【自然语言处理】Python基于逻辑回归模型进行电影评论情感分析项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
NLP(自然语言处理)是计算机科学领域以及人工智能领域的一个重要的研究方向,它研究用计算机来处理、理解以及运用人类语言(如中文等),达到人与计算机之间进行有效通讯。所谓“自然”乃是寓意自然进化形成,是为了区分一些人造语言,类似Python、Java等人为设计的语言。在人类社会中,语言扮演着重要的角色,语言是人类区别于其他动物的根本标志,没有语言,人类的思维无从谈起,沟通交流更是无源之水。这些年,NLP研究取得了长足的进步,逐渐发展成为一门独立的学科,从自然语言的角度出发,NLP基本可以分为两个部分:自然语言处理以及自然语言生成。
本项目应用逻辑回归模型进行电影评论情感分析。
2.数据采集
本次建模数据来源于网络,数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
3.1用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
结果如图所示:
3.2数据缺失值统计
使用Pandas工具的info()方法统计每个特征的缺失值:
结果如图所示:
4.探索性数据分析
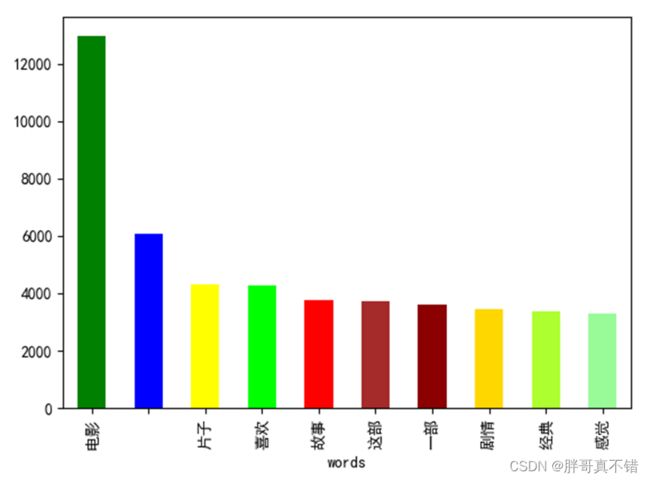
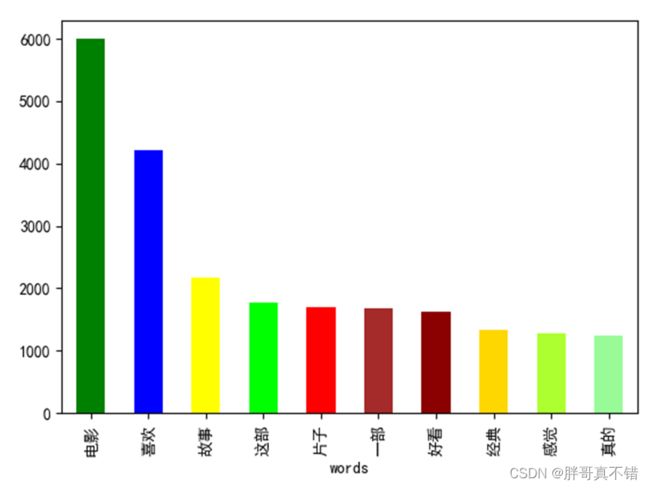
4.1消极类型分词统计
all_words0 = [i.strip() for line in data_0.CONTENT for i in line.split(',')] # 获取所有分词 all_df0 = pd.DataFrame({'words': all_words0}) # 构建数据框 all_df0.groupby(['words'])['words'].count().sort_values(ascending=False)[:10].plot.bar( color=['green', 'blue', 'yellow', 'lime', 'red', 'brown', 'darkred', 'gold', 'greenyellow', 'palegreen']) # 对分词进行统计、按降序进行排序 取前词频前10的分词 plt.show() # 展示图片结果如图所示:
4.2消极类型词云图
my_wordcloud0 = wc.generate(list_new0) # 生成词云 plt.imshow(my_wordcloud0) # 显示词云 plt.axis("off") # 关闭保存 plt.show() wc.to_file('负面词云图.png') plt.close() # 关闭当前窗口结果如图所示:
4.3积极类型分词统计
data_1 = data[data['type'] == 1] all_words1 = [i.strip() for line in data_1.CONTENT for i in line.split(',')] # 获取所有分词 all_df1 = pd.DataFrame({'words': all_words1}) # 构建数据框 all_df1.groupby(['words'])['words'].count().sort_values(ascending=False)[:10].plot.bar( color=['green', 'blue', 'yellow', 'lime', 'red', 'brown', 'darkred', 'gold', 'greenyellow', 'palegreen']) # 对分词进行统计、按降序进行排序 取前词频前10的分词 plt.show() # 展示图片
4.4积极类型词云图
my_wordcloud1 = wc.generate(list_new1) # 生成词云 plt.imshow(my_wordcloud1) # 显示词云 plt.axis("off") # 关闭保存 plt.show() wc.to_file('正面词云图.png') # 保存图片文件 plt.close() # 关闭当前窗口结果如图所示:
5.特征工程
5.1构建特征和标签
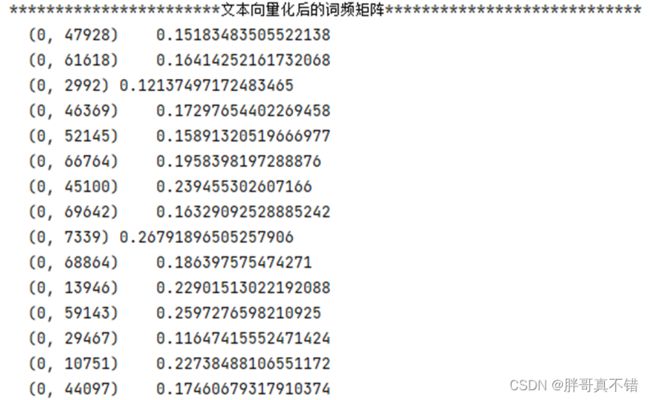
X = data[['CONTENT']] # 构建特征 y = data['type'] # 构建标签5.2 TF/IDF文本特征提取
tfidf = TfidfVectorizer() # 文本向量化 除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征 X_train = tfidf.fit_transform(X_train.CONTENT) # 拟合转换 print('***********************文本向量化后的词频矩阵****************************') print(X_train[:1, :])结果如图所示:
5.3数据集拆分
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=42) # 进行数据拆分6.构建逻辑回归情感分类模型
6.1模型构建
model = LogisticRegression() # 建模 model.fit(X_train, y_train) # 拟合 y_pred = model.predict(X_valid) # 预测7.模型评估
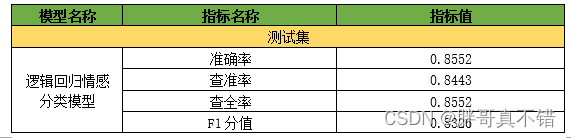
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率(召回率)、F1分值等等。
print('逻辑回归分类模型-默认参数-准确率分值: {0:0.4f}'.format(accuracy_score(y_valid, y_pred))) print("逻辑回归分类模型-默认参数-查准率 :", round(precision_score(y_valid, y_pred, average='weighted'), 4), "\n") print("逻辑回归分类模型-默认参数-召回率 :", round(recall_score(y_valid, y_pred, average='weighted'), 4), "\n") print("逻辑回归分类模型-默认参数-F1分值:", round(f1_score(y_valid, y_pred, average='weighted'), 4), "\n")
通过上表可以看到,模型的准确率为85.52%,F1分值为0.8326,说明模型效果良好。
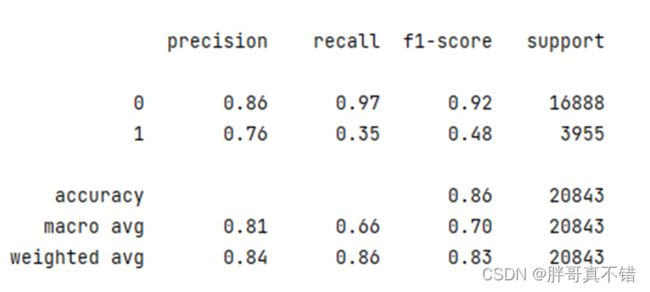
7.2分类报告
print(classification_report(y_valid, y_pred))
类型为负面的F1分值为0.92;类型为正面的F1分值为0.48。
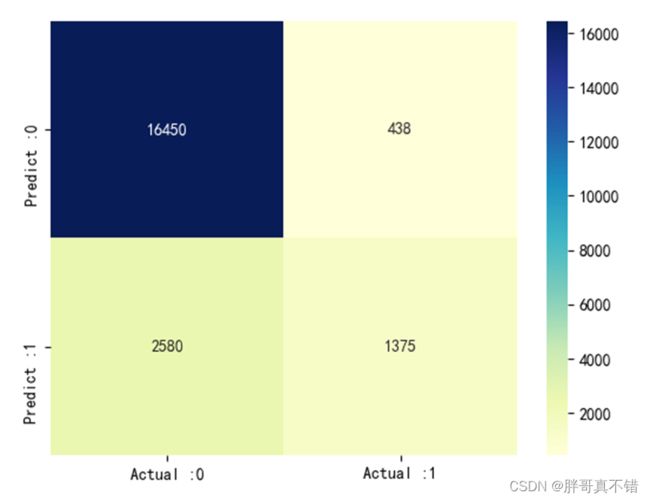
7.3混淆矩阵
cm_matrix = pd.DataFrame(data=cm, columns=['Actual :0', 'Actual :1'], index=['Predict :0', 'Predict :1']) sns.heatmap(cm_matrix, annot=True, fmt='d', cmap='YlGnBu') # 热力图展示 plt.show() # 展示图片结果如图所示:
从上图可以看到,预测为负面 实际为正面的有428条;预测为正面 实际为负面的2580条。
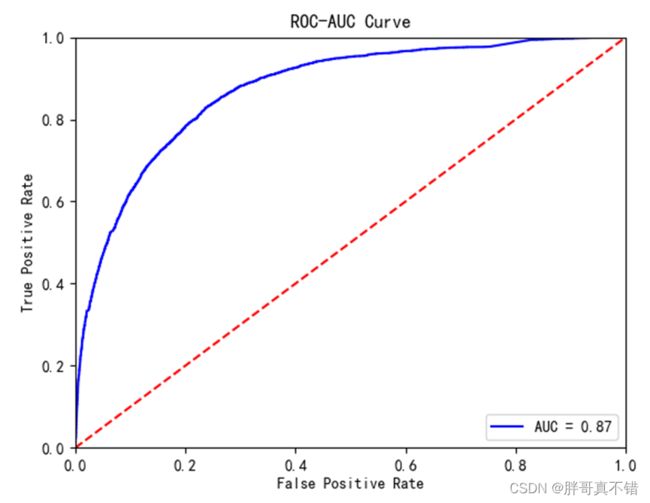
7.4ROC曲线
plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % roc_auc) # 绘制曲线图 plt.legend(loc='lower right') # 设置图例 plt.plot([0, 1], [0, 1], 'r--') # 绘制曲线图 plt.xlim([0, 1]) # 获取或设置x轴数值显示范围0-1 plt.ylim([0, 1]) # 获取或设置y轴数值显示范0-1 plt.ylabel('True Positive Rate') # 设置y轴名称 plt.xlabel('False Positive Rate') # 设置x轴名称 plt.title('ROC-AUC Curve') # 设置标题 plt.show() # 显示图片结果如图所示:
从上图可以看到,AUC的值为0.87,说明模型效果良好。
8.总结展望
本项目应用逻辑回归模型针对电影评论数据进行情感分类研究,通过数据预处理、探索性数据分析、特征工程、模型构建、模型评估等工作,最终模型的F1分值达到0.83,这在文本分类领域,是很不错的效果,可以应用于实际工作中。






本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取码:bcbp网盘如果失效,可以添加博主微信:zy10178083