基于 Metal 的现代渲染技术
Python实战社群
Java实战社群
长按识别下方二维码,按需求添加
.jpg")
扫码关注添加客服
进Python社群▲

扫码关注添加客服
进Java社群▲
作者:提拉拉拉就是技术宅,LinkedIn 高级研发工程师。曾就职于百度。博客:http://yuusann.com
Sessions: https://developer.apple.com/videos/play/wwdc2019/601/
本文发表于 2019/06/08 《WWDC19 内参》
引言
Metal 是 Apple 开发的一款图形引擎,诞生至今已经六岁了。去年,苹果带来了 Metal 3。
本文将基于 Metal 介绍图形学上几大经典的优化技术,以及 Metal 独有的 GPU 驱动渲染,其中包含 Metal3 带来的少量新 Feature。
由于 Metal 是底层的图形引擎,因此阅读本文需要一定的图形学基础和 Metal 基础。本文假定读者已经具备一定图形学知识并对 Metal 的基本渲染流程熟悉。
高级渲染技术
本章节会介绍几个图形学上经典的优化技术。这些技术在实现思想上并不是新的,有的甚至已经有几十年历史了。
下面就来看看这些技术的思想,以及在 Metal 里是如何实现的。
正向渲染(Forward Render)
在介绍优化技术之前,先来看看不优化的情况下,渲染一个场景是怎么实现的。
要在场景里绘制一个物体,只需要获得物体的顶点数据(网格),然后画就行了。它看上去像这样:

这是个最简单的场景,仅仅只有顶点,最多包含贴图,它没有材质,没有光源,没有反射,没有阴影。整个场景是没血没肉的,大概二十年前的游戏长得就是这样。

接下来,给场景加上光源和材质。光源和材质无非就是一些数值,只要装在一个 Buffer 里丢给着色器去计算就行了,因此它现在的流程像这样:
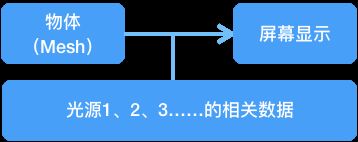
只是多上传了一些数值而已,材质和反射的计算部分都在着色器里处理了,对性能似乎并不会造成什么影响,看上去似乎没有需要优化的。
然而事实并非如此。在正向渲染中会针对每一个图元进行 N 次光照运算(N为光源数量),当光源数量成百上千时,正向渲染就会遇到瓶颈。下图中共有 1874 个点光源,用正向渲染耗时是无法想象的。
 图片来源:Hannes Nevalainen
图片来源:Hannes Nevalainen
以上就是传统的渲染流程,被称为正向渲染。
延迟渲染(Deferred)
为了解决多光源下的性能问题,延迟渲染诞生。
延迟渲染引入了Geometry Buffer(下文简称为G-Buffer)概念。G-Buffer 是一组大小和最终输出大小一致的缓冲区,在渲染时不立即计算出图元的最终颜色,而是将各个维度(位置、法线、反射等,其维度根据渲染的需求而定。如果需要渲染阴影,那么之中会有储存阴影遮挡状态的缓冲器等)的暂时记录在 G-Buffer 上,然后统一进行光照计算,确保只对最终显示在屏幕上的像素点进行光照运算。
其渲染流程为:

那么在 Metal 中,如何实现呢?
从图中可以看出,整个渲染过程被分为两个阶段:
G-Buffer Rendering
Lighting
因此开发者需要为这两个阶段分别创建不同的MTLRenderPassDescriptor。
首先是 G-Buffer 的 RenderPassDescriptor:
func setupDeferred() {
let geometryRenderPassDescriptor = MTLRenderPassDescriptor.init()
// Depth
geometryRenderPassDescriptor.depthAttachment.texture = depthTexture
geometryRenderPassDescriptor.depthAttachment.loadAction = .clear
geometryRenderPassDescriptor.depthAttachment.storeAction = .store
// G-Buffer
// Position
geometryRenderPassDescriptor.colorAttachments[0].texture = positionTexture
geometryRenderPassDescriptor.colorAttachments[0].loadAction = .dontCare
geometryRenderPassDescriptor.colorAttachments[0].storeAction = .store
// Albedo
geometryRenderPassDescriptor.colorAttachments[1].texture = albedoTexture
geometryRenderPassDescriptor.colorAttachments[1].loadAction = .dontCare
geometryRenderPassDescriptor.colorAttachments[1].storeAction = .store
// Normal
geometryRenderPassDescriptor.colorAttachments[2].texture = normalTexture
geometryRenderPassDescriptor.colorAttachments[2].loadAction = .dontCare
geometryRenderPassDescriptor.colorAttachments[2].storeAction = .store
// ……
}
Lighting 阶段的 RenderPassDescriptor:
func setupDeferred() {
let lightingRenderPassDescriptor = MTLRenderPassDescriptor.init()
lightingRenderPassDescriptor.colorAttachments[0].texture = lightingTexture
lightingRenderPassDescriptor.colorAttachments[0].loadAction = .clear
lightingRenderPassDescriptor.colorAttachments[0].storeAction = .store
}
渲染过程:
func render(command: MTLCommandBuffer) {
// Phase 1: G-Buffer Rendering
let geoEncoder = command.makeRenderCommandEncoder(descriptor: geometryRenderPassDescriptor)!
// Render Scene in G-Buffer
for mesh in scene.meshes {
geoEncoder.drawPrimitives(……)
}
geoEncoder.endEncoding()
// Phase 2: Lighting
let lgtEncoder = command.makeRenderCommandEncoder(descriptor: lightingRenderPassDescriptor)!
for light in scene.lights {
// Setup G-Buffer Textures
lgtEncoder.setFragmentTexture(……)
// Lighting Rendering
lgtEncoder.drawPrimitives(……)
}
lgtEncoder.endEncoding()
}
着色器方面,G-Buffer 阶段的片元着色器由于需要渲染一系列缓冲区,返回值不再是一个颜色值,而是类似于以下结构的一个结构体。
struct GBufferData
{
half4 lighting [[color(0), raster_order_group(0)]];
half4 albedo_specular [[color(1), raster_order_group(1)]];
half4 normal_shadow [[color(2), raster_order_group(1)]];
float depth [[color(3), raster_order_group(1)]];
};
代码中raster_order_group为光栅化顺序,指定光栅化顺序的特性由 Metal 2 引入,由于 GPU 光栅化是高度并行的,这个特性用于解决竞争问题。对这个概念陌生的同学可以访问这里[1]查看 Apple 对于Raster Order Groups的详细解释。
Lighting 阶段显然已经不需要原始物体的顶点数据了,而是直接从已经准备好的 G-Buffer 中取出各个维度的数据进行光照渲染。
fragment float4 Shade(LightingVertexInput in [[stage_in]],
depth2d depth_tex [[texture(0)]],
texture2d color_tex [[texture(1)]],
texture2d normal_tex [[texture(2)]]) {
float depth = depth_tex.read(in.pixelPos);
float4 color = color_tex.read(in.pixelPos);
uint normal = normal_tex.read(in.pixelPos);
return lightingFunction(color, normal, depth, ......)
}
从 Lighting 阶段的着色可以看出最终计算光照的像素点仅仅是最终显示在屏幕上的点而已,大大节约了不必要的计算。
以上为延时渲染的流程,它避免了大量不必要的光照计算,大大提升了多光源场景下的渲染性能,。
对于延迟渲染的实现有其他疑问的同学可以访问这里[2]获取 Apple 为开发者们准备的 Sample Code。这个 Demo 包含了完整的延时渲染过程,而且十分精美。

可编程混合(Programmable Blending)
上面提到的延时渲染技术引入了 G-Buffer,这是一组存储各个维度信息的缓冲区,必然会带来大量的显存消耗。每一个维度的缓冲区和渲染目标的大小一致,这就意味着每一个维度都会带来数兆的显存开销,一组 G-Buffer 可能会带来十几兆额外的显存开销,这是开发者们不愿意看到的。
那么如何来优化这组临时缓冲区呢?在原来的流程中,第一阶段开发者们向 G-Buffer 写入了大量数据,而在第二阶段中又原模原样读了出来。这个过程是不必要的。如果第一阶段的输出能够直接传递给第二阶段,那就皆大欢喜了。
顺着这个思路,Metal 允许开发者在不真正分配 G-Buffer 这一组临时缓冲区显存的情况下实现延时渲染。这一技术被称为Programmable Blending。
首先,在创建 G-Buffer 使用的临时纹理时,不再需要真正分配空间:
textureDescriptor.storageMode = .memoryless
其次,在创建 G-Buffer 各个维度的 RenderPassDescriptor 时,不再需要存储结果:
geometryRenderPassDescriptor.colorAttachments[n].storeAction = .dontcare
最后,在着色器代码中,传入参数不再是纹理,而是颜色值:
fragment float4 Shade(LightingVertexInput in [[stage_in]],
float depth [[color(0)]],
float4 color [[color(1)]],
float4 normal [[color(2)]]) {
// ......
}
现在,G-Buffer 不消耗额外的显存空间了。
平铺延迟渲染(Tiled Deferred)
平铺延迟渲染旨在解决多光源场景下的性能问题。
其思想是进一步减少多光源场景下的无效着色。在多光源场景下,并不是每个光源都对每个图元都有影响。在渲染一个图元时,仅计算对图元有影响的光源,剔除无效的光源是提升性能的有效途径。

每一个分块都被看做一个视锥,通过遍历各个光源计算光源和视锥是否相交来决定这个光源是否被剔除。在剔除光源时,分块之间是没有影响的,因此可以并行进行。在 Metal 中,这一步使用kernel function来实现。
kernel void CullLights(device Light *all_lights [[buffer(0)]]
threadgroup uint32_t &active_light_list [[threadgroup(0)]]
threadgroup float2 &depth_bounds [[threadgroup(1)]]) {
active_light_mask = 0;
for (uint i = tid; i < MAX_LIGHTS; ++i) {
if (IntersectLightWithTileFrustum(all_lights[i], depth_bounds) {
active_light_list |= (1u << i);
}
}
}
看完了 Shader,回头再来看看 Metal API 的使用。
func setupDeferredTiled() {
let tileDescriptor = MTLTileRenderPipelineDescriptor.init()
tileDescriptor.colorAttachments[0].pixelFormat = .rgba16Uint
tileDescriptor.colorAttachments[1].pixelFormat = .r32Float
// ......
}
首先生成一个MTLTileRenderPipelineDescriptor并使用这个 Descriptor 生成 Pipeline State,随后在编码阶段编入 CommandBuffer。
encoder.setRenderPipelineState(tileCullPipeline)
encoder.setTileBuffer(sceneLights, offset:0 atIndex:0)
encoder.setThreadgroupMemoryLength(MemoryLayout.size, offset:0 atIndex:0)
encoder.dispatchThreadsPerTile(MTLSizeMake(encoder.tileWidth, encoder.tileHeight, 1))
在获得每个分块对应的光源激活情况后进行光源着色即可。由于部分光源被剔除,能够提升性能是显而易见的。
平铺正向渲染(Tiled Forward)
基于对分块延迟的了解,现在把视角放在 G-Buffer 阶段。
在 G-Buffer 阶段渲染了各个维度的缓冲区,但事实上 Light Culling 阶段需要的仅仅是深度信息(depth bounds),因此完全没有必要在那个时候渲染这么多维度的内容。

在最初的阶段只进行深度渲染,然后进行光源剔除。在光源剔除以后,一个图元通常不会被太多光源照亮,因此此时可以直接使用前向渲染进行渲染。
集群正向渲染(Clustered Forward)
集群正向渲染是平铺正向渲染的优化。
传统的光源剔除算法基于二维的分块(Tile),所得到的是基于二维分块的光源列表。而新的光源剔除算法直接对三维空间进行分块,直接生成基于三维空间的光源列表。

有了三维的光源列表,直接进行前向渲染即可。
可见性缓冲(Visibility Buffer)
物体(Mesh)可见性优化也是常见的优化方式。
其思想显而易见,摄像机能看得到的物体才进行渲染,看不到的物体就不渲染。
可以看到途中红色框框区域是摄像机,只有摄像机能够看到的区域才进行光照、阴影等渲染。
本次 Metal 3 提供了两个新的内建索引来帮助开发者进行相关开发:
float 3 [[barycentric_coord]]uint [[primitive_id]]
可见性检测可以通过摄像机视锥和网格进行相交性计算,具体方法再次就不展开了。
小结
本章节主要讲了几种传统的渲染优化技术在 Metal 中的实现,它们的优缺点如下图所示:

这些优化技术或新或旧,在古老的 OpenGL 相关技术栈上都能够实现。但接下来,GPU 驱动渲染,就是这些“老古董”们无能为力的了,好戏现在才上演。
GPU 驱动渲染
GPU 驱动渲染最早发布于 Metal 2,它可以完全解放 CPU,仅依靠 GPU 自己驱动自己进行渲染。
传统渲染循环
传统的渲染循环使用的是 CPU 驱动渲染。
在渲染一个大场景时,视锥剔除(Frustum Culling)、遮挡剔除(Occlusion Culling)以及细节层次选择(LOD Selection)等流程。
视锥剔除:相机所见范围外的物体直接剔除。
遮挡剔除:根据深度信息,被完全遮挡的物体也直接剔除。
细节层次选择:近处的物体加载高精度模型,越远的物体选择加载越低精度模型。
在传统渲染循环中,这些过程都是在 CPU 完成的。

在这几个过程中,以视锥剔除为例子。在视锥剔除中需要遍历场景中的物体,与摄像机视锥做相交运算来得到哪些物体在视锥里,哪些在视锥外。这些运算是独立的,可以并行的。而 CPU 通常只有几个核心,即使设计使用并行,也并行不了几个。

同理,遮挡剔除、细节层次选择也是如此。

把这些任务放在 CPU 中进行,并发量并不理想。但如果把这些工作放在 GPU,那情况就完全不同了。
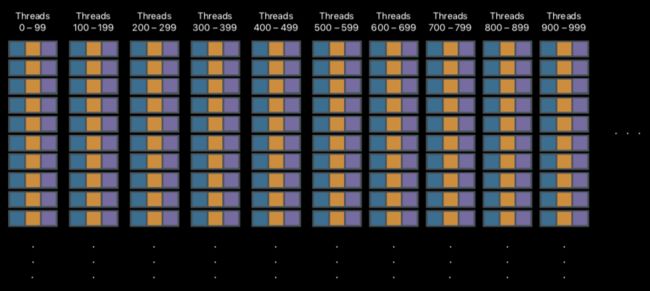
GPU 拥有成百上千的流处理器,可以很好地并发处理这些。如果把这些任务交给 GPU,性能上将会得到一定提升。
GPU 驱动渲染循环
GPU 驱动旨在让 CPU 脱离渲染流程,其好处有:
让 CPU 可以专注处理逻辑,更新资源。
减少了 CPU 和 GPU 的同步的时间消耗。
在渲染大场景时,虽然渲染流程复杂,但整个处理逻辑清晰。开发者只需要把数据预先准备好并交给 GPU,后面的过程仅仅是把逻辑挪个位置罢了。
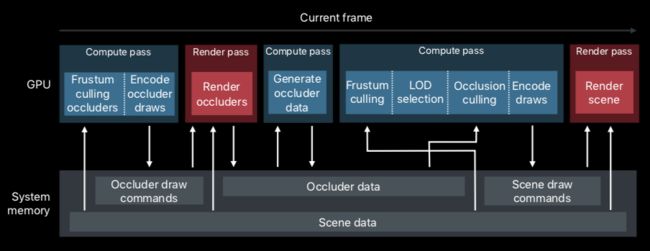
那么如何构建这么一个渲染流程呢?
准备数据
首先自然是场景数据,包括物体顶点、材质等。

再之是各类参数,包括物体参数,材质参数等。

这些参数的定义大概像这样:
// 材质
struct Material
{
float roughness;
float intensity;
texture2d surfaceTexture;
texture2d specularTexture;
render_pipeline_state pipelineState;
// ...
};
// 场景数据
struct Scene
{
device Mesh *meshes;
device Material *materials;
device Model *models;
// ...
};
这些数据由 CPU 打包放进 MTLBuffer 里一口气上传给 GPU。
CPU 的任务
CPU 不再直接驱动渲染,因此这里使用的是间接命令(Indirect Command Buffer,ICB)。
// 创建 icb
let desc = MLTIndirectCommandBufferDescriptor()
desc.commandTypes = [.drawIndexed]
let icb = device.newIndirectCommandBuffer(with: desc, maxCommandCount:count, options...)!
渲染时:
// CPU 处理其他逻辑,如游戏逻辑处理
// 通过 Blit Command 等命令更新缓冲区数据
// 执行 icb 由 GPU 编码渲染命令并执行
renderEncoder.executeCommandsInBuffer(in: icb, withRange:NSMakeRange(0, count))
GPU 编码命令
由于是 GPU 驱动渲染,因此这里需要开发者使用 Shader 实现命令编码。
kernel void EncodeDraw(device Scene &scene [[buffer(0)]],
device CommandArgs &cmd_args [[buffer(1)]])
{
const uint draw_id [[thread_position_in_grid]])
// 获取模型
device Model* model = scene.models[draw_id];
// 计算视锥剔除
bool culled = isFrustumCulled(model, ...);
// 如果没有被剔除,进入渲染流程
if (!culled)
{
// 选择一个合适精度的资源
uint lod = getLOD(model, ...);
// 获得物体网格数据
uint mesh_id = model->meshIndices[lod];
Mesh *mesh = scene.meshes[mesh_id];
// 获取材质数据
uint material_id = scene.models->materialIndices[lod];
Material *material = scene.materials[material_id];
// 其他操作
// ...
// 生成渲染命令
render_command cmd(cmd_args.cmd_buffer, draw_id);
// 编码
cmd.set_render_pipeline_state(material->pipelineState);
cmd.set_vertex_buffer(getMeshUniforms(mesh), 0);
cmd.set_vertex_buffer(getMeshVertexData(mesh), 1);
cmd.set_fragment_buffer(material, 0);
// 绘制
cmd.draw_indexed_primitives(primitive_type::triangle, ...);
}
}
所有曾经在 CPU 中实现的命令编码现在将以 Kernel Function 的形式实现。这些工作在 Shader 里的 API 和 Metal API 十分类似,所以开发者们能够很好地上手。
对于以上流程有任何疑问可以参考这里[3]的 Demo。
稀疏编码
在上面的着色器代码中,只有没被剔除的物体才会被渲染。
if (!culled) { ... }
被遮挡的物体不会被渲染,那么这个命令就是空的。空的命令被提交以后,命令缓冲区的内容就变得稀疏了。

那么最好的方法就是把这些空隙去掉。
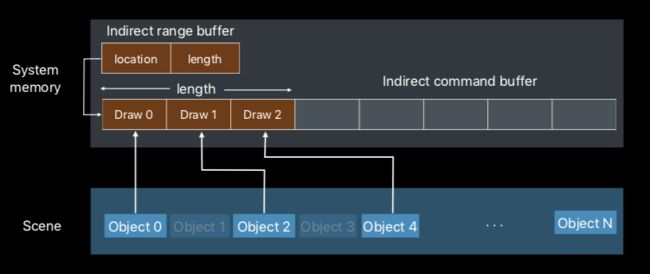
那样的话,渲染的物体的个数就会随着剔除情况不同而变化,想要得到结果,就必须在着色器里才能知道。因此在这里引入了一个新参数atomic_uint *range来计数,每当渲染一个物体,就使用atomic_fetch_add_explicit增加计数。
kernel void EncodeDraw(device Scene &scene [[buffer(0)]],
device CommandArgs &cmd_args [[buffer(1)]],
device atomic_uint *range [[buffer(2)]])
{
// ...
if (!culled)
{
// ...
render_command cmd(cmd_args.cmd_buffer, atomic_fetch_add_explicit(range, 1, ...));
// ...
}
}
最后,使用计数个数来渲染,这样就能解决稀疏编码的问题了。
GPU 驱动计算
接下来是一个 Metal 3 带来的新功能——GPU 驱动计算。
Metal 2 所带来的仅仅是 GPU 驱动渲染,而现在,GPU 可以驱动 Compute Shader 了。这就意味着包括各类剔除算法在内的大量功能也能够挪到 GPU 来驱动了。
小结
以上就是 GPU 驱动渲染的内容。
Metal 2 所带来的功能在 Metal 3 得到了进一步加强,进一步解放 CPU,离 CPU 彻底脱离渲染更近了一步。
硬件差异
Metal 发展到今天,由于硬件的更新换代,许多旧设备已经无法支持新的功能了。当开发者们在使用新特性时,如何兼容旧设备呢?
现在,Apple 将设备分为以下几个簇:
1、Apple(iOS)

2、Mac

3、Common

4、iOSMac
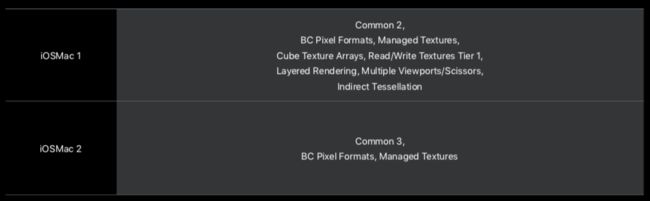
使用时应这样使用:
if #available(macOS 10.15, iOS 13, tvOS 13, *) {
if self.device.supportsVersion(.version3_0) {
if self.device.supportsFamily(.familyMac2) {
// 启用Mac族,版本2,Metal版本3的特性
}
} else {
// 使用早期特性
}
} else {
// 使用早期系统的特性
if self.device.supportsFeatureSet(.featureSet_macOS_GPUFamily2_v1) {
// ...
}
}
最后是本文第一章提到的各项优化技术的支持情况:

以及本文第二章提到的 GPU 驱动渲染的支持情况:

结语
本文着重介绍了几项传统图形学优化技术在 Metal 中的实现,以及 Metal 现金的 GPU 驱动渲染技术,最后介绍了特性的硬件支持情况。
现如今,Metal 技术已经在 Apple 的图形技术栈的地位已不可动摇。如果热爱图形学的你还停留在 OpenGL 的话,不妨现在行动起来,学起来吧。
参考资料
[1]
这里: https://developer.apple.com/documentation/metal/mtldevice/ios_and_tvos_devices/about_gpu_family_4/about_raster_order_groups?language=objc
[2]这里: https://developer.apple.com/documentation/metal/deferred_lighting?language=objc
[3]这里: https://developer.apple.com/documentation/metal/advanced_command_setup/encoding_indirect_command_buffers_on_the_gpu?language=objc

程序员专栏 扫码关注填加客服 长按识别下方二维码进群

近期精彩内容推荐:
 阿里、京东、美团……背后的共同金主
阿里、京东、美团……背后的共同金主
沸腾了!苏宁全员涨薪,每月最高多1万6!
大白话java多线程,高手勿入
用Python完成Excel合并(拆分)的各种操作


在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓