python + sklearn实现手写数字识别
一、数据集
训练用的数据集使用的是sklearn框架中内置的数字数据集, 共 1797条数据,每条数据由64个特征点组成
import numpy as np
from sklearn import datasets
digits = datasets.load_digits() # 加载数字样本
X = digits.data # 特征数据
y = digits.target # 标签
print(X.shape)
print(X[0])
print(np.array(X[0]).reshape(8, 8)) # 训练数据都是1d的,转成8x8的2d矩阵后,能看出数字的轮廓
print("第一条数据的标签是:", y[0])
结果如下:
(1797, 64)
[ 0. 0. 5. 13. 9. 1. 0. 0. 0. 0. 13. 15. 10. 15. 5. 0. 0. 3.
- 2. 0. 11. 8. 0. 0. 4. 12. 0. 0. 8. 8. 0. 0. 5. 8. 0.
- 9. 8. 0. 0. 4. 11. 0. 1. 12. 7. 0. 0. 2. 14. 5. 10. 12.
- 0. 0. 0. 6. 13. 10. 0. 0. 0.]
[[ 0. 0. 5. 13. 9. 1. 0. 0.]
[ 0. 0. 13. 15. 10. 15. 5. 0.]
[ 0. 3. 15. 2. 0. 11. 8. 0.]
[ 0. 4. 12. 0. 0. 8. 8. 0.]
[ 0. 5. 8. 0. 0. 9. 8. 0.]
[ 0. 4. 11. 0. 1. 12. 7. 0.]
[ 0. 2. 14. 5. 10. 12. 0. 0.]
[ 0. 0. 6. 13. 10. 0. 0. 0.]]
第一条数据的标签是: 0
二、分类器
可以使用框架中提供的基于SVM算法分类器SVC(或LinearSVC),也可以使用基于K-邻近算法的分类器KNN
- SVC分类器
import pickle
from sklearn import svm
def train_by_svc(name, x_train, y_train):
"""
基于SVM的SVC分类器
:param name: 训练好的分类器持久化存储到此名称的文件中
:param x_train: 训练数据
:param y_train: 预期结果
:return:
"""
classifier = svm.SVC(gamma=0.001) # 创捷支持向量机的SVC的分类器(训练集大于1万时不要使用)
# classifier = svm.LinearSVC(dual=False) # 创捷支持向量机的LinearSVC的分类器
# 训练过程
start = time.perf_counter()
classifier.fit(x_train, y_train)
print("训练完成, 耗时:%s" % (time.perf_counter() - start))
with open(name, 'wb') as f:
pickle.dump(classifier, f)
- KNN分类器
import pickle
from sklearn.neighbors import KNeighborsClassifier as KNN
def train_by_knn(name, x_train, y_train):
"""
基于k-邻近算法的KNN分类器
:param name: 训练好的分类器持久化存储到此名称的文件中
:param x_train: 训练数据
:param y_train: 预期结果
:return:
"""
classifier = KNN(n_neighbors=3, algorithm='auto')
# 训练过程
start = time.perf_counter()
classifier.fit(x_train, y_train)
print("训练完成, 耗时:%s" % (time.perf_counter() - start))
with open(name, 'wb') as f:
pickle.dump(classifier, f)
三、使用样本数据训练分类器
我们先将从框架中获取到的数据集,分成训练数据和测试数据两部分,使用框架提供的函数train_test_split 可以很容易完成数据的拆分
# 分隔训练和测试样本, test_size为用来进行测试的数据的占比,0.1即1797 * 0.1约等于180条
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=0.1)
开始训练分类器,我们这里训练SVC分类器,也可以使用函数train_by_knn训练KNN分类器
# 训练好的分类器持久化存储到文件“手写数字分类器.cfr”中
train_by_svc('手写数字分类器.cfr', X_train, Y_train)
训练完成, 耗时:0.05120200000000019
四、测试训练完的分类器,并输出报告
定义一个预测函数,用于从指定文件加载分类器,并返回预测结果
def predict(name, x_test):
"""
从指定文件加载分类器,对数据集进行测试,并返回预测结果
:param name: 分类器文件
:param x_test: 测试数据
:return:
"""
with open(name, 'rb') as f:
clsifier = pickle.load(f)
start = time.perf_counter()
predicted = clsifier.predict(x_test)
print("预测完成, 耗时:%s" % (time.perf_counter() - start))
return predicted
开始测试
pre = predict('手写数字分类器.cfr', X_test)
print("分类器结果如下:")
print(metrics.classification_report(Y_test, pre))
print(metrics.confusion_matrix(Y_test, pre))
预测完成, 耗时:0.01339659999999987
分类器结果如下:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 21
2 1.00 1.00 1.00 17
3 1.00 1.00 1.00 15
4 1.00 1.00 1.00 17
5 1.00 0.93 0.96 27
6 1.00 1.00 1.00 20
7 1.00 1.00 1.00 12
8 1.00 1.00 1.00 16
9 0.90 1.00 0.95 18
accuracy 0.99 180
macro avg 0.99 0.99 0.99 180
weighted avg 0.99 0.99 0.99 180
[[17 0 0 0 0 0 0 0 0 0]
[ 0 21 0 0 0 0 0 0 0 0]
[ 0 0 17 0 0 0 0 0 0 0]
[ 0 0 0 15 0 0 0 0 0 0]
[ 0 0 0 0 17 0 0 0 0 0]
[ 0 0 0 0 0 25 0 0 0 2]
[ 0 0 0 0 0 0 20 0 0 0]
[ 0 0 0 0 0 0 0 12 0 0]
[ 0 0 0 0 0 0 0 0 16 0]
[ 0 0 0 0 0 0 0 0 0 18]]
五、报告解读
classification_report
最左侧的一列是标签0-9, 第二列precision代表准确度,能够看到标签9准确度为0.9,可以理解为预测为9的结果中,有百分之10不是9
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 21
2 1.00 1.00 1.00 17
3 1.00 1.00 1.00 15
4 1.00 1.00 1.00 17
5 1.00 0.93 0.96 27
6 1.00 1.00 1.00 20
7 1.00 1.00 1.00 12
8 1.00 1.00 1.00 16
9 0.90 1.00 0.95 18
accuracy 0.99 180
macro avg 0.99 0.99 0.99 180
weighted avg 0.99 0.99 0.99 180
confusion_matrix(混淆矩阵)
这个矩阵中给我们展示真实值与预测值之间的数量关系,下边这个10x10的矩阵,
垂直代表真实值0-9, 水平代表预测值0-9
那么第6行第10列的数字2,代表:真实值是5, 但预测值是9的数量是2.
[[17 0 0 0 0 0 0 0 0 0]
[ 0 21 0 0 0 0 0 0 0 0]
[ 0 0 17 0 0 0 0 0 0 0]
[ 0 0 0 15 0 0 0 0 0 0]
[ 0 0 0 0 17 0 0 0 0 0]
[ 0 0 0 0 0 25 0 0 0 2]
[ 0 0 0 0 0 0 20 0 0 0]
[ 0 0 0 0 0 0 0 12 0 0]
[ 0 0 0 0 0 0 0 0 16 0]
[ 0 0 0 0 0 0 0 0 0 18]]
六、手动创建测试数据
通过测试报告分析,感觉分类器的准确度还可以,接下来我们在白纸手写几个数字,并处理成特征数据,验证下分类器的效果。
测试图片, 数字0:

处理成特征值, 使用opencv进行处理:
import cv2
import matplotlib.pyplot as plt
source = cv2.imread('test/0.jpg')
gray = cv2.cvtColor(source, cv2.COLOR_BGR2GRAY) # 转成灰度图
gray = cv2.GaussianBlur(gray, (51, 81), 0) # 这里我用高斯滤波器处理了一下
# 二值化,大于140的转为0, 其他的不变
binary = cv2.threshold(gray, 140, 255, cv2.THRESH_TOZERO_INV)[1]
# 将二值图压缩为8x8,因为我们训练的数据都是64个特征点,除10也是因为训练数据的特征点大小都在25以内
feature = cv2.resize(binary, (x, y)) / 10
plt.imshow(feature, cmap='gray') # 查看二值化并压缩为8x8后的效果
plt.show()
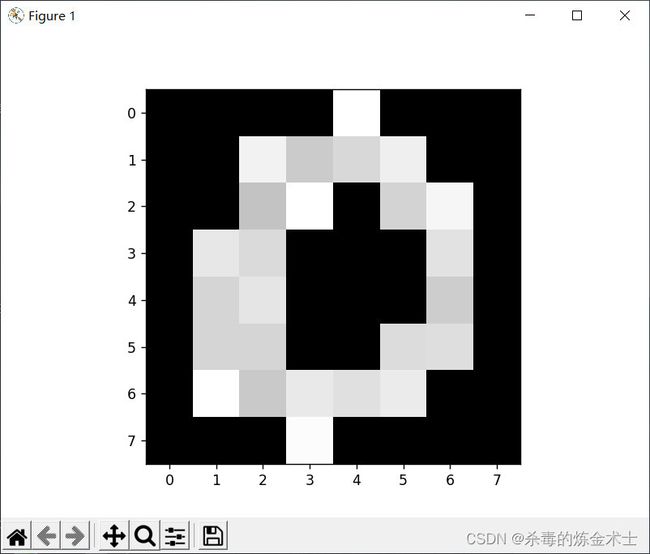
嗯~ o( ̄▽ ̄)o, 不错,确实是个0,然后转为1维的特征值
feature_1d = feature.flatten()
测试下,能不能识别出来
pre = predict('手写数字分类器.cfr', [feature_1d])
print("识别结果:", pre)
呦呵,还真识别出来了
预测完成, 耗时:0.00033789999999989107
识别结果: [0]