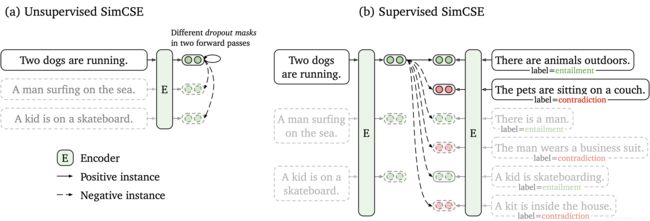
SimCSE nlp对比学习句向量相似语义
参考:
https://github.com/princeton-nlp/SimCSE
https://github.com/bojone/SimCSE/blob/main/utils.py
提前下载数据
Google官方的两个BERT模型:
BERT:chinese_L-12_H-768_A-12.zip
RoBERTa:chinese_roberta_wwm_ext_L-12_H-768_A-12.zip
关于语义相似度数据集,可以从数据集对应的链接自行下载,也可以从作者提供的百度云链接下载。
链接: https://pan.baidu.com/s/1d6jSiU1wHQAEMWJi7JJWCQ 提取码: qkt6
其中senteval_cn目录是评测数据集汇总,senteval_cn.zip是senteval目录的打包,两者下其一就好。
源代码下载:git clone https://github.com/bojone/SimCSE.git

训练(大概一个半小时)
#基本参数:
model_type, pooling, task_name, dropout_rate = “BERT”, “first-last-avg”, “ATEC”, 0.3
get_encoder函数在utils.py文件里定义的
#! -*- coding: utf-8 -*-
# SimCSE 中文测试
from utils import *
import sys
import tensorflow as tf
from bert4keras.optimizers import Adam
from bert4keras.snippets import DataGenerator, sequence_padding
import jieba
jieba.initialize()
# 基本参数
model_type, pooling, task_name, dropout_rate = "BERT", "first-last-avg", "ATEC", 0.3
# model_type, pooling, task_name, dropout_rate = sys.argv[1:]
assert model_type in [
'BERT', 'RoBERTa', 'NEZHA', 'WoBERT', 'RoFormer', 'BERT-large',
'RoBERTa-large', 'NEZHA-large', 'SimBERT', 'SimBERT-tiny', 'SimBERT-small'
]
assert pooling in ['first-last-avg', 'last-avg', 'cls', 'pooler']
assert task_name in ['ATEC', 'BQ', 'LCQMC', 'PAWSX', 'STS-B']
dropout_rate = float(dropout_rate)
if task_name == 'PAWSX':
maxlen = 128
else:
maxlen = 64
# 加载数据集
data_path = r"D:\simcse\senteval_cn\\"
datasets = {
'%s-%s' % (task_name, f):
load_data('%s%s/%s.%s.data' % (data_path, task_name, task_name, f))
for f in ['train', 'valid', 'test']
}
# bert配置
model_name = {
'BERT': 'chinese_L-12_H-768_A-12',
'RoBERTa': 'chinese_roberta_wwm_ext_L-12_H-768_A-12',
'WoBERT': 'chinese_wobert_plus_L-12_H-768_A-12',
'NEZHA': 'nezha_base_wwm',
'RoFormer': 'chinese_roformer_L-12_H-768_A-12',
'BERT-large': 'uer/mixed_corpus_bert_large_model',
'RoBERTa-large': 'chinese_roberta_wwm_large_ext_L-24_H-1024_A-16',
'NEZHA-large': 'nezha_large_wwm',
'SimBERT': 'chinese_simbert_L-12_H-768_A-12',
'SimBERT-tiny': 'chinese_simbert_L-4_H-312_A-12',
'SimBERT-small': 'chinese_simbert_L-6_H-384_A-12'
}[model_type]
config_path = r'D:\t**\simbert\%s\bert_config.json' % model_name
if model_type == 'NEZHA':
checkpoint_path = '/root/kg/bert/%s/model.ckpt-691689' % model_name
elif model_type == 'NEZHA-large':
checkpoint_path = '/root/kg/bert/%s/model.ckpt-346400' % model_name
else:
checkpoint_path = r'D:\t**\simbert\%s\bert_model.ckpt' % model_name
dict_path = r'D:\t**\simbert\%s\vocab.txt' % model_name
print(dict_path)
# 建立分词器
if model_type in ['WoBERT', 'RoFormer']:
tokenizer = get_tokenizer(
dict_path, pre_tokenize=lambda s: jieba.lcut(s, HMM=False)
)
else:
tokenizer = get_tokenizer(dict_path)
# 建立模型
if model_type == 'RoFormer':
encoder = get_encoder(
config_path,
checkpoint_path,
model='roformer',
pooling=pooling,
dropout_rate=dropout_rate
)
elif 'NEZHA' in model_type:
encoder = get_encoder(
config_path,
checkpoint_path,
model='nezha',
pooling=pooling,
dropout_rate=dropout_rate
)
else:
encoder = get_encoder(
config_path,
checkpoint_path,
pooling=pooling,
dropout_rate=dropout_rate
)
# 语料id化
all_names, all_weights, all_token_ids, all_labels = [], [], [], []
train_token_ids = []
for name, data in datasets.items():
a_token_ids, b_token_ids, labels = convert_to_ids(data, tokenizer, maxlen)
all_names.append(name)
all_weights.append(len(data))
all_token_ids.append((a_token_ids, b_token_ids))
all_labels.append(labels)
train_token_ids.extend(a_token_ids)
train_token_ids.extend(b_token_ids)
if task_name != 'PAWSX':
np.random.shuffle(train_token_ids)
train_token_ids = train_token_ids[:10000]
class data_generator(DataGenerator):
"""训练语料生成器
"""
def __iter__(self, random=False):
batch_token_ids = []
for is_end, token_ids in self.sample(random):
batch_token_ids.append(token_ids)
batch_token_ids.append(token_ids)
if len(batch_token_ids) == self.batch_size * 2 or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = np.zeros_like(batch_token_ids)
batch_labels = np.zeros_like(batch_token_ids[:, :1])
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids = []
def simcse_loss(y_true, y_pred):
"""用于SimCSE训练的loss
"""
# 构造标签
idxs = K.arange(0, K.shape(y_pred)[0])
idxs_1 = idxs[None, :]
idxs_2 = (idxs + 1 - idxs % 2 * 2)[:, None]
y_true = K.equal(idxs_1, idxs_2)
y_true = K.cast(y_true, K.floatx())
# 计算相似度
y_pred = K.l2_normalize(y_pred, axis=1)
similarities = K.dot(y_pred, K.transpose(y_pred))
similarities = similarities - tf.eye(K.shape(y_pred)[0]) * 1e12
similarities = similarities * 20
loss = K.categorical_crossentropy(y_true, similarities, from_logits=True)
return K.mean(loss)
# SimCSE训练
encoder.summary()
encoder.compile(loss=simcse_loss, optimizer=Adam(1e-5))
train_generator = data_generator(train_token_ids, 64)
encoder.fit(
train_generator.forfit(), steps_per_epoch=len(train_generator), epochs=1
)
encoder.save('test.model')
# del encoder
模型加载
from bert4keras.backend import keras
encoder = keras.models.load_model('test.model', compile=False)
使用测试
from utils import *
import sys
import numpy as np
import tensorflow as tf
from bert4keras.optimizers import Adam
from bert4keras.snippets import DataGenerator, sequence_padding
import jieba
jieba.initialize()
## 加载模型
from bert4keras.backend import keras
encoder = keras.models.load_model('../test.model', compile=False)
## 加载数据
kkk_all = np.load(r"D:\t**内容1.npy")
# 基本参数
model_type, pooling, task_name, dropout_rate = "BERT", "first-last-avg", "ATEC", 0.3
dropout_rate = float(dropout_rate)
# bert配置
model_name = {
'BERT': 'chinese_L-12_H-768_A-12',
'RoBERTa': 'chinese_roberta_wwm_ext_L-12_H-768_A-12',
'WoBERT': 'chinese_wobert_plus_L-12_H-768_A-12',
'NEZHA': 'nezha_base_wwm',
'RoFormer': 'chinese_roformer_L-12_H-768_A-12',
'BERT-large': 'uer/mixed_corpus_bert_large_model',
'RoBERTa-large': 'chinese_roberta_wwm_large_ext_L-24_H-1024_A-16',
'NEZHA-large': 'nezha_large_wwm',
'SimBERT': 'chinese_simbert_L-12_H-768_A-12',
'SimBERT-tiny': 'chinese_simbert_L-4_H-312_A-12',
'SimBERT-small': 'chinese_simbert_L-6_H-384_A-12'
}[model_type]
config_path = r'D:\t**\simbert\%s\bert_config.json' % model_name
if model_type == 'NEZHA':
checkpoint_path = '/root/kg/bert/%s/model.ckpt-691689' % model_name
elif model_type == 'NEZHA-large':
checkpoint_path = '/root/kg/bert/%s/model.ckpt-346400' % model_name
else:
checkpoint_path = r'D:\t**\simbert\%s\bert_model.ckpt' % model_name
dict_path = r'D:\t**\simbert\%s\vocab.txt' % model_name
print(dict_path)
# 建立分词器
if model_type in ['WoBERT', 'RoFormer']:
tokenizer = get_tokenizer(
dict_path, pre_tokenize=lambda s: jieba.lcut(s, HMM=False)
)
else:
tokenizer = get_tokenizer(dict_path)
### 数据embedding保存
if task_name == 'PAWSX':
maxlen = 128
else:
maxlen = 64
datas_all = [ i[1] for i in kkk_all.tolist()]
# 测试相似度效果
data = datas_all
a_token_ids, b_token_ids, labels = [], [], []
texts = []
for d in data:
# d=d[1]
token_ids = tokenizer.encode(d, maxlen=maxlen)[0]
a_token_ids.append(token_ids)
# token_ids = tokenizer.encode(d[1], maxlen=maxlen)[0]
# b_token_ids.append(token_ids)
# labels.append(d[2])
texts.append(d)
a_token_ids = sequence_padding(a_token_ids)
# b_token_ids = sequence_padding(b_token_ids)
a_vecs = encoder.predict([a_token_ids, np.zeros_like(a_token_ids)],
verbose=True)
# b_vecs = encoder.predict([b_token_ids, np.zeros_like(b_token_ids)],
# verbose=True)
# labels = np.array(labels)
a_vecs = a_vecs / (a_vecs**2).sum(axis=1, keepdims=True)**0.5
np.save(r"simcse_datas_chinese.npy",a_vecs)
##测试效果
def most_similar(text, topn=10):
"""检索最相近的topn个句子
"""
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
vec = encoder.predict([[token_ids], [segment_ids]])[0]
vec /= (vec**2).sum()**0.5
sims = np.dot(a_vecs, vec)
return [(kkk_all[i], sims[i]) for i in sims.argsort()[::-1][:topn]]
kk=["妲己不是坏女人","百变巴士","最美青春"]
mmm = []
for i in kk:
results = most_similar(i, 10)
mmm.append([i,results])
print(i,results)
titles = []
pics = []
for ii in results:
titles.append(ii[0][1])
pics.append(ii[0][2])
print(titles, pics)
妲己不是坏女人:
![]()
百变巴士:
![]()
最美青春:
![]()