验表明,我们的ReDegNet能够很好地从人脸图像中学习到真实的退化过程,而且用我们的合成对训练的修复网络在对抗SOTA时表现良好。更重要的是,我们的方法提供了一种新的方式来处理不可合成的真实世界场景,通过其中的人脸图像来学习它们的退化表征,这可以用来进行专门的微调。源代码可在 https://github.com/csxmli2016/ReDegNet 获取。
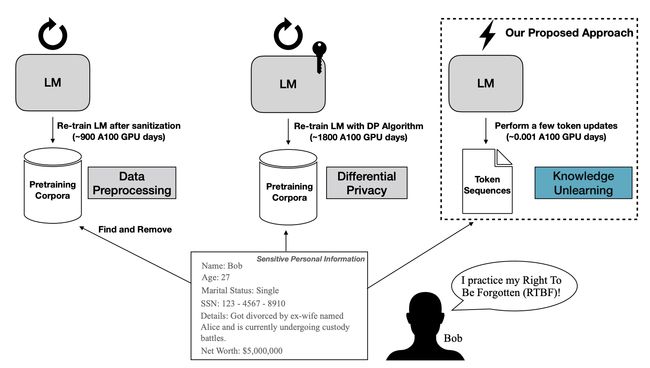
⚡ 论文:Knowledge Unlearning for Mitigating Privacy Risks in Language Models
论文时间:4 Oct 2022
领域任务:Language Modelling, Pretrained Language Models,语言模型,预训练语言模型
论文地址:https://arxiv.org/abs/2210.01504
代码实现:https://github.com/joeljang/knowledge-unlearning
论文作者:Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, Minjoon Seo
论文简介:Pretrained Language Models (LMs) memorize a vast amount of knowledge during initial pretraining, including information that may violate the privacy of personal lives and identities./预训练的语言模型(LMs)在最初的预训练中记忆了大量的知识,包括可能侵犯个人生活和身份隐私的信息。
论文摘要:预训练语言模型(LMs)在最初的预训练中会记忆大量的知识,包括可能侵犯个人生活和身份隐私的信息。以前解决语言模型隐私问题的工作大多集中在数据预处理和差异化隐私方法上,这两种方法都需要重新训练基础的LM。我们提出知识解除学习(unlearning)作为一种替代方法来减少LM的事后隐私风险。我们表明,简单地将非可能性训练目标应用于目标标记序列,就能有效地遗忘它们,而几乎不降低一般语言建模的性能;有时甚至只需几次迭代就能大幅提高基础LM。我们还发现,按顺序解除学习比试图一次性解除所有数据的学习要好,而且解除学习在很大程度上取决于被遗忘的数据(领域)的种类。通过展示与以前的数据预处理方法的比较,我们表明,在易受提取攻击的数据是预先知道的情况下,解除学习可以提供更强的经验隐私保证,同时在计算上更有效率。我们发布了复现我们结果所需的代码和数据集:https://github.com/joeljang/knowledge-unlearning

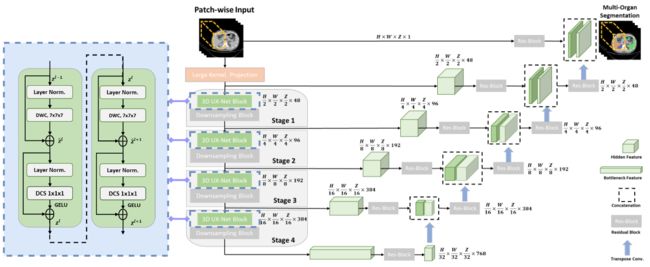
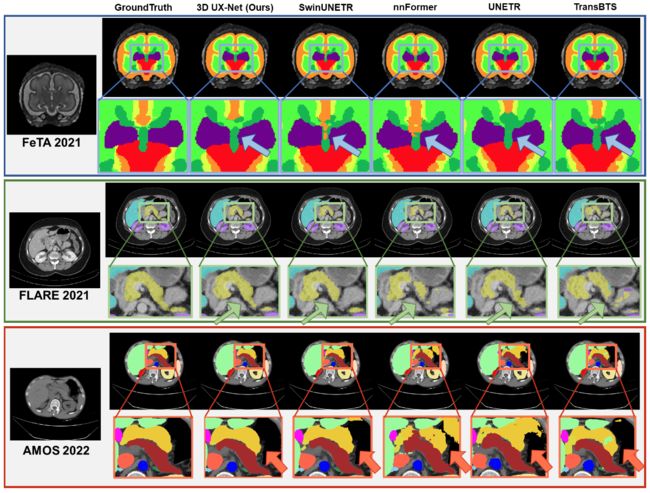
⚡ 论文:3D UX-Net: A Large Kernel Volumetric ConvNet Modernizing Hierarchical Transformer for Medical Image Segmentation
论文时间:29 Sep 2022
领域任务:Image Segmentation, Medical Image Segmentation, 图像分割,医疗图像分割
论文地址:https://arxiv.org/abs/2209.15076
代码实现:https://github.com/masilab/3dux-net
论文作者:Ho Hin Lee, Shunxing Bao, Yuankai Huo, Bennett A. Landman
论文简介:Hierarchical transformers (e. g., Swin Transformers) reintroduced several ConvNet priors and further enhanced the practical viability of adapting volumetric segmentation in 3D medical datasets./分层transformer(如Swin transformer)重新引入了几个ConvNet先验,并进一步增强了在三维医疗数据集中适应体积分割的实际可行性。
论文摘要:视觉transformers(ViTs)已经迅速取代了卷积网络(ConvNets),成为目前最先进的(SOTA)医学图像分割模型。分层transformers(如Swin transformers)重新引入了几个ConvNet先验,并进一步增强了在三维医疗数据集中适应体积分割的实际可行性。混合方法的有效性主要归功于非局部自我注意的大接收场和大量的模型参数。在这项工作中,我们提出了一个轻量级的体积压缩网络,称为3D UX-Net,它利用ConvNet模块适应分层变换器,以实现稳健的体积分割。具体来说,我们重新审视了具有大核尺寸(例如从7×7×7开始)的体积深度卷积,以实现更大的全局感受野,其灵感来自Swin Transformer。我们进一步用点式深度卷积代替Swin Transformer块中的多层感知器(MLP),并通过减少归一化和激活层来提高模型性能,从而减少模型参数的数量。3D UX-Net与目前的SOTA转化器(如SwinUNETR)竞争,使用了三个关于体积脑和腹部成像的挑战性公共数据集:1)MICCAI Challenge 2021 FLARE,2)MICCAI Challenge 2021 FeTA,和3)MICCAI Challenge 2022 AMOS。3D UX-Net始终优于SwinUNETR,改进幅度从0.929到0.938 Dice(FLARE2021)和0.867到0.874 Dice(Feta2021)。我们用AMOS2022进一步评估了3D UX-Net的转移学习能力,并证明了2.27%的Dice改善(从0.880到0.900)。我们提出的模型的源代码可在 https://github.com/MASILab/3DUX-Net 获取。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 获取AI电子月刊与论文 / 电子书等。
