卷积神经网络CNN
卷积神经网络CNN
- CNN通常用于影像处理
为什么需要CNN
为什么需要CNN,我用普通的fully connected的反向传播网络进行图像训练会怎样
-
需要过多参数
假设一张彩色的图为100×100的,那么像素点就是100×100×3,那么输入层为三万维
假设下一层隐含层有1000个神经元,那么这个神经网络第一层就已经有30000×1000个参数了
——CNN做的事情,就是简化这个神经网络的架构
——我们用一些人的理解,不要使用fully connected的神经网络,尽可能把不需要的参数从一开始就过滤掉
如何拿掉参数
为什么我们能够将一些参数拿掉?为什么我们可以简化这个网络架构?
减少冗余神经元
-
我们神经元的训练,是为了观测图片上的某一个patterns
比如某个神经元负责侦测有没有鸟嘴,有没有翅膀,有没有爪子等
Some patterns are much smaller than the whole image
-
因此,我们可以只观测部分,不需要观测整张图
A neuron does not have to see the whole image to discover the pattern.
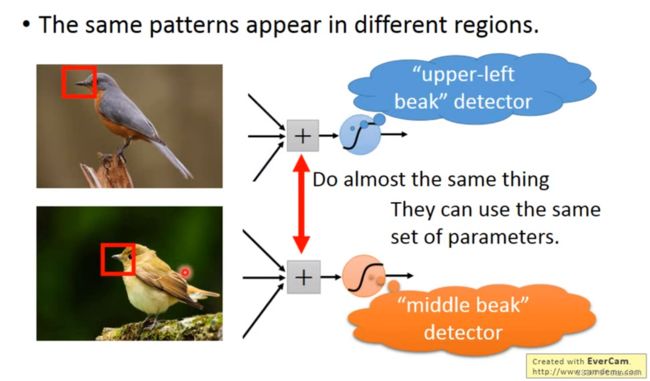
——侦测鸟嘴这部分的工作是一样的;我们不需要说,用一个神经元侦测一下左上方有没有鸟嘴,再用另一个神经元侦测中间部分有没有鸟嘴
——简化的基本就是,去除这种冗余的神经元,使得统一
Subsampling
- 将像素点偶数列/偶数行删除
- Subsampling the pixels will not change the object.

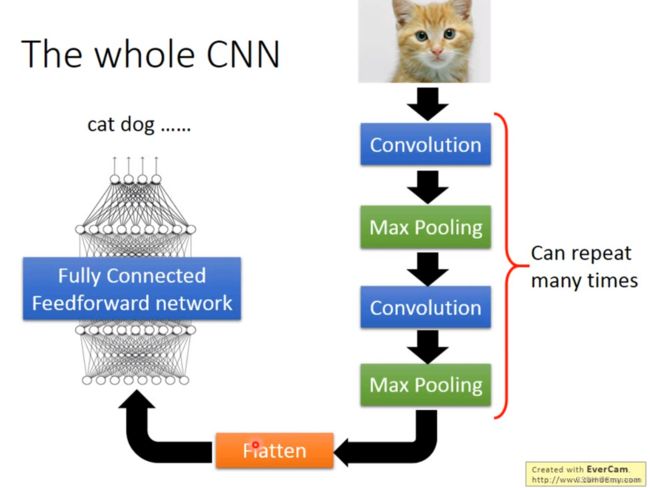
CNN步骤
-
Property 1
某些patterns比整张图小的多,因此可以观测局部
-
Property 2
某些同一种patterns出现在不同的地方
-
Property 3
可以做Subsampling
Property1和Property2主要通过卷积操作完成
Property3主要通过Max Pooling完成
Convolution
——卷积
-
会存在一堆Filter(这些Filter相当于全连接网络的一个神经元)
-
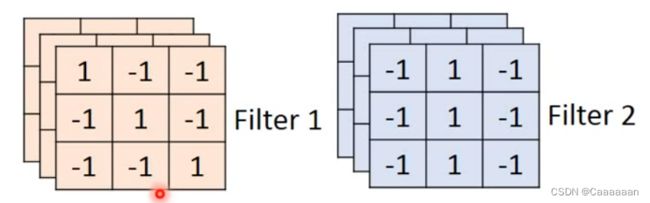
每一个Filter本质都是一个矩阵,矩阵里的每一个元素相当于网络的参数,和神经元的weight和bias一样,是需要train出来的
-
每一个Filter,在侦测一个pattern
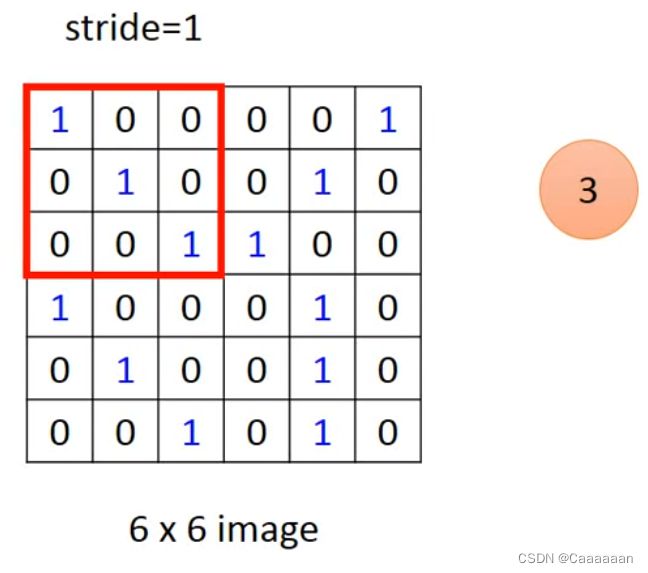
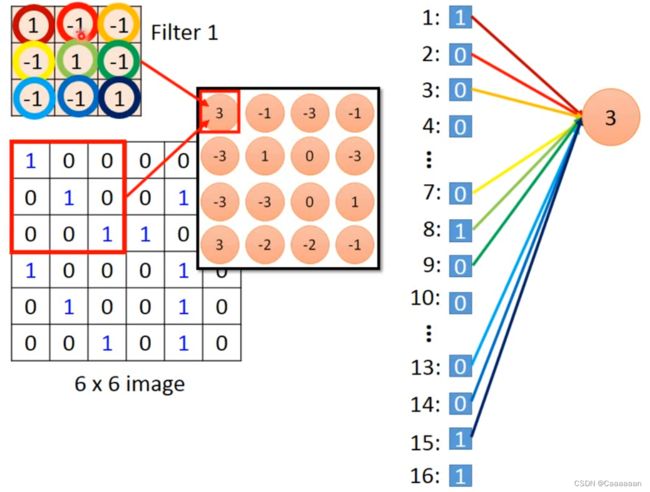
例如,现在6×6的一个image,有一个Filter是3×3,这个Filter的作用相当于在侦测一个3×3的pattern
步骤
- 将Filter放于图像上,与图像对应位置做内积
- 实现property1,变成寻找对应pattern
-
挪动Filter的位置,这个挪动位置的多少,用stride表示
这个stride是超参数,需要自己设定和调节

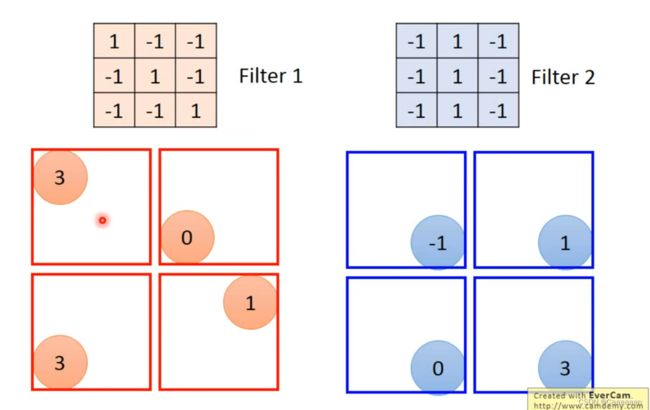
这个Filter要检测的pattern,得到最大值分布在左上角和左下角,因此这个Filter对应检测的pattern分布在这个图上的左上角和左下角,就能够实现property2.
——同一个pattern,出现在不同位置,用同一个filter就能检测出来
- 很多很多个Filter工作完成之后,形成Feature Map
缺陷
当你的pattern是不同大小的时候,会出现说你需要不同Filter才能够处理
例如当你的图像中,有大的鸟嘴和小的鸟嘴,需要不同size的Filter才能够解决甄别出鸟嘴
- 方法一:如果你实现知道图像的pattern是偏大还是偏小,可以去先做normalized这件事
- 方法二:DeepMind里提到一个新的方式,在CNN之前加多一层隐含层,该层需要提示了,需要将图片的哪一部分进行缩放,旋转等操作,再进入CNN中训练,可以得到比较好的结果
——对于彩图如何处理呢?因为有3个颜色通道(RGB),相当于是有一张图上有3个image,每一层分别代表RGB层的值
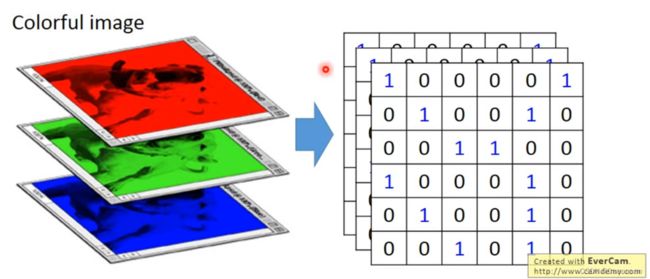
——这个时候,你的Filter就不是一个矩阵了,也是一个3维的立方体
注意
我们在做内积的时候,并不是把RGB每一层颜色,分开来算内积
而是把这三层和Filter一块来计算,从整体上来考虑这个pattern
在神经网络中理解Filter
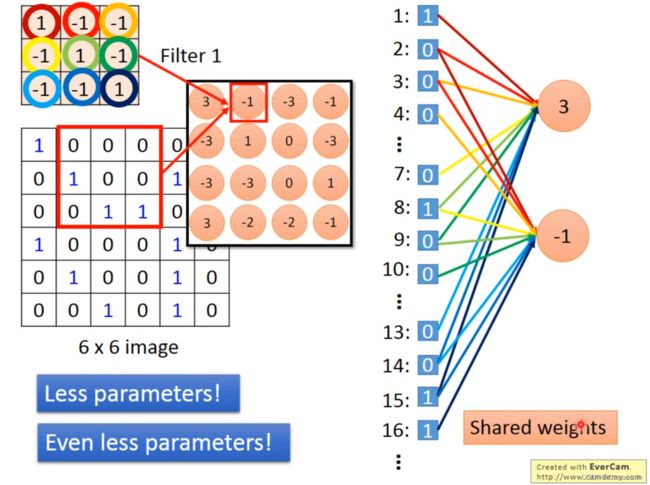
卷积的过程,就是等同于一个网络删掉某些weight训练的结果

-
将image拉直
内积对应相乘,等于某个值成对应权重,最后输出内积结果
-
只有对应框起来的那些神经元,才会进行连接
通过这种方式,实现更少的参数
-
同时,当我们通过stride进行挪动的时候,这个Filter不变,因此weight是不变的,只是连接的神经元变化了,达到了Share weights的功能
-
这个时候就能实现更少的参数,因为用的是同一组weights
如何实现share weights
- 原理和反向传播网络是一样的
- 对于不连接的线,只要让它的weight一直是0,一直不训练它,就可以实现不完全连接的网络
- 对于同一组weight,我们通过反向传播计算出多组梯度,然后取梯度平均,让他们update同样的量
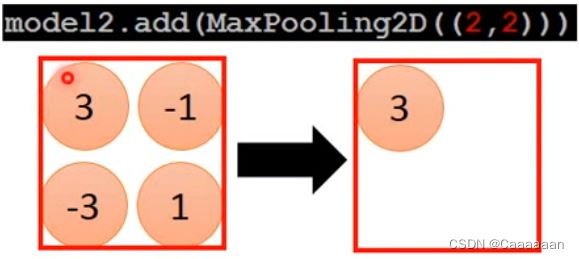
Max Pooling
——SubSampling
-
对得到的矩阵,可以四个为一组,合并成一个值
合并方式有很多:可以选其中最大值,可以取平均值
达到让你的image变小的效果
-
每一个Filter就能带来一层

-
然后你就得到了比较小的image,然后再重复卷积-池化
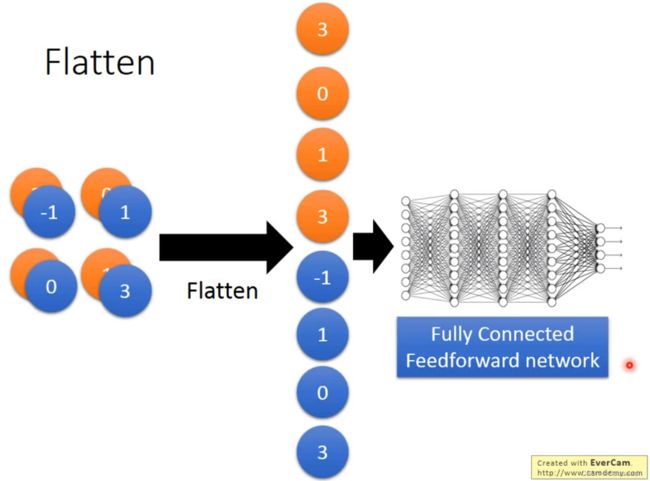
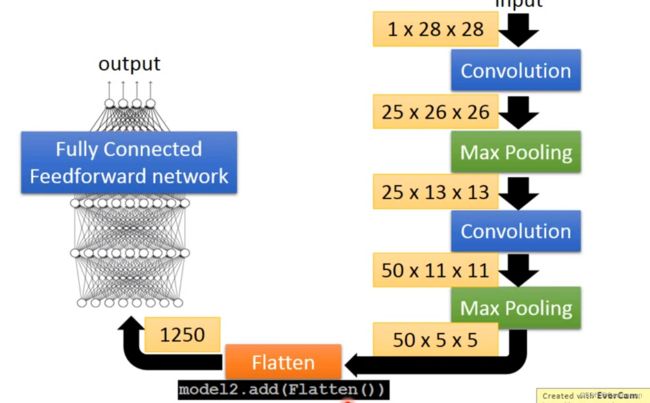
Flatten
——扁平化
- 得到的Feature map拉直
- 丢进Fully connected的网络中进行训练就可以了
CNN in keras
——你只需要修改网络的结构和输入的格式
——本来在DNN里面,input是一个向量vector
——CNN会考虑这个image的几何空间的,因此需要input一个张量tensor(高维的向量)
model.add(Conv2D(25,3,3,input_shape=(1,28,28)))
#Conv2D(25,3,3意味着有25个Filter,每个Filter是3*3的
#input_shape=(1,28,28)表明你输入的图片是28*28的,每个pixel是一个颜色,因此是1;如果是RGB的话需要3个颜色通道

model.add(MaxPooling2D((2,2)))
#我们把feature map的东西,按照2*2来考虑,进行最大池化

——扁平化
model.add(Flatten())
可解释性
- 第一层的filter是比较容易解释的,我们只需要看它的值,就能够直到这个filter在detect什么特征
- 但是第二层往后的filter,它直接针对的对象,并不是image的东西;而且它考虑的范围,并不是一个矩阵,而是一个高维的立方体
——如何识别这个filter是做什么的
-
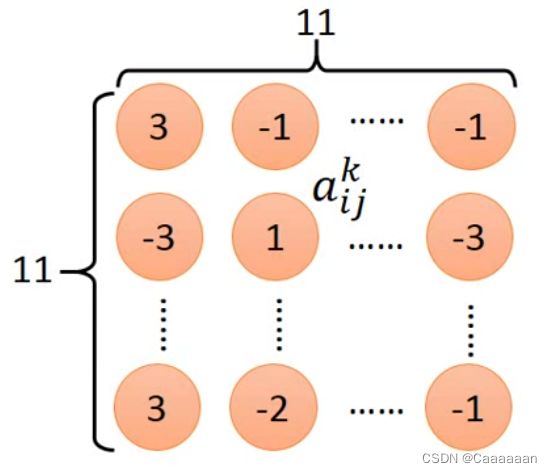
把第k个filter的输出拿出来
-
定义:Degree of the activation of the k-th filter
定义一个东西,能衡量第k个filter有多activation
a k = ∑ i = 1 11 ∑ j = 1 11 a i j k a^k=\sum_{i=1}^{11}\sum_{j=1}^{11}a_{ij}^k ak=i=1∑11j=1∑11aijk -
我们希望直到这个filter做的是什么,我们找一张image,这个image能够使得 a k a^k ak最大
假设我们input的image是x
x ∗ = arg max x a k x^*=\arg\max_xa^k x∗=argxmaxak
这个image——x能够让上述定义的Degree最大这个也可以通过梯度下降法来实现
- 以往的过程是,我们通过image来update filter的参数,来使得可以训练出一个较好的神经网络模型
- 当我们希望找到filter寻找的对应是什么feature时,我们可以反向——固定filter的参数,取update image,来找到这个image

——然后结果大概是这样子
- 我们可以看到,这些filter最match的image,都是一些纹路
- 例如第一行第三个的filter,就是寻找一种斜条纹
- 每个filter detect的就是不同角度的线条
——fully connected neural network的每个神经元做的是什么事情呢?
如法炮制刚才的做法
-
我们定义一个神经元的输出的是 a j a_j aj
-
然后我们需要找到一个image能够使得这个 a j a_j aj最大
x ∗ = arg max x a j x^*=\arg\max_xa^j x∗=argxmaxaj

——得到的结果大概是这样的
因为在做卷积这件事的过程,其实是在寻找一些feature,因此可以看到filter侦测的是类似于纹路的东西
因此我们可以看到,我们丢进去全连接的网络中,神经元输出的东西是不一样的
因为这个网络的工作是看整张图,是一个完整的图形,而不是一个局部的纹路
——虽然考虑的并不是是哪个数字,但是是某种线条中的图案
——考虑output
我们直接考虑output的输出,会不会得到数字呢?
然后反向寻找,使之最大的image
x ∗ = arg max x y i x^*=\arg\max_xy^i x∗=argxmaxyi

——得到的结果是这样的
为什么是这样呢?
因为神经网络学习到的东西和人类学习的东西其实不太一样的。我们肉眼其实看不出上述的结果图有什么差别
我们将上面的图放进去CNN里面去训练,它就会反应说这个就是0,这个就是1,它就是能够区分
推荐文章——“Deep Neural Networks are Easily Folled”
https://ieeexplore.ieee.org/document/7298640
——怎样让它表现出来像数字
因为一张图是不是数字,我们都会有一些假设,会有一些东西肯定不是数字
我们应该对这个y做一些规范化regularization
对输入的x做一些constraint(约束)
这个约束告诉机器,这个x虽然能够让你的y很大,但是它不是数字
x ∗ = arg max x ( y i − ∑ i , j ∣ x i j ∣ ) x^*=\arg\max_x(y^i-\sum_{i,j}|x_{ij}|) x∗=argxmax(yi−i,j∑∣xij∣)
∑ i , j ∣ x i j ∣ \sum_{i,j}|x_{ij}| ∑i,j∣xij∣所有pixel的values,这就是L1的正则项
得到的结果是这样的

——这样之后,你得到的x就比较像数字了,你会发现6还是比较像的
让机器所看到的东西放大呈现出来,实际上是目前Deep Dream和Deep Style做的事情
Deep Style
- 输入一张图片,让它的风格像某个著名的画作


参考文献——“A Neural Algorithm of Artistic Style”
[1508.06576] A Neural Algorithm of Artistic Style (arxiv.org)
——核心思路
-
将第一张照片放进CNN里训练,得到Filter的output
-
这个output得到的是第一张图有怎样的内容
-
然后将呐喊放进CNN里训练,得到的是filter和filter之间的correlation(相关性)
-
这个相关性代表的就是这张图里有怎样的风格
-
使用同一个CNN,去找到一个image
-
这个image通过filter后的输出能够像第一张照片的output;
-
这个image输出的filter之间的correlation要像第二张照片
更多的应用
那么CNN呢,不只是用于图像上,也可以用于其他领域
Alpha Go
Alpha Go的监督学习的学习就是通过CNN实现的
那么什么时候可以使用CNN
-
一些patterns比整张图小得多
-
同一个patterns可能会出现在不同的位置
-
做Subsampling不会影响图片的object——所以有maxpooling这个部分
但是围棋里面并没有这个东西;那么Alpha Go是如何表现的呢?
Alpha Go的paper上有写到CNN的架构,它的输入是19×19×48的
因为这个棋盘是19×19的,48表示这个位置的一些状态,不仅仅是讨论上面是黑棋还是白棋,还有一些状态例如是否处于叫吃的状态等。
- 第一层将输入zero pads到23×23,(也就是用0填充外围)
- 用5×5的filter,一共是192个filters,stride=1
- 变成21×21的image
- 下面的filter都是3×3的filter,stride=1
然后你就会发现Alpha Go是没有使用max Pooling的
——根据围棋的特性,不需要再做max pooling这一层
Speech

- 将speech的音频转换成Spectrogram
- 这个CNN的filter,只在纵轴上移动
Text
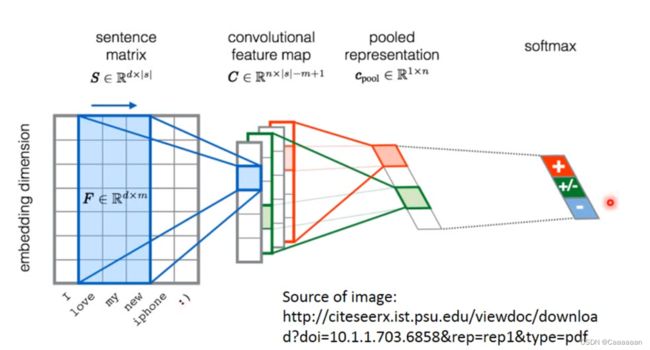
-
这个词序列需要先经过词嵌入,获得词对应的向量
-
然后我们把向量排在一起,当作一个image
-
filter的高和向量的长度时一样的,沿着词汇的顺序进行移动,得到feature map
Learn more
让机器画出一些image
PixelRNN
[1601.06759] Pixel Recurrent Neural Networks (arxiv.org)
Variation Autoencoder(VAE)
[1312.6114] Auto-Encoding Variational Bayes (arxiv.org)
Generative Adversarial Network(GAN)
[1406.2661] Generative Adversarial Networks (arxiv.org)