【十分钟机器学习系列笔记】决策树-剪枝
视频作者:简博士 - 知乎 (zhihu.com);简博士的个人空间_哔哩哔哩_bilibili
链接:【合集】十分钟 机器学习 系列视频 《统计学习方法》_哔哩哔哩_bilibili
原书:《统计学习方法》李航
决策树生成算法递归地产生决策树,直到不等你继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,模型结构过于复杂,即出现过拟合现象
直接来看优秀的决策树一般要求深度小、叶结点少
剪枝是我们常用来处理决策树的过拟合问题的手段,一般有预剪枝的后剪枝
预剪枝:生辰过程中,对每个节点划分前进行估计,若当前节点的划分不能提升泛化能力,则停止划分,记当前结点为叶结点
后剪枝:生成一颗完整的决策树之后,自底而上的对内部结点考察,若此内部节点变为叶结点,可以提升泛化能力,则做此替换
预剪枝
限定决策树的深度

通过ID3生成决策树

如果我们限定决策树的深度为2,那么我们需要对根蒂 → \rightarrow →色泽进行剪枝
其中符合纹理为清晰,根蒂为稍蜷缩的数据有

显然是否好瓜中,是为2个,否为1个,因此我们认为剪枝后的根蒂在稍蜷缩的情况下,对叶结点为好瓜,即新的决策树为

阈值
在决策树的生成中,我们就有提到阈值,其由 ϵ \epsilon ϵ限制
我们可以计算 D D D下各个特征的信息增益

如果我们设定 ϵ = 0.4 \epsilon =0.4 ϵ=0.4,显然在确定根节点的时候,没有任何一个特征符合要求,因此返回单结点树,又因为 D D D上坏瓜数量多于好瓜,因此唯一叶结点为坏瓜
基于测试集上的误差率
测试集上的误差率:测试集中错误分类的实例占比
测试集上的准确率:测试集中正确分类的实例占比

先构建单结点树,由于训练集中好瓜有5个,坏瓜有5个,我们认为单结点树类标记为好瓜。对于测试集,好瓜有3个,坏瓜有4个,因此可计算误差率 P = 4 7 \begin{aligned} P=\frac{4}{7}\end{aligned} P=74
再构建深度为1的树,计算最大信息增益,可得脐部为最大值,因此脐部作为根节点


与测试集对照,求得误差率 P = 2 7 \begin{aligned} P=\frac{2}{7}\end{aligned} P=72
显然误差率小于单结点树,因此保留该结点
再构建深度为2的树
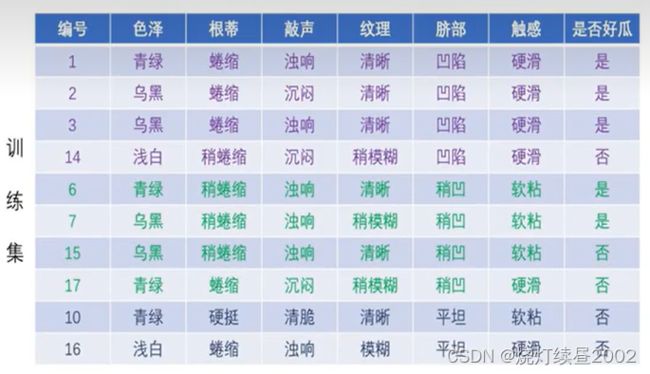
计算脐部凹陷的情况下最大信息增益,可得色泽为最大值,计算误差率 P = 3 7 \begin{aligned} P=\frac{3}{7}\end{aligned} P=73,因此不保留该结点
计算脐部稍凹的情况下最大信息增益,可得根蒂为最大值,计算误差率 P = 2 7 \begin{aligned} P=\frac{2}{7}\end{aligned} P=72,根据奥卡姆剃刀原理(模型越简单越好),因此不保留该结点
在脐部为平坦的情况下,全为坏瓜,根据ID3算法要求,因此该结点即为叶结点,标记为坏瓜
后剪枝
降低错误剪枝(REP)
原理:自下而上,使用测试集来剪枝。对每个结点,计算剪枝前和剪枝后的误判个数,若是剪枝有利于减少误判(包括相等的情况),则剪掉该结点所在分枝
有点类似于预剪枝中的基于测试集上的误差率剪枝
该方法受测试集影响大,如果测试集比训练集小很多,会限制分类的精度。
例:

根据ID3算法,可得决策树

该决策树深度为4,现在我们尝试剪枝深度为3。从测试集中找到脐部为稍凹,根蒂为稍卷曲,色泽为乌黑的样本,编号8、9符合要求。与训练集所得决策树相比较,可得误判个数为2。
剪掉纹理所在的枝条,根据训练集数据,对应样本(脐部为稍凹,根蒂为稍卷曲,色泽为乌黑),编号为7、15,好瓜数量为1,坏瓜数量为1,因此我们令该叶结点(脐部为稍凹,根蒂为稍卷曲,色泽为乌黑)为好瓜,可得新的决策树

在新的决策树下该结点(脐部为稍凹,根蒂为稍卷曲,色泽为乌黑)误判个数为1,因此符合剪枝要求,进行剪枝
按照此方法不断递归剪枝,最终可得符合条件的决策树

显然该决策树是由欠拟合倾向的
悲观错误剪枝(PEP)
原理:根据剪枝前后的错误率来决定是否剪枝。
和REP不同之处在于,PEP只需要训练集即可,不需要验证集,并且PEP是自上而下剪枝的
优点:不需要分离剪枝数据集,有利于实例较小的问题;误差使用了连续修正值,使得适用性更强;由于自上而下的剪枝策略,PEP效率更高
但仍然有可能会剪掉不应剪掉的枝条
步骤:
剪枝前
-
计算剪枝前目标子树每个叶结点的误差,并进行连续修正
E r r o r ( L e a f i ) = e r r o r ( L e a f i ) + 0.5 N ( T ) Error(Leaf_{i})=\frac{error(Leaf_{i})+0.5}{N(T)} Error(Leafi)=N(T)error(Leafi)+0.5其中 i i i表示每个叶结点; e r r o r i ( L e a f i ) error_{i}(Leaf_{i}) errori(Leafi)表示叶结点 L e a f i Leaf_{i} Leafi处误判的样本个数; N ( T ) N(T) N(T)表示的是总样本个数,剪谁,总样本就对应谁,不一定是整个 D D D上的所有样本
加0.5是为了连续型修正作者:Dr_Janneil
链接:从二项分布到正态分布的连续性修正 (qq.com)这里阐述不是很准确,建议结合例题看
-
计算剪枝前目标子树的修正误差
E r r o r ( T ) = ∑ i = 1 L E r r o r ( L e a f i ) = ∑ i = 1 L e r r o r ( L e a f i ) + 0.5 × L N ( T ) Error(T)=\sum\limits_{i=1}^{L}Error(Leaf_{i})=\frac{\sum\limits_{i=1}^{L}error(Leaf_{i})+0.5 \times L}{N(T)} Error(T)=i=1∑LError(Leafi)=N(T)i=1∑Lerror(Leafi)+0.5×LL L L表示叶结点个数
-
计算剪枝前目标子树误差个数的期望
E ( T ) = N ( T ) × E r r o r ( T ) = ∑ i = 1 L e r r o r ( L e a f i ) + 0.5 × L E(T)=N(T)\times Error(T)=\sum\limits_{i=1}^{L}error(Leaf_{i})+0.5\times L E(T)=N(T)×Error(T)=i=1∑Lerror(Leafi)+0.5×L -
计算剪枝前目标子树误判个数的标准差
s t d ( T ) = N ( T ) × E r r o r ( T ) × ( 1 − E r r o r ( T ) ) std(T)=\sqrt{N(T)\times Error(T)\times (1-Error(T))} std(T)=N(T)×Error(T)×(1−Error(T))根据我们现在已经得到的叶结点误差数据,如果要们要预测整个子树的误差数量,则可以由已知的数据构造二项分布,即
T ∼ B ( n p , n p ( 1 − p ) ) T \sim B(np,np(1-p)) T∼B(np,np(1−p))
其中 p = E r r o r ( T ) , n = N ( T ) p=Error(T),n=N(T) p=Error(T),n=N(T) -
计算剪枝前误判上限(即悲观误差)
E ( T ) + s t d ( T ) E(T)+std(T) E(T)+std(T)
这里的悲观误差是从期望上限来考虑的,那么我们这里只加了1个标准差
剪枝后
- 计算剪枝后该结点的修正误差
E r r o r ( L e a f ) = e r r o r ( L e a f ) + 0.5 N ( T ) Error(Leaf)=\frac{error(Leaf)+0.5}{N(T)} Error(Leaf)=N(T)error(Leaf)+0.5 - 计算剪枝后该结点误判个数的期望值
E ( l e a f ) = e r r o r ( L e a f ) + 0.5 E(leaf)=error(Leaf)+0.5 E(leaf)=error(Leaf)+0.5 - 比较剪枝前后的误判个数,如果满足以下不等式,则剪枝;否则,不剪枝
E ( L e a f ) < E ( T ) + s t d ( T ) E(Leaf)
例:用PEP判断是否要剪枝

E r r o r ( T ) = 6 + 0.5 × 3 30 = 7.5 30 E ( T ) = 7.5 s t d ( T ) = 30 × 7.5 30 × ( 1 − 7.5 30 ) = 2.37 E r r o r ( L e a f ) = 13 + 0.5 30 = 13.5 30 E ( L e a f ) = 13.5 9.87 < 13.5 \begin{aligned} Error(T)&=\frac{6+0.5 \times 3}{30}= \frac{7.5}{30}\\ E(T)&=7.5\\ std(T)&=\sqrt{30 \times \frac{7.5}{30}\times (1- \frac{7.5}{30})}=2.37\\ Error(Leaf)&=\frac{13+0.5}{30}=\frac{13.5}{30}\\ E(Leaf)&=13.5\\ 9.87&<13.5 \end{aligned} Error(T)E(T)std(T)Error(Leaf)E(Leaf)9.87=306+0.5×3=307.5=7.5=30×307.5×(1−307.5)=2.37=3013+0.5=3013.5=13.5<13.5
不剪枝
最小误差剪枝(MEP)
原理:根据剪枝前后的最小分类错误概率例决定是否剪枝。自下而上剪枝,只需要训练集即可
在节点 T T T处,计算出属于类别 k k k的概率
P k ( T ) = n k ( T ) + P r k ( T ) × m N ( T ) + m P_{k}(T)=\frac{n_{k}(T)+Pr_{k}(T)\times m}{N(T)+m} Pk(T)=N(T)+mnk(T)+Prk(T)×m
其中 N ( T ) N(T) N(T)为该节点处总样本个数; n k ( T ) n_{k}(T) nk(T)为结点下属于类别 k k k的样本个数; P r k ( T ) Pr_{k}(T) Prk(T)为类别 k k k的先验; m m m是先验概率对后验概率的影响
如果 m → 0 , P k ( T ) → n k ( T ) N ( T ) \begin{aligned} m \to 0,P_{k}(T)\to \frac{n_{k}(T)}{N(T)}\end{aligned} m→0,Pk(T)→N(T)nk(T),意味着以后验概率为准
如果 m → ∞ , P k ( T ) → P r k ( T ) \begin{aligned} m \to \infty,P_{k}(T)\to Pr_{k}(T)\end{aligned} m→∞,Pk(T)→Prk(T),意味着以先验概率为准
在节点 T T T处,计算出预测出错率
E r r o r ( T ) = min { 1 − P k ( T ) } Error(T)=\min \left\{1-P_{k}(T)\right\} Error(T)=min{1−Pk(T)}
如果我们将节点 T T T记为类别 k k k,那么上式意味着不属于类别 k k k的概率,代入 P k ( T ) P_{k}(T) Pk(T)
E r r o r ( T ) = min { N ( T ) − n k ( T ) + m ( 1 − P r k ( T ) ) N ( T ) + m } Error(T)=\min \left\{\frac{N(T)-n_{k}(T)+m(1-Pr_{k}(T))}{N(T)+m}\right\} Error(T)=min{N(T)+mN(T)−nk(T)+m(1−Prk(T))}
如果先验概率是确定的(一般,在无任何假设的情况下,我们通常假设各类别是等概率出现的,因此,先验概率为 P r k ( T ) = 1 K \begin{aligned} Pr_{k}(T)=\frac{1}{K}\end{aligned} Prk(T)=K1),那么该式就是以 m m m作为变量的函数,我们可以通过计算
argmin m E r r o r ( T ) \mathop{\text{argmin}\space}\limits_{m}Error(T) margmin Error(T)
来得到 m m m。在这里为了演示MEP算法,假设 m = K m=K m=K, K K K为类别的总个数,因此预测错误率可以写作
E r r o r ( T ) = N ( T ) − n k ( T ) + K − 1 N ( T ) + K Error(T)=\frac{N(T)-n_{k}(T)+K-1}{N(T)+K} Error(T)=N(T)+KN(T)−nk(T)+K−1
步骤
- 计算剪枝前目标子树每个叶结点的预测错误率
E r r o r ( L e a f i ) = N ( L e a f i ) − n k ( L e a f i ) + K − 1 N ( L e a f i ) + K Error(Leaf_{i})=\frac{N(Leaf_{i})-n_{k}(Leaf_{i})+K-1}{N(Leaf_{i})+K} Error(Leafi)=N(Leafi)+KN(Leafi)−nk(Leafi)+K−1
N ( L e a f i ) N(Leaf_{i}) N(Leafi)代表叶结点处样本的总个数, n k ( L e a f i ) n_{k}(Leaf_{i}) nk(Leafi)代表叶结点下属于 k k k类的样本个数 - 计算剪枝前目标子树的预测错误率
假设目标子树中一共有 L L L个叶结点
E r r o r ( L e a f ) = ∑ i = 1 L ω i E r r o r ( L e a f i ) = ∑ i = 1 L N ( L e a f i ) N ( T ) E r r o r ( L e a f i ) Error(Leaf)=\sum\limits_{i=1}^{L}\omega_{i}Error(Leaf_{i})=\sum\limits_{i=1}^{L}\frac{N(Leaf_{i})}{N(T)}Error(Leaf_{i}) Error(Leaf)=i=1∑LωiError(Leafi)=i=1∑LN(T)N(Leafi)Error(Leafi)
这里 ω i = N ( L e a f i ) N ( T ) \begin{aligned} \omega_{i}=\frac{N(Leaf_{i})}{N(T)}\end{aligned} ωi=N(T)N(Leafi)指每个叶子结点对应目标子树的权重 - 计算剪枝后目标子树的预测错误率
E r r o r ( T ) = N ( T ) − n k ( T ) + K − 1 N ( T ) + K Error(T)=\frac{N(T)-n_{k}(T)+K-1}{N(T)+K} Error(T)=N(T)+KN(T)−nk(T)+K−1 - 比较剪枝前后的预测错误率,如果满足以下不等式,则剪枝;否则,不剪枝
E r r o r ( T ) < E r r o r ( L e a f ) Error(T)
例:通过MEP判断T4-T5是否可以剪枝

计算剪枝前目标子树每个叶结点的预测错误率
E r r o r ( T 7 ) = N ( T 7 ) − n 7 ( T 7 ) + K − 1 N ( T 7 ) + K = 11 − 9 + 2 − 1 11 + 2 = 3 13 E r r o r ( T 8 ) = N ( T 8 ) − n 8 ( T 8 ) + K − 1 N ( T 8 ) + K = 9 − 8 + 2 − 1 9 + 2 = 2 11 \begin{aligned} Error(T7)&=\frac{N(T7)-n_{7}(T7)+K-1}{N(T7)+K}=\frac{11-9+2-1}{11+2}=\frac{3}{13}\\ Error(T8)&=\frac{N(T8)-n_{8}(T8)+K-1}{N(T8)+K}=\frac{9-8+2-1}{9+2}=\frac{2}{11} \end{aligned} Error(T7)Error(T8)=N(T7)+KN(T7)−n7(T7)+K−1=11+211−9+2−1=133=N(T8)+KN(T8)−n8(T8)+K−1=9+29−8+2−1=112
计算剪枝前目标子树的预测错误率
E r r o r ( L e a f ) = ω 7 E r r o r ( T 7 ) + ω 8 E r r o r ( T 8 ) = 11 20 × 3 13 + 9 20 × 2 11 = 0.2087 \begin{aligned} Error(Leaf)&=\omega_{7}Error(T7)+\omega_{8}Error(T8)\\ &=\frac{11}{20}\times \frac{3}{13}+ \frac{9}{20}\times \frac{2}{11}\\ &=0.2087 \end{aligned} Error(Leaf)=ω7Error(T7)+ω8Error(T8)=2011×133+209×112=0.2087
计算剪枝后目标子树的预测错误率
E r r o r ( T 5 ) = N ( T 5 ) − n 5 ( T 5 ) + K − 1 N ( T 5 ) + K = 20 − 10 + 2 − 1 20 + 2 = 11 22 = 0.5 Error(T5)=\frac{N(T5)-n_{5}(T5)+K-1}{N(T5)+K}=\frac{20-10+2-1}{20+2}=\frac{11}{22}=0.5 Error(T5)=N(T5)+KN(T5)−n5(T5)+K−1=20+220−10+2−1=2211=0.5
显然 0.2087 < 0.5 0.2087<0.5 0.2087<0.5,因此不能剪枝
基于错误剪枝(EBP)
原理:根据剪枝前后的误判个数来决定是否剪枝。自下而上剪枝,只需要训练集即可
计算置信水平 α \alpha α下每个结点的误判上界
U α ( e ( T ) , N ( T ) ) = e ( T ) + 0.5 + q α 2 2 + q α ( e ( T ) + 0.5 ) ( N ( T ) − e ( T ) − 0.5 ) N ( T ) + q α 2 4 N ( T ) + q α 2 U_{\alpha}(e(T),N(T))=\frac{e(T)+0.5+ \frac{q_{\alpha}^{2}}{2}+ q_{\alpha}\sqrt{\frac{(e(T)+0.5)(N(T)-e(T)-0.5)}{N(T)}+ \frac{q_{\alpha}^{2}}{4}}}{N(T)+ q_{\alpha}^{2}} Uα(e(T),N(T))=N(T)+qα2e(T)+0.5+2qα2+qαN(T)(e(T)+0.5)(N(T)−e(T)−0.5)+4qα2
其中
E r r o r ( T ) = e ( T ) + 0.5 N ( T ) \begin{aligned} Error(T)= \frac{e(T)+0.5}{N(T)}\end{aligned} Error(T)=N(T)e(T)+0.5,也就是误判率, e ( T ) e(T) e(T)代表样本的误判个数, N ( T ) N(T) N(T)代表样本总个数, 0.5 0.5 0.5为连续型修正
U α ( e ( T ) , N ( T ) ) U_{\alpha}(e(T),N(T)) Uα(e(T),N(T))表示在置信水平为 α \alpha α下的误差率上界
( e ( T ) + 0.5 ) ( N ( T ) − e ( T ) − 0.5 ) N ( T ) = N ( T ) ⋅ e ( T ) + 0.5 N ( T ) ⋅ N ( T ) − e ( T ) − 0.5 N ( T ) \begin{aligned} \frac{(e(T)+0.5)(N(T)-e(T)-0.5)}{N(T)}=N(T)\cdot \frac{e(T)+0.5}{N(T)}\cdot \frac{N(T)-e(T)-0.5}{N(T)}\end{aligned} N(T)(e(T)+0.5)(N(T)−e(T)−0.5)=N(T)⋅N(T)e(T)+0.5⋅N(T)N(T)−e(T)−0.5表示二项分布里的方差,即 n p ( 1 − p ) np(1-p) np(1−p), p p p为误判率
q α 2 2 \begin{aligned} \frac{q_{\alpha}^{2}}{2}\end{aligned} 2qα2就是对方差的修正
q α q_{\alpha} qα代表标准正态分布的上分位数,一般的上分位数我们可以通过查标准正态分布表得到。特殊的值我们可以找到周围的两个点,然后通过构建过已知两点的直线在估计中间的值。在该算法中(C4.5), q α q_{\alpha} qα取 0.6925 0.6925 0.6925,对应 α = 0.75 \alpha=0.75 α=0.75
q α q_{\alpha} qα可能描述不对,但值是对的
步骤:
- 计算剪枝前目标子树每个叶子结点的误判率上界
U C F ( e ( L e a f i ) , N ( L e a f i ) ) = e ( L e a f i ) + 0.5 + q α 2 2 + q α ( e ( L e a f i ) + 0.5 ) ( N ( L e a f i ) − e ( L e a f i ) − 0.5 ) N ( L e a f i ) + q α 2 4 N ( L e a f i ) + q α 2 U_{CF}(e(Leaf_{i}),N(Leaf_{i}))=\frac{e(Leaf_{i})+0.5+ \frac{q_{\alpha}^{2}}{2}+ q_{\alpha}\sqrt{\frac{(e(Leaf_{i})+0.5)(N(Leaf_{i})-e(Leaf_{i})-0.5)}{N(Leaf_{i})}+ \frac{q_{\alpha}^{2}}{4}}}{N(Leaf_{i})+ q_{\alpha}^{2}} UCF(e(Leafi),N(Leafi))=N(Leafi)+qα2e(Leafi)+0.5+2qα2+qαN(Leafi)(e(Leafi)+0.5)(N(Leafi)−e(Leafi)−0.5)+4qα2
设 L L L代表子树上有 L L L个叶结点,因此我们就要算 L L L个误判率上界 - 计算剪枝前目标子树的误判个数上界
E ( L e a f ) = ∑ i = 1 L N ( L e a f i ) U C F ( e ( L e a f i ) , N ( L e a f i ) ) E(Leaf)=\sum\limits_{i=1}^{L}N(Leaf_{i})U_{CF}(e(Leaf_{i}),N(Leaf_{i})) E(Leaf)=i=1∑LN(Leafi)UCF(e(Leafi),N(Leafi))
这一步骤就是将每个叶子结点的个数乘以对应的误判率上界后求和,就得出了这棵子树上的误判个数上界。 - 计算剪枝后目标子树的误判率上界
U C F ( e ( T ) , N ( T ) ) = e ( T ) + 0.5 + q α 2 2 + q α ( e ( T ) + 0.5 ) ( N ( T ) − e ( T ) − 0.5 ) N ( T ) + q α 2 4 N ( T ) + q α 2 U_{CF}(e(T),N(T))=\frac{e(T)+0.5+ \frac{q_{\alpha}^{2}}{2}+ q_{\alpha}\sqrt{\frac{(e(T)+0.5)(N(T)-e(T)-0.5)}{N(T)}+ \frac{q_{\alpha}^{2}}{4}}}{N(T)+ q_{\alpha}^{2}} UCF(e(T),N(T))=N(T)+qα2e(T)+0.5+2qα2+qαN(T)(e(T)+0.5)(N(T)−e(T)−0.5)+4qα2 - 计算剪枝后目标子树的误判个数上界
E ( T ) = N ( T ) U C F ( e ( T ) , N ( T ) ) E(T)=N(T)U_{CF}(e(T),N(T)) E(T)=N(T)UCF(e(T),N(T))
只需要计算将目标子树替换成叶子结点后的误判率上界。 - 比较剪枝前后的误判个数上界,如果满足以下不等式,则剪枝;否则,不剪枝。
E ( T ) < E ( L e a f ) E(T)
例:通过EBP判断 T T T是否可以剪枝

计算剪枝前目标子树每个叶子结点的误判率上界
U C F ( 0 , 6 ) = e ( L e a f i ) + 0.5 + q α 2 2 + q α ( e ( L e a f i ) + 0.5 ) ( N ( L e a f i ) − e ( L e a f i ) − 0.5 ) N ( L e a f i ) + q α 2 4 N ( L e a f i ) + q α 2 = 0 + 0.5 + 0.692 5 2 2 + 0.6925 ( 0 + 0.5 ) ( 6 − 0 − 0.5 ) 6 + 0.692 5 2 4 6 + 0.692 5 2 = 0.206 U C F ( 0 , 9 ) = 0.143 U C F ( 0 , 1 ) = 0.75 \begin{aligned} U_{CF}(0,6)&=\frac{e(Leaf_{i})+0.5+ \frac{q_{\alpha}^{2}}{2}+ q_{\alpha}\sqrt{\frac{(e(Leaf_{i})+0.5)(N(Leaf_{i})-e(Leaf_{i})-0.5)}{N(Leaf_{i})}+ \frac{q_{\alpha}^{2}}{4}}}{N(Leaf_{i})+ q_{\alpha}^{2}}\\ &=\frac{0+0.5+ \frac{0.6925^{2}}{2}+0.6925\sqrt{\frac{(0+0.5)(6-0-0.5)}{6}+ \frac{0.6925^{2}}{4}}}{6+0.6925^{2}}\\ &=0.206\\ U_{CF}(0,9)&=0.143\\ U_{CF}(0,1)&=0.75 \end{aligned} UCF(0,6)UCF(0,9)UCF(0,1)=N(Leafi)+qα2e(Leafi)+0.5+2qα2+qαN(Leafi)(e(Leafi)+0.5)(N(Leafi)−e(Leafi)−0.5)+4qα2=6+0.692520+0.5+20.69252+0.69256(0+0.5)(6−0−0.5)+40.69252=0.206=0.143=0.75
计算剪枝前目标子树的误判个数上界
E ( L e a f ) = ∑ i = 1 L N ( L e a f i ) U C F ( e ( L e a f i ) , N ( L e a f i ) ) = 6 × 0.206 + 9 × 0.143 + 1 × 0.75 = 3.273 \begin{aligned} E(Leaf)&=\sum\limits_{i=1}^{L}N(Leaf_{i})U_{CF}(e(Leaf_{i}),N(Leaf_{i}))\\ &=6 \times 0.206+9\times 0.143+1\times 0.75\\ &=3.273 \end{aligned} E(Leaf)=i=1∑LN(Leafi)UCF(e(Leafi),N(Leafi))=6×0.206+9×0.143+1×0.75=3.273
计算剪枝后目标子树的误判率上界
U C F ( 1 , 16 ) = 0.157 U_{CF}(1,16)=0.157 UCF(1,16)=0.157
计算剪枝后目标子树的误判个数上界
E ( T ) = N ( T ) U C F ( e ( T ) , N ( T ) ) = 16 × 0.157 = 2.512 E(T)=N(T)U_{CF}(e(T),N(T))=16 \times 0.157=2.512 E(T)=N(T)UCF(e(T),N(T))=16×0.157=2.512
比较剪枝前后的误判个数上界,如果满足以下不等式,则剪枝;否则,不剪枝
E ( T ) = 2.512 < 3.273 = E ( L e a f ) E(T)=2.512<3.273=E(Leaf) E(T)=2.512<3.273=E(Leaf)
因此可以剪枝
CSDN话题挑战赛第2期
参赛话题:学习笔记