数据分析在银行业应用之欺诈检测
在本文中我们将通过探索一个很常见的用例——欺诈检测,从而了解数据分析在银行业是如何运用的。
背景介绍
银行业是最早应用数据科学技术的领域之一,收集了大量结构化数据。
那么,数据分析是如何应用于银行业的呢?
如今,数据已经成为银行业最宝贵的资产,不仅可以帮助银行吸引更多的客户,提高现有客户的忠诚度,做出更有效的数据驱动的决策,还可以增强业务能力,提高运营效率,改善现有的服务,加强安全性,并通过所有这些行动获得更多的收入等等。
因此,当下大部分数据相关工作需求来自银行业,这并不令人惊讶。
数据分析使银行业能够成功地执行众多任务,包括:
-
投资风险分析
-
客户终身价值预测
-
客户细分
-
客户流失率预测
-
个性化营销
-
客户情绪分析
-
虚拟助理和聊天机器人
……
下面,我们将仔细看看银行业中最常见的数据分析用例之一。
数据分析在银行业应用案例:欺诈检测
除了银行业,欺诈活动还存在于许多领域。在政府、保险、公共部门、销售和医疗保健等领域,这都是一个具有挑战性的问题。也就是说,任何处理大量在线交易的企业都会面临欺诈风险。
金融犯罪的形式多种多样,包括欺诈性信用卡交易、伪造银行支票、逃税、网络攻击、客户账户盗窃、合成身份、诈骗等。
欺诈检测是为识别和防止欺诈活动和财务损失而采取的一种主动措施。
其主要分析技术可分为两组:
-
**统计学:**统计参数计算、回归、概率分布、数据匹配
-
**人工智能(AI):**数据挖掘、机器学习、深度学习
机器学习是欺诈检测的重要支柱,其工具包提供了两种方法:
-
监督方法:K-近邻、逻辑回归、支持向量机、决策树、随机森林、时间序列分析、神经网络等。
-
无监督方法:聚类分析、链接分析、自组织地图、主成分分析、异常识别等。
目前还没有通用的机器学习算法用于欺诈检测。相反,对于现实世界的数据科学用例,通常会测试几种技术或其组合,计算模型的预测准确性,并选择最佳方法。
欺诈检测系统的主要挑战是迅速适应不断变化的欺诈模式和欺诈者的策略,并及时发现新的和日益复杂的方案。欺诈案件总是占少数,并且很好地隐藏在真实的交易中。
下面来探讨一下使用Python进行信用卡欺诈检测。
我们将用到 creditcard_data 数据集。
Credit Card Fraud Detection | Kaggle数据集:
https://www.kaggle.com/mlg-ulb/creditcardfraud
该数据集是Kaggle信用卡欺诈检测数据集的一个修改样本。原始数据代表了2013年9月两天内欧洲持卡人拥有信用卡的交易情况。
让我们读入数据并快速浏览一下。
import pandas as pd
creditcard_data = pd.read_csv('creditcard_data.csv', index_col=0)
print(creditcard_data.info())
print('\n')
pd.options.display.max_columns = len(creditcard_data)
print(creditcard_data.head(3))
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5050 entries, 0 to 5049
Data columns (total 30 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 V1 5050 non-null float64
1 V2 5050 non-null float64
2 V3 5050 non-null float64
3 V4 5050 non-null float64
4 V5 5050 non-null float64
5 V6 5050 non-null float64
6 V7 5050 non-null float64
7 V8 5050 non-null float64
8 V9 5050 non-null float64
9 V10 5050 non-null float64
10 V11 5050 non-null float64
11 V12 5050 non-null float64
12 V13 5050 non-null float64
13 V14 5050 non-null float64
14 V15 5050 non-null float64
15 V16 5050 non-null float64
16 V17 5050 non-null float64
17 V18 5050 non-null float64
18 V19 5050 non-null float64
19 V20 5050 non-null float64
20 V21 5050 non-null float64
21 V22 5050 non-null float64
22 V23 5050 non-null float64
23 V24 5050 non-null float64
24 V25 5050 non-null float64
25 V26 5050 non-null float64
26 V27 5050 non-null float64
27 V28 5050 non-null float64
28 Amount 5050 non-null float64
29 Class 5050 non-null int64
dtypes: float64(29), int64(1)
memory usage: 1.2 MB
V1 V2 V3 V4 V5 V6 V7 \
0 1.725265 -1.337256 -1.012687 -0.361656 -1.431611 -1.098681 -0.842274
1 0.683254 -1.681875 0.533349 -0.326064 -1.455603 0.101832 -0.520590
2 1.067973 -0.656667 1.029738 0.253899 -1.172715 0.073232 -0.745771
V8 V9 V10 V11 V12 V13 V14 \
0 -0.026594 -0.032409 0.215113 1.618952 -0.654046 -1.442665 -1.546538
1 0.114036 -0.601760 0.444011 1.521570 0.499202 -0.127849 -0.237253
2 0.249803 1.383057 -0.483771 -0.782780 0.005242 -1.273288 -0.269260
V15 V16 V17 V18 V19 V20 V21 \
0 -0.230008 1.785539 1.419793 0.071666 0.233031 0.275911 0.414524
1 -0.752351 0.667190 0.724785 -1.736615 0.702088 0.638186 0.116898
2 0.091287 -0.347973 0.495328 -0.925949 0.099138 -0.083859 -0.189315
V22 V23 V24 V25 V26 V27 V28 \
0 0.793434 0.028887 0.419421 -0.367529 -0.155634 -0.015768 0.010790
1 -0.304605 -0.125547 0.244848 0.069163 -0.460712 -0.017068 0.063542
2 -0.426743 0.079539 0.129692 0.002778 0.970498 -0.035056 0.017313
Amount Class
0 189.00 0
1 315.17 0
2 59.98 0
数据集包含以下变量:
-
数值编码的变量V1到V28是从PCA变换中获得的主分量。由于保密问题,未提供有关原始功能的背景信息。
-
Amount变量表示交易金额。
-
Class变量显示交易是否为欺诈(1)或非欺诈(0)。
幸运的是,就其性质而言,欺诈事件在任何交易列表中都是极少数。然而,当数据集中包含的不同类别或多或少存在时,机器学习算法通常效果最好。否则,就没有什么数据可供借鉴,这个问题被称为类别不均。
接着计算欺诈交易占数据集中交易总数的百分比:
round(creditcard_data['Class'].value_counts()*100/len(creditcard_data)).convert_dtypes()
0 99
1 1
Name: Class, dtype: Int64
并创建一个图表,将欺诈与非欺诈的数据点可视化。
import matplotlib.pyplot as plt
import numpy as np
def prep_data(df):
X = df.iloc[:, 1:28]
X = np.array(X).astype(float)
y = df.iloc[:, 29]
y = np.array(y).astype(float)
return X, y
def plot_data(X, y):
plt.scatter(X[y==0, 0], X[y==0, 1], label='Class #0', alpha=0.5, linewidth=0.15)
plt.scatter(X[y==1, 0], X[y==1, 1], label='Class #1', alpha=0.5, linewidth=0.15, c='r')
plt.legend()
return plt.show()
X, y = prep_data(creditcard_data)
plot_data(X, y)
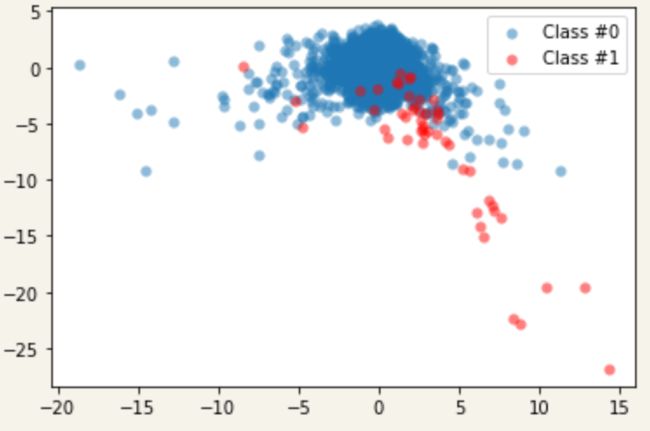
可以确认的是,欺诈性交易的比例非常低,当中存在一个类别不平衡问题的案例。
为了解决这个问题,我们可以使用合成少数人超抽样技术(SMOTE)来重新平衡数据。与随机超额取样不同,SMOTE稍微复杂一些,因为它不只是创建观察值的精确副本。
相反,它使用欺诈案件的最近邻居的特征来创建新的、合成的样本,这些样本与少数人类别中的现有观察值相当相似,让我们把SMOTE应用于该信用卡数据。
from imblearn.over_sampling import SMOTE
method = SMOTE()
X_resampled, y_resampled = method.fit_resample(X, y)
plot_data(X_resampled, y_resampled)
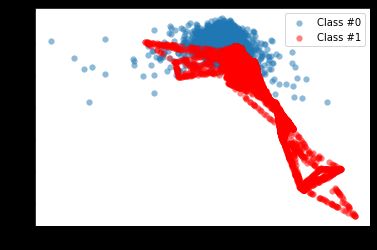
正如所看到的,使用SMOTE突然提供了更多的少数类别的观察结果。为了更好地看到这种方法的结果,这里将把其与原始数据进行比较。
def compare_plot(X, y, X_resampled, y_resampled, method):
f, (ax1, ax2) = plt.subplots(1, 2)
c0 = ax1.scatter(X[y==0, 0], X[y==0, 1], label='Class #0',alpha=0.5)
c1 = ax1.scatter(X[y==1, 0], X[y==1, 1], label='Class #1',alpha=0.5, c='r')
ax1.set_title('Original set')
ax2.scatter(X_resampled[y_resampled==0, 0], X_resampled[y_resampled==0, 1], label='Class #0', alpha=.5)
ax2.scatter(X_resampled[y_resampled==1, 0], X_resampled[y_resampled==1, 1], label='Class #1', alpha=.5,c='r')
ax2.set_title(method)
plt.figlegend((c0, c1), ('Class #0', 'Class #1'), loc='lower center', ncol=2, labelspacing=0.)
plt.tight_layout(pad=3)
return plt.show()
print(f'Original set:\n'
f'{pd.value_counts(pd.Series(y))}\n\n'
f'SMOTE:\n'
f'{pd.value_counts(pd.Series(y_resampled))}\n')
compare_plot(X, y, X_resampled, y_resampled, method='SMOTE')
Original set:
0.0 5000
1.0 50
dtype: int64
SMOTE:
0.0 5000
1.0 5000
dtype: int64
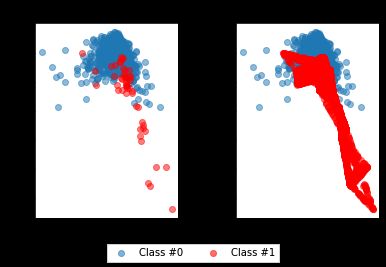
因此,SMOTE方法已经完全平衡了数据,少数群体现在与多数群体的规模相等。
接着让我们回到原始数据,并尝试检测欺诈案件。按照这类传统的方式,我们必须制定一些规则来识别欺诈行为。
例如,此类规则可能涉及不寻常的交易地点或可疑的频繁交易。其想法是基于常见的统计数据定义阈值,通常是基于观察值的平均值,并在功能上使用这些阈值来检测欺诈。
print(creditcard_data.groupby('Class').mean().round(3)[['V1', 'V3']])
V1 V3
Class
0 0.035 0.037
1 -4.985 -7.294
在特殊情况下,可以应用以下条件:V1<-3和V3<-5。然后,为了评估这种方法的性能,我们将把标记的欺诈案例与实际案例进行比较:
creditcard_data['flag_as_fraud'] = np.where(np.logical_and(creditcard_data['V1']<-3, creditcard_data['V3']<-5), 1, 0)
print(pd.crosstab(creditcard_data['Class'], creditcard_data['flag_as_fraud'], rownames=['Actual Fraud'], colnames=['Flagged Fraud']))
Flagged Fraud 0 1
Actual Fraud
0 4984 16
1 28 22
我们发现,在50个欺诈案件中能识别其中的22个,但无法检测出其他28个,并得到16个误报。让我们看看使用机器学习技术是否能解决这个问题。
现在要在信用卡数据上实现一个简单的逻辑回归分类算法,从而来识别欺诈行为,然后在混淆矩阵上将结果可视化。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
lr = LogisticRegression()
lr.fit(X_train, y_train)
predictions = lr.predict(X_test)
print(pd.crosstab(y_test, predictions, rownames=['Actual Fraud'], colnames=['Flagged Fraud']))
Flagged Fraud 0.0 1.0
Actual Fraud
0.0 1504 1
1.0 1 9
需要注意的是,在混淆矩阵中要查看的观测值较少,因为我们只使用测试集来计算模型结果,即仅占整个数据集的30%。
结果是发现了更高比例的欺诈案件:90%(9/10),而之前的结果是44%(22/50),得到的误报也比以前少了很多,这是一个进步。
现在让我们回到前面讨论的类不平衡问题,并探索是否可以通过将逻辑回归模型与SMOTE重采样方法相结合来进一步提高预测结果。为了高效、一次性地完成这项工作,我们需要定义一个管道,并在数据上运行:
from imblearn.pipeline import Pipeline
# Defining which resampling method and which ML model to use in the pipeline
resampling = SMOTE()
lr = LogisticRegression()
pipeline = Pipeline([('SMOTE', resampling), ('Logistic Regression', lr)])
pipeline.fit(X_train, y_train)
predictions = pipeline.predict(X_test)
print(pd.crosstab(y_test, predictions, rownames=['Actual Fraud'], colnames=['Flagged Fraud']))
Flagged Fraud 0.0 1.0
Actual Fraud
0.0 1496 9
1.0 1 9
可以看到,在案例中,SMOTE并没有带来任何改进:仍然捕获了90%的欺诈事件,而且假阳性数量略高。
这里的解释是,重新取样不一定在所有情况下都能带来更好的结果。当欺诈案件在数据中非常分散时,其最近的不一定也是欺诈案件,所以使用SMOTE会引入偏见问题。
为了提高逻辑回归模型的准确性,我们可以调整一些算法参数,也可以考虑采用K-fold交叉验证法,而不是直接将数据集分成两部分。
最后,还可以尝试一些其他的机器学习算法(如决策树或随机森林),看看它们是否能给出更好的结果。
参考链接:
https://www.datacamp.com/blog/data-science-in-banking
好,以上就是今天的分享。如果大家还有数据分析方面相关的疑问,就在评论区留言。
推荐文章
-
李宏毅《机器学习》国语课程(2022)来了
-
有人把吴恩达老师的机器学习和深度学习做成了中文版
-
上瘾了,最近又给公司撸了一个可视化大屏(附源码)
-
如此优雅,4款 Python 自动数据分析神器真香啊
-
梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
-
年终汇总:20份可视化大屏模板,直接套用真香(文末附源码)
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
