Functional Mechanism: Regression Analysis under Differential Privacy
Functional Mechanism: Regression Analysis under Differential Privacy
1. 摘要
差分隐私是一种能在保护隐私的同时发布敏感数据的方法。
目前,已经提出了很多种方法将差分隐私应用到回归分析中。但是,这些方法要么只能在某些非标准类型的回归中使用,
要么就无法达到足够的精度。
于是,为了解决上面的两个问题,作者提出了函数机制,并将它应用到了线性回归和 logistic 回归上。
那么函数机制有什么特别之处呢?现有的方法都是直接扰动最终的结果,而函数机制是在目标函数上进行扰动。
2. 介绍
2.1 函数机制的设计难点
- 扰动目标函数比扰动标量要论难的多
- 直接在目标函数的系数上加人噪声很容易导致注入了过量的噪声,从而导致函数无法收敛
- 部分目标函数被扰动后可能失效,比如产生了无界的结果,或者多个局部最优。
2.2 函数机制的优点
- 对于线性回归和 logistic 回归,无论训练集的规模是多少,加入的噪声量是恒定的。
- 在 ϵ \epsilon ϵ - differential privacy上就能实现,不需要使用松弛化项 δ \delta δ
3. 准备工作
3.1 线性回归
线性回归假设目标值和特征之间线性相关,即可以通过多个特征来预测目标值。线性回归可以由以下公式表示:
y ^ = ω x + b ( 线 性 回 归 的 一 般 表 示 ) \widehat{y} = \omega x + b (线性回归的一般表示) y =ωx+b(线性回归的一般表示)
其中, ω \omega ω 是权重,b是偏移量。
线性回归的一个经典例子就是房价预测,使用占地面积,地段,房龄等特征来预测房价
线性回归使用均方误差来做损失函数,用梯度下降法来不断修正参数,使得预测结果变得越来越精确。
线性回归损失函数为 L ( ω , b ) = 1 n ∑ i = 1 n ( ω x i + b − y i ) 2 L(\omega,b) =\frac{1}{n}\sum_{i=1}^n(\omega x_i + b - y_i)^2 L(ω,b)=n1∑i=1n(ωxi+b−yi)2
线性回归的核心思路就是通过梯度下降求解损失函数最小时的 ω ∗ 和 b ∗ \omega ^* 和 b^* ω∗和b∗
( ω ∗ , b ∗ ) = a r g m i n ( ω , b ) ∑ i = 1 n ( ω x i + b − y i ) 2 (\omega ^*,b^*) = argmin(\omega,b)\sum_{i=1}^n(\omega x_i + b - y_i)^2 (ω∗,b∗)=argmin(ω,b)i=1∑n(ωxi+b−yi)2
3.2 Logistic 回归
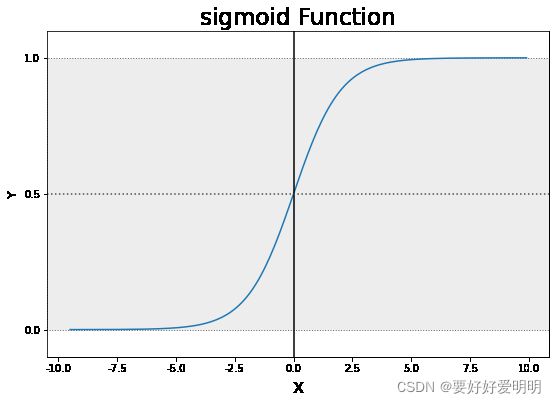
Logistic 回归常用于分类问题。它使用sigmoid函数将原函数转化成一个值在 ( 0 , 1 ) (0,1) (0,1) 之间的分布。例如,我们可以将预测值大于 0.5 0.5 0.5 的个体分为一类,小于等于 0.5 0.5 0.5 的个体分为第二类。Logistic 的一般公式为: y ^ = e ω x 1 + e ω x \widehat{y}=\frac{e^{\omega x}}{1+e^{\omega x}} y =1+eωxeωx
和线性回归不同的是,Logistic 回归的损失函数为对数损失函数。公式表示如下:
L ( ω , b ) = − [ y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ] L(\omega,b) = -[y{\,}log{\,}\widehat{y}+(1-y)log(1-\widehat{y})] L(ω,b)=−[ylogy +(1−y)log(1−y )]
该损失函数可用分段函数表示为
L ( ω , b ) = { − l o g ( y ^ ) y = 1 − l o g ( 1 − y ^ ) y = 0 L(\omega,b) =\left\{ \begin{matrix} -log({\,}\widehat{y}){\,} \quad \quad \quad y=1 \\ -log({\,}1-\widehat{y}){\,}{\,} \quad y=0 \end{matrix} \right. L(ω,b)={−log(y )y=1−log(1−y )y=0
Logistic 回归通过最小化损失函数来实现更精准的分类。
3.3 ϵ \epsilon ϵ- Differential Privacy
差分隐私使查询随机化,让攻击者无法判断某条记录是否在数据集中。
如果一个随机化算法 A \mathcal{A} A 满足 $\epsilon $- Differential Privacy,那么 A A A 在任意两个相邻数据集 D 1 D1 D1 和 D 2 D2 D2 上的输出满足:
P r [ A ( D 1 ) = O ] ≤ e ϵ ⋅ P r [ A ( D 2 ) = O ] Pr[\mathcal{A}(D_1) = O ]{\,}\le e^\epsilon\cdot Pr[\mathcal{A}(D_2) = O] Pr[A(D1)=O]≤eϵ⋅Pr[A(D2)=O]
其中 O O O 表示输出的结果 , P r Pr Pr 表示概率。
ϵ \epsilon ϵ为隐私保护强度, ϵ \epsilon ϵ越大,数据可用性越高,隐私保护强度越低。反之亦然。
3.4 拉普拉斯机制
实现差分隐私最简单的方式就是将拉普拉斯噪声注入到查询的结果中。
设查询为 f ( x ) f(x) f(x) ,扰动后的查询为 F ( x ) F(x) F(x) ,那么 F ( x ) = f ( x ) + L a p ( s ϵ ) F(x) = f(x){\,}+Lap(\frac{s}{\epsilon}) F(x)=f(x)+Lap(ϵs)
其中, L a p ( s ϵ ) Lap(\frac{s}{\epsilon}) Lap(ϵs) 是满足拉普拉斯分布的噪声。
s s s 为全局敏感度,设 D 1 D1 D1 和 D 2 D2 D2 是两个相差只有一条记录的兄弟数据集, Q Q Q 为查询函数。 s s s 等于任意两个兄弟数据集查询结果的 L 1 L_1 L1范数的最大值:
s = m a x ∣ ∣ Q ( D 1 ) − Q ( D 2 ) ∣ ∣ 1 s = max{\,}||Q(D_1)-Q(D2)||_1 s=max∣∣Q(D1)−Q(D2)∣∣1
3.5 符号定义
| 符号 | 描述 |
|---|---|
| D D D | 包含 n 条记录的数据集 |
| t i = ( x i , y i ) t_i = (x_i,y_i) ti=(xi,yi) | 数据集 D 中的第 i 条记录 |
| d d d | 特征向量 x i x_i xi 的特征数 |
| ω \omega ω | 回归模型的权重向量 |
| f ( t i , ω ) f(t_i,\omega) f(ti,ω) | 回归模型的损失函数 |
| f D ( ω ) f_D(\omega) fD(ω) | f D ( ω ) = ∑ t i ∈ D f ( t i , ω ) f_D(\omega) = \sum_{t_i\in D}f(t_i,\omega) fD(ω)=∑ti∈Df(ti,ω) | 对所有记录的损失函数求和 |
| ω ∗ \omega^* ω∗ | ω ∗ = a r g m i n ω f D ( ω ) \omega^* = argmin_{\omega} f_D(\omega) ω∗=argminωfD(ω) |
| f ˉ D ( ω ) \bar{f}_D(\omega) fˉD(ω) | 扰动后的 f D ( ω ) f_D(\omega) fD(ω) |
| ω ˉ \bar{\omega} ωˉ | f ˉ D ( ω ) \bar{f}_D(\omega) fˉD(ω) 最小时对应的权重 ω \omega ω |
| f ~ D ( ω ) \widetilde{f}_D(\omega) f D(ω) | 对 f D ( ω ) f_D(\omega) fD(ω) 泰勒展开后得到的损失函数 |
| ω ~ \widetilde{\omega} ω | f ~ D ( ω ) \widetilde{f}_D(\omega) f D(ω) 最小时对应的权重 ω \omega ω |
| f ^ D ( ω ) \widehat{f}_D(\omega) f D(ω) | 取泰勒展开式中的低次项构成的渐进函数 |
| ω ^ \widehat{\omega} ω | f ^ D ( ω ) \widehat{f}_D(\omega) f D(ω) 最小时对应的权重 ω \omega ω |
| ϕ \phi ϕ | ω \omega ω 中的各个分量运算得到的结果(与二项展开式有关)如 ( ω 1 ) 3 ⋅ ω 2 (\omega_1)^3\cdot\omega^2 (ω1)3⋅ω2 |
| Φ j \Phi_j Φj | 所有幂为 j j j 的 ϕ \phi ϕ 对应的集合 |
| λ ϕ t i \lambda_{\phi_{t_i}} λϕti | 第 i i i 条记录对应的 ϕ \phi ϕ 的多项式系数(这里有多个,因为 ϕ \phi ϕ的幂有多个) |
3.6 部分说明
-
设 D D D 包含 n n n 条记录 t 1 , t 2 , . . . t n t_1,t_2,...t_n t1,t2,...tn ,每条记录包含 n + 1 n+1 n+1 个属性, X 1 , X 2 . . . X d , Y X_1,X_2...X_d,Y X1,X2...Xd,Y。
假设不失一般性, ∑ j = 1 d x i j 2 ≤ 1 \sqrt{\sum^d_{j=1}x^2_{ij}}\le1 ∑j=1dxij2≤1 (第 i i i 条记录的特征的 L2 范数小于等于 1 )
这里我觉得是因为对数据做了规范化处理(均值为0,方差为1)
-
为了方便进行讨论,论文所有的属性都是二值属性,即 0 或 1 。如果有多值,比如婚姻状况,有未婚,已婚,丧偶三种。则将这个三值属性转换成两个二值属性,即是否已婚,是否丧偶。
4.理论部分
4.1 函数机制
直接在目标函数上进行扰动,极具挑战。这主要是因为权重 ω \omega ω 的全局敏感度分析起来十分困难 。
根据 S t o n e − W e i e r s t r a s s Stone -Weierstrass Stone−Weierstrass 定理,任何连续可微分的函数 f ( x ) f(x) f(x) 可以由一个多项式 A x n + B x n − 1... + K x 1 + b x 0 Ax^n +Bx^n-1...+Kx^1+bx^0 Axn+Bxn−1...+Kx1+bx0来表示。
这样,在将原函数转换成多项式形式后。就可以在多项式系数上加入噪声,而不是在权重 ω \omega ω 上加入噪声。
在回归问题中,对于训练集中的一条记录,目标函数为 f ( t i , ω ) f(t_i,\omega) f(ti,ω) 。这里的 ω \omega ω 就可以看作是 f ( x ) f(x) f(x) 中的 x x x 。
向量 ω \omega ω 中包含 d d d 个值 ω 1 , ω 2 . . . ω d \omega_1,\omega_2...\omega_d ω1,ω2...ωd,令 ϕ \phi ϕ 为 ω \omega ω 中的各个分量幂运算得到的结果(这里与二项式定理有关)。
Φ j \Phi_j Φj 为所有幂为 j j j 的 ϕ \phi ϕ 对应的集合,公式表达如下:
Φ j = { ω 1 c 1 ω 2 c 2 . . . ω d c d ∣ ∑ l = 1 d c l = j } \Phi_j = \left\{\begin{matrix}\omega_1^{c_1}\omega_2^{c_2}...\omega_d^{c_d}|\sum_{l=1}^dc_l=j \end{matrix}\right\} Φj={ω1c1ω2c2...ωdcd∣∑l=1dcl=j}
例如, Φ 0 = { 1 } \Phi_0=\left\{\begin{matrix}1 \end{matrix}\right\} Φ0={1} , Φ 1 = { ω 1 , ω 2 . . . , ω d } \Phi_1=\left\{\begin{matrix}\omega_1,\omega_2...,\omega_d \end{matrix}\right\} Φ1={ω1,ω2...,ωd} , Φ 2 = { ω i ⋅ ω j ∣ i , j ∈ [ 1 , d ] } \Phi_2=\left\{\begin{matrix}\omega_i\cdot\omega_j|i,j \in[1,d]\end{matrix}\right\} Φ2={ωi⋅ωj∣i,j∈[1,d]} 。
这里其实就是对 ω \omega ω 求幂, ω 0 = 1 \omega^0 = 1 ω0=1 , ω 1 = { ω 1 , ω 2 . . . , ω d } \omega^1=\left\{\begin{matrix}\omega_1,\omega_2...,\omega_d \end{matrix}\right\} ω1={ω1,ω2...,ωd}, ω 2 = { ω i ⋅ ω j ∣ i , j ∈ [ 1 , d ] } \omega^2=\left\{\begin{matrix}\omega_i\cdot\omega_j|i,j \in[1,d]\end{matrix}\right\} ω2={ωi⋅ωj∣i,j∈[1,d]}
设 J J J 为多项式的最高次幂, J ∈ [ 0 , ∞ ] J\in[0,\infty] J∈[0,∞] , λ ϕ t i 为 多 项 式 系 数 \lambda_{\phi_{t_i}}为多项式系数 λϕti为多项式系数, f ( t i , ω ) f(t_i,\omega) f(ti,ω) 为可以由多项式表示为:
f ( t i , w ) = ∑ j = 0 J ∑ ϕ ∈ Φ j λ ϕ t i ϕ ( ω ) f(t_i,w)=\sum^J_{j=0}\sum_{\phi\in\Phi_j}\lambda_{\phi_{t_i}}\phi(\omega) f(ti,w)=j=0∑Jϕ∈Φj∑λϕtiϕ(ω)
因为函数机制是在多项式系数上加入拉普拉斯噪声,所以我们需要求解多项式系数的全局敏感度 s s s
对于兄弟数据集 D D D 和 D ′ D' D′,它们的目标函数可以由如下多项式表示:
f ( t i , ω ) = ∑ j = 0 J ∑ ϕ ∈ Φ j ∑ t i ∈ D λ ϕ t i ϕ ( ω ) , f ( t i , ω ) = ∑ j = 0 J ∑ ϕ ∈ Φ j ∑ t i ∈ D 1 λ ϕ t i ϕ ( ω ) . f(t_i,\omega) =\sum^J_{j=0}\sum_{\phi\in\Phi_j}\sum_{t_i \in D}\lambda_{\phi_{t_i}}\phi(\omega),\\ f(t_i,\omega) =\sum^J_{j=0}\sum_{\phi\in\Phi_j}\sum_{t_i \in D_1}\lambda_{\phi_{t_i}}\phi(\omega). f(ti,ω)=j=0∑Jϕ∈Φj∑ti∈D∑λϕtiϕ(ω),f(ti,ω)=j=0∑Jϕ∈Φj∑ti∈D1∑λϕtiϕ(ω).
对它们的多项式作差,可得如下不等式:
∑ j = 0 J ∑ ϕ ∈ Φ j ∣ ∣ ∑ t i ∈ D λ ϕ t i − ∑ t i ′ ∈ D ′ λ ϕ t i ′ ∣ ∣ 1 ≤ 2 max t ∑ j = 1 J ∑ ϕ ∈ Φ j ∣ ∣ λ ϕ t ∣ ∣ 1 \sum_{j=0}^J\sum_{\phi\in\Phi_j}||\sum_{t_i\in D}\lambda_{\phi_{t_i}}-\sum_{t'_i\in D'}\lambda_{\phi_{t_i'}}||_1 \le 2\max_t \sum_{j=1}^J\sum_{\phi \in \Phi_j}||\lambda_{\phi_t}||_1 j=0∑Jϕ∈Φj∑∣∣ti∈D∑λϕti−ti′∈D′∑λϕti′∣∣1≤2tmaxj=1∑Jϕ∈Φj∑∣∣λϕt∣∣1
根据上述,可以得到函数机制的算法流程:

4.2 泰勒展开式
泰勒展开是用一个多项式函数 g ( x ) g(x) g(x) 来仿造原函数 f ( x ) f(x) f(x) 的方法,使这两个函数在某一点的初始值相等, 1 1 1 阶导数相等, 2 2 2 阶导数相等,… n n n 阶导数相等。泰勒展开式在点 x 0 x_0 x0 处的表达式如下:
g ( x ) = g ( x 0 ) + f 1 ( x 0 ) 1 ! x + f 2 ( x 0 ) 2 ! x 2 + . . . . . . f n ( x 0 ) n ! x n g(x) = g(x_0)+\frac{f^1(x_0)}{1!}x + \frac{f^2(x_0)}{2!}x^2+......\frac{f^n(x_0)}{n!}x^n g(x)=g(x0)+1!f1(x0)x+2!f2(x0)x2+......n!fn(x0)xn
知乎上有个很好的帖子来理解泰勒展开式:怎样更好的理解并记忆泰勒展开式?
4.3 将函数机制应用到线性回归上
前面说到,函数机制用多项式来渐进目标函数,而线性回归的损失函数本身就是多项式,所以可以直接在损失函数的多项式系数上加噪声。
线性回归的目标函数:
f D ( ω ) = ∑ t i ∈ D ( y i − x i T ω ) 2 = ∑ t i ∈ D ( y i ) 2 − ∑ j = 1 d ( 2 ∑ t i ∈ D y i x i j ) ω j + ∑ 1 ≤ j , l ≤ d ( ∑ t i ∈ D x i j x i l ) ω j ω l f_D(\omega) = \sum_{t_i\in D}(y_i-x_i^T\omega)^2 =\\ \sum_{t_i\in D}(y_i)^2-\sum_{j=1}^d\left(2\sum_{t_i\in D}y_ix_{ij}\right)\omega_j + \sum_{1\le j,l \le d}\left(\sum_{t_i \in D}x_{ij}x_{il}\right)\omega_j\omega_l fD(ω)=ti∈D∑(yi−xiTω)2=ti∈D∑(yi)2−j=1∑d(2ti∈D∑yixij)ωj+1≤j,l≤d∑(ti∈D∑xijxil)ωjωl
全局敏感度求解如下:
Δ = 2 max t = ( x , y ) ∑ j = 1 J ∑ ϕ ∈ Φ J ∣ ∣ λ ϕ t ∣ ∣ 1 ≤ 2 max t = ( x , y ) ( y 2 + 2 ∑ j = 1 d y x ( j ) + ∑ 1 ≤ j , l ≤ d x ( j ) x ( l ) ) ≤ 2 ( 1 + 2 d + d 2 ) \Delta = 2{\,} \max_{t=(x,y)}\sum_{j=1}^J\sum_{\phi\in\Phi_J}||\lambda_{\phi_t}||_1 {\,} \le 2{\,} \max_{t=(x,y)}\left(y^2+2\sum_{j=1}^dyx_{(j)}+\sum_{1\le j,l \le d}x_{(j)}x_{(l)}\right) \le 2{\,}(1+2d+d^2) Δ=2t=(x,y)maxj=1∑Jϕ∈ΦJ∑∣∣λϕt∣∣1≤2t=(x,y)max⎝⎛y2+2j=1∑dyx(j)+1≤j,l≤d∑x(j)x(l)⎠⎞≤2(1+2d+d2)
∵ y ∈ [ − 1 , 1 ] → m a x ( y 2 ) = 1 , m a x ( y x j ) = 1 \because y \in [-1,1] \rightarrow max({\,}y^2) = 1,max(yx_j)=1 ∵y∈[−1,1]→max(y2)=1,max(yxj)=1
将求解得到的全局敏感度 Δ \Delta Δ 带入到算法1中即可求解。
4.4 将函数机制应用到 Logistic 回归上
L o g i s t i c Logistic Logistic 回归的损失函数本身不是多项式,需要使用泰勒展开式构造一个多项式。
Logistic 回归的损失函数为: f D ( w ) = − [ y l o g x i T ω + ( 1 − y ) l o g ( 1 − x i T ω ) ] f_D(w) = -[y{\,}log{\,}x_i^T\omega+(1-y)log(1-x_i^T\omega)] fD(w)=−[ylogxiTω+(1−y)log(1−xiTω)]
论文证明在 Logistic 回归中泰勒展开到二阶就能保证构造的多项式函数相对于原函数损失只有 ≈ 0.015 \approx 0.015 ≈0.015
我们将 Logistic 回归的损失函数用泰勒在 0 0 0 处展开到二阶(后面一项本身是多项式不需要展开)
f ^ D ( ω ) = ∑ i = 1 n ∑ k = 0 2 f 1 ( k ) ( 0 ) k ! ( x i T ω ) k − ( ∑ i = 1 n y i x i T ) ω \widehat{f}_D(\omega)=\sum_{i=1}^n\sum_{k=0}^2\frac{f_1^{(k)}(0)}{k!}\left(x_i^T\omega\right)^k -\left(\sum_{i=1}^ny_ix_i^T\right)\omega f D(ω)=i=1∑nk=0∑2k!f1(k)(0)(xiTω)k−(i=1∑nyixiT)ω
对应的全局敏感度 Δ \Delta Δ 为
Δ = 2 max t = ( x , y ) ( f 1 ( 1 ) ( 0 ) 1 ! ∑ j = 1 d x ( j ) + f 1 ( 2 ) ( 0 ) 2 ! ∑ j , l x ( j ) x ( l ) + y ∑ j = 1 d x ( j ) ) ≤ 2 ( d 2 + d 2 8 + d ) = d 2 4 + 3 d \Delta = 2{\,}\max_{t={(x,y)}}\left(\frac{f_1^{(1)}(0)}{1!}\sum_{j=1}^dx_{(j)}+\frac{f_1^{(2)}(0)}{2!}\sum_{j,l}x_{(j)}x_{(l)}+y\sum^d_{j=1}x_{(j)}\right) \\ \le 2 {\,}(\frac{d}{2}+\frac{d^2}{8}+d) = \frac{d^2}{4}+3d Δ=2t=(x,y)max⎝⎛1!f1(1)(0)j=1∑dx(j)+2!f1(2)(0)j,l∑x(j)x(l)+yj=1∑dx(j)⎠⎞≤2(2d+8d2+d)=4d2+3d
将 Δ \Delta Δ 带入到算法1中即可求解
5. 避免注入的噪声使损失函数无法收敛
使用函数机制 L o g i s t i c Logistic Logistic 回归中注入噪声,可能会导致损失函数无法收敛。
我们在对 L o g i s t i c Logistic Logistic 进行低阶泰勒展开后,得到的是一个二阶多项式。
为了方便描述,我们令这个式子为 A x 2 + b x + c Ax^2+bx+c Ax2+bx+c. 当 A > 0 A>0 A>0 时,损失函数为一个开口向上的抛物线。
如果加入对多项式系数扰动后, A < 0 A<0 A<0 那么损失函数就变成了一个开口向下的抛物线,那么就导致损失函数无法收敛到最小值处。
所以在 L o g i s t c Logistc Logistc 回归中需要保证多项式的二次项系数加噪后仍然为正。
论文中给出的一个解决方式是:如果发现 A < 0 A<0 A<0 了,重新运行函数机制,直到它扰动后为正。
6. 实验
作者将自己的算法与 D P M E DPME DPME, F i l t e r − P r i o r i t y Filter-Priority Filter−Priority,Truncated 以及不加差分隐私的算法进行了对比,结果证明函数机制造成的性能损失更小,训练时间更短,基本上是完胜其他几个算法(在我的论文里,你们是无法战胜我的)。
原作者使用的matlab进行实验且代码未公开,具体性能需要复现后才能知道。