什么是Prometheus?
引入
我们先来类比这样一个场景:
有一个已经上线的系统平台,用户在访问某个页面时响应及其缓慢,就投诉给产品,产品又来找研发,研发经过排查后,发现磁盘打满了,就把磁盘清了,系统恢复了正常。
过了没几天,又出现同样的问题,这次研发发现的问题是系统cpu打满了,接着就去各种调试后,系统恢复了正常。
然而又过了没几天,出现了…xxx…问题,产品又来找研发,还吐槽这系统真菜,这么不稳定,你是不是不行啊…研发表面接受,心里一万个羊驼在奔腾…没办法啊,我心里也苦…
之后研发受够了,索性开发了系统,让系统去主动发现可预见的问题,有问题之后给研发报警,研发知道后,悄悄的在用户产品发现前将其处理了,这样就舒服了…再也不用被指着鼻子了。
相信上述案例,大家或多或少都会遇到过,而在这里,我们就要引出我们的主角——Prometheus。
什么是 Prometheus?
Prometheus(普罗米修斯)是古希腊的一个神明,而他的超能力就是未卜先知,提前可以发现一些事情。对应我们的技术层面,不就是监控告警么。
维基百科的解释:Prometheus is a free software application used for event monitoring and alerting(Prometheus 是用来监控、报警的免费软件)。
Prometheus 官网的解释「From metrics to insight」(用指标洞察系统的意思)描述了 Prometheus 的用途。
历程:
Prometheus 受启发于 Google 的Brogmon 监控系统(相似的 Kubernetes 是从 Google的 Brog 系统演变而来),从 2012 年开始由前 Google 工程师在 Soundcloud 以开源软件的形式进行研发,并且于 2015 年早期对外发布早期版本。
2016 年 5 月继 Kubernetes 之后成为第二个正式加入 CNCF 基金会的项目,同年 6 月正式发布 1.0 版本。2017 年底发布了基于全新存储层的 2.0 版本,能更好地与容器平台、云平台配合。
Prometheus 作为新一代的云原生监控系统,目前已经有超过 650+位贡献者参与到Prometheus 的研发工作上,并且超过 120+项的第三方集成。
看到这里我们大概知道 Prometheus 其实就是一个数据监控解决方案,它能帮你简单快速地搭建起一套可视化的监控系统。 但这么说还是有点抽象,下面我举几个简单的例子,帮助大家理解 Prometheus 究竟能做什么?
- 对于运维人员来说,他们需要监控机器的 CPU、内存、硬盘的使用情况,以此来保证运行在机器上的应用的稳定性。
- 对于研发人员来说,他们关注某个异常指标的变化情况,从而来保证业务的稳定运行。
- 对于产品或运营来说,他们更关心产品层面的事情,例如:某个活动参加人数的增长情况,活动积分的发放情况。
对于上面说到的这些功能,Prometheus 都能够实现。Prometheus 能根据这些收集的数据实现告警功能。
例如:运维希望在 CPU 达到 80% 的时候给值班的运维人员发送邮件,产品希望活动积分发放数量超过 10 万的时候发送告警邮件。这些都可以通过 Prometheus 实现。
除了数据收集、告警功能之外,Prometheus 还有很多强大的功能,例如:强大的 ProQL 查询、许多客户端库等。
因为 Prometheus 功能强大、构建成本低,所以现在越来越多的公司都使用 Prometheus 作为其数据监控的解决方案。
来源:Prometheus 快速入门教程(开篇):为什么要学 Prometheus ?
特征
Prometheus 是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统,Prometheus 具有以下优点:
-
强大的多维度数据模型。所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中 (TSDB)。
-
时间序列数据通过 metric 名和键值对来区分。
-
所有的 metrics 都可以设置任意的多维标签。

所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB,Time Series DB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。如下所示:http_request_status{ code='200', content_path='/api/path', environment='produment' } => [value1@timestamp1,value2@timestamp2...] http_request_status{ # 指标名称 code='200', # 维度的标签 content_path='/api/path2', environment='produment' } => [value1@timestamp1,value2@timestamp2...] # 存储的样本值每一条时间序列由**指标名称(Metrics Name)以及一组标签(Labels)**唯一标识。每条时间序列按照时间的先后顺序存储一系列的样本值。
➢ http_request_status:指标名称(Metrics Name)
➢ {code=‘200’,content_path=’/api/path’,environment=‘produment’}:表示维度的标签,基于这些 Labels 我们可以方便地对监控数据进行聚合,过滤,裁剪。
➢ [value1@timestamp1,value2@timestamp2…]:按照时间的先后顺序存储的样本值。
一个指标对应多个时序。(cpu的每个核心都是一个时序)
cpu使用率是个综合信息,如包含了用户空间使用率、内核空间使用率、切换使用率
指标是数据库, 每个表的字段是通过标签定义的。
-
数据模型更随意,不需要刻意设置为以点分隔的字符串。
-
可以对数据模型进行聚合,切割和切片操作。
-
支持双精度浮点类型,标签可以设为全 unicode。
-
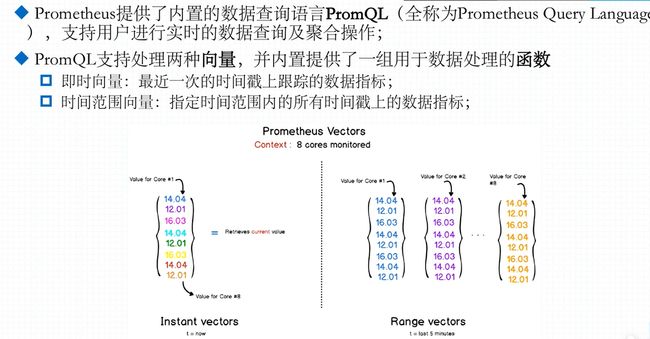
灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
比如:
➢ 在过去一段时间中 95%应用延迟时间的分布范围?
➢ 预测在 4 小时后,磁盘空间占用大致会是什么情况?
➢ CPU 占用率前 5 位的服务有哪些?(过滤)
-
易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
-
高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
-
使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。

-
可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端。
-
可以通过服务发现或者静态配置去获取监控的 targets。
-
有多种可视化图形界面。
-
易于伸缩。
生态圈组件
Prometheus生态系统包含多个组件,其中许多是可选的:
- Prometheus Server: 主服务器,负责收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 推送网关,主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。
- 一些其他的工具。
大多数Prometheus组件都是用
Go编写的,因此易于构建和部署为静态二进制文件。
架构

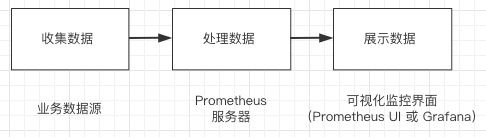
整体的工作流程是:
- Prometheus server 定期从配置好的 jobs 或者 exporters 中拉 metrics,或者接收来自 Pushgateway 发过来的 metrics,或者从其他的 Prometheus server 中拉 metrics。
- Prometheus server 在本地存储收集到的 metrics,并运行已定义好的 alert.rules,记录新的时间序列或者向 Alertmanager 推送警报。
- Alertmanager 根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
简单来说,就是收集数据、处理数据、可视化展示,再进行数据分析进行报警处理。
为什么需要Prometheus
来源:Prometheus 快速入门教程(开篇):为什么要学 Prometheus ?
对于流量不是很大的系统来说,出现几分钟的故障可能造成不了多少损失。但是对于像淘宝、美团、字节跳动这样的巨无霸来说,宕机 1 分钟损失的金额可能就是几百万!
所以弄清楚此时此刻系统的运行是否正常?各项业务指标是否超过阈值?这些问题是每个经验丰富的研发人员所需要关注的事情!
那么如何监控你的系统?如何得知系统目前是正常还是异常?甚至如何预知未来一段时间系统可能出问题?Prometheus 正是这么一套数据监控解决方案。它能让你随时掌控系统的运行状态,快速定位出现问题的位置,快速排除故障。
对于个人来讲,掌握 Prometheus 可以增加你当 leader 的竞争力。 毕竟如果一个研发对自己的系统运行状况都不了解,那么他怎么做 leader,怎么带领一个团队往前冲呢?
市场上的竞品
来源:监控 prometheus 与zabbix对比
经过上述的介绍,我们已经知道了Prometheus是一个监控告警的软件,那么目前市面上监控系统只有Prometheus么?
答案是否定的,与其存在竞争的产品是Zabbix。
两者之间的区别如下:
| Zabbix | Prometheus |
|---|---|
| 后端用 C 开发,界面用 PHP 开发,定制化难度很高。 | 后端用 golang 开发,前端是 Grafana,JSON 编辑即可解决。定制化难度较低。 |
| 集群规模上限为 10000 个节点。 | 支持更大的集群规模,速度也更快。 |
| 更适合监控物理机环境. | 更适合云环境的监控,对 OpenStack,Kubernetes 有更好的集成。 |
| 监控数据存储在关系型数据库内,如 MySQL,很难从现有数据中扩展维度。 | 监控数据存储在基于时间序列的数据库内,便于对已有数据进行新的聚合。 |
| 安装简单,zabbix-server 一个软件包中包括了所有的服务端功能。 | 安装相对复杂,监控、告警和界面都分属于不同的组件。 |
| 图形化界面比较成熟,界面上基本上能完成全部的配置操作。 | 界面相对较弱,很多配置需要修改配置文件。 |
| 发展时间更长,对于很多监控场景,都有现成的解决方案。 | 2015 年后开始快速发展,但发展时间较短,成熟度不及 Zabbix。 |
总结:
如果监控的是物理机,用 Zabbix 没毛病,Zabbix在传统监控系统中,尤其是在服务器相关监控方面,占据绝对优势。甚至环境变动不会很频繁的情况下,Zabbix 也会比 Prometheus 好使;
但如果是云环境的话,除非是 Zabbix 玩的非常溜,可以做各种定制,否则还是 Prometheus 吧,毕竟人家就是干这个的。Prometheus开始成为主导及容器监控方面的标配,与kubernetes适配度更高,并且在未来可见的时间内被广泛应用。如果是刚刚要上监控系统的话,不用犹豫了,Prometheus 准没错。
使用场景
- 容器监控,服务部署在云服务器上;
- k8s架构下的监控系统;
- 急需一套监控系统,而又没有特别大的精力和成本去开发一套;
Prometheus非常适合记录任何纯数字时间序列。它既适合以机器为中心的监视,也适合于高度动态的面向服务的体系结构的监视。在微服务世界中,它对多维数据收集和查询的支持是一种特别的优势。
Prometheus的设计旨在提高可靠性,使其成为中断期间要使用的系统,以使您能够快速诊断问题。
每个Prometheus服务器都是独立的,而不依赖于网络存储或其他远程服务。当基础结构的其他部分损坏时,您可以依靠它,并且无需设置广泛的基础结构即可使用它。