【Transformers】第 8 章:使用高效的 Transformer
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
高效、轻便、快速transformers简介
模型尺寸缩减的实现
使用 DistilBERT 进行知识蒸馏
修剪transformers
量化
使用有效的自我关注
具有固定模式的稀疏注意力
可学习的模式
低秩分解、核方法和其他方法
概括
到目前为止,您已经学习了如何设计自然语言处理( NLP ) 架构,以使用转换器实现成功的任务性能。在本章中,您将学习如何使用蒸馏、修剪和量化从经过训练的模型中制作出有效的模型。其次,您还将获得有关高效稀疏转换器的知识,例如 Linformer、BigBird、Performer 等。您将看到它们在各种基准测试中的表现,例如内存与序列长度以及速度与序列长度。您还将看到模型尺寸缩小的实际用途。
本章的重要性凸显出来,因为在有限的计算能力下运行大型神经模型变得越来越困难。拥有更轻量级的通用语言模型(例如 DistilBERT)非常重要。然后可以对这个模型进行微调,获得良好的性能,就像它的非蒸馏模型一样。由于 Transformers 中注意力点积的二次复杂性,基于 Transformers 的架构面临复杂性瓶颈,尤其是对于长上下文 NLP 任务。基于字符的语言模型、语音处理和长文档属于长上下文问题。近年来,我们看到在提高 self-attention 效率方面取得了很大进展,例如作为复杂性解决方案的 Reformer、Performer 和 BigBird。
简而言之,在本章中,您将了解以下主题:
- 高效、轻便、快速变压器简介
- 模型尺寸缩减的实现
- 使用有效的自我关注
技术要求
我们将使用 Jupyter Notebook 来运行我们的编码练习,这需要 Python 3.6+,并且需要安装以下包:
- TensorFlow
- PyTorch
- Transformers >=4.00
- Datasets
- sentence-transformers
- py3nvml
高效、轻便、快速transformers简介
基于变压器楷模有以二次内存和计算复杂性为代价,在许多 NLP 问题中明显取得了最先进的结果。我们可以强调以下有关复杂性的问题:
- 由于它们的自我注意机制,这些模型无法有效地处理长序列,这种机制与序列长度成二次方。
- 使用具有 16 GB 的典型 GPU 的实验设置可以处理 512 个标记的句子以进行训练和推理。但是,较长的条目可能会导致问题。
- NLP 模型从 BERT-base 的 1.1 亿个参数不断增长到 Turing-NLG 的 170 亿个参数,再到 GPT-3 的 1750 亿个参数。这个概念引起了对计算和内存复杂性的担忧。
- 我们还需要关注成本、生产、再现性和可持续性。因此,我们需要更快、更轻的变压器,尤其是在边缘设备上。
已经提出了几种方法来降低计算复杂性和内存占用。其中一些方法侧重于改变架构,而另一些则不改变原始架构,而是对训练模型或训练阶段进行改进。我们将它们分为两组,模型大小缩减和高效自注意力。
可以使用三种不同的方法来减小模型大小:
- 知识蒸馏
- 修剪
- 量化
这三个中的每一个都有自己的减小模型大小的方法,我们将在模型大小减小部分的实现中简要描述。
在知识蒸馏中,一个较小的转换器(学生)可以转移一个大模型(老师)的知识。我们训练学生模型,以便它可以模仿老师的行为或为相同的输入产生相同的输出。蒸馏模型可能表现不佳这老师。之间有一个取舍压缩、速度和性能。
修剪是机器学习中的一种模型压缩技术,用于通过删除模型中对产生结果贡献不大的部分来减小模型的大小。最典型的例子是决策树剪枝,它有助于降低模型复杂度,增加模型的泛化能力。量化将模型权重类型从较高分辨率更改为较低分辨率。例如,我们使用一个典型的浮点数 ( float64 ),每个权重消耗 64 位内存。相反,我们可以使用int8进行量化,每个权重消耗 8 位,自然呈现数字的准确性较低。
自注意力头没有针对长序列进行优化。为了解决这个问题,许多不同的已经提出了一些方法。最有效的方法是Self-Attention Sparsification,我们将很快讨论。另一个最广泛使用的方法是Memory Efficient Backpropagation。这种方法平衡了中间结果的缓存和重新计算之间的权衡。需要在前向传播期间计算的中间激活来计算反向传播期间的梯度。梯度检查点可以减少大量的内存占用和计算。另一种方法是流水线并行算法。小批量被拆分为小批量,并行管道利用前向和后向操作期间的等待时间,同时将批次传输到深度学习加速器这样的作为图形处理单元( GPU ) 或张量处理单元( TPU )。
参数共享可以被认为是实现高效深度学习的首批方法之一。最典型的例子是 RNN,如第 1 章所述,从词袋到变形金刚,其中展开表示的单元使用共享参数。因此,可训练参数的数量不受输入大小的影响。一些共享参数(也称为权重绑定或权重复制)传播网络因此可训练参数的数量为减少。例如,Linformer 跨头和层共享投影矩阵。Reformer 以性能损失为代价共享查询和密钥。
现在让我们尝试通过相应的实例来理解这些问题。
模型尺寸缩减的实现
尽管基于 Transformer 的模型在 NLP 的许多方面都取得了最先进的结果,它们通常具有相同的问题:它们是大型模型并且速度不够快而无法使用。在需要将它们嵌入到移动应用程序或 Web 界面中的商业案例中,如果您尝试使用原始模型似乎是不可能的。
为了提高这些模型的速度和大小,提出了一些技术,这里列出:
- 蒸馏(也称为知识蒸馏)
- 修剪
- 量化
对于这些技术中的每一种,我们提供了一个单独的小节来解决技术和理论见解。
使用 DistilBERT 进行知识蒸馏
这过程将知识从较大模型转移到较小模型的过程称为知识蒸馏。也就是说,有教师模式和学生模式;老师通常是一个更大更强的模型,而学生则更小更弱。
该技术用于各种问题,从视觉到声学模型和 NLP。该技术的典型实现如图 8.1所示:
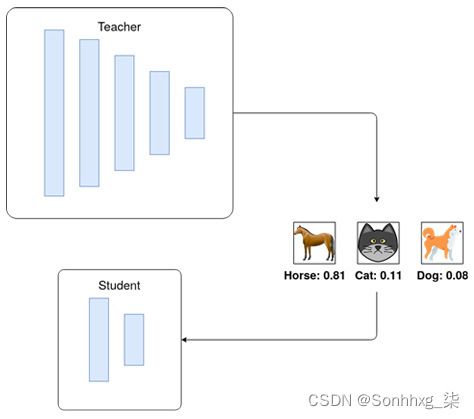
图 8.1 – 图像分类的知识蒸馏
DistilBERT 是该领域最重要的模型之一,受到了研究人员甚至企业的关注。该模型试图模仿 BERT-Base 的行为,参数减少了 50%,达到了教师模型 95% 的性能。
一些细节如下:
- DistilBert 压缩了 1.7 倍,速度提高了 1.6 倍,相对性能提高了 97%(与原始 BERT 相比)。
- Mini-BERT 压缩了 6 倍,速度提高了 3 倍,并且具有 98% 的相对性能。
- TinyBERT 压缩了 7.5 倍,速度提高了 9.4 倍,相对性能提高了 97%。
用于训练模型的蒸馏训练步骤使用 PyTorch 非常简单(原始描述和代码可在https://medium.com/huggingface/distilbert-8cf3380435b5获得):
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Optimizer
KD_loss = nn.KLDivLoss(reduction='batchmean')
def kd_step(teacher: nn.Module,
student: nn.Module,
temperature: float,
inputs: torch.tensor,
optimizer: Optimizer):
teacher.eval()
student.train()
with torch.no_grad():
logits_t = teacher(inputs=inputs)
logits_s = student(inputs=inputs)
loss = KD_loss(input=F.log_softmax(
logits_s/temperature,
dim=-1),
target=F.softmax(
logits_t/temperature,
dim=-1))
loss.backward()
optimizer.step()
optimizer.zero_grad()这种模型监督训练为我们提供了一个更小的模型,它在行为上与基本模型非常相似。然而,损失这里使用的函数是Kullback-Leibler损失,以确保那学生模型模仿了教师模型的好的和坏的方面,而没有修改最后一个 softmax logits 的决定。这个损失函数显示了两个分布之间的差异;更大的差异意味着更高的损失值。使用这个损失函数的原因是为了让学生模型尝试完全模仿老师的行为。BERT 和 DistilBERT 的 GLUE 宏分数仅相差 2.8%。
修剪transformers
修剪包括设置过程根据预先指定的标准,每层的权重为零。例如,一个简单的剪枝算法可以获取每一层的权重并设置低于阈值的权重。这种方法消除了价值非常低且不会对结果影响太大的权重。
同样,我们修剪变压器网络的一些冗余部分。修剪后的网络比原始网络更容易泛化。我们已经看到了成功的剪枝操作,因为剪枝过程可能保留了真正的潜在解释因素并丢弃了冗余子网。但是我们仍然需要训练一个大型网络。合理的策略是我们训练一个尽可能大的神经网络。然后,丢弃对模型性能影响较小的不太显着的权重或单位。
有两种方法:
- 非结构化修剪:哪里无论它们位于神经网络的哪个部分,具有较小显着性(或最小权重大小)的单个权重都会被删除。
- 结构化修剪:这个方法修剪头或层。
但是,修剪过程必须与现代 GPU 兼容。
大多数库(例如 Torch 或 TensorFlow)都具有此功能。我们将描述如何使用 Torch 修剪模型。修剪中有许多不同的方法可以使用(基于幅度的或基于互信息的)。最容易理解和实现的方法之一是 L1 剪枝方法。该方法取每一层的权重并将具有最低 L1 范数的那些归零。您还可以指定什么修剪后,您的权重百分比必须转换为零。为了使这个示例更易于理解并显示其对模型的影响,我们将使用第 7 章文本表示中的文本表示示例。我们将修剪模型,看看修剪后它的表现如何:
- 我们将使用Roberta模型。您可以使用以下代码加载模型:
from sentence_transformers import SentenceTransformer distilroberta = SentenceTransformer('stsb-distilroberta-base-v2') - 您还需要加载指标和数据集进行评估:
from datasets import load_metric, load_dataset stsb_metric = load_metric('glue', 'stsb') stsb = load_dataset('glue', 'stsb') mrpc_metric = load_metric('glue', 'mrpc') mrpc = load_dataset('glue','mrpc') - 为了评估模型,就像在第 7 章,文本表示中一样,您可以使用以下功能:
import math import tensorflow as tf def roberta_sts_benchmark(batch): sts_encode1 = tf.nn.l2_normalize( distilroberta.encode(batch['sentence1']), axis=1) sts_encode2 = tf.nn.l2_normalize( distilroberta.encode(batch['sentence2']), axis=1) cosine_similarities = tf.reduce_sum( tf.multiply(sts_encode1, sts_encode2), axis=1) clip_cosine_similarities = tf.clip_by_value(cosine_similarities,-1.0,1.0) scores = 1.0 - tf.acos(clip_cosine_similarities) / math.pi return scores - 当然,还需要设置标签:
references = stsb['validation'][:]['label'] - 并在不进行任何更改的情况下运行基本模型:
distilroberta_results = roberta_sts_benchmark(stsb['validation']) - 在完成所有这些事情之后,这就是我们真正开始修剪模型的步骤:
from torch.nn.utils import prune pruner = prune.L1Unstructured(amount=0.2) - 前面的代码使用 L1-norm 剪枝制作了一个剪枝对象,每层的权重为 20%。要将其应用于模型,您可以使用以下代码:
state_dict = distilroberta.state_dict() for key in state_dict.keys(): if "weight" in key: state_dict[key] = pruner.prune(state_dict[key])它会迭代地修剪所有层以他们的名义有分量;换句话说,我们将修剪所有权重层,而不触及有偏差的层。当然,您也可以出于实验目的进行尝试。
- 同样,最好将状态字典重新加载到模型中:
distilroberta.load_state_dict(state_dict) - 现在我们已经完成了所有工作,我们可以测试新模型:
distilroberta_results_p = roberta_sts_benchmark(stsb['validation']) - 为了对结果有一个良好的可视化表示,您可以使用以下代码:
import pandas as pd pd.DataFrame({ "DistillRoberta":stsb_metric.compute(predictions=distilroberta_results, references=references), "DistillRobertaPruned":stsb_metric.compute(predictions=distilroberta_results_p, references=references) })以下屏幕截图显示了结果:
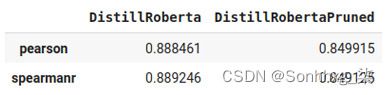
图 8.2 – 原始模型和修剪模型之间的比较
但是你所做的是你消除了模型所有重量的 20%,减少了它的大小和计算量成本,以及性能损失 4%。但是,此步骤可以与其他技术(例如量化)结合使用,这将在下一小节中进行探讨。
这种类型的剪枝适用于层中的某些权重;然而,也有可能完全放弃某些部分或变压器架构的层,例如,可以放弃一些注意力头并跟踪变化。
PyTorch 中还有其他类型的剪枝算法,比如迭代剪枝和全局剪枝,值得一试。
量化
量化是一个信号处理和通信术语,通常用于强调所提供数据的准确性。更多的位意味着在数据分辨率方面更高的准确性和精度。例如,如果您有一个以 4 位表示的变量,并且您想将其量化为 2 位,这意味着您必须降低分辨率的准确性。使用 4 位可以指定 16 种不同的状态,而使用 2 位可以区分 4 种状态。换句话说,通过将数据的分辨率从 4 位降低到 2 位,您可以节省 50% 以上的空间和复杂性。
许多流行的库,例如 TensorFlow、PyTorch 和 MXNET,都支持混合精度运算。回忆一下第 5 章中TrainingArguments类中使用的fp16参数。fP16提高了计算效率,因为现代 GPU 为降低精度的数学提供了更高的效率,但结果在fP32中累积。混合精度可以减少训练所需的内存使用量,这允许我们增加批量大小或模型大小。
量化可应用于模型权重以降低其分辨率并节省计算时间、内存和存储空间。在本小节中,我们将尝试量化我们在上一节中修剪的模型:
- 为了为此,您可以使用以下代码将模型量化为 8 位整数表示而不是浮点数:
import torch distilroberta = torch.quantization.quantize_dynamic( model=distilroberta, qconfig_spec = { torch.nn.Linear : torch.quantization.default_dynamic_qconfig, }, dtype=torch.qint8) - 之后,您可以使用以下代码获得评估结果:
distilroberta_results_pq = roberta_sts_benchmark(stsb['validation']) - 和以前一样,您可以查看结果:
pd.DataFrame({ "DistillRoberta":stsb_metric.compute(predictions=distilroberta_results, references=references), "DistillRobertaPruned":stsb_metric.compute(predictions=distilroberta_results_p, references=references), "DistillRobertaPrunedQINT8":stsb_metric.compute(predictions=distilroberta_results_pq, references=references) })结果如下:

图 8.3 – 原始模型、修剪模型和量化模型之间的比较
- 到现在为止,你刚用了蒸馏模型,修剪它,然后量化它以减少它的大小和复杂性。让我们看看保存模型节省了多少空间:
distilroberta.save("model_pq")使用以下代码查看模型大小:
ls model_pq/0_Transformer/ -l --block-size=M | grep pytorch_model.bin -rw-r--r-- 1 root 191M May 23 14:53 pytorch_model.bin如您所见,它是 191 MB。模型的初始大小为 313 MB,这意味着我们设法将模型的大小减小到其原始大小的 61%,而性能方面仅损失了 6%-6.5%。请注意,块大小参数在 Mac 上可能会失败,需要使用-lh来代替。
到目前为止,您已经了解了在工业用途的实际模型准备方面的剪枝和量化。但是,您还获得了有关蒸馏过程及其用途的信息。还有许多其他方法可以执行修剪和量化,这可能是阅读本节后的一个很好的步骤。了解更多信息和指南,您可以在https://github.com/huggingface/block_movement_pruning查看运动修剪。这种剪枝是一种简单且确定性的一阶权重剪枝方法。它使用重量变化训练找出哪些权重更有可能未被使用,对结果的影响较小。
使用有效的自我关注
有效的方法限制注意力机制以获得有效的转换器模型,因为转换器的计算和内存复杂性主要是由于自注意力机制。注意机制相对于输入序列长度呈二次方缩放。对于短输入,二次复杂度可能不是问题。然而,为了处理更长的文档,我们需要改进随序列长度线性缩放的注意力机制。
我们大致可以将有效的注意力解决方案分为三类:
- 具有固定模式的稀疏注意力
- 可学习的稀疏模式
- 低秩分解/核函数
接下来让我们从基于固定模式的稀疏注意力开始。
具有固定模式的稀疏注意力
回顾这注意力机制由查询、键和值组成,大致如下所示:
![]()
这里,主要是 softmax的Score函数执行 QK T乘法,需要 O(n 2) 内存和计算复杂度,因为一个令牌位置以完全自注意力模式关注所有其他令牌位置以构建其位置嵌入。我们对所有标记位置重复相同的过程以获得它们的嵌入,从而导致二次复杂度问题。这是一种非常昂贵的学习方式,尤其是对于长上下文 NLP 问题。很自然地会问这样一个问题,我们是否需要如此密集的交互,或者是否有更便宜的方法来进行计算?许多研究人员已经解决了这个问题,并采用了各种技术来减轻复杂性负担并降低自注意力机制的二次复杂性。他们大多在性能、计算和内存之间进行权衡,特别是对于长文档。
降低复杂性的最简单方法是稀疏化完整的自注意力矩阵或找到另一种更便宜的方法来近似完全注意力。稀疏注意力模式制定了如何连接/断开某些位置而不干扰通过层的信息流,这有助于模型跟踪长期依赖关系并构建句子级编码。
图 8.4描述了完全自注意力和稀疏注意力按此顺序,其中行对应于输出位置,列对应于输入。一个完整的自注意力模型将直接在任意两个位置之间传输信息。另一方面,在局部滑动窗口注意力中,也就是稀疏注意力,如图右侧所示,空单元格表示对应的输入-输出位置之间没有交互。图中的稀疏模型是基于固定的模式,即某些手动设计的规则。更具体地说,局部滑动窗口注意力是最早提出的方法之一,也称为基于局部的固定模式方法。其背后的假设是有用信息位于每个位置邻居中。每个查询令牌都关注该位置左侧的 window/2 键令牌和右侧的 window/2 键令牌。在下面的示例中,窗口大小选择为 4。此规则以相同的方式适用于转换器中的每一层。在一些研究中,窗口大小随着它进一步向层移动而增加。
下图简单描述了full attention和sparse attention的区别:
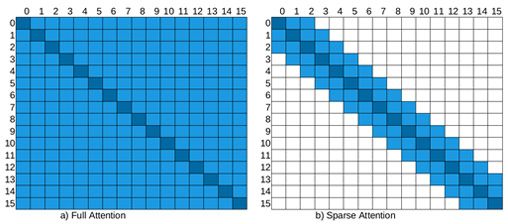
图 8.4 – 全注意力与稀疏注意力
在稀疏模式信息通过模型中的连接节点(非空单元)传输。例如,稀疏注意矩阵的输出位置 7 不能直接关注输入位置 3(请参见图 8.4右侧的稀疏矩阵),因为单元格 (7,3) 被视为空。但是,位置 7 通过令牌位置 5 间接涉及位置 3,即 (7->5, 5->3 => 7->3)。该图还说明,虽然完全自注意力会产生 n 2个活动单元(顶点),但稀疏模型大约会产生5×n 个。
另一个重要的类型是全球关注。一些选定的令牌或一些注入的令牌被用作全局注意力,可以关注所有其他位置并被他们关注。因此,任意两个标记位置之间的最大路径距离等于 2。假设我们有一个句子[GLB, the, cat, is, very, sad]其中Global ( GLB ) 是注入的全局标记,窗口大小为 2 ,这意味着令牌只能处理其直接的左右令牌和 GLB。从cat到sad没有直接的交互。但是我们可以按照cat-> GLB, GLB-> sad交互,通过 GLB 令牌创建超链接。全局令牌可以从现有令牌中选择,也可以像(CLS)一样添加。如下图所示,前两个token位置被选为全局token:
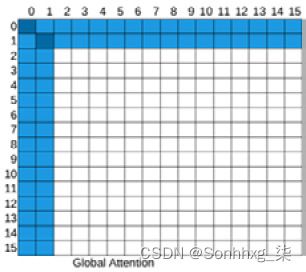
图 8.5 –Global attention
由方式,这些全球的代币也不必在句子的开头。例如,longformer 模型在前两个标记之外随机选择全局标记。
还有四个更广泛看到模式。随机注意(图 8.6中的第一个矩阵)用于通过随机选择来缓解信息流从现有的令牌。但大多数时候,我们将随机注意力作为组合模式(左下角矩阵)的一部分,该模式由其他模型的组合组成。Dilated attention类似于滑动窗口,只是在窗口中放了一些空隙,如图 8.6右上方所示:
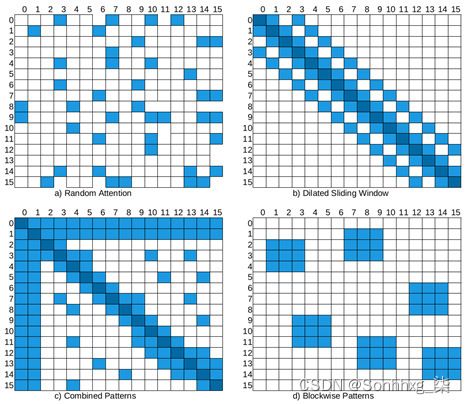
图 8.6 – 随机、扩张、组合和分块
分块模式(底部图 8.6的右侧)提供一个其他模式的基础。它将令牌分成固定数量的块,这对于长上下文问题特别有用。例如,当使用 512 的块大小对 4,096x4,096 的注意力矩阵进行分块时,会形成 8 (512x512) 个查询块和关键块。BigBird 和 Reformer 等许多高效模型大多将代币分块以降低复杂性。
需要注意的是,建议的模式必须得到加速器和库的支持。一些注意力模式(如扩张模式)需要特殊的矩阵乘法,在撰写本章时,当前的深度学习库(如 PyTorch 或 TensorFlow)不直接支持这种矩阵乘法。
我们准备进行一些高效变压器的实验。我们将继续使用 Transformers 库支持并在 HuggingFace 平台上具有检查点的模型。Longformer是使用稀疏注意力的模型之一。它使用滑动的组合窗口和全球关注。它还支持扩张的滑动窗口注意力:
- 在开始之前,我们需要安装py3nvml包进行基准测试。请回想一下,我们已经在第 2 章,主题的动手介绍中讨论了如何应用基准测试:
!pip install py3nvml - 我们也需要检查我们的设备以确保没有正在运行的进程:
! nvidia-smi输出如下:
图 8.7 – GPU 使用情况
- 目前,Longformer 作者分享了几个检查点。以下代码片段加载 Longformer 检查点allenai/longformer-base-4096并处理长文本:
from transformers import LongformerTokenizer, LongformerForSequenceClassification import torch tokenizer = LongformerTokenizer.from_pretrained( 'allenai/longformer-base-4096') model=LongformerForSequenceClassification.from_pretrained( 'allenai/longformer-base-4096') sequence= "hello "*4093 inputs = tokenizer(sequence, return_tensors="pt") print("input shape: ",inputs.input_ids.shape) outputs = model(**inputs) - 这输出就像如下:
input shape: torch.Size([1, 4096])
正如所见,Longformer 可以处理最长为4096的序列。当我们传递一个长度超过4096的序列时,这是限制,你会得到错误IndexError: index out of range in self。
Longformer 的默认attention_window是512,这是每个标记周围的注意力窗口的大小。通过以下代码,我们实例化了两个 Longformer 配置对象,其中第一个是默认的 Longformer,第二个是较轻的,我们将窗口大小设置为较小的值,例如 4,以便模型变得更轻:
- 请注意以下示例。我们将始终调用XformerConfig.from_pretrained()。此调用不会下载模型检查点的实际权重,而只会从 HuggingFace Hub 下载配置。在本节中,由于我们不会进行微调,因此我们只需要配置:
from transformers import LongformerConfig, PyTorchBenchmark, PyTorchBenchmarkArguments config_longformer=LongformerConfig.from_pretrained( "allenai/longformer-base-4096") config_longformer_window4=LongformerConfig.from_pretrained( "allenai/longformer-base-4096", attention_window=4) - 和这些配置实例,您可以使用自己的数据集训练 Longformer 语言模型,将配置对象传递给 Longformer 模型,如下所示:
from transformers import LongformerModel model = LongformerModel(config_longformer)除了训练 Longformer 模型外,您还可以将经过训练的检查点微调到下游任务。为此,您可以继续应用第 03 章中所示的代码进行语言模型训练和第 05-06 章中的微调。
- 现在,我们将使用PyTorchBenchmark比较这两种配置与不同长度的输入 [128、256、512、1024、2048、4096] 的时间和内存性能,如下所示:
sequence_lengths=[128,256,512,1024,2048,4096] models=["config_longformer","config_longformer_window4"] configs=[eval(m) for m in models] benchmark_args = PyTorchBenchmarkArguments( sequence_lengths= sequence_lengths, batch_sizes=[1], models= models) benchmark = PyTorchBenchmark( configs=configs, args=benchmark_args) results = benchmark.run() - 这输出是以下:
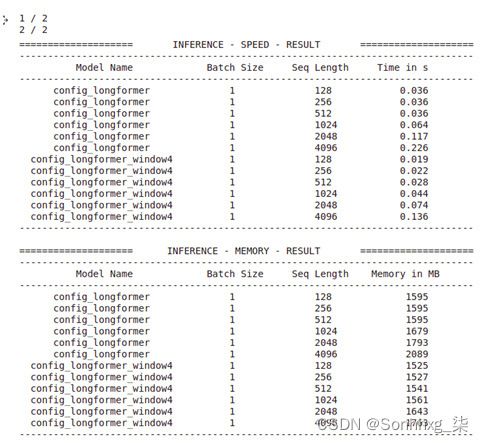
图 8.8 – 基准测试结果
一些提示对于PyTorchBenchmarkArguments:如果如果您想查看训练和推理的性能,则应将参数training设置为True(默认为False)。您可能还想查看您当前的环境信息。您可以通过将no_env_print设置为False来做到这一点;默认值为True。
让我们将性能可视化以更易于解释。为此,我们定义了一个plotMe()函数,因为我们还需要该函数进行进一步的实验。该函数根据默认运行时间复杂度或正确的内存占用量绘制推理性能:。
- 这里是这函数定义:
import matplotlib.pyplot as plt def plotMe(results,title="Time"): plt.figure(figsize=(8,8)) fmts= ["rs--","go--","b+-","c-o"] q=results.memory_inference_result if title=="Time": q=results.time_inference_result models=list(q.keys()) seq=list(q[models[0]]['result'][1].keys()) models_perf=[list(q[m]['result'][1].values()) \ for m in models] plt.xlabel('Sequence Length') plt.ylabel(title) plt.title('Inference Result') for perf,fmt in zip(models_perf,fmts): plt.plot(seq, perf,fmt) plt.legend(models) plt.show() - 我们来看看两种 Longformer 配置的计算性能,如下:
plotMe(results)这个地块这下图:
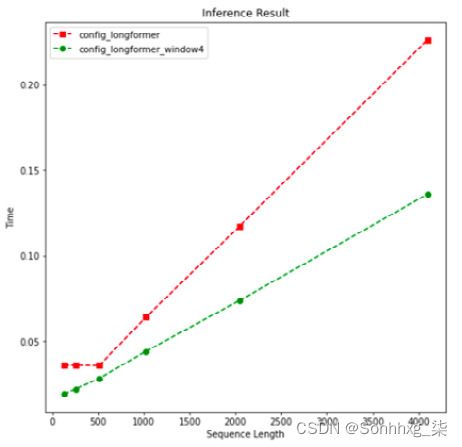
图 8.9 – 序列长度上的速度性能(Longformer)
在这个示例和下一个示例中,我们看到了从长度 512 开始的重型模型和轻型模型之间的主要区别。上图显示绿色的较轻的 Longformer 模型(窗口长度为 4 的模型)在以下方面表现更好时间复杂度符合预期。我们还看到两个 Longformer 模型以线性时间复杂度处理输入。
- 让我们从内存性能方面评估这两个模型:
plotMe(results, "Memory")这个地块这下列的:
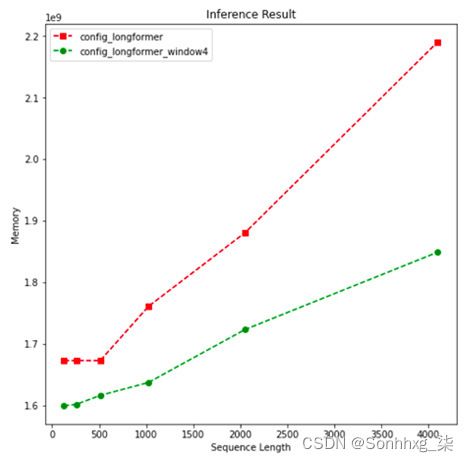
图 8.10 – 序列长度上的内存性能(Longformer)
再次,向上至长度512,有没有实质性的区别。对于其余部分,我们看到了与时间性能相似的内存性能。很明显,Longformer self-attention 的记忆复杂度是线性的。另一方面,让我提请您注意,我们还没有对模型任务性能发表任何评论。
感谢PyTorchBenchmark脚本,我们交叉检查了这些模型。当我们选择应该使用哪种配置来训练语言模型时,此脚本非常有用。在开始真正的语言模型训练和微调之前,这将是至关重要的。
另一个利用稀疏注意力的最佳模型是 BigBird (Zohen et al. 2020)。作者声称他们的稀疏注意力机制(他们称之为广义注意力机制)保留了完全自注意力的所有功能机制香草变压器线性时间。作者将注意力矩阵视为有向图,以便他们利用图论算法。他们从图稀疏化算法中获得灵感,该算法通过图G '用更少的边或顶点来逼近给定的图 G。
BigBird 是一个块级注意力模型,可以处理长度为4096的序列。它首先通过将查询和键打包在一起来阻止注意力模式,然后在这些块上定义注意力。它们利用随机、滑动窗口和全局注意力。
- 让我们像 Longformer 变压器模型一样加载和使用 BigBird 模型检查点配置。HuggingFace Hub 中的开发人员共享了几个 BigBird 检查点。我们选择原始 BigBird 模型google/bigbird-roberta-base,它是从 RoBERTa 检查点热启动的。再一次,我们不是下载模型检查点权重,而是下载配置。大鸟配置实现允许我们比较完全自注意力和稀疏注意力。因此,我们可以观察和检查稀疏化是否会将全注意力 O(n^2) 复杂度降低到较低的水平。再一次,直到长度为 512,我们没有清楚地观察到二次复杂度。我们可以从这个层面上看到复杂性。将注意力类型设置为 original-full 将为我们提供一个完整的自注意力模型。为了比较,我们创建了两种类型的配置:第一种是 BigBird 原始的稀疏方法,第二种是使用全自注意力模型的模型。
- 我们称之为他们sparseBird和fullBird在命令如下:
from transformers import BigBirdConfig # Default Bird with num_random_blocks=3, block_size=64 sparseBird = BigBirdConfig.from_pretrained( "google/bigbird-roberta-base") fullBird = BigBirdConfig.from_pretrained( "google/bigbird-roberta-base", attention_type="original_full") - 请注意,对于不超过 512 的较小序列长度,由于块大小和序列长度不一致,BigBird 模型作为完全自注意模式工作:
sequence_lengths=[256,512,1024,2048, 3072, 4096] models=["sparseBird","fullBird"] configs=[eval(m) for m in models] benchmark_args = PyTorchBenchmarkArguments( sequence_lengths=sequence_lengths, batch_sizes=[1], models=models) benchmark = PyTorchBenchmark( configs=configs, args=benchmark_args) results = benchmark.run()输出如下:
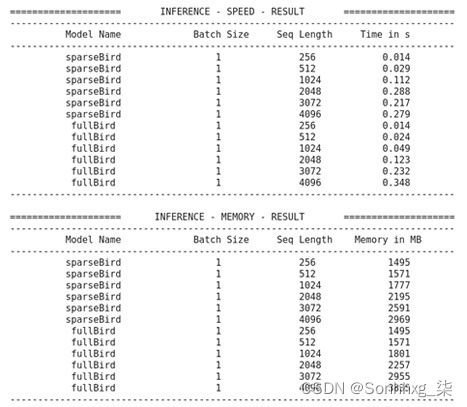
图 8.11 – 基准测试结果(BigBird)
- 再次,我们阴谋这时间表现如下:
plotMe(results)这绘制了以下内容:
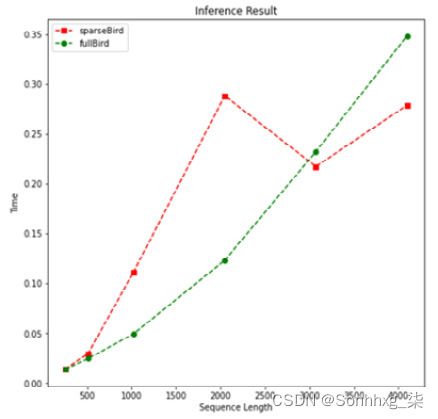
图 8.12 – 速度表现(BigBird)
对某个程度,全自注意力模型性能优于稀疏模型。但是,我们可以观察到fullBird的二次时间复杂度。因此,在某一点之后,我们还看到稀疏注意力模型在结束时突然优于它。
- 让我们检查内存复杂度如下:
plotMe(results,"Memory")这是输出:
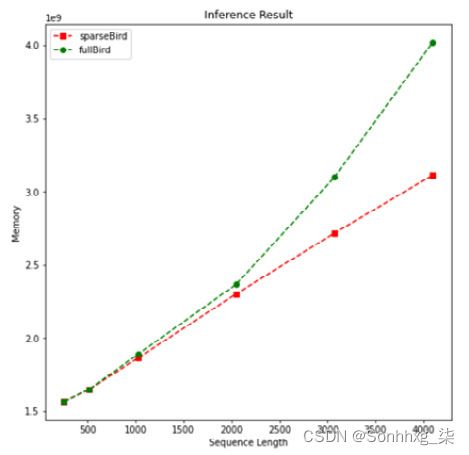
图 8.13 – 内存性能(BigBird)
在这前图中,我们可以清楚地看到线性和二次内存复杂度。再一次,直到某个点(在这个例子中长度为 2,000),我们不能说清楚的区别。
接下来,让我们讨论可学习的模式并使用可以处理更长输入的模型。
可学习的模式
以学习为基础模式是固定(预定义)模式的替代品。这些方法以无监督的数据驱动方式提取模式。他们利用一些技术来测量查询和键之间的相似性以正确地对它们进行聚类。这个转换器系列首先学习如何对标记进行聚类,然后限制交互以获得注意力矩阵的最佳视图。
现在,我们将使用作为基于可学习模式的重要高效模型之一的 Reformer 进行一些实验。在此之前,我们先来谈谈Reformer模型对NLP领域的贡献,如下:
- 它采用局部自我注意( LSA ) 将输入切割成n 个块以减少复杂性瓶颈。但是这种切割过程使边界令牌无法关注其直接邻居。例如,在块[a,b,c]和[d,e,f]中,标记d不能参与其直接上下文c。作为补救措施,Reformer 使用控制先前相邻块数量的参数来扩充每个块。
- 最多Reformer 的重要贡献是利用了局部敏感散列( LSH ) 函数,该函数将相同的值分配给相似的查询向量。注意力可以通过只比较最相似的向量来近似,这有助于我们降低维数,然后稀疏矩阵。这是一个安全的操作,因为 softmax 函数高度受大值支配并且可以忽略不相似的向量。此外,不是查找给定查询的相关键,而是仅查找和备份相似的查询。也就是说,一个查询的位置只能关注与它具有高余弦相似度的其他查询的位置。
- 为了减少内存占用,Reformer 使用了可逆残差层,这避免了在可逆残差网络 ( Reversible Residual Network ( Reversible Residual Network, RevNet ) 之后存储所有层的激活以用于反向传播的需要,因为任何层的激活都可以从下一层的激活中恢复。
需要注意的是,Reformer 模型和许多其他高效变压器受到批评,因为在实践中,当输入长度很长时,它们仅比普通变压器更有效(参考:高效变压器:调查,Yi Tay,Mostafa Dehghani、Dara Bahri、唐纳德·梅茨勒)。我们在之前的实验中做了类似的观察(请参阅 BigBird 和 Longformer 实验)。
- 现在我们将使用Reformer 进行一些实验。再次感谢 HuggingFace 社区,Transformers 库为我们提供了 Reformer执行及其预训练的检查点。我们将加载原始检查点google/reformer-enwik8的配置,并调整一些设置以在完全自注意力模式下工作。当我们将lsh_attn_chunk_length和local_attn_chunk_length设置为16384(这是 Reformer 可以处理的最大长度)时,Reformer 实例将没有机会进行局部优化,并且会像香草变压器一样自动工作,全神贯注。我们称之为fullReformer。对于原始的Reformer,我们使用原始检查点的默认参数对其进行实例化,并将其称为sparseReformer,如下所示:
from transformers import ReformerConfig fullReformer = ReformerConfig.from_pretrained("google/reformer-enwik8", lsh_attn_chunk_length=16384, local_attn_chunk_length=16384) sparseReformer = ReformerConfig.from_pretrained("google/reformer-enwik8") sequence_lengths=[256, 512, 1024, 2048, 4096, 8192, 12000] models=["fullReformer","sparseReformer"] configs=[eval(e) for e in models]请注意,Reformer 模型最多可以处理长度为16384的序列。但是对于完全自注意力模式,由于我们环境的加速器容量,注意力矩阵不适合 GPU,我们会收到 CUDA 内存不足警告。因此,我们将最大长度设置为12000。如果你的环境适合,你可以增加它。
- 让我们跑基准实验如下:
benchmark_args = PyTorchBenchmarkArguments( sequence_lengths=sequence_lengths, batch_sizes=[1], models=models) benchmark = PyTorchBenchmark( configs=configs, args=benchmark_args) result = benchmark.run()输出如下:
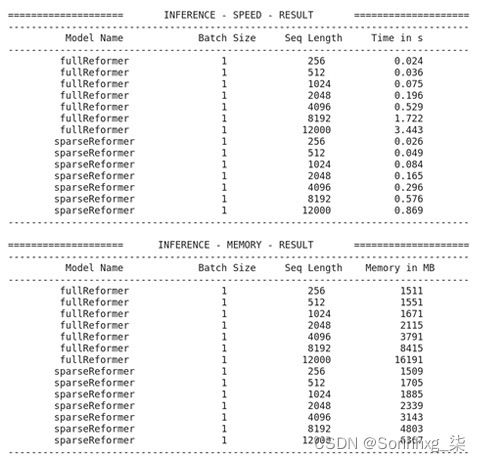
图 8.14 – 基准测试结果
- 让我们可视化时间性能结果如下:
plotMe(result)输出如下:
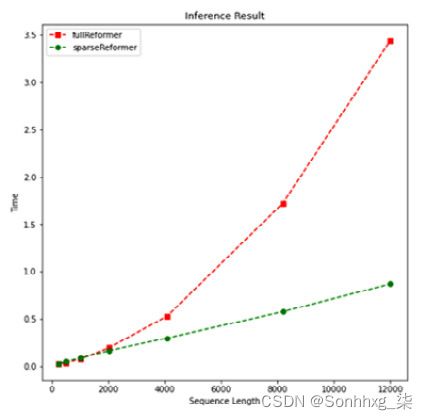
图 8.15 – 速度表现(改革者)
- 我们可以看到线性和模型的二次复杂度。我们通过运行以下行来观察内存占用的类似特征:
plotMe(result,"Memory Footprint")它绘制以下内容:
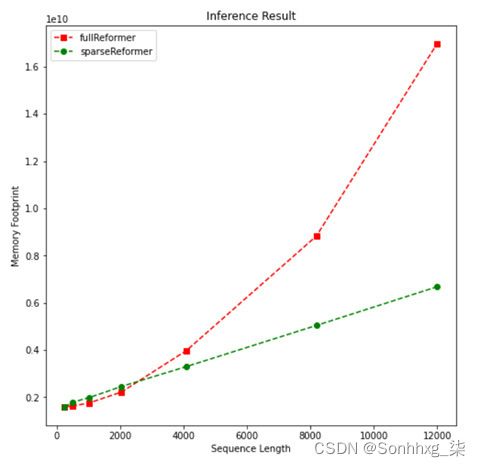
图 8.16 – 内存使用(Reformer)
正如预期,改革者用稀疏的注意力产生一个轻量级的模型。然而,如前所述,我们很难观察到一定长度的二次/线性复杂度。正如所有这些实验所表明的那样,高效的转换器可以减轻较长文本的时间和内存复杂性。任务绩效如何?它们对于分类或汇总任务的准确性如何?为了回答这个问题,我们要么开始一个实验,要么看看模型相关文章中的性能报告。对于实验,您可以通过实例化一个高效模型而不是普通变压器来重复第 04 章和第 5 章中的代码。您可以使用我们将在细节第11 章,注意力可视化和实验跟踪。
低秩分解、核方法和其他方法
最新的的趋势有效的模型是利用全自注意力矩阵的低秩近似。这些模型被认为是最轻的,因为它们可以在计算时间和内存占用方面将自注意力复杂度从O(n2) 降低到 O(n) 。选择一个非常小的投影维度k,使得k << n,那么内存和空间复杂度就会大大降低。Linformer 和 Synthesizer 是通过低秩分解有效地逼近全部注意力的模型。他们通过线性投影分解原始变压器的点积N×N注意力。
Kernel attention 是我们最近看到的另一种方法族,它通过内核化查看注意力机制来提高效率。内核是一个函数,它接受两个向量作为参数并返回它们的投影与特征图的乘积。它使我们能够在高维特征空间中进行操作,甚至无需计算该高维空间中数据的坐标,因为该空间内的计算变得更加昂贵。这是内核技巧发挥作用的时候。基于核化的高效模型使我们能够重写自注意力机制以避免显式计算 N×N 矩阵。在机器学习中,我们听到最多的关于核方法的算法是支持向量机,其中径向基函数核或多项式核被广泛使用,尤其是为了非线性。对于变压器,最著名的例子是Performer和Linear Transformers。
概括
本章的重要性在于,我们学会了如何减轻在有限计算能力下运行大型模型的负担。我们首先讨论并实现了如何使用蒸馏、修剪和量化从训练模型中制作出有效的模型。预训练较小的通用语言模型(例如 DistilBERT)非常重要。然后,与非蒸馏模型相比,此类轻模型可以在各种问题上进行微调,并具有良好的性能。
其次,我们获得了有关高效稀疏变换器的知识,这些变换器使用 Linformer、BigBird、Performer 等近似技术将完整的自注意矩阵替换为稀疏矩阵。我们已经看到了它们在各种基准测试中的表现,例如计算复杂度和内存复杂度。这些示例向我们展示了这些方法能够在不牺牲性能的情况下将二次复杂度降低为线性复杂度。
在下一章中,我们将讨论其他重要主题:跨语言/多语言模型。