springboot入门
一.springboot加载机制
springboot 用来简化Spring等框架的操作,整合maven项目,可以和Spring框架无缝衔接,可以理解一个框架的高级API。
1 核心机制
“开箱即用” :只需导入特定的jar包文件 则可以直接使用其中的功能。
根本原因: SpringBoot 将主流的框架进行整合,内部进行了扩展,无需多余的配置 拿来就用.即开箱即用
2 pom.xml文件
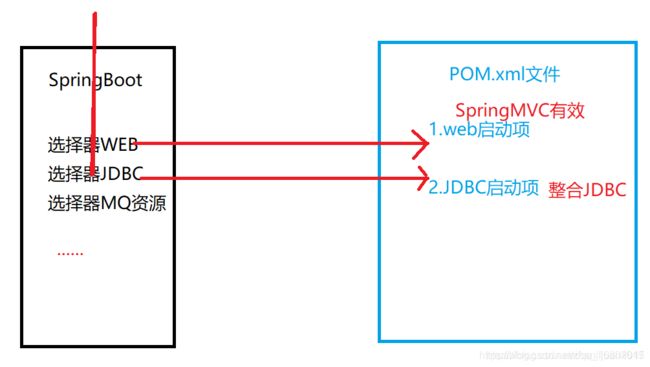
SpringBoot 中pom.xml文件 只是添加了jar包文件的依赖. 存储到项目中,需要被其他程序调用才能生效.
SpringBoot中常见启动项(依赖):
1.spring-boot-starter-web
2.spring-boot-starter-text
3.spring-boot-starter-jdbc
4.spring-boot-starter-aop
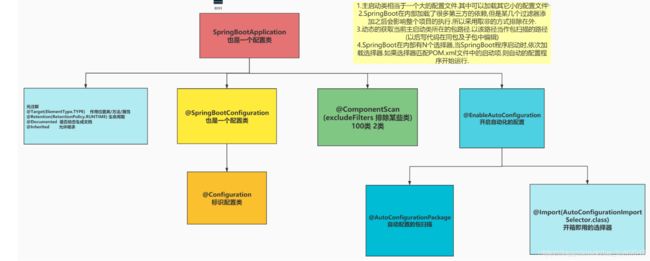
3 @SpringBootApplication注解说明
说明: SpringBoot程序启动的实质 注解开始工作.
3.1 注解的结构
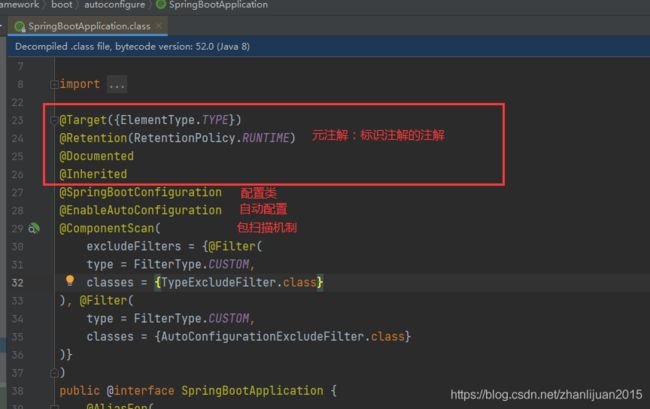
3.2 启动项执行过程
3.3 SpringBoot主启动类加载过程
4 框架之间的关系
1.SpringMVC 作用: 接收用户提交的数据,返回服务器数据.(交互)
2.Spring 作用: 整合其他的第三方框架,可以让程序调用以一种统一的方式进行调用 (整合)
3.Mybatis 作用: 整合JDBC 方便用户与数据库进行交互(持久化)

5 springboot加载器顺序
1.当用户点击main方法时启动程序.(开始)
2.SpringBoot程序开始加载主启动类上边的注解@SpringBootApplication(SpringBoot内部运行机制开始执行)
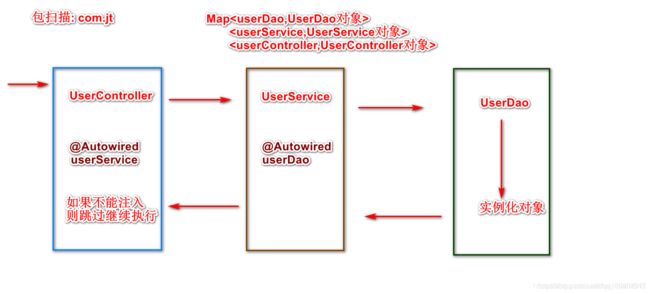
3.当SpringBoot程序开始执行,则会动态的获取当前主启动类的包路径.
4.通过包扫描的机制 将特定的注解标识的类(Controller/Service/Dao).交给Spring容器管理.
5.Spring容器维护的是一个Map集合
6.当对象创建时(实例化),遇到@Autowired 则需要依赖注入对象,当整个Spring容器内部都没有该对象时,则会报错 注入失败. 如果Map中维护了需要注入的对象,.则@Autowired 注入成功, 则最终对象实例化正常.
7.当上述的操作都运行成功之后则spring容器启动成功,等待用户的调用.
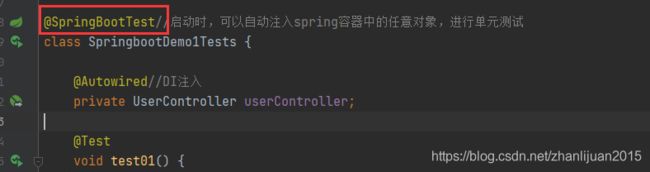
二、@SpringBootTest注解说明
springboot提供的注解,导包时名称一般含有org.springframework.boot
import org.springframework.boot.test.context.SpringBootTest;
注解说明: 如果测试方法中添加了该注解,则当执行**@Test**注解方法时,则Spring容器将会启动,启动之后将所有需要依赖注入的信息完整构建.之后用户有针对性的挑选需要测试的代码 测试即可.
三、springboot整合SpringMVC流程
1 Servlet机制
Servlet(Server Applet)是Java Servlet的简称,称为小服务程序或服务连接器,用Java编写的服务器端程序,具有独立于平台和协议的特性,主要功能在于交互式地浏览和生成数据,生成动态Web内容。
总结: Servlet是JAVA实现前后端数据交互的一种机制
2 Servlet核心对象
Request对象 Response对象

3 SpringMVC调用流程
3.1 重要的组件
1、前端控制器 DispatcherServlet 实现请求的流转
2、处理器映射器 实现了请求路径与方法之间的映射.
3、处理器适配器 ,处理器的管理器 内部有N个处理器. 针对不同的用户请求 调用不同的处理器完成任务
4、视图解析器 ,实现页面路径的拼接
3.2 SpringMVC程序启动前状态说明
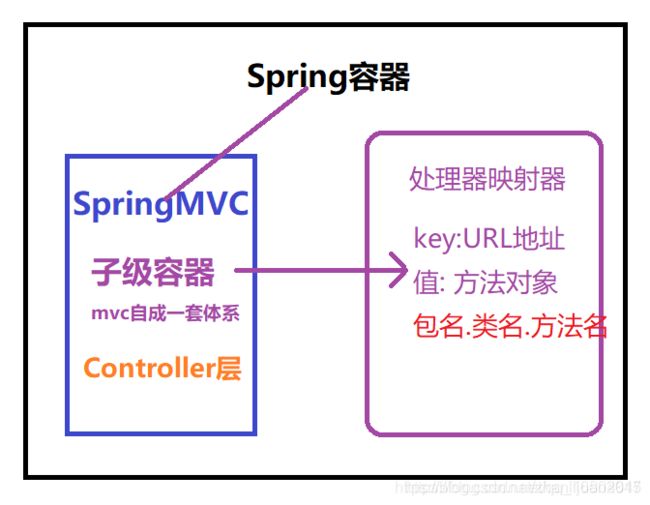
父子容器概念:
1.Spring容器(内存中的一大块空间)由于IOC/DI的机制,可以作为第三方的管理者 所以作为父级.
2.SpringMVC容器,其中只负责Controller层的相关的对象的管理.
说明: 当SpringMVC容器启动时,提前将SpringMVC中的所有请求路径与方法完成映射.
3.3 SpringMVC运行流程
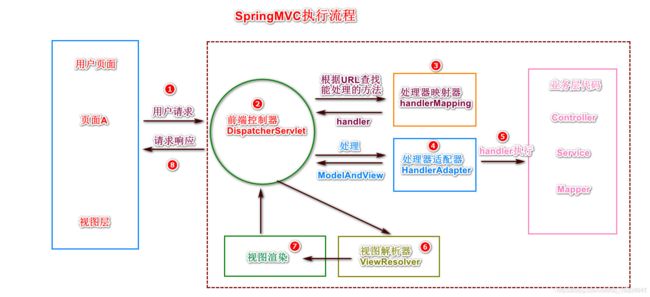
1、用户发起请求时,第一步经过前端控制器,
2、但是前端控制器 只负责请求的转发和响应.不做任何业务处理.将请求转发给处理器映射器.
3、处理器映射器接收到前端控制器的请求之后,查询自己维护的服务列表信息。
如果服务列表中没有这个URL的key. 该程序不能处理用户的请求,则返回特定数据,前端控制器接收之后响应用户404.
如果服务列表中有该URL key 则说明请求可以正常执行. 将该方法的对象返回给前端控制器.
4、前端控制器将返回的方法进行接收,但是由于前端控制器只负责转发和响应,不能直接执行该方法.所以交给处理器适配器执行.
5、处理器适配器根据方法的类型(xml配置文件/注解/其他方法),处理器适配器在自己的处理器库中挑选一个最为合适的处理器去执行该方法. 当处理器执行该方法时标识业务开始. 将最终的处理的结果通过ModelAndView对象进行包裹,返回给前端控制器.
ModelAndView: Model: 代表服务器返回的业务数据 View: 服务器端返回的页面的名称
6、视图解析器 将View中的数据进行解析 拼接一个完整的页面路径 前缀/hello后缀
7、视图渲染: 将数据与页面进行绑定. 这样用户就可以在页面中看到具体的数据.
8、由于现在流行前后端分离. 所以SpringMVC省略了视图解析和视图渲染.只有前5步. 核心注解: @ResponseBody 省略6-7步
4 SpringMVC提供的注解
springmvc提供的注解,导包时名称一般含有org.springframework.web
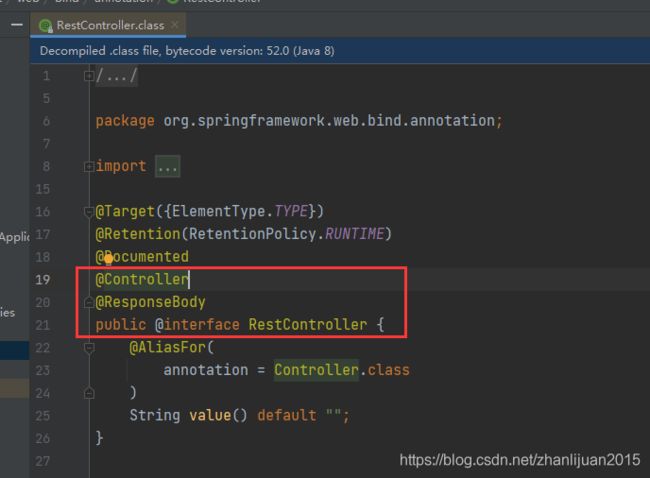
4.1 @RestController
import org.springframework.web.bind.annotation.RestController;
作用:接收用户的请求,如果返回对象并响应json数据
@RestController = @Controller + @ResponseBody
4.2 @RequestMapping
import org.springframework.web.bind.annotation.RequestMapping;
作用:请求后的映射路径
4.3 @CrossOrigin
import org.springframework.web.bind.annotation.CrossOrigin;
作用:解决跨域问题
跨域详情介绍点这里》》》
4.4 @PathVariable
import org.springframework.web.bind.annotation.PathVariable;
作用:获取restful里的参数值

4.5 @ResponseBody
import org.springframework.web.bind.annotation.ResponseBody;
作用:返回对象利用jackson工具类转换为json字符串
4.6 @RequestBody
import org.springframework.web.bind.annotation.RequestBody;
将json串转化为对象
4.7 @RequestParam
import org.springframework.web.bind.annotation.RequestParam;
参数名和请求参数名称不同时使用,可以设置默认值
四.springboot整合mybatis核心
1 加入依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<scope>runtimescope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.2.0version>
dependency>
2 编辑YML配置文件
SpringBoot程序加载jar包文件之后,通过YML配置文件实现数据的填充.配置Mybaits相关信息.
#spring整合数据源
spring:
datasource:
#使用高版本驱动使用cj
driver-class-name: com.mysql.cj.jdbc.Driver
#serverTimezone=GMT%2B8 东8区 %2B +号
#useUnicode=true&characterEncoding=utf8 是否开启useUnicode编码/utf-8
#autoReconnect=true 断线允许重连
#allowMultiQueries=true 是否允许批量操作
url: jdbc:mysql://127.0.0.1:3306/jt?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
username: root
#如果密码以数据0开头,则使用“”包裹,“0123456”
password: 1234
#springboot整合mybatis配置
mybatis:
#设置别名包
type-aliases-package: com.jt.pojo
#加载映射文件,
mapper-locations: classpath:/mappers/*.xml
#开启驼峰映射
configuration:
map-underscore-to-camel-case: true
3 为接口创建代理对象
SpringBoot为了整合mybatis,简化代码结构,spring动态的为mybatis的接口创建代理对象
代理对象理解:根据原有对象的模型,在运行期动态创建了一个一模一样功能的实例化对象
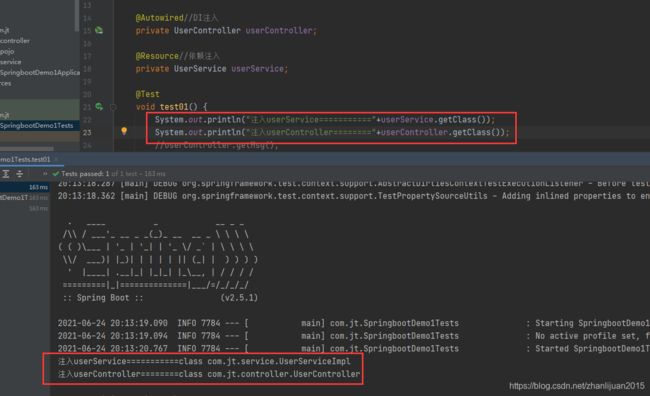
前提:明确spring提供的依赖注入,写代码时注入的是接口,实际上注入的一定是对象,以下代码获取注入的class对象可以验证,注入的是userService,但代码打印的class对象是userServiceImpl
但我们写的Mapper接口,没有写实现类,我们注入是什么呢?
@Mapper注解:写在接口上,springboot为了整合mybatis,简化代码接口,spring动态的为mybatis接口创建代理对象(jdk代理)
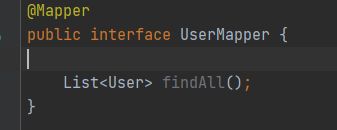
写了@Mapper注解,真的创建了代理对象吗?代码验证
4 @MapperScan的引入
每写一个Mapper接口,就写一个@Mapper注解,代码冗余,SpringBoot为了简化代码,在主启动类上提供了包扫描机制,引入 @MapperScan注解,为包路径下的接口创建了代理对象,之后交给spring容器管理,可以任意位置依赖注入

5 Mybatis 接口注解说明
第一种:将所有的Sql语句都写到xml 映射文件中. (万能操作方式)
第二种:可以将Sql语句通过注解的方式标识在接口方法中.(只适用于简单操作)
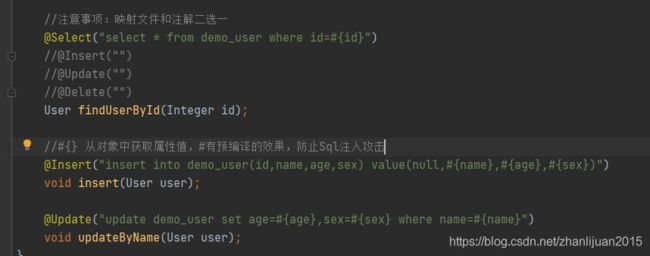
注:注解和映射文件只能二选一
五.springboot整合mybatis-plus
说明: mybatis-plus简称MP,使用MP主要完成单表的CURD操作简化开发(以对象的方式操作数据库 单表几乎不写Sql 简化代码操作)
1 工作原理
核心思想: 以对象的方式操作数据库.
配置:
- 编辑POJO与数据表的映射.
- 编辑POJO属性与表字段映射. 映射.
- 封装了大量的常用CURD API 简化用户调用
- 根据对象动态的生成Sql语句.
执行过程:
- 程序业务开始调用
userMapper.insert(user); - 根据Mapper接口动态获取操作的泛型对象.获取对象之后获取表的相关数据
public interface UserMapper extends BaseMapper{}
- 只要获取对象就获取了 表名称,字段名称.数据的值
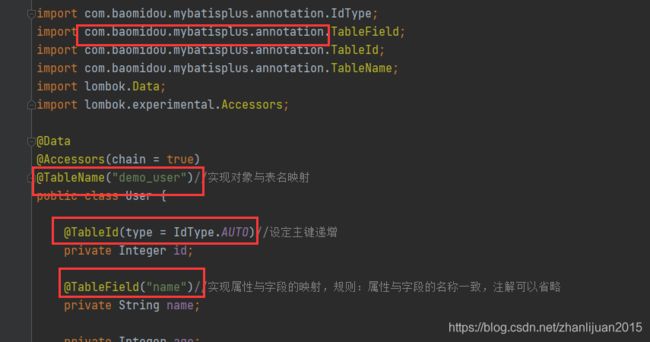
@Data
@Accessors(chain = true)
@TableName("demo_user")//实现对象与表名映射
public class User {
@TableId(type = IdType.AUTO)//设定主键递增
private Integer id;
@TableField("name")//实现属性与字段的映射,规则:属性与字段的名称一致,注解可以省略
private String name;
private Integer age;
private String sex;
}
- 将对象转化为特定的Sql,之后交给Mybatis执行.
2 实现步骤
2.1 引入jar包
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.4.3version>
dependency>
2.2 编辑POJO
说明:
1.POJO应该与数据库中的表完成映射
2.POJO中的属性与表中的字段一一映射.
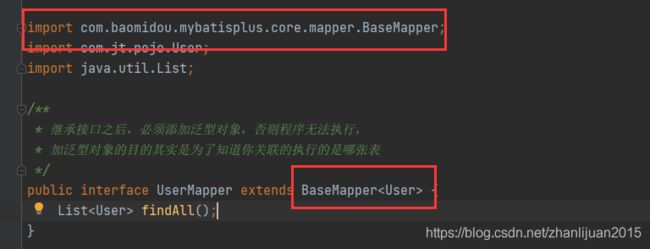
2.3继承公共的接口
说明: 继承接口之后,必须添加泛型对象 否则程序无法执行
父级中的接口:MP将常用的CURD的方法进行了抽取. 以后子类如果需要调用.则直接使用即可.
2.4 MP生效配置
说明: 将原来的mybatis 改为mybatis-plus即可
#springboot整合MybatisPlus配置
mybatis-plus:
#设置别名包
type-aliases-package: com.jt.pojo
#加载映射文件,
mapper-locations: classpath:/mappers/*.xml
#开启驼峰映射
configuration:
map-underscore-to-camel-case: true
#打印sql语句
logging:
level:
#指定包路径,日志输出
com.jt.mapper: debug
3 MP常用操作
3.1 查询常用操作
@Test
public void testSelect() {
/**
* 创建查询条件构造器,封装where条件,实现时会动态的根据对象不为null的属性,拼接where条件,默认的关系连接符and
*/
//方式一
QueryWrapper<User> queryWrapper1 = new QueryWrapper<>(new User().setName("小乔").setSex("男"));
//方式二
QueryWrapper<User> queryWrapper2 = new QueryWrapper<>();
queryWrapper2.eq("name", "小乔").eq("sex", "男");
//方式三(常用逻辑运算符> gt ,< lt ,= eq ,>= ge, <= le,! = ne)
QueryWrapper<User> queryWrapper3 = new QueryWrapper<>();
queryWrapper3.gt("age", 18).eq("sex", "女");
//方式四 like关键字
QueryWrapper<User> queryWrapper4 = new QueryWrapper<>();
queryWrapper4.like("name", "乔");
//queryWrapper3.likeLeft("name", "乔");
//方式五 in关键字
QueryWrapper<User> queryWrapper5 = new QueryWrapper<>();
/**
* in(R column, Object... values)
* java中参数使用... 表示可变参数类型 多个参数逗号分割,一般定义可变参数类型时一般位于方法的最后一位
* 可变参数类型的实质就是数组,写法不同而已
*/
//queryWrapper5.in("id",1,3,5,6);
/**
* in(R column, Collection coll)
* 有坑坑坑 注意!!!!当传入数组是基本类型时 比如new int[]{1,3,5,6},内部得到的参数信息是[I@799f916e(int[])
* 因此数组一般采用包装类型,使用对象身上的方法,基本类型没有方法
*/
queryWrapper5.in("id", new Integer[]{1, 3, 5, 6});
//方式六 order by关键字
QueryWrapper<User> queryWrapper6 = new QueryWrapper<>();
queryWrapper6.eq("sex", "男").orderByDesc("age");
//方式七 API说明queryWrapper.eq(判断条件,字段名称,字段值) 判断条件true 则动态的拼接where条件;判断条件为false 不会拼接where条件
QueryWrapper<User> queryWrapper7 = new QueryWrapper<>();
queryWrapper7.eq(StringUtils.hasLength("女"), "sex", "女");
//System.out.println(userMapper.selectList(queryWrapper7));
//方式8 只获取主键ID的值,返回list
System.out.println(userMapper.selectObjs(null));
}
3.2修改常用操作
@Test
public void testUpdate2() {
//修改除ID之外的所有不为null的数据,id当作where唯一条件
//userMapper.updateById(new User().setId(228).setName("晚上吃啥呢"));
/**
* userMapper.update(对象,修改条件构造器)
* 对象:修改后的数据使用对象封装
* 修改条件构造器:负责修改的where条件
*/
UpdateWrapper<User> userUpdateWrapper=new UpdateWrapper<>();
userUpdateWrapper.eq("name","星期五");
userMapper.update(new User().setName("宵夜吃什么么").setAge(20).setSex("女"),userUpdateWrapper);
}
4 MP分页
关于MP分页规则说明
规则:需要设定一个拦截器,将分页的Sql进行动态拼接
Sql规则:现在的Sql都支持Sql92标准!!!设计理念不同
4.1 配置说明
/**
* 命名规则:如果该类 类似于配置文件,则把这个类称之为“配置类” 一般config结尾
*/
@Configuration//表示我是一个配置类(代替之前的xml文件)
public class MybatisPlusConfig {
/**
* 铺垫:xml中通过标签管理对象,将对象交给Spring容器管理
* 配置类:将方法的返回值交给Spring容器管理 @Bean注解
*/
// 最新版
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
4.2 分页代码
/**
* 利用Mp的方式实现分页查询
* API说明 userMapper.selectPage(arg1,arg2)
* arg1: MP中的分页对象 固定的
* arg2: MP分页中的条件构造器
* 动态Sql: select * from user where username like "%admin%"
* 条件: 如果用户传递query则拼接where条件 否则不拼接where条件
*/
@Override
public PageResult getUserList(PageResult pageResult) {
//1.定义MP分页中的对象
IPage iPage =new Page(pageResult.getPageNum(),pageResult.getPageSize());
//2.构建查询条件构造器
QueryWrapper queryWrapper=new QueryWrapper<>();
queryWrapper.like(StringUtils.hasLength(pageResult.getQuery()), "username", pageResult.getQuery());
//3.经过MP分页查询将所有的分页(total/结果/页面/条数/xxx)数据封装到iPage对象
iPage=userMapper.selectPage(iPage,queryWrapper);
return pageResult.setRows(iPage.getRecords()).setTotal(iPage.getTotal());
}
5 MP数据自动填充
通过数据库进行 “更新” 操作,会修改数据库中的创建时间/修改时间. 每张表都有类似的操作. 所以应该抽取为一个公共API进行业务调用
5.1 数据自动填充功能
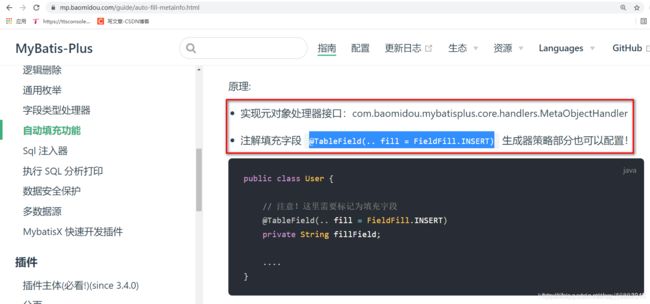
5.2 编辑pojo属性
说明: 设定POJO属性 什么时候实现自动填充.
//pojo基类,完成2个任务,2个日期,实现序列化
@Data
@Accessors(chain=true)
public class BasePojo implements Serializable{
@TableField(fill = FieldFill.INSERT)
private Date created; //表示入库时需要赋值
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updated; //表示入库/更新时赋值.
}
5.3 实现MP自动填充
说明: MP对外暴露了一个自动填充的接口MetaObjectHandler ,用户只需要实现该接口,并且重写其中的方法.即可以实现自动填充的功能.
package com.jt.config;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.stereotype.Component;
import java.util.Date;
@Component//将对象交给Spring容器管理 不属于C/S/M
public class MyMetaObjectHandler implements MetaObjectHandler {
/**
* 入库操作时调用
* setFieldValByName(arg1, arg2, arg3)
* arg1:自动填充的字段名称 arg2:自动填充的值 arg3:metaObject 固定写法
*/
@Override
public void insertFill(MetaObject metaObject) {
Date date=new Date();
this.setFieldValByName("created",date,metaObject);
this.setFieldValByName("updated",date,metaObject);
}
//更新操作时调用 updated
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updated",new Date(),metaObject);
}
}
六、springboot整合spring
1.spring中AOP
1.1 应用场景
AOP(Aspect Oriented Programming)面向切面编程:在不影响源码的条件下,对方法进行扩展.,应用场景如下:
日志管理:可以记录请求信息的日志,以便进行信息监控、信息统计、计算PV(Page View)等等。
权限管理:如登陆检测,进入处理器检测是否登陆,如果没有直接返回到登陆页面。
缓存管理:
事物管理:对事务的提交回滚等,与业务无关的代码
性能监测:可以通过拦截器在进入处理器之前记录开始时间,在处理完后记录结束时间,从而得到该请求的处理时间;
1.2 组成部分
- Aspect切面:其实就是一个类,由通知和切点组成
- 切点PointCut:找到指定包里的类,类里的方法,增加功能
通过切点(PointCut)配置切点表达式(expression)来指定哪些类的哪些方法上织入(weaving in)横切逻辑,被切的地方叫连接点(JoinPoint) - 通知Advice:就是类里的一个方法,分为
1.前置通知 @Before,
2.后置通知 @After
3.环绕通知@Around
4.返回后通知@AfterReturning
5.异常通知@AfterThrowing
1.3 代码实现
说明:有多个切面,可以使用注解@Order(1) 定义执行顺序,数字越小,越先执行
package cn.tedu.service;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.stereotype.Component;
import org.springframework.core.annotation.Order;
/**
* spring的AOP功能,其实就是为了增强方法的功能,由切点和通知组成
* AOP的使用场景:事物管理,日志管理,权限管理,缓存管理,性能测试
*/
@Component
@Order(1)//有多个切面,设置执行顺序,数字越小越优先执行
@Aspect///1.标记是一个切面
public class AspectTest {
/**
* 2.切点表达式:用来给指定的包,类,方法加功能 @Pointcut("execution(返回值 包名.类名.方法名(参数列表) )")
* *代表一个值 返回值随便, ..表示多个值 service的多个包 ( 第一个*表示方法的返回值,第二个*表示类,第三个*表示方法)
*/
@Pointcut("execution(* cn.tedu.service..*.*(..) )")
public void point(){}
/**
* 3.通知,本质上是一个方法,增强功能
*/
@Around("point()")//标志这是环绕通知,是在方法执行前后都加了功能
public Object doAround(ProceedingJoinPoint joinPoint) throws Throwable{
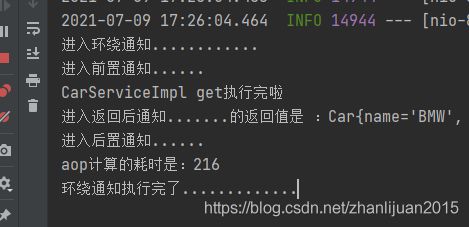
System.out.println("进入环绕通知............");
long start=System.currentTimeMillis();
Object o=joinPoint.proceed(); //执行原来的业务方法
long end=System.currentTimeMillis();
System.out.println("aop计算的耗时是:"+(end-start));
System.out.println("环绕通知执行完了.............");
return o;
}
@Before("point()")
public void doBefore(JoinPoint joinPoint){
System.out.println("我是前置通知");
}
@After("point()")
public void doAfter(JoinPoint joinPoint){
System.out.println("后置通知执行了!");
}
@AfterReturning(value="point()",returning = "keys")
public void doAfterReturning(JoinPoint joinPoint,Object keys){
System.out.println("返回后通知的返回值是 :"+keys);
}
@AfterThrowing(value="point()",throwing = "exception")
public void doAfterThrowingAdvice(JoinPoint joinPoint,Throwable exception){
System.out.println("异常通知...........");
// 目标方法名
System.out.println(joinPoint.getSignature().getName());
if(exception instanceof NullPointerException){
System.out.println("发生了空指针异常");
}
}
}
单个切面执行顺序:
环绕通知开始–>前置通知—>执行业务方法---->返回后通知---->后置通知----->环绕通知结束
多个切面执行顺序,Spring AOP就是面向切面编程,什么是切面,画一个图来理解下:
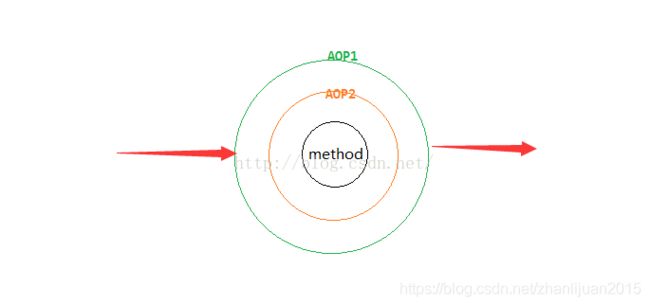
由此得出:spring aop就是一个同心圆,要执行的方法为圆心,最外层的order最小。从最外层按照AOP1、AOP2的顺序依次执行Around方法,Before方法。然后执行method方法,最后按照AOP2、AOP1的顺序依次执行AfterReturning、After方法。也就是说对多个AOP来说,先before的,一定后after。
多个切面和多个拦截器同时执行顺序
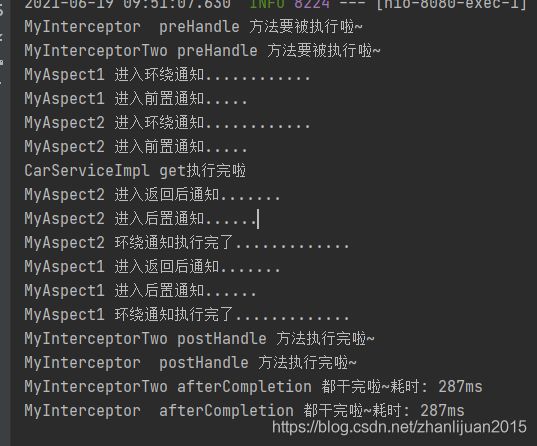
2 spring中事务控制
2.1 原子性
关于原子性说明: 一个方法该方法中的业务要么同时成功/要么同时失败. 才能满足原子性的要求.
2.2 @Transactional 注解说明
Spring针对于数据库中的事务控制,开发了一套注解**@Transactional**,其注解的核心用法采用AOP中的Around通知,实现了对事务的控制.

2.3 注解用法
Spring默认的事务策略:
1.如果控制的方法出现了运行时异常则事务自动的回滚.
2.如果控制的方法 检查异常(编译异常), 事务不会自动回滚,Spring任务程序既然已经提示需要异常的处理.则默认由程序员自己控制.Spring不负责管理.
注解属性
rollbackFor: 遇到什么类型, 异常回滚事务,
noRollbackFor: 遇到什么类型的异常 事务不回滚.
关于属性说明: 一般工作中都采用默认策略,特殊条件下才使用该配置.
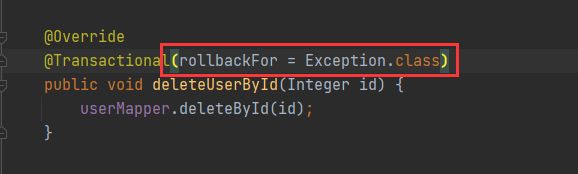
3.全局异常处理机制
核心思想:AOP,环绕通知
3.1 业务说明
一般在业务操作时,无法保证所有的操作都能正常运行.所以为了完全性,需要添加大量的try-catch代码. 效果如图:
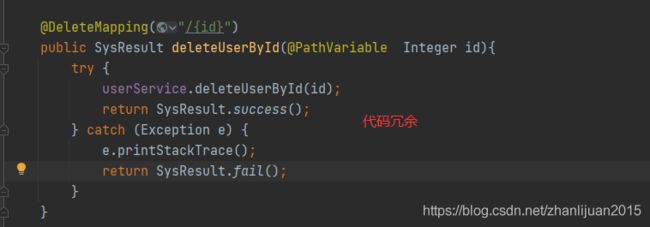
需求: 如果将大量的try-catch代码直接写到业务中,导致业务代码混乱,所以需要将异常信息进行抽取.所有提供了全局异常处理机制. Spring4开始的.
3.2 全局异常处理实现
package com.jt.exception;
import com.jt.vo.SysResult;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
/**
* 全局异常处理,内部依然采用环绕通知的方式
* 异常处理之后返回的json串,该全局异常处理机制,捕获Controller层的异常(其它层向上抛出)
*/
@RestControllerAdvice
public class MyException {
/**
* 业务:如果后端报错,应该及时提示前端用户,返回统一的对象SysResult status=201/msg="XXX失败"
* 注解说明:@ExceptionHandler(RuntimeException.class)
* 当遇到某种异常时,全局异常处理机制有效
*/
@ExceptionHandler(RuntimeException.class)
public Object exception(Exception e){
//1.打印异常信息
e.printStackTrace();
//2.返回特定的响应数据
return SysResult.fail();
}
}
4.Spring自动装配过程
4.1 Spring"容器"
说明: Spring容器是在内存中一大块的内存区域,存储Spring管理对象
数据结构: KEY-VALUE结构
数据类型: Map集合
Map详细说明: Key: 类型首字母小写 Value: 对象
4.2 依赖注入的原理
- 按照类型注入
按照属性的类型 去Map集中中查找是否有改类型的对象. 如果有则注入. - 按照名称注入
根据属性的name 去Map集中中查找对应的KEY
@Autowired
@Qualifier(value="李四")
private SpringService springService;
4.3 自动装配的规则说明
1.如果对象在进行实例化.如果对象中的属性被 @Autowired注解修饰,则说明应该先注入属性.
2.先根据属性的类型,查找Map集合中是否有该类型的对象.
3.如果根据类型查找没有找到,则根据属性的名称按照name查找对象.
4.如果上述的方式都没有找到,则报错实例化对象失败.
原则:Spring容器中要求 接口必须单实现. 如果有多实现则通过@Qualifier(“xxxx”)区分即可
5.spring提供的注解
spring提供的注解,导包时名称一般含有org.springframework,没有web,这是与springmvc提供注解的主要区分
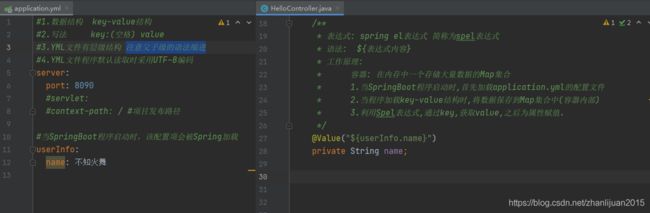
5.1 @Value
import org.springframework.beans.factory.annotation.Value;
用法如下:
5.2 @PropertySource
import org.springframework.context.annotation.PropertySource;
作用:根据指定路径,加载配置文件,交给Spring容器管理

5.3 @Controller
import org.springframework.stereotype.Controller;
作用:controller层使用 标识是一个Controller,Spring包扫描创建实例
5.4 @Service
import org.springframework.stereotype.Service;
作用:Service层中使用,让IOC容器对于你注解的类可以在容器中生成相应的bean实例
5.5 @Autowired
import org.springframework.beans.factory.annotation.Autowired;
作用:Spring自动给你进行了new一个对象将这个对象放入你的注解所在类里面。
@Autowired 和 @Resource区别比较
@Autowired 默认先按byType进行匹配,如果发现找到多个bean,则又按照byName方式进行匹配,如果还有多个,则报出异常。
@Resource(javax.annotation.Resource)默认按byName自动注入。
既不指定name属性,也不指定type属性,则自动按byName方式进行查找。如果没有找到符合的bean,则回退为一个原始类型进行进行查找,如果找到就注入。
只是指定了@Resource注解的name,则按name后的名字去bean元素里查找有与之相等的name属性的bean。
只指定@Resource注解的type属性,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常。
5.6 @Component
import org.springframework.stereotype.Component;
通用注解,表示这是一个组件
5.7 @Repository
import org.springframework.stereotype.Repository;
表示这是一个持久层
七.lombok插件提供的注解
作用: 简化用户创建实体对象(POJO)的过程,由插件自动的完成实体对象中常用方法的构建(get/set/toString/构造等)
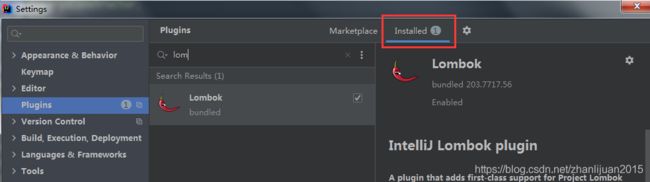
使用:
idea安装插件
pom文件引入插件
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
1 @Data
import lombok.Data;
在JavaBean或类JavaBean中使用,这个注解包含范围最广,它包含**@getter**(生成对应的getter方法)、@setter生成对应的setter方法、@NoArgsConstructor(生成无参构造)注解,@ToString即当使用当前注解时,会自动生成包含的所有方法;
2 @NoArgsConstructor
import lombok.NoArgsConstructor;
作用:生成无参构造
3 @AllArgsConstructor
import lombok.AllArgsConstructor;
作用:生成全参构造
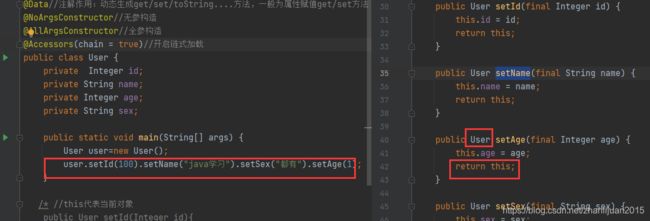
4 @Accessors(chain = true)
import lombok.experimental.Accessors;
作用:开启链式加载,链式调用
原理:未开启链式加载时,set方法的返回值void,不能链式调用,开启链式加载后,编译后生成的字节码文件中的属性set方法有返回值,返回this当前对象
5 @ToString
在JavaBean或类JavaBean中使用,使用此注解会自动重写对应的toStirng方法
使用参数:
@ToString(exclude=“column”),排除column列所对应的元素,即在生成toString方法时不包含column参数;
@ToString(of=“column”),只生成包含column列所对应的元素的参数的toString方法,即在生成toString方法时只包含column参数;
6 @EqualsAndHashCode
在JavaBean或类JavaBean中使用,使用此注解会自动重写对应的equals方法和hashCode方法;
7 @Slf4j
在需要打印日志的类中使用,当项目中使用了slf4j打印日志框架时使用该注解,会简化日志的打印流程,只需调用info方法即可;
8 @Log4j
在需要打印日志的类中使用,当项目中使用了log4j打印日志框架时使用该注解,会简化日志的打印流程,只需调用info方法即可;