【目标检测】44、YOLOv2 | 更快 更好 更强的 YOLO 结构

文章目录
-
- 一、 背景
- 二、方法
-
- 2.1 Better
- 2.2 Faster
- 2.3 Stronger
- 三、 总结
论文:Yolo9000: Better, faster, stronger
代码:https://github.com/pjreddie/darknet
出处:CVPR2017
作者:Joseph Redmon
时间:2016.12
一、 背景
YOLOv2 是基础结构,YOLO9000 通过联合分类和检测数据集可以检测 9000 个类别的目标而称为 YOLO9000。
相比 YOLOv1 有以下两种改进:
-
作者认为,目前分类的数据集数据量很大,但检测数据集数量量相对小一些,所以作者提出了联合训练分类和检测数据集。使用检测数据集来保证定位的准确性,使用分类数据集来提升模型的词汇量和鲁棒性。
-
作者使用了一系列的方法对原来的YOLO多目标检测框架进行了改进,在保持原有速度的优势之下,精度上得以提升。
本文方法中用到了 kmeans 聚类,这里先介绍一下该聚类方法:K-means 的算法步骤为:
- 随机选择 k 个样本作为初始聚类中心(这里的 k 是提前设定的聚类的类型数量)
- 针对数据集中每个样本,计算它到 k 个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中(距离可以使用欧式距离等来衡量)
- 对每个聚类后的簇,重新计算该簇的聚类中心(即属于该类的所有样本的质心)
- 重复上面 2 和 3,直到达到某个中止条件(迭代次数、最小误差变化等)
kmeans 的优点:
- 容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;
- 处理大数据集的时候,该算法可以保证较好的伸缩性;
- 当簇近似高斯分布的时候,效果非常不错;
- 算法复杂度低。
kmeans 的缺点:
- K 值需要人为设定,不同 K 值得到的结果不一样;
- 对初始的簇中心敏感,不同选取方式会得到不同结果;
- 对异常值敏感;
- 样本只能归为一类,不适合多分类任务;
- 不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。
二、方法
YOLOv1 有很多不足,其中最主要的两点在于:
- 定位不准
- Recall 低
所以 YOLOv2 也主要在提高这两个问题上下功夫。但 YOLOv2 没有提高模型大小,同时速度更快了,主要从以下方面来让网络效果更好
2.1 Better
YOLOv1 和 YOLOv2 输出的变化:
- YOLO v1 总输出为 7x7x(5x2+20):在特征图 (7x7) 的每一个 grid 中预测出两个 bounding box 及分类概率值,每个 bounding box 预测 5 个值
- YOLO v2 总输出为 13x13x5x(5+20):在特征图 (13x13) 的每一个 grid 中预测 5 个 bounding box (对应 5 个 Anchor Box),每个 bound box 预测 5 个值以及分类概率值
1、Batch Normalization:在 YOLOv1 的所有卷积层后面加 BN,提升了 2mAP
2、High Resolution Classififier:
- 很多 SOTA 方法在 ImageNet 上训练时,都是使用 256x256 的大小,YOLOv1 使用 224x224 大小,YOLOv2 提升到了 448x448 大小,能够让网络学习更适用于检测的特征,YOLOv2 在 ImageNet 上使用 448x448 训练 10 epochs,能帮助网络在大分辨率输入上更好提取特征,带来 4mAP 的提升
3、Convolutional with Anchor Boxes:YOLOv1 直接使用 fc 网络预测框的位置坐标,而非像 Faster RCNN 一样预测的是框和预选框的偏移,偏移学习比直接学习位置坐标更简单。
- 所以 YOLOv2 移除了 fc 层,使用了 anchor 来预测框。输入图像大小 416x416(为了保证奇数大小特征图),下采样 32 倍,得到 13x13 大小特征图
- 提出了 objectness,预测每个 anchor 和 gt 的 IoU,和该 anchor 是目标的概率
- 使用 anchor,每张图上能预测的目标从 98 变成了 1k 多,无 anchor 时 mAP=69.5,recall=81%,有 anchor 后,mAP=69.2,recall=88%。提升了 recall 后,表示模型有了更大的提升空间。
4、Dimension Clusters:
- 在使用 anchor 时,anchor 的纵横比和尺度需要手动选择,所以如果选择得当,则效果好,如果选择失当,则效果差。
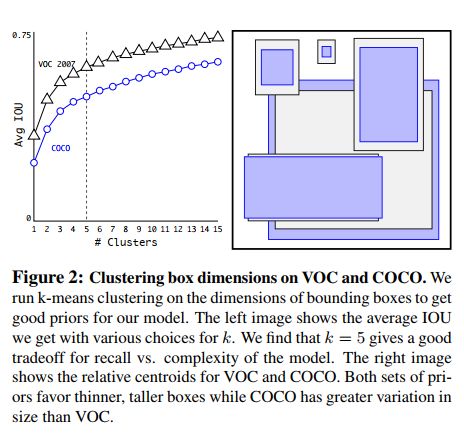
- YOLOv2 为了避免手工选择带来的误差,在训练集上使用了 k-means 来自动选择最优的值。由于欧氏距离对尺寸很敏感,所以作者使用 d ( b o x , c e n t r o i d ) = 1 − I o U ( b o x , c e n t r o i d ) d(box, centroid) = 1-IoU(box, centroid) d(box,centroid)=1−IoU(box,centroid) 的方式来度量距离。如图 2 所示,最终使用 k=5 来平衡模型复杂度和 recall。使用这种在形心聚类的方法和手工选择不同,聚类的方法选择了更多的高瘦框,更少的矮胖框。如表 1 所示,只有 5 种形心的聚类方法得到的框的效果和 9 种 anchor box 效果类似。使用 9 种形心的聚类方法能够得到更高的 IoU。
论文中说,如果一开始就选择了合适的 anchors,那么网络就更容易去学习如何进行好的预测。
这里是如何使用 kmeans 来实现 anchor 生成的呢?
- 首先,来看看 YOLOv2 中认定好的 anchor 的标准是什么?通过计算所有 gt 和其负责的最大 IoU 的均值 Avg IoU 作为指标,值越大代表得到的越好。
- 其次,如何判定某个 gt 和该类 gt 中心的距离呢,肯定不能使用欧式距离,这样会对尺度很敏感,这里使用的是 1-IoU(box, centroid),这里 centroid 就是该类 gt 的质心,如果某个 gt 和质心的 IoU 越大,则(1-IoU)结果越小,这里的“距离”越小。
YOLOv2 中使用 kmeans 聚类方法,是为了得到合适的 anchor 初始化参数(纵横比、尺度等),所以,这里要聚类的也就是 gt 框的 w、h,过程如下:
- 随机选择 k 个 bbox 作为质心
- 计算其他所有 bbox 和这 k 个质心的 距离(1-IoU)值
- 将这些 bbox 分配到距离最近的质心上去,然后重新计算每个簇 bbox 的质心,默认使用中值
- 重复上面的第三步操作,直到每个簇中的框不再发生变化

5、Direct location prediction
- 在使用 anchor 后,会遇到的第二个问题是:模型不稳定,尤其是在训练早期
- 不稳定性很大程度来源于对 box 的预测框位置 ( x , y ) (x, y) (x,y),在 RPN 网络中,网络预测 t x t_x tx 和 t y t_y ty,则其中心点可以计算如下,当 t x = 1 t_x=1 tx=1 时,box 将被右移框的宽度大小, t x = − 1 t_x=-1 tx=−1 则会左移框的宽度大小:

- 这种形式是不受约束的,所以任意 anchor 会在图中的任何位置结束,所以需要很长的时间来稳定
- 故此,YOLOv2 仍然预测相对于网格的相对位置,这会限制到 0~1 之间,使用 logistic 激活函数来限制网络的预测落入这个范围。
- 网络在输出特征图中的每个网格中预测 5 个 bbox,每个 bbox 分别预测 ( t x , t y , t w , t h , t o ) (t_x, t_y, t_w, t_h, t_o) (tx,ty,tw,th,to),如果某个网格距离图像坐上角点距离为 ( c x , c y ) (c_x, c_y) (cx,cy),bbox 的宽高分别为 p w p_w pw 和 p h p_h ph,则预测的位置为:

- 由于限制的位置参数的大小,所以有助于网络快速稳定,提升了约 5% 的速度
6、Fine-Grained Features
- YOLOv2 在 13x13 的特征图上预测,但得益于大特征图的预训练,这样的大小也也足够大目标的预测了。参考 SSD 和 Faster RCNN,都是在多分辨率特征图上预测不同尺度的目标的,所以作者在 26x26 大小的特征图上也引出了分支,得到了 1% 的性能提升。
7、Multi-scale Training
- YOLOv1 中使用大小为 448x448 的输入,YOLOv2 中由于要添加 anchor,所以改成了 416x416,但为了对不同大小的目标更加鲁棒,所以 YOLOv2 使用了多尺度训练。
- 多尺度训练的模式:在每 10 个 epoch 随机选择训练的尺度,由于最后下采样 32 倍,所以作者选择了 32 的倍数:{320, 352, …, 608},最小的为 320, 最大的为 608。
- 这种机制迫使网络学习跨各种输入维度进行良好的预测。这意味着同一个网络可以在不同的分辨率下预测检测结果。网络在较小的尺寸下运行速度更快,因此 YOLOv2 可以轻松地在速度和精度之间进行权衡。
- 在低分辨率时,YOLOv2 是一种耗费小而相当精确的检测器,288x288 大小时,可以达到 90 FPS,且 mAP 和 Fast RCNN 类似。
- 在高分辨率时,YOLOv2 在 VOC2007 上达到了 SOTA的 78.6 mAP,且接近实时速度。



2.2 Faster
为了实现又准又快的检测,来支撑如自动驾驶的任务,在耗时小的情况下保持很好的效果。所以 YOLOv2 需要提升速度。
YOLOv1 基于 GoogLeNet,比 VGG-16 快,但准确率低。
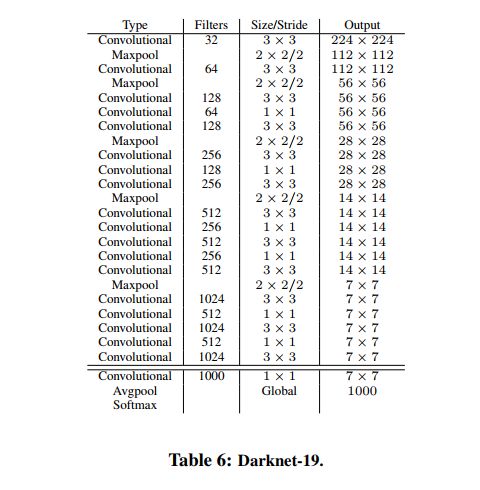
1、DarkNet19
YOLOv2 中提出了一个新的分类模型,Darknet-19,共 19 层卷积层,5 层 maxpooling,结构见表 6。
2、Training for classification
训练 ImageNet-1000 共 160 epochs,使用 SGD,训练时使用标准数据增强(crop、rotation、hue、saturation、exposure shifts等)。
先使用 224x224 训练,然后使用 448x448 微调,微调共使用 10 个epochs。
3、Training for detection
检测网络,作者移除了最后一个卷积层,使用 3 个 3x3 conv (1024 个通道)+ 1 个 1x1 conv(通道和类别相关,对于 VOC,5 bbox * 5 coordinates + 5 bbox * 20 cls = 125)。
2.3 Stronger
为了让网络见识更多的类别,增加鲁棒性, YOLOv2 提出了对分类和检测联合训练:
- 使用检测数据学习 detection-specific 的特征,如 bbox 位置、objectness、如何对类似的目标进行分类等
- 使用分类数据来扩充网络的眼界,扩充能检测的类别
1、Dataset combination with WordTree
当我们要预测一只狗是不是柯基时, Pr(Corgi) 是一系列条件概率的乘积:
P r ( C o r g i ) = P r ( C o r g i ∣ d o g ) × P r ( d o g ∣ c a n i n e ) × . . . × P r ( l i v i n g t h i n g ∣ w h o l e ) × P r ( w h o l e ∣ o b j e c t ) × P r ( o b j e c t ) Pr(Corgi)=Pr(Corgi|dog)×Pr(dog|canine)×...×Pr(living thing|whole)×Pr(whole|object)×Pr(object) Pr(Corgi)=Pr(Corgi∣dog)×Pr(dog∣canine)×...×Pr(livingthing∣whole)×Pr(whole∣object)×Pr(object)
WordTree的类别数量非常大,基本可以囊括目前所有的检测数据集,只需要在WordTree中标明哪些节点是检测数据集上的即可,图7显示的是COCO数据集合并到WordTree的结果。其中蓝色节点表示COCO中可以检测的类别。


2、混合训练分类和检测
作者将 COCO 和 ImageNet 的 9000 子类进行联合,对应的 WordTree 共 9418 类,通过对 COCO 的过采样来实现和 ImageNet 的平衡,将COCO上采样到和ImageNet的比例为 1:4。
训练 YOLO9000:
- 每个锚点的输出不再是85个,而是 9418+5=9423 个;
- 基于基础 YOLOv2 的结构,为了减少每个cell的输出节点数,每个网格输出 3 个,而非 5 个框,但每个cell的输出也达到了 3×9423=28269 个
- 当运行分类任务时,要更新该节点和其所有父节点的权值,且不更新检测任务的权值,因为我们此时根本没有任何关于检测的信息;
- 锚点和Ground Truth的IoU大于0.3时便被判为正锚点,而YOLOv2的阈值是0.5。

三、 总结
YOLOv2 是当时 SOTA 的又快又好的方法,可以使用不同大小的输入图像,并达到效果和速度的平衡。
YOLO9000 是实时检测框架,通过使用 WordTree 来将不同源的数据联合起来,能够弥补不同数据集的 gap。