从阿里来个技术大佬,入职就给我们分享Java打日志的几大神坑!
文章来源:https://juejin.cn/post/7152173254734512141

前言
![]()
在日常开发中,如果你是一名后端开发人员,想必应该非常清楚在应用系统运行期间,打印日志有多么重要。
它不但能够记录服务运行情况及轨迹,还有助于提升故障排查及定位问题的效率,甚至还可以对其进行分析及监控,洞察系统隐患,提前预警防范。
如果输出的日志是毫无价值的,或者是存在问题的时候,会给我我们带来很多不必要的麻烦。
今天和大家聊一聊日志,希望大家看完之后能够得到一些帮助。

1. 日志框架众多,兼容问题
我们会接触到不同的日志框架,很多人都认为打印日志是一件简单的事情,但不合理的日志打印会给我们排查问题带来困扰。
常用的日志框架:Logbcak、Log4J、Log4j2、commons-logging
在使用过程中会去调用他们各自的API,完成日志信息的记录,各种各样的API就造成了很混乱的感觉,同时还要避免同时使用他们,会造成死循环。为了解决这个问题应该采用日志门面。
什么是日志门面?
日志门面,是门面模式的一个典型的应用。
门面模式(Facade Pattern),也称之为外观模式,其核心为:外部与一个子系统的通信必须通过一个统一的外观对象进行, 使得子系统更易于使用。
解决方案:SLF4J(Simple Logging Facade For Java)
org.projectlombok
lombok
true
org.slf4j \
slf4j-api \
1.6.1 \
这样做的最大好处,就是业务层的开发不需要关心底层日志框架的实现及细节,在编码的时候也不需要考虑日后更换框架所带来的成本。这也是门面模式所带来的好处。
2. 日志配置复杂,容易出错
在使用日志框架的时候,我们会根据一些定制化的不同级别的日志输出,进行自定义的变更配置,下面整理了下我们需要注意的一些点。
(1)错误配置LevelFilter造成日志重复记录
INFO
问题分析:
我们可以跟进一下源码来定位下,为什么没有过滤INFO的日志信息
public AbstractMatcherFilter() {
this.onMatch = FilterReply.NEUTRAL;
this.onMismatch = FilterReply.NEUTRAL;
}默认是NEUTRAL,默认交给下一个过滤器处理,否则调用onMismatch定义的处理方式处理,默认也是交给下一个过滤器处理
大概的意思就明白了,因为我们没有配置 onMatch 和 onMismatc h,所以默认交给了下一个过滤器执行。
解决方案:
由于没有配置 onMatch 和 onMismatch 属性,导致一直交给下一个过滤器处理,
只要加上配置就可以解决
DENY
ACCEPT 3. 日志异步乱用,导致日志错乱
什么情况下我们会考虑使用异步,那肯定是为了提高性能瓶颈,特别是针对一些突发日志的应用程序比较有利,提高吞吐量。
AsyncAppender 顾名思义是个异步Appender,采用异步方式处理日志,在其内部维护了一个 BlockingQueue 阻塞队列,每次处理日志时,都先尝试把 Log4jLogEvent 事件存入队列中,然后交由后台线程从队列中取出事件并处理(把日志交由 AsyncAppender 所关联的Appender处理),但队列长度总是有限的,且队列默认大小是128,如果日志量过大或日志异步线程处理不及时,就很可能导致日志队列被打满。
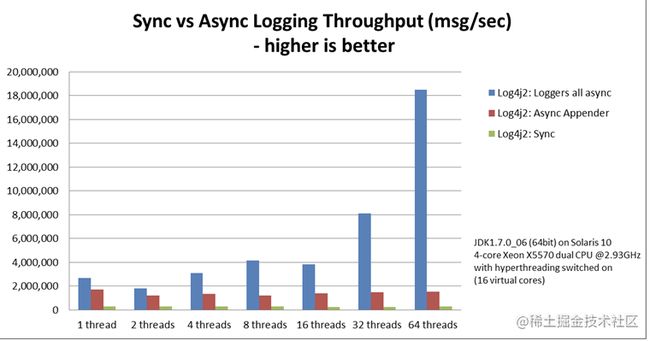
官网也为我们提供的对比图
下图比较了同步记录器、异步追加器和异步记录器的吞吐量。这是所有线程的总吞吐量。在具有 64 个线程的测试中,异步记录器比异步追加器快 12 倍,比同步记录器快 68 倍。
异步记录器的吞吐量随着线程数的增加而增加,而同步记录器和异步追加器的吞吐量或多或少是恒定的,而不管执行日志记录的线程数如何。
(1)异步日志丢失行号、方法名等信息
false

看到前面的?,就是我们丢失的行号、方法名等信息
主要是因为includeCallerData属性设置为false的原因
includeCallerData作用:控制是否收集调用方数据,设置为false目的是为了提高性能
true

(2) 异步日志出现丢失
在异步日志中有关键的三个属性值,他决定了日志是否出现丢失的问题
模拟打印500次的INFO级别的日志信息
@GetMapping("/testPerformance")
public void testPerformance(){
StopWatch stopWatch = new StopWatch();
stopWatch.start();
IntStream.rangeClosed(1, 500).forEach(val ->{
log.info("{}, {}", val, "write log" + val);
});
stopWatch.stop();
log.info("result {} ", stopWatch.prettyPrint());
}执行结果:

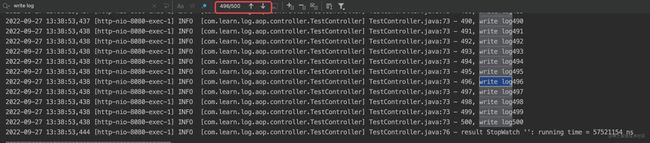
根据图片我们可以看到,我们进行了500次循环,但是打印结果的数据存在缺失。
分析源码
AsyncAppender 类主要继承了 AsyncAppenderBase类
下面我们来看一下源码
public class AsyncAppenderBase extends UnsynchronizedAppenderBase implements AppenderAttachable {
AppenderAttachableImpl aai = new AppenderAttachableImpl();
BlockingQueue blockingQueue;
public static final int DEFAULT_QUEUE_SIZE = 256;
int queueSize = 256;
int appenderCount = 0;
static final int UNDEFINED = -1;
int discardingThreshold = -1;
boolean neverBlock = false;
AsyncAppenderBase.Worker worker = new AsyncAppenderBase.Worker();
public static final int DEFAULT_MAX_FLUSH_TIME = 1000;
int maxFlushTime = 1000;
public AsyncAppenderBase() {
}
if (this.discardingThreshold == -1) {
this.discardingThreshold = this.queueSize / 5;
} queueSize 属性
作用:用于控制阻塞队列大小,防止队列塞满后阻塞,默认为256,内存中最多保存256条日志。
discardingThreshold 属性
作用:控制丢弃日志的阈值,默认值-1,需要注意的是,这里的阈值是指行数,不是百分比
private void put(E eventObject) {
if (this.neverBlock) {
this.blockingQueue.offer(eventObject);
} else {
this.putUninterruptibly(eventObject);
}
}问题分析:
因为 queueSize 的默认为256,所以内存中最多保存256条日志,当到达 discardingThreshold 剩余总行数的五分之一时,就会进行日志丢弃的操作。
解决方案:
通过修改关键的属性值,来进行日志丢失问题的解决
false
0
我们只需要将 discardingThreshold 设置为0,他表示不进行日志的丢弃操作,这样就可以达到保证日志不丢失的目的。
(3)异步日志内存撑爆
因为异步里面主要使用 BlockingQueue 阻塞队列,队列都会存在的一个问题就是过大的时候肯定就会造成OOM。
所以 queueSize 设置特别大,也会造成 OOM 异常。
(4) 异步日志出现阻塞
业务场景:
a. 调用后端RPC服务超时,导致调用方大量线程阻塞
b. 输出异常日志导致大量线程阻塞
关键属性:neverBlock属性
作用:队列满的时候,加入数据是否丢弃,默认不丢弃
是的时候调用 offer() 方法不阻塞,否的时候调用 put() 方法阻塞。
我们来看一下这部分的源码
private void put(E eventObject) {
if (this.neverBlock) {
this.blockingQueue.offer(eventObject);
} else {
this.putUninterruptibly(eventObject);
}
}
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while(true) {
try {
this.blockingQueue.put(eventObject);
return;
} catch (InterruptedException var7) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}在默认情况下,就会调用putUninterruptibly阻塞方法,抛出 OOM 异常后,会一直阻塞着。
所以,当我们设置过大的队列或者不愿意牺牲日志的情况下可能会导致线程的阻塞问题。
我们需要做好取舍的工作,看一看是性能有限还是数据安全优先

4. DefaultErrorHandler存在线程安全问题
// org.apache.logging.log4j.core.appender.DefaultErrorHandler
private static final Logger LOGGER = StatusLogger.getLogger();
private static final int MAX_EXCEPTIONS = 3;
// 5min 时间间隔
private static final long EXCEPTION_INTERVAL = TimeUnit.MINUTES.toNanos(5);
private int exceptionCount = 0;
private long lastException = System.nanoTime() - EXCEPTION_INTERVAL - 1;
public void error(final String msg) {
final long current = System.nanoTime();
// 当前时间距离上次异常处理时间间隔超过5min 或者异常处理数小于3次
if (current - lastException > EXCEPTION_INTERVAL
|| exceptionCount++ < MAX_EXCEPTIONS) {
// StatusLogger 负责处理
LOGGER.error(msg);
}
lastException = current;
}DefaultErrorHandler 内部在处理异常日志时增加了条件限制,只有下述两个条件任一满足时才会处理,从而避免大量异常日志导致的性能问题。
两条日志处理间隔超过5min。
异常日志数量不超过3次。
lastException 用于标记上次异常的时间戳,该变量可能被多线程访问,无法保证多线程情况下的线程安全。
exceptionCount用于统计异常日志次数,该变量可能被多线程访问,无法保证多线程情况下的线程安全。
5. 需要禁止的一些操作
【强制】ERROR 级别日志需打印堆栈,而非 ERROR 级别日志则不需要。
【强制】禁止日志打印内容中仅打印特殊字符或数字的情况。
【强制】禁止使用 Logback/Log4j2 等的 API,应使用 SLF4J 的 API。
【强制】禁止日志不能打印客户敏感信息,如身份证号,银行卡号。
6. 需要注意的一些操作
【建议】日志内容中应包含关键特征类信息,例如:用户标识或流水号。
【建议】应采用异步打印模式,且打印时建议关闭打印位置信息。
【建议】日志打印若出现堵塞,建议至少丢弃 INFO 级别以上的日志。
【建议】每条日志在语义上可独立被理解,减少上下文关联理解。
【建议】打印异常堆栈信息,调用方法log.error(Object message, Throwable e) ,正确写法:log.error("订单【"+orderId+"】详情查询异常:, e);
【强制】在接口/方法的入口/出口处,打印请求及响应参数日志。
7. 系统异常处理原则和实践
异常处理原则
(1)具体明确的原则。具体而不是泛化地抛出异常,明确捕获哪种类型的异常,而不是泛化地捕获Exception类型的异常。 可以对同一try块定义多个catch块。
(2)更泛化的异常类型放在最后的catch块,如IOException。
(3)提早抛出的原则。提早抛出异常(又称"快速失败"),异常得以清晰又准确。
(4)延迟捕获的原则,在合适的层面捕获异常。如在web前端捕获、处理异常,可以有效通知用户并提供处理意见。
异常处理实践
(1)在堆栈跟踪中包含引起异常的原因 。
(2)检查型异常转为运行时异常。如throw new RuntimeException("查询失败",sqlException)。
(3)禁止catch块为空。
异常处理建议
(1)catch块中,ex.printStacktrace()只是将异常输出到控制台,没有任何意义。而且这里出现了异常并没有中断程序,进而调用代码继续执行,导致更多的异常。
(2)不要在PC网页、H5、APP界面上显示异常类名或者打印异常堆栈信息,这种东西对用户没有帮助。
(3)不要将异常包含在循环语句块中(特别注意循环代码块中调用方法中包含异常处理),异常处理占用系统资源。
(4)多层次打印异常,会导致异常日志重复累赘。在合适的处理层打印异常日志信息和处理异常。
(5)不要在 finally 内部使用 return 语句。它不仅会影响函数的正确返回值,而且它可能还会导致一些异常处理过程的意外终止,最终导致某些异常的丢失。
总结
关于日志,确实是我们日常中使用最多,但却最容易忽视的地方,只要线上一出现问题我们只能通过日志来复现问题,
只有规范的输出日志才能让我们的排查做到事半功倍,主要从日志的兼容性、异步日志问题、需要禁止和注意的一些操作,
在之后的输出日志的时候,保持着更严谨的态度。


![]()
欢迎扫码加入儒猿技术交流群,每天晚上20:00都有Java面试、Redis、MySQL、RocketMQ、SpringCloudAlibaba、Java架构等技术答疑分享,更能跟小伙伴们一起交流技术

另外推荐儒猿课堂的1元系列课程给您,欢迎加入一起学习~
互联网Java工程师面试突击课
(1元专享)

SpringCloudAlibaba零基础入门到项目实战
(1元专享)

亿级流量下的电商详情页系统实战项目
(1元专享)

Kafka消息中间件内核源码精讲
(1元专享)

12个实战案例带你玩转Java并发编程
(1元专享)

Elasticsearch零基础入门到精通
(1元专享)

基于Java手写分布式中间件系统实战
(1元专享)

基于ShardingSphere的分库分表实战课
(1元专享)
